



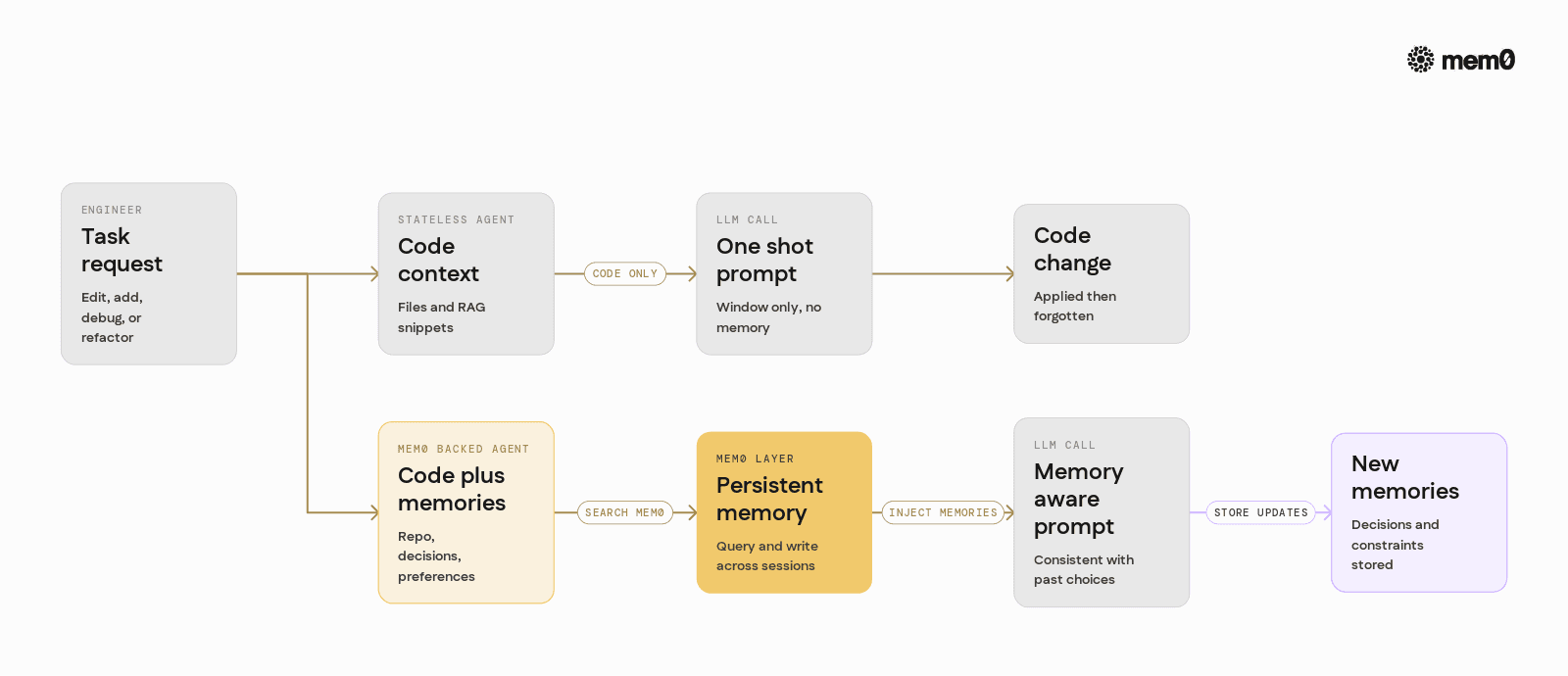
AI coding agents are now writing tests, refactoring modules, and wiring services together. Yet most agents still behave like stateless copilots. They forget decisions, lose track of project conventions, and repeat the same clarifying questions across sessions.
The missing piece is not a smarter model. It is a real memory layer that treats a codebase as a long-lived environment, not a one-off chat. This article explains how to make coding agents that actually remember a repository over time, and how Mem0 fits as the memory backbone for that behavior.
What a coding agent needs to remember?
A production-ready coding agent interacts with more than isolated snippets. It touches a living system. Useful memories fall into several categories:
Repository structure
Packages, modules, entrypoints
CLI tools, scripts, migration paths
Build system layout
Domain and architecture
Core domain models and aggregates
Service boundaries and layers
Cross-cutting concerns like logging and observability
Conventions and patterns
Naming schemes, folder structure, and testing styles
Framework or library idioms used by the team
Linting and formatting rules
Decisions and constraints
"We use Pydantic v1 patterns, do not use v2 features yet"
"All public APIs must be backwards compatible with clients on v3"
"Caching must go through this abstraction"
User-specific preferences
The engineer's preferred frameworks, patterns, or design choices
Rejected suggestions and the reasons
Security and performance sensitivities
Each of these items should improve future interactions. If an agent learns that UserId is a value object, it should stop re-implementing IDs as raw strings. If a migration path has been chosen, it should not propose incompatible alternatives the next day.
Without explicit memory, agents rely only on immediate context. That works inside a single call, but breaks down as soon as the agent needs to reason across files, tasks, or sessions.
Why stateless tools fail on real repositories
Most current coding tools depend on two mechanisms: local context windows and retrieval from vector search. Both are necessary, but not sufficient. Here are a couple of reasons to ponder over:
Context window limits
LLMs reason over a bounded context window. For large monorepos, this context is only a thin slice of the codebase. The agent must decide which files, docs, and decisions to include on each call. That introduces several problems:
Long histories become truncated
Architectural decisions get dropped
The same scheduled task might be discussed, forgotten, and rediscovered in slightly different variants
Raw RAG is not memory
Vector search over code or docs helps locate relevant snippets. Yet retrieval alone does not capture the agent's evolving understanding of a repository. Common issues:
No persistent notion of "this pattern is preferred in this repo"
No accumulation of decisions like "we already tried and rejected that design"
No user-level preferences or cross-session learning
A coding agent that only has RAG behaves like an efficient search interface, not like a collaborator who knows the project history.
What is missing is a memory layer that stores meaningful, structured records about the repository and interactions, then feeds those back into agent reasoning.
What a memory layer for coding agents looks like
An effective memory layer for coding agents has four key properties:
Persistent and queryable: It stores memories across sessions and environments, with APIs to query by semantics, tags, and scopes.
Scoped and structured: It distinguishes types of memories: repo facts, user preferences, decisions, tests failures, etc. Attach metadata like repo id, branch, file path, and time.
Model-agnostic and multi-agent friendly: This works with different LLMs, local models, and multiple agents that share a codebase.
Safe and controllable: It allows inspection, auditing, and deletion. Developers can understand what the agent thinks it knows about the repo.
Mem0 is designed to provide exactly this layer. It sits between the agent logic and the model, handling memory creation, retrieval, and organization without forcing a specific agent framework.
The rest of this article shows how to use Mem0 to add real memory to coding agents.
How Mem0 represents codebase memories
Mem0 stores "memories" as semantic records with optional structured metadata. For coding agents, several memory types appear frequently:
Repo facts: "Service X uses FastAPI and depends on module Y."
Metadata:{"type": "repo_fact", "repo": "payments-service", "file": "api/routes.py"}Design decisions: "Feature flags must be read from ConfigService, not environment variables directly."
Metadata:{"type": "decision", "scope": "feature_flags", "author": "alice"}User preferences: "Prefers dependency injection over global singletons in this repo."
Metadata:{"type": "preference", "user_id": "alice"}Constraints and policies: "Do not add new dependencies without updating the architecture doc."
Metadata:{"type": "constraint", "severity": "high"}
Mem0 handles the embedding, storage, and semantic search. The agent then retrieves and injects relevant memories into prompts.
Compared to embedding raw code, these memories capture the meaning of interactions and decisions, not just tokens. That is what allows the agent to behave consistently over time.
Integrating Mem0 into a coding agent loop
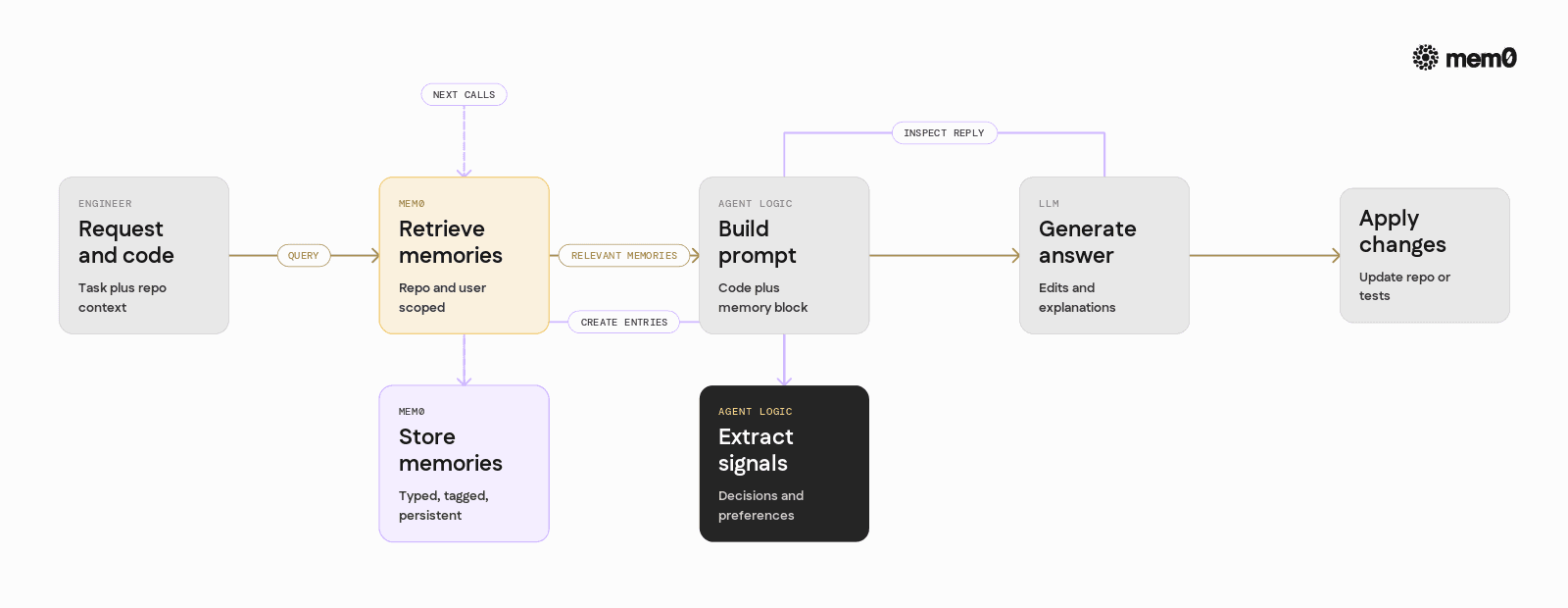
The core integration pattern is:
Observe a user request and the current repo context.
Query Mem0 for relevant memories.
Build a prompt that includes both code snippets and memories.
Send to the model, get actions or code edits.
Persist new memories derived from the interaction.
The following example shows a simplified synchronous loop with Python.
🔑 You'll require Mem0 API key to move forward. Get it for free: app.mem0.ai.
This example omits error handling and fine-grained extraction of memories, but the pattern is clear. Every interaction pulls in prior knowledge and has the option to update that knowledge.
In a production system you would add more structure, for example:
Separate memories for repo facts vs user preferences
A moderating step that filters what should be stored
Background jobs that mine the repo for new memories
Memory patterns for large codebases
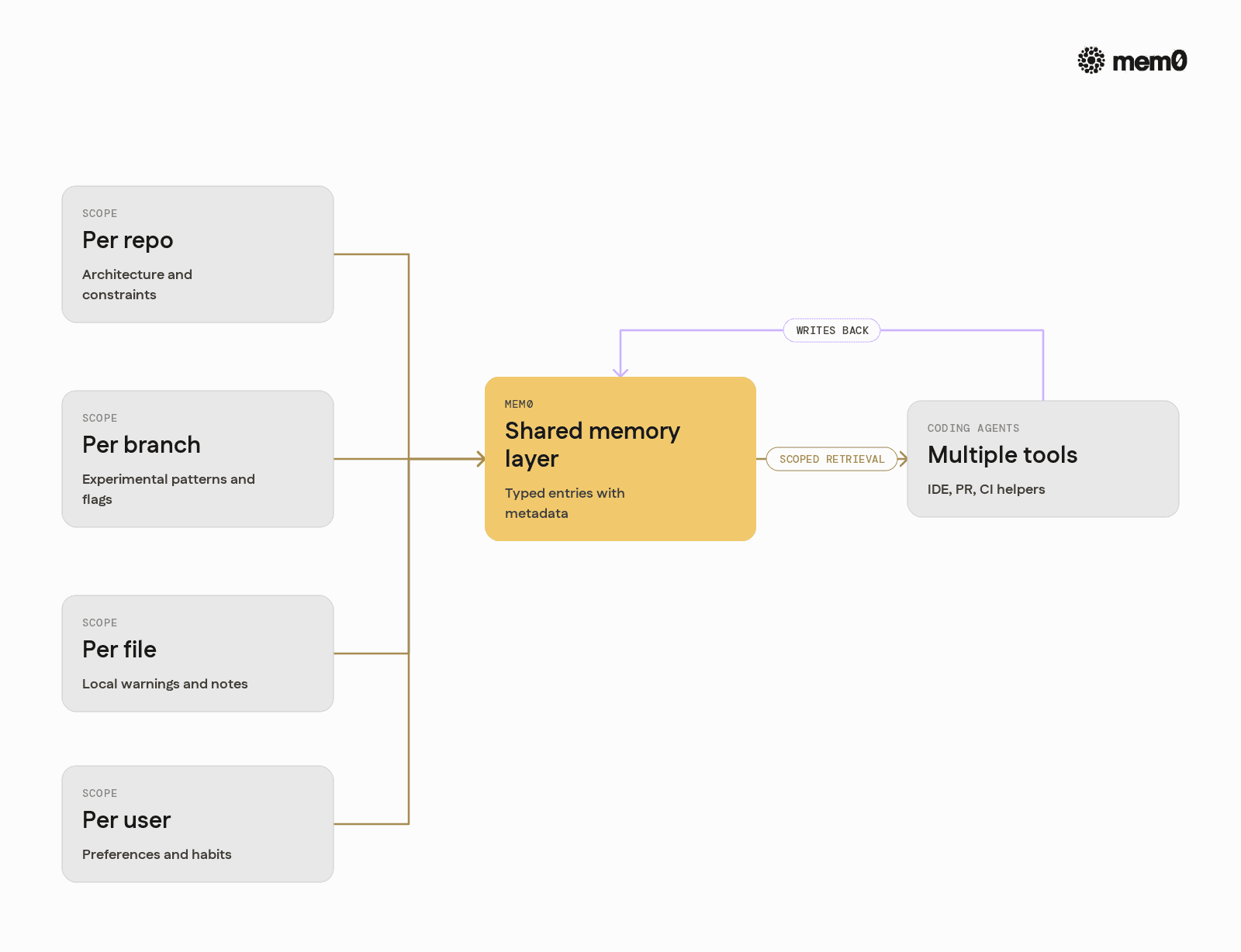
Mem0 can support several useful patterns when dealing with large repositories.
Per-repo and per-branch memory
Use metadata like repo_id and branch to isolate memories. A feature branch might use experimental patterns that should not affect the main branch.
Example metadata:
Retrieval queries can then filter on branch when needed.
File-local context and cross-file knowledge
Not every memory needs to be global. File-level memories can capture recurring patterns like:
"This file uses sync functions only."
"This module is imported by the public API, be careful about breaking changes."
Tags like {"file": "src/api/invoices.py"} let the agent recall specific warnings when editing that file.
Test failures and fix history
Memories can record patterns around flaky tests or past failures:
"Test X is flaky under high load, do not rely on exact timing."
"Bug Y was caused by timezone mishandling, prefer aware datetime objects."
These memories improve future debugging and reduce repeated mistakes.
Comparison: Stateless vs Mem0-backed agents
Dimension | Stateless coding agent | Mem0-backed coding agent |
|---|---|---|
Cross-session consistency | No persistent knowledge | Remembers past decisions and conventions per repo and user |
Preference learning | Repeated questions and style resets | Learns and reuses user and team preferences |
Design decision recall | Limited to current context window | Stores explicit decisions with metadata and timestamps |
Large repo navigation | RAG-only, no long-term structure | Builds a semantic map of modules, patterns, and constraints |
Collaboration between users | No shared understanding beyond the code itself | Shared memories scoped to repo or team when desired |
Debugging behavior | Treats each failure as new | Remembers past failures, fixes, and investigation paths |
The behavior difference becomes especially visible in multi-week projects where context fragmentation is the norm.
Where the memory pattern breaks down
A memory layer improves coding agents significantly, but it is not a silver bullet. There are several failure modes and edge cases to handle.
Stale or incorrect memories
Memories created from old code or misunderstandings can become outdated. The agent might rely on a design that changed last week. To mitigate:
Attach timestamps and version metadata
Prefer recent memories for conflicting facts
Periodically validate and prune memories with automated checks
Over-reliance on high-level summaries
Summaries of code or architecture can hide important edge cases. An agent that only reads "This module handles authentication" might misinterpret how it does so.
To address that:
Combine memories with fresh retrieval from the actual code
Make it easy to inspect and trace which memories influenced a suggestion
Encourage the agent to verify assumptions in the current codebase
Memory bloat and query noise
If every token of interaction becomes a memory, retrieval quality drops. The agent sees a wall of partial thoughts and trivial comments.
Mitigations:
Use simple heuristics or classification models to decide what to store
Favor higher-level decisions over raw logs
Add filters for type and scope in queries
Security and privacy concerns
Memories can contain sensitive code and decisions. In some environments, certain data must not persist.
Consider:
Scopes and policies for which repos or users have persistent memory
Redaction rules for secrets and tokens
Tools to delete or export memories as part of compliance processes
These limitations are not specific to Mem0. They are inherent challenges when granting any agent a long-lived memory.
How Mem0 fits into real coding workflows
Mem0 focuses on the memory layer, not on imposing a particular agent orchestration framework. This makes it flexible enough to drop into several patterns.
As a plugin to an existing tool
An existing internal coding assistant that already uses a chosen LLM can add Mem0 as:
A pre-call "context augmenter" that retrieves repo and user memories
A post-call "logger" that stores extracted decisions and patterns
Only a small wrapper is needed to integrate Mem0's create and search operations.
As a shared memory backend for multiple agents
In complex setups, separate agents handle tasks like:
PR review
Refactoring
Test generation
Architecture advisory
Mem0 can act as the shared backend where each agent writes structured memories. For example, the PR review agent can store "This pattern was accepted / rejected" which influences future refactorings by a different agent.
As infrastructure for code-aware copilots
For teams building custom copilots embedded in IDEs, CI, or chat tools, Mem0 can serve as the persistent backbone:
IDE extension reads relevant memories for the current file and user
CI agent logs test failures and recovery strategies
Chat assistant recalls previous conversations about the same service
The key is to treat Mem0 as the single source of "what the agent has learned about this repo", independent of interface or model.
Best practices for Mem0-powered coding agents
Several patterns improve quality and reliability when using Mem0 in coding agents.
Define memory schemas upfront: Decide on a set of memory types and their required metadata. For example:
repo_fact,decision,preference,test_failure. Keep schemas simple but consistent.Introduce memory gradually: Start by persisting only clear decisions and key preferences. Expand to more categories once the impact is visible.
Use conservative write policies: Do not store every LLM output. Prefer memories confirmed by the user or by observing merged code.
Surface memories to humans: Build simple UIs or CLI tools that list memories for a repo or file. Developers can correct or delete entries when needed.
Log which memories influenced each suggestion: For debugging and trust, record which Mem0 entries were retrieved for each LLM call. That helps diagnose incorrect behavior.
These practices help keep the memory layer an asset instead of a source of confusion.
Frequently Asked Questions
Q. What types of information should a coding agent store in Mem0?
Agents should store high-value items that influence future decisions. This includes architecture facts, design decisions, user preferences, common pitfalls, and constraints, all scoped by repository and sometimes by file or branch.
Q. How often should the agent write to Mem0 during development?
For most setups, writing at key decision points is enough. Examples are after resolving a debate about an approach, finalizing an API shape, or confirming a preferred pattern, instead of on every minor edit.
Q. Can Mem0 handle multiple repositories and branches for the same agent?
Yes, repositories and branches can be modeled with metadata fields such as repo_id and branch. Queries then filter on these fields so that memories remain specific to each codebase and branch when required.
Q. How does Mem0 interact with existing code search or RAG systems?
Mem0 complements search by storing semantic memories that are not just raw code. The agent still uses code search for source snippets, and blends those results with Mem0 memories that encode decisions, preferences, and constraints.
Q. When should stale or incorrect memories be removed or updated?
Any time a core design changes or a previous decision becomes invalid, memories referencing that choice should be updated. Teams can schedule periodic reviews or use automated checks that compare memories with current repo state to flag inconsistencies.
Q. Why not just store everything in logs instead of a memory layer like Mem0?
Logs are unstructured and optimized for sequential playback, not for semantic retrieval across time. Mem0 stores compact, queryable memories with metadata and embeddings, which makes it feasible for agents to retrieve the right pieces in milliseconds during coding tasks.
Further Reading
AI Powered Coding Agents That Actually Remember Your Codebase
Codex Mem0 MCP Build A Coding Agent That Remembers Your Codebase
Build A Financial AI Agent That Remembers Analyst Preferences
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

