



Most AI agent memory systems retrieve information by maximizing context window size. That works on benchmarks but does not work in production, where every token adds cost. Token efficiency means achieving high accuracy with less context per query.
Our new memory algorithm, benchmarked across LoCoMo, LongMemEval, and BEAM, achieves competitive accuracy while using under 7,000 tokens per retrieval call. For comparison, full-context approaches on these benchmarks routinely consume 25,000+ tokens per query.
The new algorithm is available today on both the Mem0 platform and the open-source SDK.
Mem0 new algorithm summary (April 2026)
Benchmark | Old Algorithm | New Algorithm | Average tokens / query |
|---|---|---|---|
LoCoMo | 71.4 | 92.5 | 6,956 |
LongMemEval | 67.8 | 94.4 | 6,787 |
BEAM (1M) | — | 64.1 | 6,719 |
BEAM (10M) | — | 48.6 | 6,914 |
Building agent memory that works in practice
Getting memory right means solving three problems at once: extraction, retrieval, and reasoning. Most systems only optimize retrieval, which is why they plateau. The dominant framing in this space (store, embed, retrieve) does not capture what a memory system deployed against millions of real interactions has to do. Two examples shaped the architecture decisions in this release:
Consider a user who orders from the same Thai restaurant every Friday for two months. A retrieval system stores eight records of "Ordered pad thai on Friday" and can tell you exactly what happened on March 8th. If you ask where to book a dinner reservation for this user, it has nothing to offer. A good memory system should have figured out weeks ago that this person loves Thai food and has a go-to Friday night spot.
Or consider a user whose profile says they live in New York. Six months later, new data indicates they have moved to San Francisco. Most memory systems treat change as replacement: the old fact gets overwritten. But knowing that a user moved from New York to San Francisco is more valuable than just knowing their current city. A system that actually understands context should retain both facts, understand there was a transition, and know that references to "your old neighborhood" point to New York while "your current location" means San Francisco.
This release advances Mem0 toward a unified memory system where extraction, retrieval, and reasoning work together rather than as independent stages.
Our approach: hierarchical memory
Retrieval scores all layers in parallel and fuses the results. A question like "what does Alice think about remote work?" leans on entity matching. "What meetings did I have last week?" depends on temporal understanding. "How has the user's attitude toward this project shifted?" requires higher-order reasoning across many scattered memories.
This release ships entity-level matching on top of existing sentence-level retrieval. We plan to add behavioral pattern matching next.
Extraction and retrieval run asynchronously, so agents are not burning cycles managing their own context.
What changed
Single-pass, ADD-only extraction
The old algorithm extracted memories in two LLM passes. The first identified candidate facts from the input. The second reconciled those facts against existing memories using ADD, UPDATE, and DELETE operations. That reconciliation step was slow, and it was where context got destroyed. Overwrites sometimes erased key information from the original fact. Deletes sometimes removed information that would be relevant later.
Generally, memory systems treat changes as replacements. When something new happens, the old fact gets overwritten, which throws away information. ADD-only extraction preserves the full history of state changes, so the system can reason about how things evolved, not just where they landed.
The new algorithm collapses extraction into a single LLM call that only adds. Every extracted fact becomes an independent record. When information changes, the new fact lives alongside the old one, and both survive. This cuts extraction latency roughly in half and produces better memories, because the model spends its capacity on understanding the input rather than diffing against existing state.
Agent-generated facts are now first-class
Mem0 now treats agent-generated facts as first-class. Previously, when an agent said something like "I've booked your flight for March 3," the old system would often ignore it entirely and focus only on what the user explicitly stated.
The new algorithm stores agent-generated facts like confirming an action or providing a recommendation, with equal weight, closing a significant gap in memory coverage.
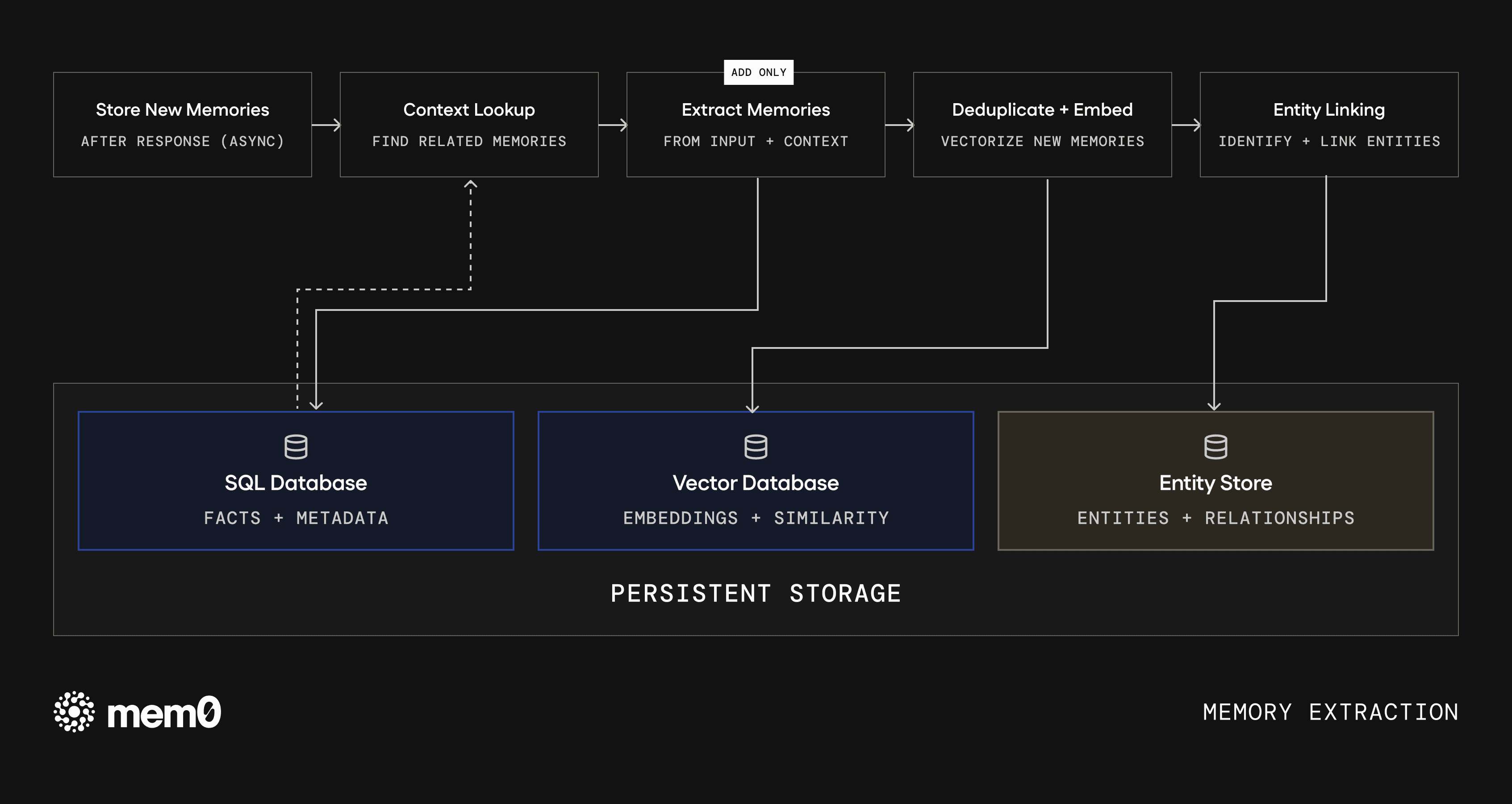
Fig 1: Memory extraction. Input flows through context lookup, single-pass extraction, deduplication, and entity linking before being written to persistent storage.
Entity linking
Every memory is now analyzed for entities, including proper nouns, quoted text, and compound noun phrases. These entities are embedded and stored in a separate lookup layer, linking memories about the same person, place, or concept. At query time, entities identified from the query are matched against this layer, and relevant memories receive a ranking boost.
Multi-signal retrieval
The retrieval stack runs three scoring passes in parallel, semantic similarity, keyword matching, and entity matching, and fuses the results. Different queries lean on different signals, and the combined score outperforms individual signal scores.
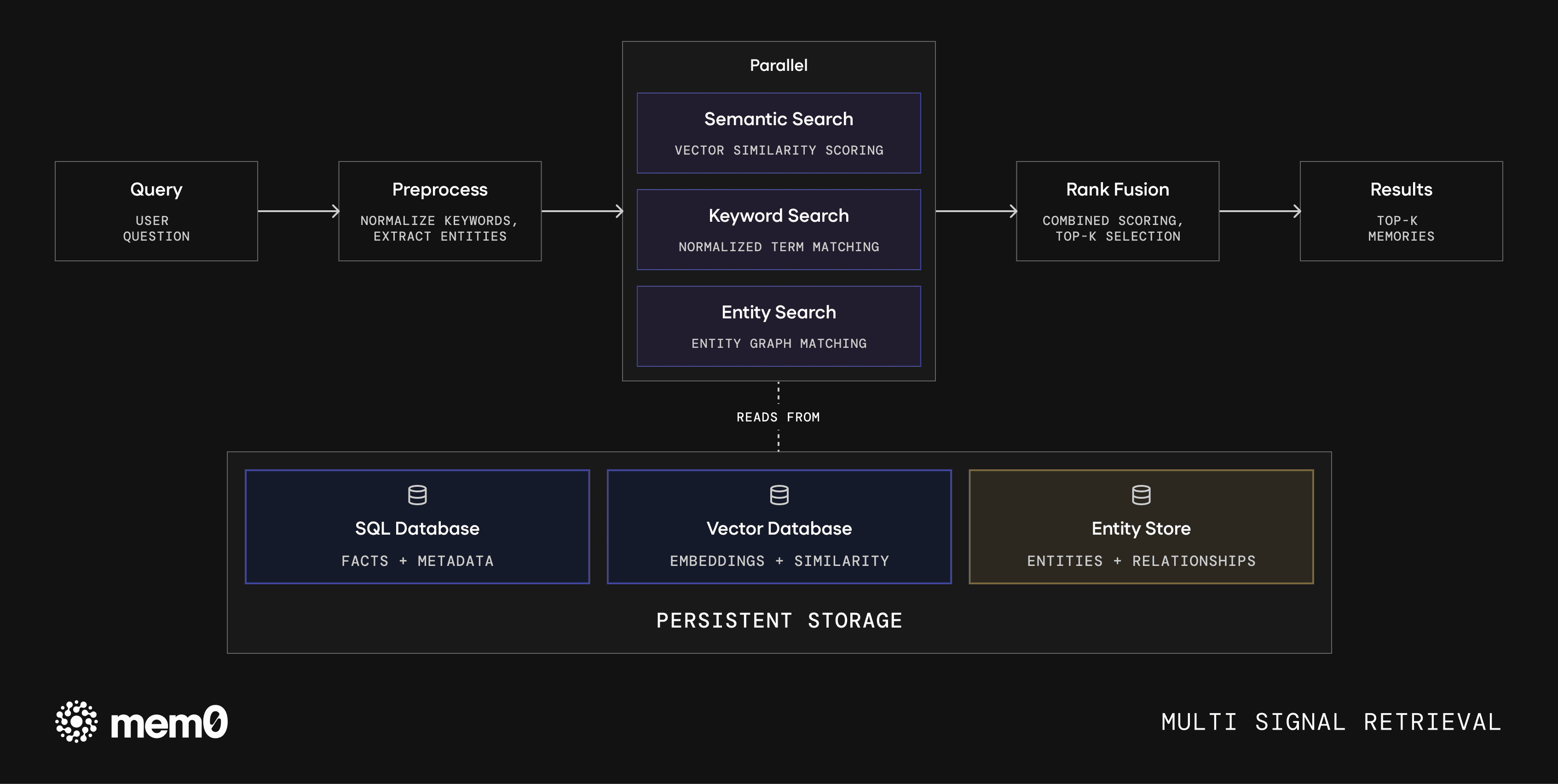
Fig 2: Multi-signal retrieval stack. Queries are preprocessed and scored in parallel across semantic, keyword, and entity signals, then fused via rank scoring.
Keyword normalization
Queries like "what meetings did I attend?" were failing to match memories containing "attending a meeting" because the keyword search treated conjugation variants as different tokens. Verb form normalization fixes this. This is a small change with measurable impact.
Results
All results compare the old algorithm against the new one, using a single-pass retrieval setup: one retrieval call, one answer, no agentic loops. Scores carry a ±1 point confidence interval due to judge inconsistency.
Scores reflect Mem0's managed platform, which includes proprietary optimizations not available in the open-source SDK. Open-source users should expect directionally similar gains but not identical numbers. The full evaluation framework is open-source so anyone can reproduce the numbers independently.
How to interpret these numbers
Evaluating a memory system at scale comes down to three parameters: accuracy (what the benchmarks measure), cost (context tokens per query), and performance (latency). Optimizing one of them is easy, but balancing all three at scale is the actual problem.
Some benchmarks today, particularly smaller ones like LoCoMo and LongMemEval, can be materially improved by aggressive retrieval strategies, larger context windows, or frontier models. That does not necessarily mean the underlying memory system has gotten better. Our goal was to test under constraints that reflect how memory systems actually run in production: limited context windows and practical token budgets.
BEAM is the most relevant benchmark here. It operates at 1M and 10M token scales and cannot be solved by simply expanding the context window. The results at 10M reflect where memory systems actually stand at production context volumes.
LoCoMo
LoCoMo tests single-hop, multi-hop, open-domain, and temporal memory recall across conversational sessions.
Mem0 new algorithm results on LoCoMo (April 2026):
Category | Old Algorithm | New Algorithm | Delta |
|---|---|---|---|
Overall | 71.4 | 92.5 | +21.1 |
Single-hop | 76.6 | 94.6 | +18.0 |
Multi-hop | 70.2 | 95.4 | +25.2 |
Open-domain | 57.3 | 82.3 | +25.0 |
Temporal | 63.2 | 92.5 | +29.3 |
Mean tokens: 6,956
The two biggest gains are on temporal queries (+29.3) and multi-hop reasoning (+25.2). For a developer, this means the new algorithm handles questions like "when did the user first mention X?" or "what led to the user's current decision?" much more reliably. Both categories directly test the ADD-only architecture and the entity linking layer.
LongMemEval
LongMemEval evaluates memory across single-session and multi-session contexts, including knowledge updates and temporal reasoning.
Mem0 new algorithm results on LongMemEval (April 2026):
Category | Old Algorithm | New Algorithm | Delta |
|---|---|---|---|
Overall | 67.8 | 94.4 | +26.6 |
Single-session (user) | 94.3 | 98.6 | +4.3 |
Single-session (assistant) | 46.4 | 98.2 | +51.8 |
Single-session (preference) | 76.7 | 96.7 | +20.0 |
Knowledge update | 79.5 | 93.6 | +14.1 |
Temporal reasoning | 51.1 | 97.0 | +45.9 |
Multi-session | 70.7 | 88.0 | +17.3 |
Mean tokens: 6,787
The biggest gains are on single-session assistant recall (+51.8), temporal reasoning (+45.9), and single-session preference recall (+20.0). The jump on assistant memory recall means the new system reliably remembers things your agent said. That is the kind of thing developers assume will just work until they actually test it. The old algorithm had a blind spot for agent-generated facts that the new one does not. Knowledge update and multi-session recall also improved meaningfully (+14.1 and +17.3), though they trail the top three categories.
BEAM
BEAM evaluates memory systems at 1M and 10M token scales across ten task categories, including preference following, temporal reasoning, and contradiction resolution. It is the only public benchmark that operates at context volumes production AI agents actually encounter.
Mem0 new algorithm results on BEAM (April 2026):
Category | 1M | 10M |
|---|---|---|
Overall | 64.1 | 48.6 |
preference_following | 88.3 | 90.4 |
instruction_following | 85.2 | 82.5 |
information_extraction | 70.0 | 56.3 |
knowledge_update | 65.0 | 75.0 |
multi_session_reasoning | 65.2 | 26.1 |
summarization | 63.5 | 46.9 |
temporal_reasoning | 61.8 | 16.3 |
event_ordering | 53.6 | 20.2 |
abstention | 52.5 | 40.0 |
contradiction_resolution | 35.7 | 32.5 |
Mean tokens (1M): 6,719 Mean tokens (10M): 6,914
Performance is meaningfully stronger at 1M than at 10M. At 10M scale, retrieval gets harder because similar content appears multiple times across the window, and the memory system cannot always surface the exact correct memory over other close matches.
Looking at the category breakdown, the system holds up well on preference following, instruction following, and knowledge updates at both scales. These tasks benefit from the ADD-only architecture retaining state cleanly over long horizons. The weaker categories at 10M are temporal reasoning, event ordering, and multi-session reasoning. These are open problems across the field. Fact-level and entity-level matching are not sufficient for them. They require higher-order representations of how events relate to each other across time, and that is a primary focus of our ongoing research.
What's next
The main limitation of the current system is that fact-level and entity-level retrieval are still insufficient for the hardest long-range memory tasks. The weakest areas remain temporal reasoning, event ordering, and multi-session reasoning at large scales. The next areas of work are:
richer temporal representations
better modeling of cross-session event structure
more expressive retrieval fusion
tighter integration with agent workflows
This release improves extraction efficiency and retrieval quality under practical token budgets. The remaining work is in representing how information changes over time and using that structure reliably at larger scales. If this is the kind of systems problem excites you, come work with us.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

