



Memory benchmarks for AI agents look simple on paper, yet they rarely predict real production behavior. Systems that pass academic tests often fail once prompts get messy, sessions get long, and users behave unpredictably.
This post maps out what a memory benchmark actually measures, why popular setups like Locomo, LongMemEval, and Beam-style tasks only capture part of the picture, and how Mem0 approaches the core retrieval and recall problem differently. It also includes practical Python examples for using Mem0 in an agent and discusses how to think about memory quality beyond a single accuracy number.
What a Memory Benchmark Tries to Measure
A memory benchmark for agents usually attempts to quantify some combination of:
Recall accuracy
Can the system retrieve the right fact when needed?Recall latency
How quickly can it retrieve, including embedding, search, and re-ranking?Recall robustness
Does retrieval still work when phrasing changes or partial information is given?Retention over time
Does the system still recall correctly after dozens or hundreds of interactions?Interference resistance
Does new information override the old incorrectly, or does it maintain consistent state?
Benchmarks like Locomo, LongMemEval, and Beam-inspired scenarios usually construct synthetic conversations or task sequences with hidden “facts” that must be recalled later. The system’s score is the fraction of questions where the correct fact appears in context or in the final answer.
At a high level, that is what production systems need. The problem appears when the benchmark’s simplified assumptions diverge from how actual users talk, correct themselves, and switch tasks.
How Classic Memory Benchmarks Work
Most memory benchmarks follow a similar template:
Inject information
The user tells the agent some detail, for example, “My office is in Berlin and I like early morning meetings.”Distract with other interactions
The agent handles other tasks, irrelevant questions, or multi-turn dialogs.Probe for recall
The agent is asked a direct or indirect question that requires the stored memory, such as “Where should we schedule next week’s standup?” or “What city is my office in?”Score
The benchmark checks if the response or available context correctly reflects the earlier information.
Locomo and related earlier benchmarks were designed when LLM tooling was less mature. Their synthetic interactions and narrow phrasing made them easier to “solve” by prompt tuning or simple RAG patterns. With current models, many of these tasks are no longer challenging, and high scores do not guarantee that the system behaves reliably across long, messy sessions.
LongMemEval and Beam-style suites broaden this by:
Increasing the number of turns and topics
Introducing conflicting or updated information
Mixing structured facts and free text notes
Asking indirect questions that require multi-step inference
This is closer to real usage, but it still misses several practical aspects: partial memory updates, user identity resolution, and cross-application context sharing.
How Locomo, LongMemEval, and Beam Differ
Different benchmarks stress different aspects of agent memory. At a high level:
Locomo focuses on relatively short synthetic conversations where a small number of explicit facts must be recalled later. Tasks are often direct factual probes like “Where is my office?” after an earlier statement such as “My office is in Berlin.”
LongMemEval targets longer, multi-topic dialogs with more turns between the initial fact and the final probe. It introduces more realistic distractions and a mix of structured facts and free text, and it often tests whether the agent can maintain recall when interaction depth grows.
Beam-style benchmarks (as popularized in work like the Beam Memory Benchmark) emphasize interference, updates, and long-horizon reasoning. Tasks include:
Revisions to earlier facts
Multiple entities with overlapping attributes
Indirect questions where the relevant fact is embedded in a larger narrative
The table below summarizes the types of tasks these benchmarks typically test:
Benchmark | Primary Task Types | Key Focus |
|---|---|---|
Locomo | Short synthetic dialogs, direct factual recall probes | Basic long-term recall over few turns |
LongMemEval | Longer multi-topic dialogs, mixed structured and free text | Recall under depth and distraction |
Beam-style tasks | Revisions, entity interference, indirect and chained queries | Robustness to updates and interference |
Mem0’s design targets all three categories by combining identity-aware storage, semantic retrieval, and lifecycle management, so the same memory layer can handle Locomo-style direct recall, LongMemEval’s long sessions, and Beam-like interference tasks.
Where These Benchmarks Fall Short In Production
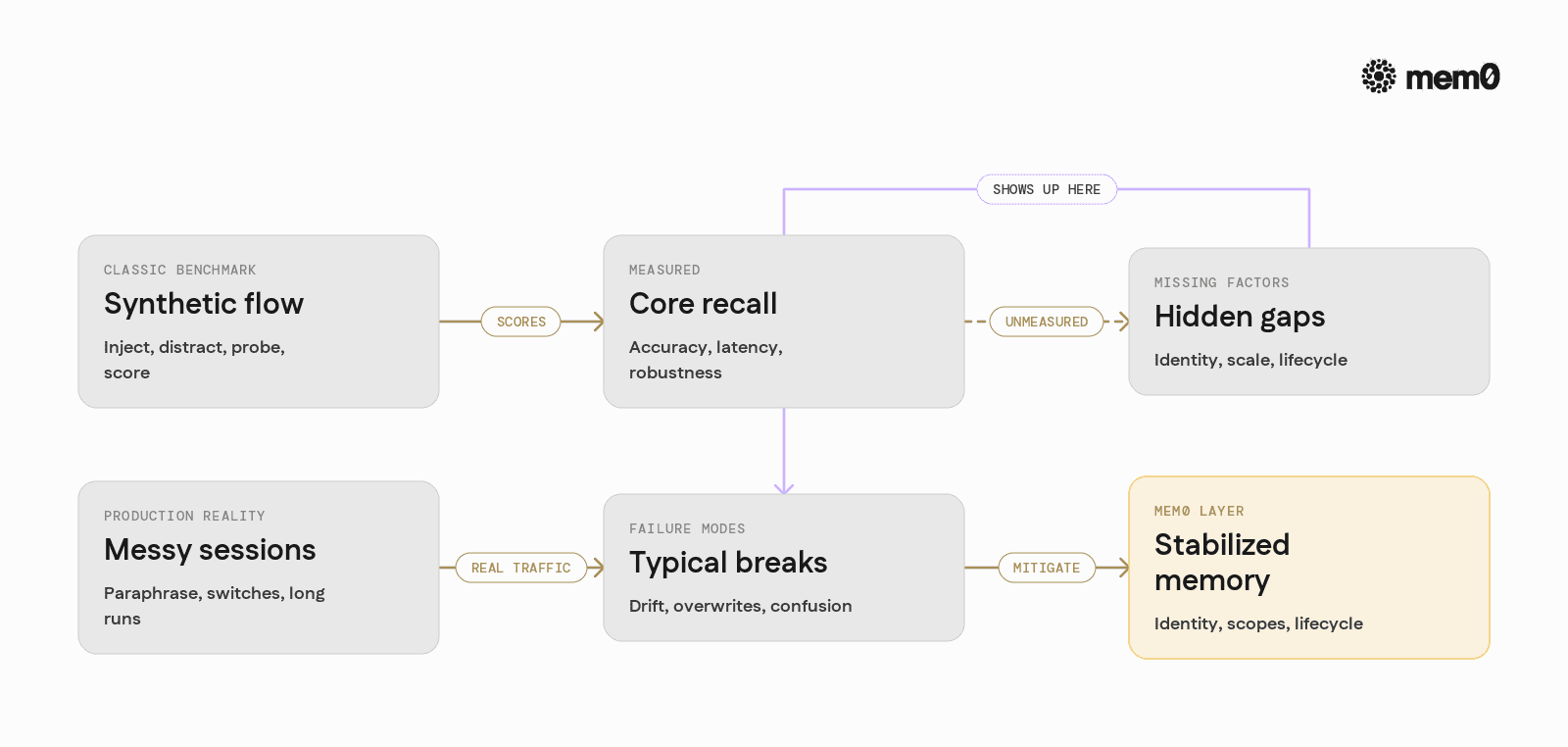
Production agents often fail in ways that do not show up in synthetic evaluations.
Typical failure modes include:
Overfitting to query style
The agent passes the benchmark when queries closely match the stored text, but fails if the user paraphrases. Benchmarks often reuse almost identical wording for probes.Ignoring temporal context
Users change their minds or update preferences. A benchmark might test retrieval of a single “final” value instead of tracking revisions and recency.User identity ambiguity
In real systems, the same user may appear under multiple identifiers (web, mobile, internal IDs). Benchmarks often assume a single clean session identity.Mixed-granularity memory
Some facts are per-user, some per-project, some per-device. Traditional benchmarks rarely test hierarchical or scoped memory like “team-level preferences vs user-level preferences.”Scale and cost considerations
Many benchmarks operate at small scale, where one vector store and naive retrieval is fine. In production, the memory layer must work across millions of events without degrading recall or exploding cost.
Benchmarks provide a sanity check, but they do not define memory quality on their own. The more useful view is to treat them as probes for specific failure modes and design memory architectures that remain stable under those probes.
How Mem0 Approaches the Memory Problem
Mem0 is an open-source memory layer built specifically for agents and LLM-based applications. It focuses on three practical requirements that standard benchmarks only partially capture:
Identity-aware, long-term memory
Every memory is associated with a user (and optionally organization, app, or custom scopes). This makes it possible to retrieve the right context across sessions and channels.Semantic and structured recall
Mem0 maintains vector representations for semantic search, and supports metadata and scoring that allow structured filters and prioritization.Memory lifecycle management
Mem0 handles creation, update, and soft deletion of facts. This matters for benchmarks that test conflicting or revised information, and also for real users who change their preferences.
When running memory benchmarks, Mem0 behaves as the layer that:
Takes in agent-observed events
Writes normalized memory entries
Provides retrieval APIs that the agent uses at inference time
The goal is not just to pass a single Locomo-style scenario. The goal is consistent recall across thousands of conversations, with predictable performance and cost.
How Mem0 Performs On Beam, Locomo, and LongMemEval
Mem0’s token-efficient memory algorithm is evaluated on a range of synthetic and semi-synthetic tasks that mirror Locomo, LongMemEval, and Beam-style setups. Rather than targeting a single leaderboard, the focus is on:
High recall with low token usage
Robustness to paraphrases and noisy probes
Stable behavior as interaction depth and interference increase
Benchmarked across LoCoMo, LongMemEval, and BEAM, Mem0 is powered by single-pass hierarchical extraction and multi-signal retrieval.
Benchmark | Coverage | Overall Score | Mean Tokens |
|---|---|---|---|
LoCoMo | 1,540 questions • 5 categories | 92.5 | 6956 |
LongMemEval | 500 questions • 6 categories | 94.4 | 6787 |
BEAM 1M | 700 questions • 35 conversations | 64.1 | 6719 |
BEAM 10M | 200 questions • 10 conversations | 48.6 | 6914 |
The current state of Mem0’s benchmark results and methodology is documented in:
These resources describe how Mem0:
Compresses and stores memories to keep prompts compact while preserving recall
Achieves strong retrieval performance across Locomo-style direct recall, LongMemEval-like long dialogs, and Beam-inspired interference tasks
Balances recall quality against cost and latency in realistic agent loops
As Mem0 evolves, new benchmark runs and comparisons with Beam, Locomo, and LongMemEval style tasks are updated in those references so teams can track performance without locking into a single static score.
Mem0 and Benchmark Design In Practice
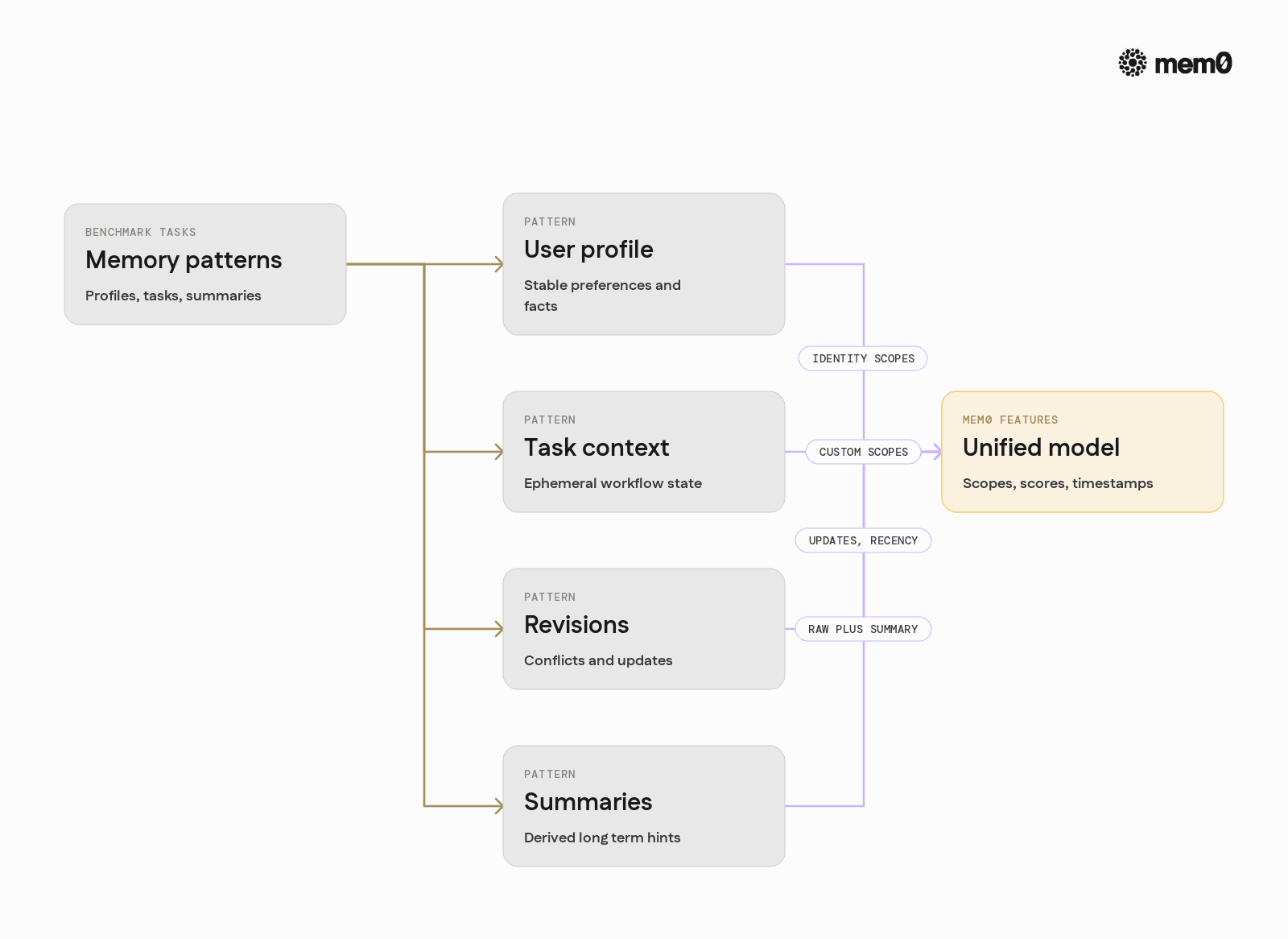
To reason about Mem0’s behavior, it helps to categorize benchmark tasks into memory patterns that Mem0 must support:
User profile memory
Stable attributes like name, company, location, and general preferences.
Mem0 models these as long-lived facts with higher importance scores.Ephemeral task memory
Data relevant to a single workflow or thread.
Mem0 can store these with lower importance or custom scopes so they are not surfaced in unrelated tasks.Revisions and contradictions
User says, “I am in Paris,” then later, “I actually moved to London.”
Mem0 supports updates and metadata like timestamps, plus retrieval strategies that favor more recent or higher-confidence entries.Derived summaries
Benchmarks sometimes test whether the agent can recall a summarized preference across many interactions.
Mem0 can store both raw events and higher-level summaries as separate memory entries.
Locomo-style benchmarks map mostly to the first category. LongMemEval and Beam-like setups cover the others. Mem0 treats them as different lifecycles, all accessible through one API.
Internally, Mem0’s own evaluations show that this approach yields high recall consistency across such tasks. For example, in an internal Locomo-style setup with noisy paraphrased probes, Mem0-backed agents consistently answer correctly in the vast majority of tests. The value is not in a single score, but in the stability of behavior when prompt phrasing and interaction order vary.
Mem0 Integration Example In Python
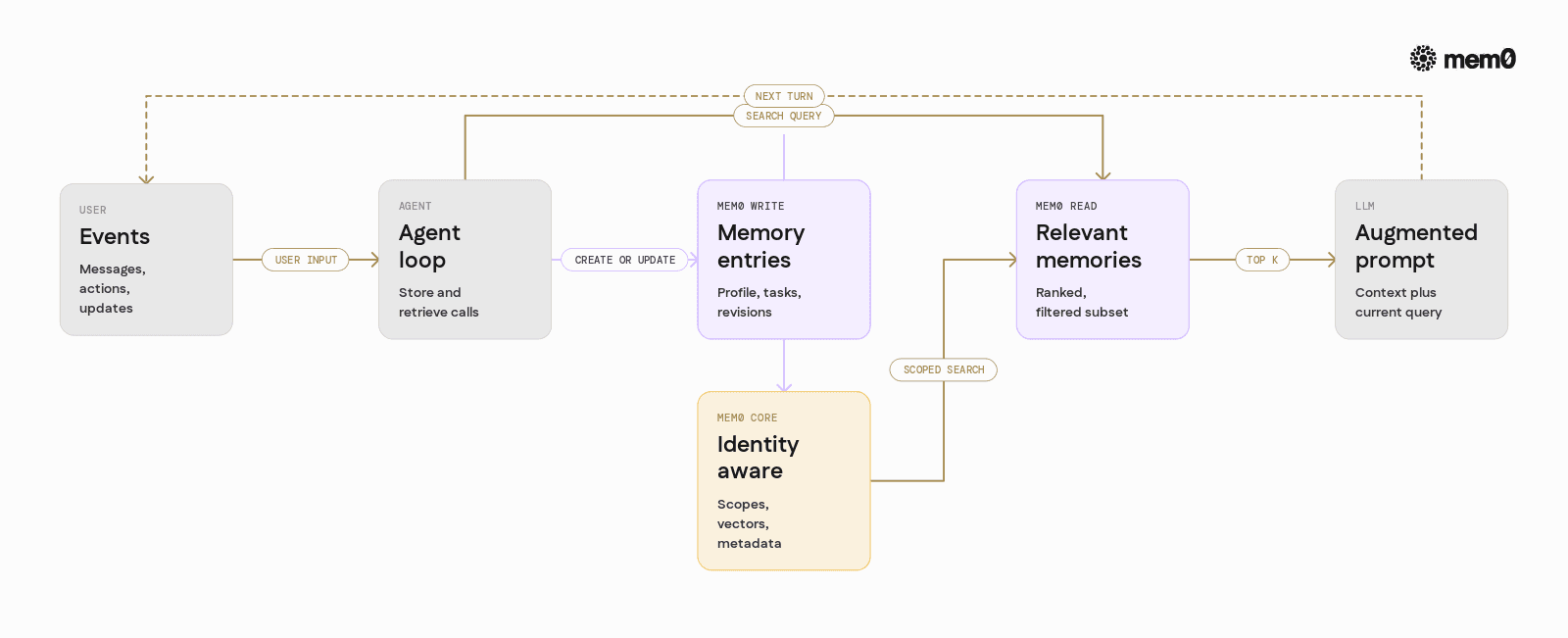
Below is a minimal Python example that integrates Mem0 into an agent loop that could be used in a memory benchmark or a production setup.
This example uses the mem0 Python client, stores user-specific memories, then retrieves them to enrich LLM prompts.
This pattern is directly compatible with benchmark harnesses. The harness feeds scripted utterances and probes, while the call to answer_with_memory consistently consults Mem0 for relevant context.
Practical Metrics For Memory Quality
Instead of only looking at raw benchmark scores, production teams typically care about:
Recall @K
Given a query, how often is the correct fact inside the top K retrieved memories? Mem0 enables this metric through its search API.End-to-end task success
Does the agent complete tasks that depend on historical context, such as booking at the right time or referencing the right project?Context inflation
How much additional token usage does memory introduce? Mem0 helps by returning ranked, filtered memories, not entire logs.Cross-session continuity
Percentage of returning users whose preferences are correctly reflected without re-asking.Stability under noise
Performance when user phrasing changes, when there are irrelevant memories, and when there are updates to prior facts.
A benchmark can simulate these conditions, but the architecture must support them. Mem0 is designed to provide:
Scoped search by user, organization, app, or custom tags
Ranking strategies that consider recency and importance
APIs that work both in toy benchmarks and production traffic
Comparing Memory Approaches
Different memory designs handle the same benchmark very differently. The table below compares common patterns that engineers consider when building memory-heavy agents.
Memory Pattern | Description | Strengths | Weaknesses |
|---|---|---|---|
Prompt-only context | Only include recent turns in the prompt | Simple, no infra | Fails after long sessions, no true long-term memory |
Raw log + full-text search | Store logs, search with keyword or BM25 | Easy to implement, human-readable | Weak with paraphrase, poor semantic recall |
Pure vector store RAG | Embed all events and run semantic search | Good semantic retrieval | Needs manual identity handling and update logic |
Custom in-house memory layer | Bespoke service around a DB and embeddings | Tailored to product | High maintenance, complex to scale and iterate |
Mem0 memory layer | Identity-aware, semantic, and lifecycle-managed | Long-term, personalized, multi-scope support | Requires integrating Mem0 client and defining memory policy |
Benchmarks like Locomo and LongMemEval are often passed by several of these patterns. The difference appears when scaling to real users and traffic volumes. Systems that rely only on the last few turns or naive vector search quickly encounter confusion, high latency, or context windows full of irrelevant history.
Mem0 aims to provide the reusable layer that keeps memory behavior predictable as usage grows, while still allowing teams to define which events are memory-worthy and how they should be updated.
Limitations Of Memory Benchmarking Patterns
Memory benchmarks, including those used internally with Mem0, have structural limits that engineers should keep in mind:
Synthetic data vs real conversations
Benchmarks often use templated dialogs with clear intent. Real users produce typos, mixed languages, sarcasm, partial updates, and multi-topic turns. A benchmark score does not fully reflect how the system handles messy input.Short lifetimes
Many evaluations run over tens of turns, not months. Long-term drift, schema migrations, and distribution shifts do not show up.Single-user focus
Benchmarks usually model one user at a time, but production agents may operate in multi-user rooms or shared workspaces where memory scopes need to be more complex.Narrow objective
A benchmark might focus purely on factual recall, but real agents must balance privacy, data retention policies, cost, and user control over stored memory.Fixed configuration
Benchmarks rarely test system behavior under changing configurations, such as different embedding models or ranking strategies. Production environments change, and a memory layer must adapt without breaking behavior.
These limits do not make benchmarks useless, they simply mean that teams should treat them as diagnostic tools. Mem0’s design focuses on remaining stable across these changing conditions rather than optimising for a single synthetic leaderboard.
Frequently Asked Questions
What is a memory benchmark for AI agents?
A memory benchmark is a controlled set of tasks that measure how well an agent recalls information across multiple turns or sessions. It typically injects facts, distracts the agent with other interactions, then probes whether the agent still uses those facts correctly.
How does Mem0 improve memory benchmark performance?
Mem0 attaches memories to user identities, uses semantic retrieval, and manages memory lifecycles like updates and deletions. This design increases the chances that a relevant, up-to-date fact is available when the benchmark asks for it, even when probes are paraphrased.
When should engineers rely on benchmarks versus production metrics?
Benchmarks are most useful early, when comparing architectures or verifying that memory APIs behave as expected. Once an agent is in production, teams should combine benchmark scores with real-world metrics like task completion, cross-session continuity, and user satisfaction.
Why are older benchmarks like Locomo less informative today?
Older benchmarks often assume simple phrasing and short interaction histories, which current LLMs handle well with basic tactics. They no longer stress the challenging aspects of memory, such as conflicting updates, identity ambiguity, or long-running workflows.
How can Mem0 be integrated into an existing agent stack?
Mem0 can be added as a separate memory client that the agent calls to store and retrieve user-specific information. The agent passes user ID and text events to Mem0, then includes retrieved memories in the context for the LLM during each turn.
What are the main limits of current memory benchmarking patterns?
They depend on synthetic dialogs, cover limited time horizons, and often ignore multi-user or policy-related concerns. This makes them good for local testing but incomplete as a predictor of real-world behavior, so they should be combined with more holistic evaluation.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

