



We’re introducing Temporal Reasoning in Mem0, a new memory layer that helps AI agents understand not just what they remember, but when it was true.
Long-running agents don’t fail only because they forget. They fail because they remember too much in the same tense. A user’s old city, previous job, past plan, and current preference can all sit in memory as if they are equally active today. Traditional retrieval can find the right topic, but it cannot always tell whether that memory is still current.
Temporal Reasoning fixes this by giving every memory a time signature, managing evolving states like location or job history, and reranking time-sensitive queries around what is current, historical, or upcoming. So when a user asks “where do I live now?” or “what am I working on this week?”, the agent retrieves the right dated instance, not just the closest semantic match.
Across our evaluations, this shows up most clearly in long-running memory benchmarks. On LoCoMo, Temporal Reasoning improved overall accuracy from 86.1% to 92.5%, with the largest gains on temporal and multi-hop questions. On LongMemEval, it improved overall accuracy from 90.4% to 94.4% at top_200, with the biggest lift on multi-session questions, where agents need to track how facts evolve across many conversations.
What changes
1. Every memory gets a time signature.
When a memory is written, a separate temporal reasoning pass reads the memory text alongside the original conversation and the date it happened. It extracts when the event occurred, whether it's still ongoing or completed, how precise the timing is, and what kind of memory it is, such as a plan, state, event, relationship, preference, or absence.
2. Memories are understood as temporal facts, not just text.
The system stores and distinguishes between past events, ongoing states, future plans, relationships, preferences, and absences. That temporal structure lives with the memory itself, so search can treat "lives in Austin," "has a dentist appointment next Tuesday," and "went to Japan last summer" as fundamentally different kinds of facts.
3. Time-sensitive queries get time-aware ranking.
Queries like "where does she live now?", "what's she planning this week?", or "how long has she had that job?" are classified by their temporal intent, with no extra LLM call. The temporal intent is then used to rerank retrieval results so the right dated instance surfaces, not just the most semantically similar one.
Temporal reasoning is fully additive: it layers on top of the existing mem0 algorithm pipeline without replacing the base retrieval system.
Highlights
7 memory types: from one-time events to stable timeless facts, every memory is classified at write time
7 temporal query modes: classified at query time, zero extra LLM calls on the read path
Temporal scoring is additive: it nudges ranking toward the right dated instance; semantic relevance always dominates
LoCoMo:
+9.1 pts at top_50: where temporal reranking has the most room to work
+4.1 pts overall, +6.7 pts on temporal questions: across 1,540 questions
LongMemEval:
94.8% at top_50, up from 94.4%: a +4.4 pt overall lift
+11.2 pts on multi-session questions: from 82.0% to 93.2% at top_50
Median search latency stays flat: +1 ms overhead on the read path
Async enrichment: latency-sensitive writes complete immediately; temporal metadata patches within seconds in the background
Zero data deletion: temporal metadata is additive, so historical context remains accessible
Try it
The API doesn't change. Add memories the way you always have:
Python
Node.js
Temporal Reasoning is on by default for every Mem0 project. If you ever need standard retrieval for a particular call, pass temporal_reasoning=False on that call and skip it.
What gets stored
Every memory can now carry four kinds of temporal structure:
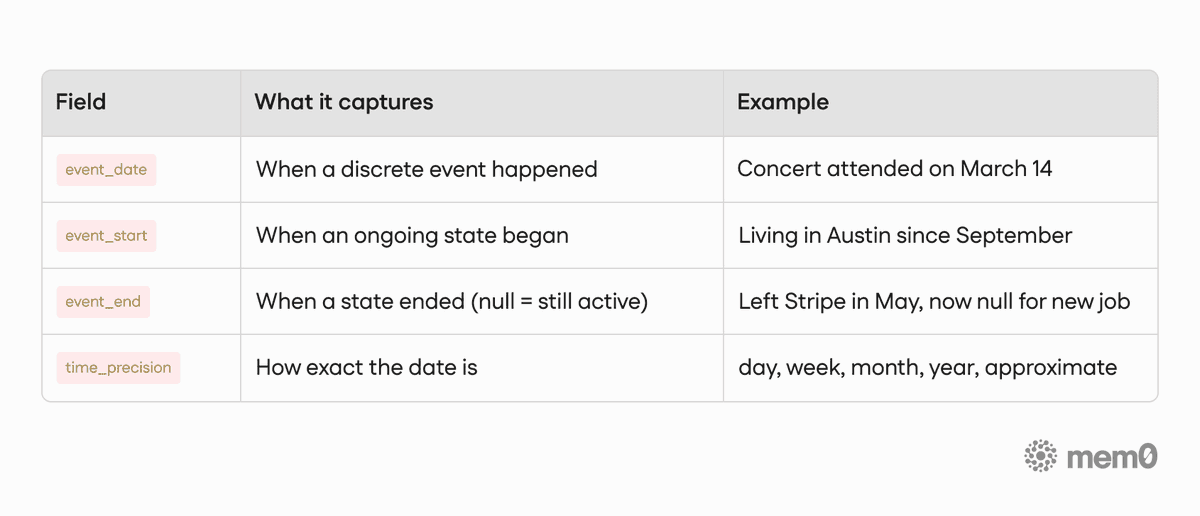
Table 1. Temporal Structure
And every memory falls into one of seven types:
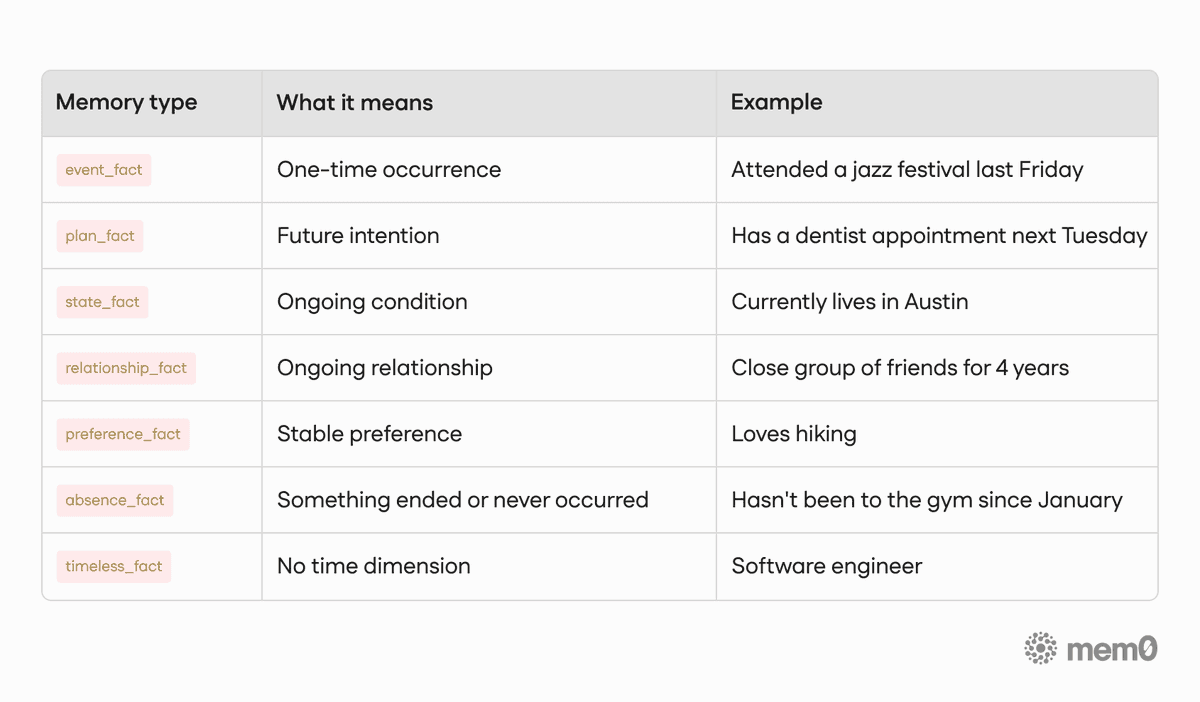
Table 2. Memory Type
Ongoing facts (states, relationships, preferences) carry a state key: a stable identifier that links every memory about the same evolving fact for one person. When a new state takes over, the old one's event_end gets set automatically. Timeline stays clean, nothing gets deleted.
How it works
Write: separate extraction and temporal enrichment
Memory extraction and temporal enrichment are intentionally separate passes. The extraction model does what it always did: reads the conversation and writes memories as natural language. The temporal reasoning pass then runs over those memories and returns structured time metadata for each one, covering when it happened, what type of memory it is, whether it's still active, and related temporal fields.
Keeping these separate means each can be improved independently. A better extraction model doesn't touch temporal enrichment, and vice versa.
For latency-sensitive applications, temporal enrichment can run asynchronously. Memories are written immediately so the add call returns fast, and a background worker patches in temporal metadata afterward. Until enrichment completes, search falls back gracefully to the base behavior for those memories.
Read: intent classification, retrieval, and temporal reranking
Queries are classified by their temporal intent, with no additional LLM call. The system recognises modes like:
historical_range: "what happened in March?"current_state: "where does she live now?"duration_state: "how long has she had that job?"upcoming: "what's she planning this week?"soft_recency: "what has she been up to lately?"
Critically, this classification does not filter what gets retrieved. Retrieval runs the same way for every query; the temporal intent has no say in which memories enter the candidate pool. It is used only at the reranking step, where each retrieved candidate is scored by how well its stored time metadata matches the query's intent.
This is intentional. Pre-filtering by time would silently drop memories with imprecise or missing dates. Instead, temporal scoring is additive, a soft signal layered on top of semantic relevance. A memory with strong semantic fit but weak temporal alignment will still rank above one with perfect temporal alignment but weak semantic fit. The temporal layer nudges ranking; it does not override it.
Temporal scoring happens after retrieval as an additive ranking signal, so the best temporal match can rise above memories that are only semantically similar.
Results
We tested the performance of our baseline algorithm (mem0.ai/research) without temporal reasoning, and then with temporal reasoning on LoCoMo and LongMemEval benchmarks.
LoCoMo
LoCoMo includes 1,540 questions across temporal, multi-hop, open-domain, and single-hop categories. These are the kinds of questions that distinguish a system with a concept of time from one without.
We report results in two views: by retrieval cutoff, and by question category.
Because these views aggregate the benchmark differently, their overall numbers are not expected to match exactly. The cutoff table shows performance at different retrieval depths, while the category table shows performance by question type.
Performance by retrieval cutoff
We tested the performance of our baseline algorithm (mem0.ai/research) without temporal reasoning, and then with temporal reasoning, by retrieval cutoff: all categories.
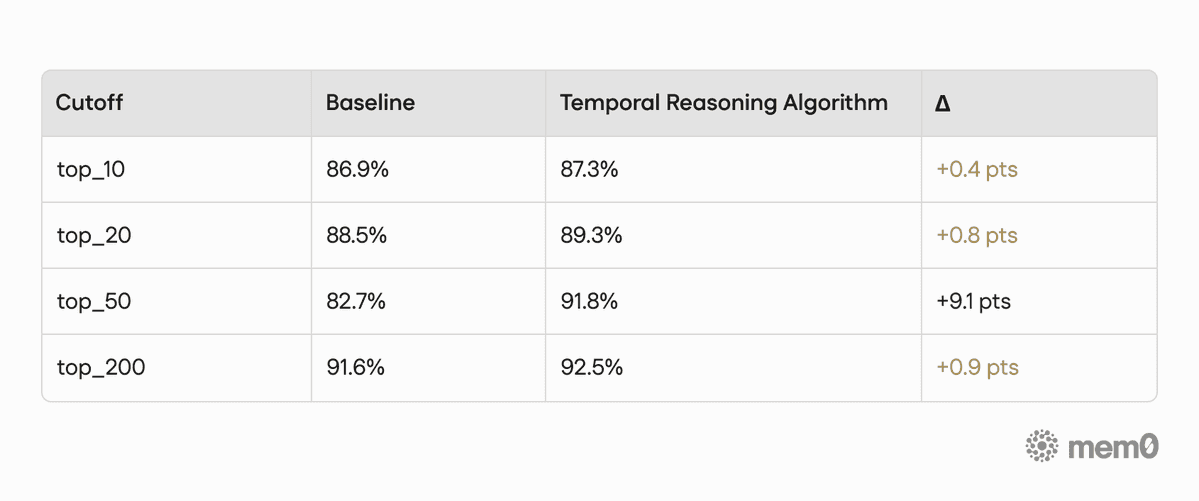
Table 3. Accuracy by retrieval cutoff on LoCoMo
The strongest LoCoMo gain appears at top_50, where accuracy improves from 82.7% to 91.8%. With more candidates in the pool, temporal reranking has more room to distinguish the right dated instance from near-identical alternatives, which is exactly the kind of question the LoCoMo benchmark is designed to stress.
Performance by question category (Across Top-10/20/50/200)
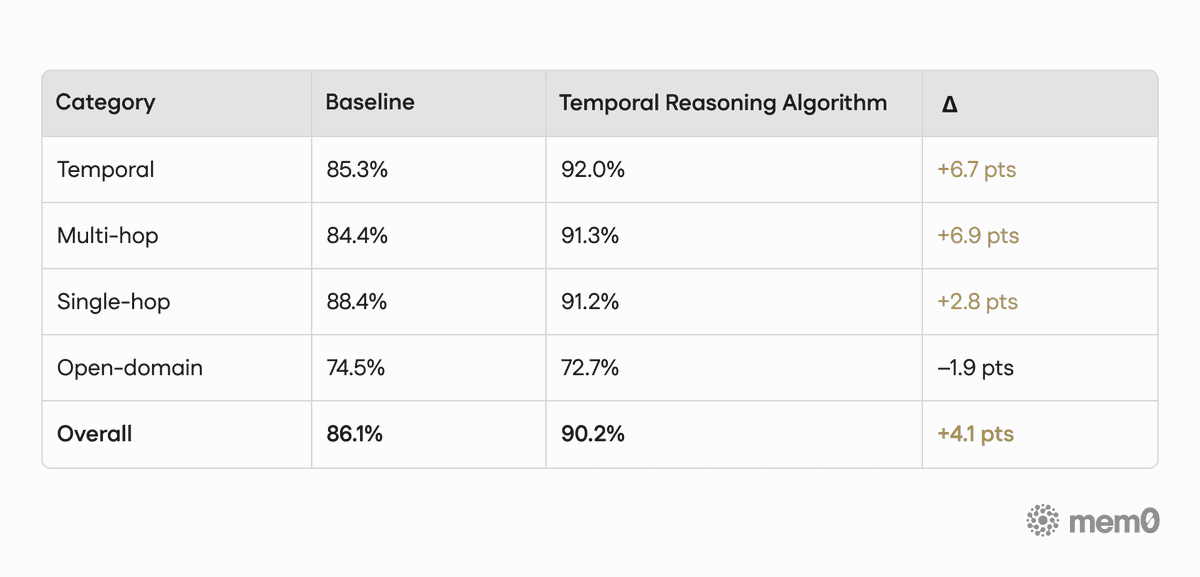
Table 4. Accuracy by question category on LoCoMo (Across Top-10/20/50/200)
Note on reading the tables: The LoCoMo results below are shown in two different views of the same benchmark. The category breakdown reports performance by question type, and its overall score is weighted by the number of questions in each category. The cutoff table reports performance by retrieval depth (top_10, top_20, top_50, and top_200). Because these views aggregate the benchmark differently, their overall numbers are not expected to match exactly.
Temporal Reasoning category by retrieval cutoff
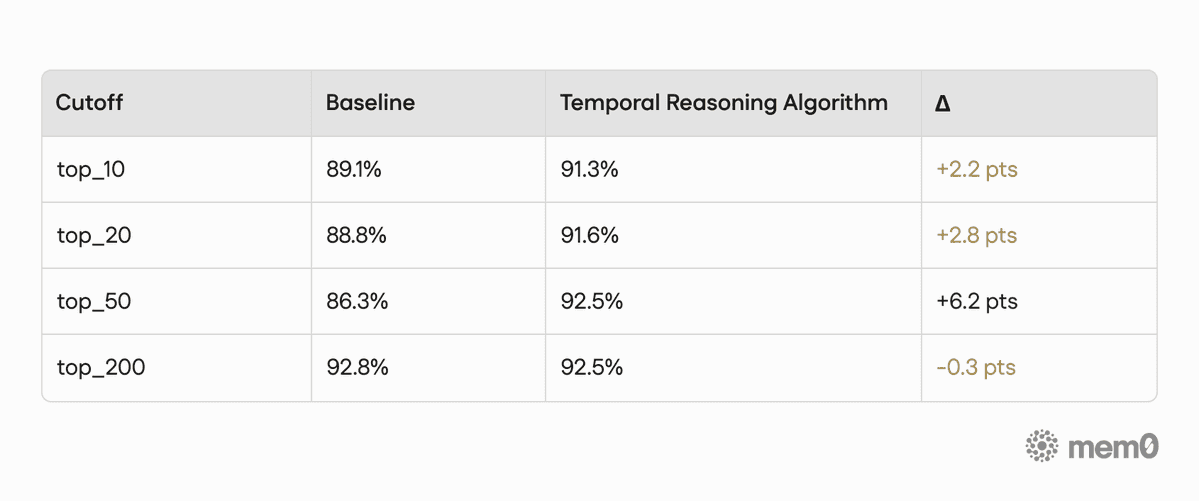
Table 5. Accuracy by retrieval cutoff on LoCoMo (Temporal reasoning category only)
Overall, we saw a +4.1 point lift across 1,540 questions. The biggest wins show up where they matter most: temporal and multi-hop questions, where the system has to figure out which instance applies and what is true right now.
The open-domain dip (96 questions, −1.9 pts) is real, and we’re actively tuning it. It is a small slice of the benchmark, and those questions are less likely to benefit from temporal reranking. We’re calling it out here so it’s visible, not buried.
LongMemEval
Temporal Reasoning also improves LongMemEval performance over our latest baseline, reaching 94.8% at top_50 and 94.4% at top_200 across 500 questions.
The biggest top_50 gain comes from multi-session questions, where accuracy improves from 82.0% to 93.2%. At top_200, the strongest lift appears in the temporal-reasoning category, improving from 93.2% to 97.0%.
LongMemEval is especially useful because it stresses the cases that show up in production memory systems: older facts competing with newer facts, user preferences evolving over time, and questions that require combining evidence across many sessions.
Performance by question category and retrieval cutoff
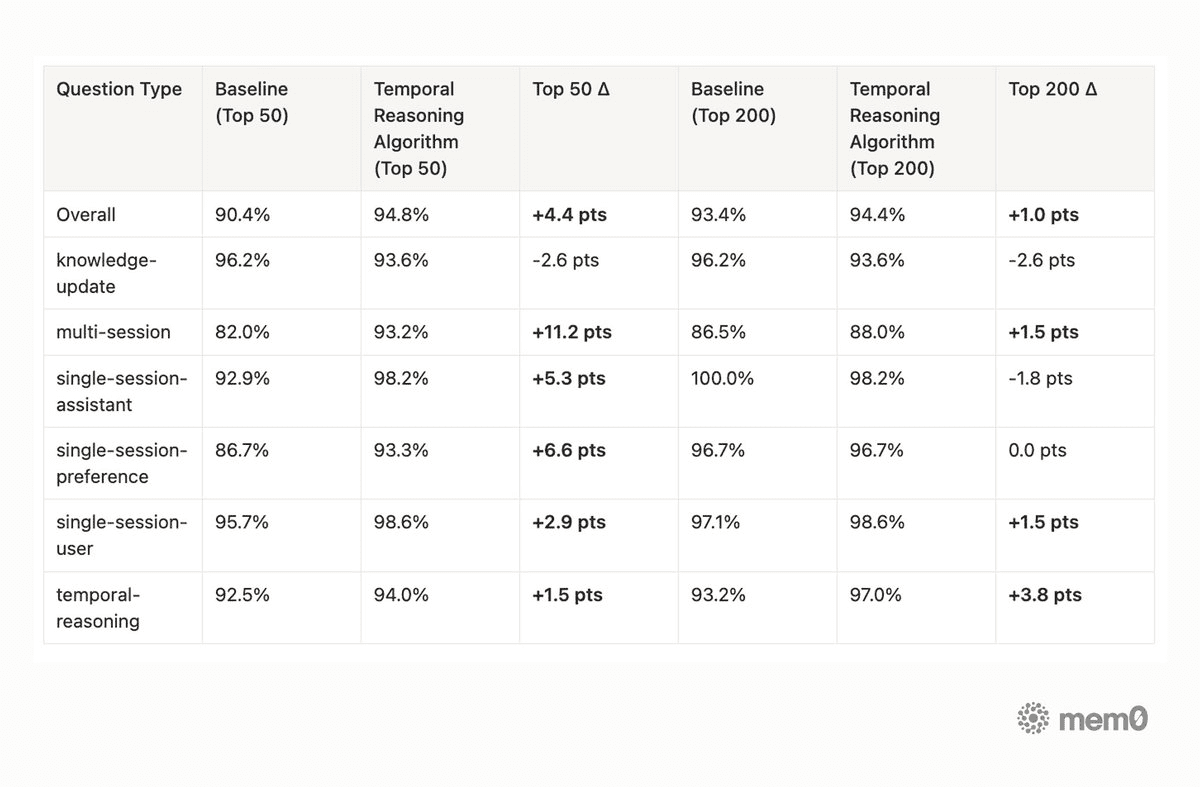
Table 6. Accuracy by question category and retrieval cutoff on LongMemEval
Knowledge-update remains the hardest category for an additive memory architecture. The latest algorithm release intentionally preserves historical memories rather than deleting or replacing them, so older semantically similar facts can still appear near newer facts. Temporal Reasoning gives the system stronger time-awareness, and the memory decay feature we recently launched further tackles stale-memory pressure by reducing the impact of older, less-current memories over time. This is part of the broader shift from static memory state toward memory evolution: preserving history while making the current truth easier to retrieve.
Search latency

Table 7. Search Latency
Median latency is essentially unchanged at +1 ms. Tail latency grows more noticeably (p95 adds ~198 ms), which is worth monitoring during rollout.
Application
Personal assistants and copilots. "What does the user prefer for dinner?" should return current preferences, not an accumulation of every meal mention over two years of conversations. Recent stated preferences rank above historical ones. Superseded preferences (the user switched from vegetarian to pescatarian) don't surface as conflicting facts.
Coding agents and dev tools. "What was the user working on?" means this sprint, not the side project from six months ago that quietly died. Plan-type memories age out of current-state queries naturally, no manual pruning needed.
CRM and sales intelligence. "What's the customer's current contract tier?" can be answered precisely. Subscription tiers are linked by state key. Customer upgrades close the old tier and open the new. No ambiguity, no hallucinated answers off stale context.
Healthcare and care coordination. "What medications is the patient currently taking?" is a question where temporal precision is the entire point. Discontinued meds carry an
event_end. Active ones don't. Active states surface first, closed ones sit as historical context.Long-running agents. Anything that accumulates memory across weeks or months hits the same wall: oldest memories feel as present as newest ones. Temporal Reasoning gives those agents a built-in sense of recency, no manual pruning required.
Takeaways
Temporal reasoning changes how memory behaves across the full pipeline: how memories are written, classified, and ranked. Classify once at write time so reads stay free. Score additively so semantic relevance still wins when it should. Never delete, because temporal context is metadata, not a replacement.
The result shows up in both benchmarks: +6.7 points on temporal questions in LoCoMo, and on LongMemEval, overall accuracy improves from 90.4% to 94.4% at top_50 (with the biggest lift on multi-session questions). Median latency stays essentially flat at +1 ms on the read path. Writes stay fast. Reads stay efficient. History stays intact.
That's the bar we wanted to clear before shipping, and the foundation for what comes next: reasoning across conflicting timelines, detecting stale facts, and tracking how beliefs evolve over time.
What's next
Temporal Reasoning is the foundation. With every memory carrying a time signature, the next layer is temporal query answering: direct responses to questions like "how long has the user had their current subscription?" computed from stored temporal metadata rather than inferred from semantic similarity.
After that comes temporal conflict resolution: when two memories about the same state have overlapping or contradictory time windows, the system will flag the conflict rather than silently picking one.
Both are backward-compatible. Memory written today will work with these improvements without any migration. Read more in the docs.
FAQ
Does this change my add or search calls?
No. Everything runs server-side. Existing code keeps working.
Does memory addition get slower?
In sync mode, there's one additional model call per batch — the temporal step. For latency-sensitive workloads, async mode writes immediately and enriches in the background. Search keeps working at full quality while enrichment is in flight; temporal metadata just isn't applied yet.
What about memories I already have?
They keep working as before. Retrieved and ranked without temporal metadata, same as always. They don't get retroactively enriched, but they don't break anything either. New memories written after enabling get full enrichment.
What if the model gets a date wrong?
It outputs a time_precision field reflecting confidence (day, week, month, year, approximate). Low-precision dates contribute less weight to temporal scoring, so a memory dated "approximately 2023" doesn't compete on equal footing with one dated "March 14, 2023." Imprecision is represented, not silently dropped.
Can I turn it off for one request?
Yes. Pass temporal_reasoning=False in the request body, and that call skips all temporal processing.
Will state changes lose my historical data?
Never. When a state is superseded, the old memory gets an event_end and is not deleted. Past states are still retrievable by queries that explicitly ask about the past. The current state just wins for present-tense queries.
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source GitHub repository
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

