



You're building something on Claude. It's working. Then usage picks up, you check your bill, and the number is twice what you expected. Token costs compound fast - and if you don't understand exactly how Claude charges for input, output, caching, and long-context requests, you'll keep getting surprised.
This guide breaks down every Claude pricing tier: subscription plans for individuals and teams, API token costs for developers, and the specific mechanics behind caching, batch processing, and tool usage. It also covers where those costs come from at the code level - and what you can do to bring them down.
TL;DR
Individual plans run $0 (Free) → $20/mo (Pro) → $100–$200/mo (Max). Annual Pro billing drops to $17/month.
API pricing starts at $1/M input tokens (Haiku 4.5) and tops out at $50/M output tokens (Claude Fable 5) at standard rates.
Developers building multi-turn agents face the biggest hidden cost: growing conversation history balloons token usage fast. Tools like persistent memory for Claude can cut that by up to 90%.
Anthropic Pricing: Claude App, API, and Console
Anthropic sells access to Claude through two billing surfaces, and knowing which one you're on explains most billing confusion.
Claude app (claude.ai): The consumer chat product for web, desktop, and mobile. Billed through the Free, Pro, Max, Team, or Enterprise subscription plans covered below, at a flat monthly or annual rate rather than per token.
Claude Platform (platform.claude.com), also called the Claude Console: The developer surface for building with the Claude API. This is where you add a payment method, generate API keys, monitor usage, set spend limits, and get billed per token. Note that console.anthropic.com is an older address for the same platform: both point to the same sign-in and dashboard.
A Claude subscription doesn't carry over to the API: they're billed separately, even if you're already paying for Pro or Max. If you're a developer running Claude Code, it's worth checking whether you're on your subscription's usage pool or accidentally billing through an API key, since those are two different meters.
Claude Plan Comparison at a Glance
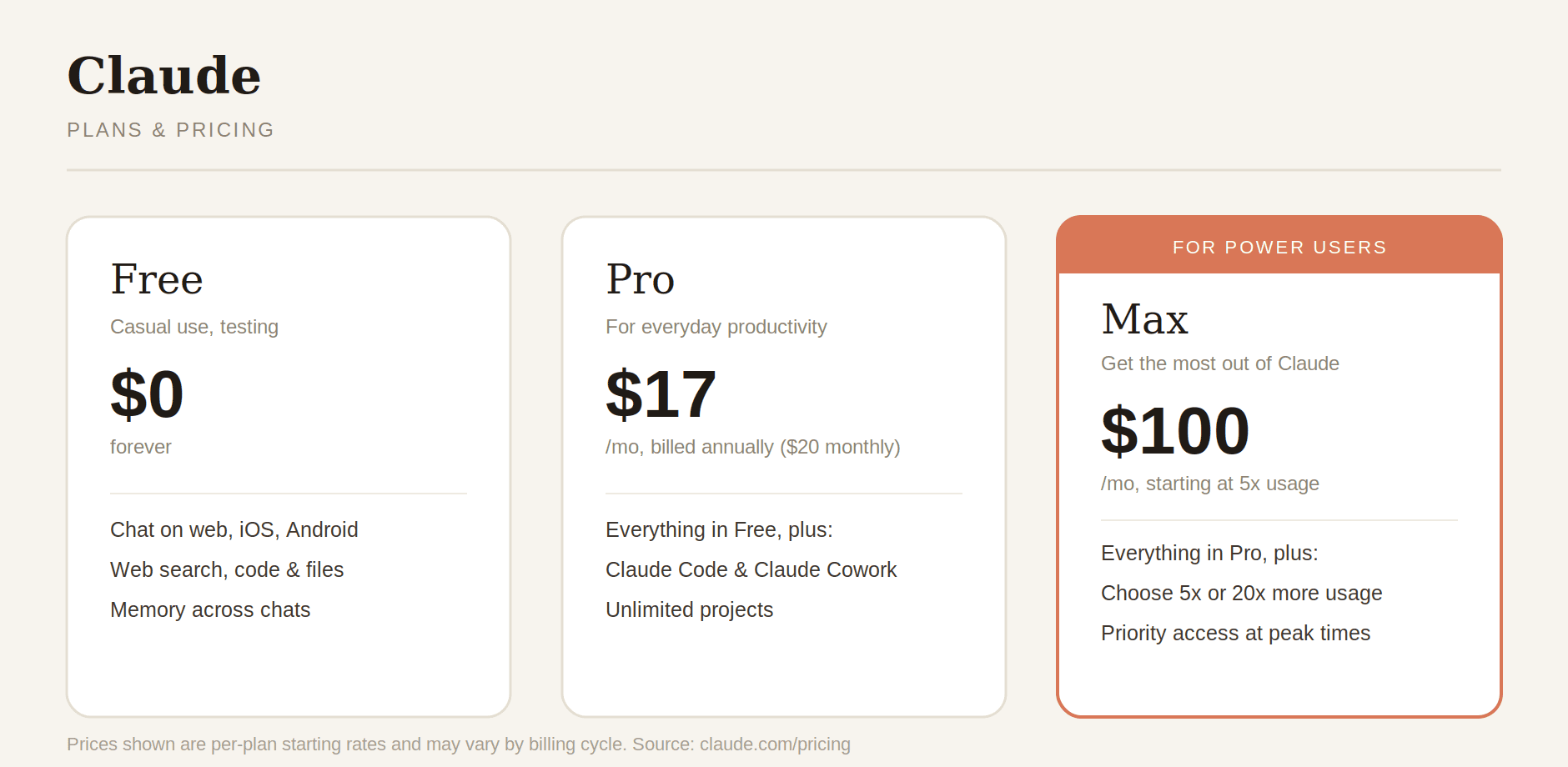
Claude pricing comparison across these plans mostly comes down to how much usage you need and whether you need Claude Code. Free and Pro cover casual-to-daily use at a flat rate, Max scales that same flat-rate model up for heavy individual users, and Team and Enterprise add per-seat billing plus collaboration and compliance features. None of these plans change which Claude models you get access to: they only change how much room you have to use them.
Plan | Price | Best For | Key Limits |
|---|---|---|---|
Free | $0 | Casual use, testing | Rate-limited; no Claude Code |
Pro | $20/mo ($17/mo annual) | Daily power users | Standard usage limits |
Max 5x | $100/mo | Heavy individual users | 5× Pro session capacity |
Max 20x | $200/mo | Extreme power users / agents | 20× Pro session capacity |
Team Standard | $25/seat/mo ($20 annual) | Collaborative teams | Min. 5 seats |
Team Premium | $125/seat/mo ($100 annual) | Engineering teams + Claude Code | Min. 5 seats |
Enterprise | Custom (~$20/seat + API) | Compliance, governance, scale | Annual billing, custom terms |
Why your Claude bill compounds fast
Every conversation re-sends context on each turn. A 10-turn chat with a 50K-token history can create 500K input tokens, most of it repeated context. Mem0 stores durable user and project memory, then retrieves only what matters per request.
Individual Plans
Claude's individual plans are built around usage volume rather than model access: everyone on Free, Pro, or Max gets the same underlying Claude models, just with different session limits and feature sets. Below, we'll walk through what each tier includes and who it makes sense for, from casual testing on Free to running sustained heavy workloads on Max 20x.
Free
The Free plan costs $0: no credit card required. It covers web, iOS, Android, and desktop access with text, image, and code generation, web search, and desktop extensions.
The catch: daily usage limits apply. You'll hit the ceiling quickly if you're doing anything beyond light experimentation.
No Claude Code on Free. If you need the terminal-based coding agent, you'll need Pro or higher.
Pro: $20/month
Pro runs $20/month, or $200/year ($17/month equivalent) on annual billing.
What you get on top of Free:
Higher usage limits (5-hour rolling session window)
Claude Code in the terminal
File creation and code execution
Unlimited Projects
Google Workspace integration
Pro is the right call for daily users who hit Free's limits regularly. If you're a developer who runs Claude Code sessions a few times a week, Pro covers most workflows.
Watch out: if ANTHROPIC_API_KEY is set in your shell, Claude Code bills at API rates: ignoring your subscription entirely.
Max: $100 or $200/month
Max comes in two tiers:
Max 5x: $100/month: 5× the session capacity of Pro
Max 20x: $200/month: 20× the session capacity of Pro
Max isn't a different model tier. It's a bigger bucket. You get the same Claude models as Pro: just more headroom before hitting limits.
Max 20x makes financial sense for heavy users. At current API rates, Sonnet 4.6 costs $3/M input and $15/M output. A daily user burning several million tokens per week can easily exceed $300/month on raw API. The $200 flat rate is often cheaper.
Max plans are monthly-only: no annual discount available as of May 2026.
Team and Enterprise Plans
Team Plan
Team plans require a minimum of 5 seats and come in two tiers:
Standard: $25/seat/month (billed monthly) or $20/seat/month (billed annually)
Premium: $125/seat/month (billed monthly) or $100/seat/month (billed annually)
Standard covers most organizational collaboration needs. Premium adds Claude Code, making it the right choice for engineering teams building with or on top of Claude.
You can mix Standard and Premium seats on the same team: useful if only part of your org needs Claude Code access.
Enterprise Plan
Enterprise is custom-priced, starting around $20/seat/month with API usage billed separately on top.
What Enterprise adds over Team:
HIPAA readiness
SSO and SCIM
Audit logs
Custom data retention
Admin spend limits per user
Token costs are metered directly at standard API rates: there's no included usage in the seat fee. Admins can set per-user spend caps.
Enterprise is the right fit if compliance or procurement is in the room.
Claude API Pricing
Cut your Claude API costs in production
Mem0 retrieves relevant memory instead of re-injecting full conversation history. Use it with Claude to reduce repeated input context while keeping personalization intact.
Model Pricing: Haiku, Sonnet, Opus
All prices are per million tokens (MTok), USD.
Model | Input $/M | Output $/M | Context Window |
|---|---|---|---|
Haiku 4.5 | $1.00 | $5.00 | 200K tokens |
Sonnet 5 | $2.00 (intro, through Aug 31, 2026; $3.00 standard after) | $10.00 (intro; $15.00 standard after) | 1M tokens |
Sonnet 4.6 | $3.00 | $15.00 | 1M tokens |
Opus 4.8 | $5.00 | $25.00 | 1M tokens |
Fable 5 | $10.00 | $50.00 | 1M tokens |
Sonnet 4.6 is the production default for most teams. Best cost-quality balance at $3/$15.
Haiku 4.5 is the budget workhorse: fast, cheap, good for high-volume classification and simple tasks.
Sonnet 4.6 is the production default for most teams. Best cost-quality balance at $3/$15.
Opus 4.8 (released May 28, 2026) is Anthropic's current flagship, designed for complex reasoning and agentic workflows. At $5/$25, it holds the same rate as Opus 4.6 and 4.7 — and still a 67% drop from Opus 4.1's $15/$75. The tokenizer change introduced with Opus 4.7 (up to 35% more tokens for the same text) carries forward into 4.8, so factor this into cost estimates. Opus 4.6 and 4.7 remain available at the same price, though Opus 4.7's fast mode is being removed July 24, 2026.
Prompt Caching
Prompt caching lets you reuse previously processed content: system prompts, documents, and conversation history at a fraction of the standard input price. You pay once to write to cache, then read back at 90% off.
Model | 5-min Cache Write | 1-hour Cache Write | Cache Read |
|---|---|---|---|
Opus | $6.25/M | $10.00/M | $0.50/M |
Sonnet | $3.75/M | $6.00/M | $0.30/M |
Haiku | $1.25/M | $2.00/M | $0.10/M |
Sonnet 5 | $2.50/M | $4.00/M | $0.20/M |
Fable 5 | $12.50/M | $20.00/M | $1.00/M |
For Sonnet 4.6: a system prompt that costs $3.00/M at standard rates drops to $0.30/M on cache reads. The write surcharge pays for itself after just a few requests.
Two TTL options: 5-minute (default) and 1-hour (extended caching, higher write cost).
Batch Processing
The Batch API processes requests asynchronously within a 24-hour window in exchange for a flat 50% discount on all input and output tokens: across every Claude model.
At batch pricing:
Sonnet 4.6: $1.50 input / $7.50 output per million tokens
Haiku 4.5: $0.50 input / $2.50 output per million tokens
Sonnet 5 (intro): $1.00 input / $5.00 output per million tokens
Ideal for content generation, data classification, document analysis, and any workload where real-time responses aren't required.
Tools and Extras
Feature | Price |
|---|---|
Web search | $10 / 1,000 searches |
Code execution | $0.05/hour (1,550 free hours/month) |
Fast mode (Opus 4.8) | 2× standard rates |
US-only inference | 1.1× standard input + output rates |
How to Choose the Right Claude Plan
Casual user: light daily use, no coding agents → Free or Pro ($20/mo)
Power user: daily heavy sessions, Claude Code, multi-step workflows → Max 5x ($100/mo)
Extreme power user: running Agent Teams, 300M+ tokens/month → Max 20x ($200/mo) is often cheaper than raw API
Team without Claude Code → Team Standard ($20/seat/mo annual)
Engineering team with Claude Code → Team Premium ($100/seat/mo annual)
Compliance-sensitive org (HIPAA, SSO, audit logs, 500K context) → Enterprise
Developer building a product → API directly: pay per token, use Batch API + prompt caching to control costs
One thing to check before subscribing: if you're a developer, confirm whether you're hitting your plan's session limits or whether you're accidentally billing via API key. These are two completely different billing paths.
How Does Claude API Pricing Compare to GPT and Gemini?
Here's how Claude Sonnet 4.6 stacks up against the closest competitors at the mid-tier:
Model | Input $/M | Output $/M | Context Window |
|---|---|---|---|
Claude Sonnet 5 | $2.00 | $10.00 | 1M tokens |
GPT-4.1 | $2.00 | $8.00 | 1M tokens |
Gemini 2.5 Pro | $1.25 | $10.00 | 1M tokens |
At the flagship tier:
Model | Input $/M | Output $/M | Context Window |
|---|---|---|---|
Claude Opus 4.8 (latest) | $5.00 | $25.00 | 1M tokens |
Claude Opus 4.6 | $5.00 | $25.00 | 1M tokens |
GPT-5.5 | $5.00 | $30.00 | 128K tokens |
Gemini 3.1 Pro | $2.00 | $12.00 | 1M tokens |
Raw list price: Claude isn't the cheapest option. GPT-4.1 at $2/$8 and Gemini 2.5 Pro at $1.25/$10 undercut Sonnet on paper.
Where Claude competes: prompt caching is more aggressive than OpenAI's (90% off cache reads vs ~50% for most OpenAI models, though rates vary by model and may have changed; verify at openai.com/api/pricing). For applications with repeated system prompts or long documents, effective Claude costs can drop well below list price. Anthropic's 1M context window also means fewer chunking workarounds compared to models with smaller windows.
How to Cut Claude API Costs with Memory
Here's the problem most developers hit at scale: multi-turn conversations get expensive fast.
Every time a user sends a message, the full conversation history goes back into the context window. A 20-turn conversation might carry 15,000+ tokens of history on every single request: tokens you're paying for repeatedly, even though most of that history is redundant.
This is token bloat. And it compounds. By turn 50, you're sending 40,000+ tokens of context just to answer a simple follow-up question.
Prompt caching helps, but it doesn't solve the root problem. Cache TTLs expire. Long conversations overflow cache boundaries. And you're still paying write costs on every cache refresh.
The cleaner fix: replace raw conversation history with compressed memory. Instead of replaying the full transcript, you store a structured summary of what matters: user preferences, prior decisions, key facts: and inject only that into each new request.
Mem0's persistent memory infrastructure does exactly this for Claude. It sits between your application and the Claude API, automatically extracting and compressing relevant context. In production deployments, this approach reduces token usage by up to 90% compared to naive full-history injection.
The math is straightforward. If you're spending $500/month on Sonnet 4.6 API calls and 60% of that is redundant conversation history, a 90% reduction on that portion saves ~$270/month: before you've changed a single model or prompt.
💡 Building with Claude?
Mem0 cuts token costs by up to 90% by replacing full conversation history with compressed memory. Works with Claude's API out of the box: no prompt engineering required.
Start free: 50 memories, no credit card. → persistent memory infrastructure
Building with Claude in production? The fastest way to reduce repeated API spend is to stop sending the same context every turn. Read: how to reduce LLM token costs →
FAQ
What is the cheapest way to use Claude?
The cheapest way is the Free plan at $0: no credit card needed. For API access, Haiku 4.5 is the most affordable model at $1/M input and $5/M output tokens. Combine it with the Batch API (50% off) for async workloads and you're looking at $0.50/$2.50 per million tokens: the lowest Claude API rate available.
Is Claude Pro worth $20/month?
For daily users who regularly hit Free's rate limits, yes. Pro gives you higher session capacity, Claude Code, file creation, code execution, and Google Workspace integration. The annual plan at $200/year ($17/month) makes it even more cost-effective. If you're only using Claude a few times a week, Free may be sufficient.
What's the difference between Max 5x and Max 20x?
Both Max tiers give you access to the same Claude models as Pro. The difference is session capacity: Max 5x gives you 5× Pro's per-session limit, Max 20x gives you 20×. Neither is a model upgrade: they're larger usage buckets. Max 20x at $200/month is aimed at users running Agent Teams or sustained heavy workloads where the flat rate beats pay-per-token API billing.
How much does Claude API cost for a heavy user?
It depends on model and volume. A developer sending 10 million tokens/day on Sonnet 4.6 at a 50/50 input/output mix would spend roughly $90/day at standard rates ($3/M input × 5M + $15/M output × 5M). With prompt caching on repeated system prompts and Batch API for async jobs, effective costs can drop by 50–90%. For very high-volume workloads, Anthropic offers volume discounts: contact their sales team.
Does Claude have a free API tier?
The Claude API has no ongoing free tier. However, new users may receive a small amount of free starter credits on signup. After those are used, it's pay-as-you-go: you'll need to add a payment method. The free claude.ai product is separate from the API and doesn't include API access.
What is prompt caching and how much does it save?
Prompt caching stores reusable content: system prompts, documents, conversation history, so you pay full price once, then 90% less on subsequent reads. For Sonnet 4.6, cached reads cost $0.30/M instead of $3.00/M. There's a small write surcharge (25% above standard input price), but it pays for itself after just a few cache hits. Most impactful for apps with consistent system prompts or large repeated context.
Is "Anthropic pricing" the same thing as "Claude pricing"?
Not exactly. "Claude pricing" usually refers to the consumer subscription plans (Free, Pro, Max, Team, Enterprise) billed through the Claude app at claude.ai. "Anthropic pricing" is the broader term that also covers Claude API token rates, billed separately through the Claude Platform at platform.claude.com. In practice, people use both terms interchangeably, but if you're trying to find the right rate card, it helps to know whether you mean the app subscription or the API.
Useful Sources
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

