



Quick Takeaways
MiniMax M3 is built for long-horizon agentic work including coding, tool use, task decomposition, multi-step reasoning, long context, and native multimodality.
Mem0 gives that agent durable memory across restarts, so the next run reuses what the previous run learned instead of starting from zero.
In the demo, M3 chooses the next improvement for an app, a test result comes back, and Mem0 stores the decision and the outcome.
The Best app score in this demo is simulated. It stands in for a real test suite, benchmark, or product metric, and in production you replace the scoring stub with your actual eval.
The pattern is four steps: recall from Mem0, ask M3 for one next action, run the tool or eval, then write the result back to Mem0.
M3 manages the next reasoning step. Mem0 manages what survives after the process ends. Agents that work across sessions need both layers.
💡 You'll need a free Mem0 API key to follow along. Get one at app.mem0.ai, free tier, no credit card required.
MiniMax brings the reasoning layer with the M3 model, which includes coding strength, agentic task decomposition, tool invocation, long-context processing, and multimodal understanding. Mem0 brings the memory layer, a persistent store of decisions, outcomes, constraints, and task state that survives outside the model context window.
M3 decides the next step, and Mem0 makes sure the next session still knows what happened in the last one. This post walks through a small demo agent that combines both, where M3 proposes the next coding step for a simple app, the app returns a test score, Mem0 stores the step and result, and after a restart, the agent recalls the old memories and continues from the next useful step.
By the end of this tutorial, you’ll see something like this:
New to this topic? Three terms to know:
Context window: The model's working memory for the current request. M3 supports up to a 1M-token context window through MiniMax Sparse Attention, with a guaranteed minimum of 512K tokens.
Persistent memory: A memory store outside the model context window. It survives restarts, new sessions, and process failures.
Long-running AI agent: An agent that can stop and start again without losing what it already tried, what worked, and what failed.
What Is a Long-Running AI Agent with Persistent Memory?
A long-running AI agent keeps task-specific memory outside the prompt, retrieves the relevant history before each step, and writes new outcomes back after each step. It does not depend on one uninterrupted chat session to keep working. A durable coding agent uses this same pattern for software tasks, remembering prior implementation decisions, test results, and constraints across restarts.
The naive version of a coding agent looks like this:
That works for one turn. It breaks when the task takes ten turns. If the process restarts, the agent no longer knows which approaches it already tried, which changes improved the score, which changes were rejected, which constraints came from the user, or which next step made sense after the latest result.
The better pattern is a loop with memory:
The model still reasons. The tool still tests. The difference is that the agent no longer has to carry continuity only inside one prompt.
Why M3 and Mem0 Fit Together
MiniMax describes M3 as a model built around three frontier capabilities: coding and agentic performance, long context through MiniMax Sparse Attention, and native multimodality. That matters for agents because long-running work is not just answering the prompt. It is breaking the task into steps, choosing the next action, calling tools, reading feedback, adapting, and continuing.
MiniMax's M3 examples showcased running a 12-hour ICLR paper reproduction workflow, optimizing an FP8 GEMM kernel over 147 benchmark submissions, and operating with a context window designed for long-range coding, long-range agent tasks, and long-video understanding.

Mem0 solves the other side of the same problem. Even a large context window is still tied to the current run. If the agent process stops, the context does not automatically become durable memory. If you want the next run to know what the previous run learned, you need a persistent layer. That is the partnership story: M3 is the reasoning engine, Mem0 is the memory layer, and the agent loop is where they meet.
What You’ll Build
The demo uses a simple recipe app task because it is easy for a broad audience to understand:
Make a simple recipe app better. Let users search recipes by ingredient, save favorites, and filter by cooking time. Keep their saved recipes after they refresh the page.
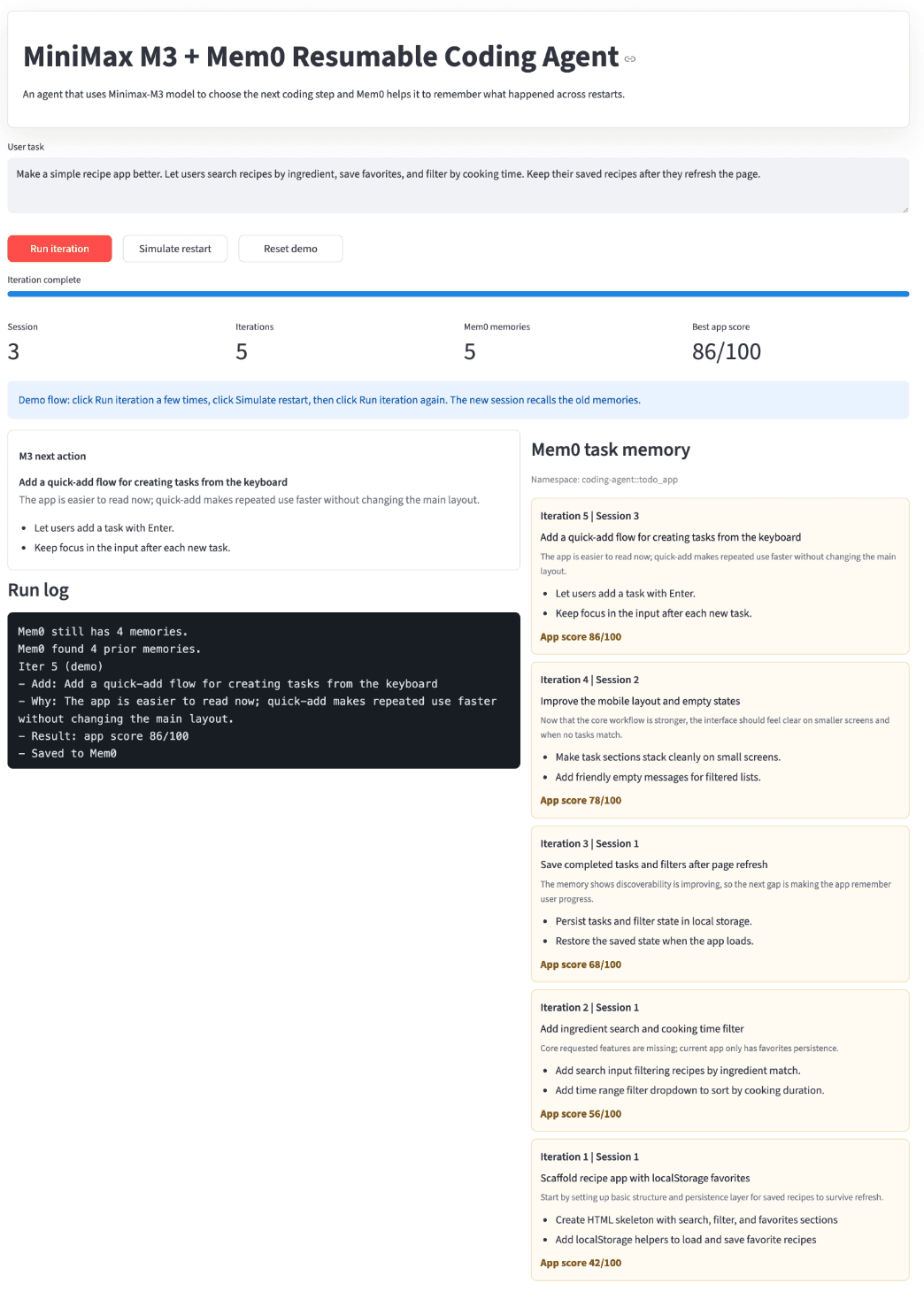
Each iteration does one thing. M3 proposes the next app improvement. The demo records a simulated app score. Mem0 stores the improvement, rationale, steps, session number, and result. When you click restart, the UI starts a new session but keeps the Mem0 task memory. When you run the next iteration, M3 sees what already happened and proposes the next step from that history.
💡You can access the complete code on the GitHub repository.
How the M3 + Mem0 Demo Works
TL;DR: The agent recalls prior task memories from Mem0, asks MiniMax M3 for one non-repeated next coding step, records a simulated test result, then writes the new step and result back to Mem0.
The demo has two paths. The Streamlit UI is a visual walkthrough that shows the loop clearly, with the task, the M3 next action, the Mem0 task memory, a run log, a restart button, and the score. The Python agent is the implementation reference. It calls M3 through MiniMax's official API and uses the Mem0 SDK for memory.
Every iteration follows the same four-step lifecycle.

Fig: Four-step lifecycle
Recall
The agent searches Mem0 using a stable task namespace:
That namespace is the small detail that makes the run stateful. A new process can search the same namespace and recover the same task memory.
Reason
The agent sends the task and recalled memories to M3.
The prompt asks for one next step, not a giant plan:
That framing matters. A strong coding model can generate a large implementation plan, but this demo needs a readable loop, and one step per iteration keeps the memory useful.
Evaluate
The demo returns an app score. For this demo, the score is simulated.
In production, this is the one function you replace. It could call unit tests, Playwright UI tests, lint and build checks, an internal eval, a benchmark harness, or a product metric. The rest of the loop stays the same.
🚨Remember
The agent stores the decision and result in Mem0.
The next run can now retrieve this memory before asking M3 what to do next. This is the write step, and in production it runs after every meaningful agent turn.
💡 Start free on Mem0. Your first memories are on the free tier with no credit card.
How MiniMax M3 Does It
M3 is responsible for choosing the next action. In this demo, the model sees the user task, the prior actions from Mem0, the results from those actions, and an instruction to avoid repeating old work. Then it returns structured JSON:
This is intentionally constrained. The UI should not show a wall of model output. The model can be powerful and still be asked for a small answer, and in fact that is usually better product design.
Why does M3 sometimes take time?
M3 is doing a live model call through the MiniMax API, so a longer response time can be normal depending on network latency, provider load, and the reasoning work requested. For this demo, the output is short, but the agent still makes a remote call when MINIMAX_API_KEY is configured. The UI includes a fallback path only so the demo keeps running if the key is missing or the API request fails.
How Mem0 Does It
Mem0 is responsible for continuity. It gives M3 the relevant memory before M3 reasons. In the demo, Mem0 stores short task memories like this:
After a restart, the agent does not need the whole transcript. It needs the useful task state: what was tried, why it was chosen, what happened, and what score came back. That is the part Mem0 preserves.
M3 vs. Mem0: Key Roles
M3 chooses the next action while Mem0 stores and retrieves the task memory that makes that choice informed.
MiniMax M3 | Mem0 | |
|---|---|---|
Role | Chooses the next action | Stores and retrieves task memory |
Scope | Current reasoning step | Cross-session continuity |
Strength | Coding, agentic reasoning, long context, multimodality | Persistent memory, retrieval, task history |
Input | Task brief plus recalled memory | Decisions, results, metadata |
Output | Next action and rationale | Relevant memories for the next run |
Failure if missing | Agent has no strong reasoning engine | Agent restarts from zero |
The pairing is stronger than either piece alone. M3 reasons over a rich task state, and Mem0 makes sure that task state still exists when the next session begins.
What the Best App Score Means
The Streamlit UI shows a metric called Best app score, and for this demo that number is simulated. It is not claiming that M3 actually improved a production app from 42/100 to 92/100. It is a stand-in for whatever feedback signal your real agent would use.
The reason the score exists is to show the shape of the loop. The agent tries something, a tool returns feedback, the feedback gets stored, and the next M3 decision uses that history. In a real coding agent, you replace the simulated score with an actual command:
Or a more product-specific score:
The demo score is simulated. The memory pattern is real.
What Does an Agent Lose Without Memory Across Sessions?
Long-running agents usually fail quietly. They repeat work, forget why a decision was made, or treat yesterday's result as if it never happened. Across cross-session agent workflows, the information that gets lost falls into five categories.
Previous attempts: The agent tries the same search, refactor, or optimization again because it cannot see that it already happened.
Decision reasoning: The agent remembers the broad goal but loses the reason a specific path was chosen or rejected.
Tool results: Test output, benchmark scores, lint failures, and evaluation notes disappear when they only lived in the previous session.
Task constraints: User preferences like keep the UI simple or change one thing per iteration stop shaping future steps.
Progress state: The next run has no reliable answer to the question of what it should do now.
This is the exact gap Mem0 closes. It stores task memories outside the model context window so the agent can retrieve them before the next M3 call.
Setting Up the Demo
You need two API keys: A MiniMax API key for M3 and a Mem0 API key for memory.
💡To get a MiniMax M3 API key: Go to platform.minimax.io/subscribe/token-plan, click Get API Key, create an account if you do not already have one, and create an API key in the platform. Then export it locally using:
💡To get a Mem0 API key: Create or log into your Mem0 account at app.mem0.ai, create an API key, and export it locally:
Install and run.
Run the Streamlit UI:
Run the Python agent:
Stop it and run it again:
On the second run, the agent recalls prior decisions from Mem0 and continues instead of treating the task as brand new.
💡You can access the complete code on the GitHub repository.
Try It On Your Agent Today!
Run the demo once without memory and once with memory. Without memory, the agent can choose good actions, but it has no durable task history after a restart. With Mem0, the next run starts with the prior decisions already available. That is the difference between an impressive one-session demo and a useful long-running agent.
M3 gives the agent strong next-step reasoning. Mem0 makes the progress durable. Together, they turn start over into continue.
Frequently Asked Questions
Q. Why use Mem0 if M3 has a large context window?
M3's long context is useful for reasoning inside a session. Mem0 is useful for memory across sessions. A large context window does not automatically persist after a restart.
Q. Can MiniMax M3 remember context across sessions?
M3's 1M-token context window holds information within a single session. It does not automatically persist when the agent process restarts. Cross-session memory requires an external layer like Mem0, which stores decisions and outcomes by user_id and retrieves them before the next M3 call.
Q. Is Mem0 free to use with MiniMax M3?
Yes. Mem0 has a free tier at app.mem0.ai with no credit card required, and the demo in this article runs entirely on the free tier. Paid plans are available for production workloads with higher memory limits.
Q. Why does M3 take multiple iterations?
Iterations are not a sign that the model is weak. They are how agentic work usually happens: choose a step, test it, read feedback, then choose the next step. Even strong models benefit from tool feedback.
Q. What should I replace before using this in production?
Replace simulate_benchmark() with real tests or evals. Keep the recall, the M3 reasoning, and the Mem0 write path.
Q. Which MiniMax model does this use?
It uses MiniMax-M3 through MiniMax's official chat completion endpoint at https://api.minimax.io/v1/text/chatcompletion_v2.
Sources
MiniMax M3 model page: https://www.minimax.io/models/text/m3
MiniMax API key page: https://platform.minimax.io/subscribe/token-plan
Mem0 Platform quickstart: https://docs.mem0.ai/platform/quickstart
Complete demo code: https://github.com/aashidutt-mem0/MiniMax-M3-x-Mem0
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

