



TL;DR
Financial AI agents retrieve tables well but they forget analysts entirely. Valuation preferences, growth assumptions, and margin caveats disappear the moment a session ends.
RAG and analyst memory are different context types and need separate storage. Mixing them creates a scoping problem that compounds with every analyst on the team.
Mem0 scopes memory per analyst. Preferences stay isolated across users, even when two analysts are working on the same company.
Prompt-stuffing and basic RAG both silently drop hard constraints and valuation frames as history grows.
RAG remembers the table. Mem0 remembers the analyst. You need both.
Most financial AI agents retrieve a table, answer one question, and stop. Real analyst work is longitudinal: the analyst carries assumptions, valuation habits, and caveats across sessions.
RAG retrieves financial facts like revenue, EBITDA, enterprise value, and filing text. Mem0 retrieves analyst preferences like valuation method, growth posture, margin-expansion caveats, and company-pattern assumptions.
In this article, we'll compare the same analyst agent before and after memory. The product moment is simple:
By the end, your agent will do this:
The evaluation checks preference recall, assumption continuity, user scope control, company-pattern relevance, and stale assumption updates.
💡You'll need a free Mem0 API key to run the hosted memory path. Get one at app.mem0.ai: no credit card required.
This post is a code-level walkthrough of a financial AI agent that remembers analyst preferences across sessions. We'll cover how the demo works, where RAG stops, where Mem0 starts, how the evaluation is structured, and what has to change before this pattern becomes production-grade.
The Problem: Financial Agents Forget the Analyst
Most financial-agent failures do not look like failures at all because the agent still produces an answer, the numbers are still plausible, and the table values are still cited. What disappears quietly is the analyst's preference from the previous session: "use EV/Revenue when SaaS EBITDA is negative," "prefer conservative growth assumptions," or "always call out whether margin expansion is assumed." The model has not changed, the dataset has not changed, and the retrieval pipeline has not changed. The system simply has no durable place to store the analyst's working assumptions.
Analysts do not start from a blank slate every time they open a company model. They bring a working style built from years of pattern recognition: use EV/Revenue when SaaS EBITDA is negative, avoid aggressive multiple expansion unless the data strongly supports it, call out whether margin expansion is assumed, and prefer FCF margin for mature software companies. These are analyst facts, not company facts, and no financial table contains them. An agent that only retrieves the table can correctly compute revenue growth and still choose a valuation frame the analyst explicitly rejected in a previous session.
New to this topic? Three terms to know:
Financial RAG: Retrieval over financial facts such as tables, filings, KPIs, market data, earnings text, and prior Q&A context.
Analyst memory: Persistent user-specific assumptions such as preferred valuation method, conservatism level, sector heuristics, and answer style.
Scope control: The guarantee that analyst_002 does not inherit analyst_001's memories just because they ask about the same company.
The Before and After Moment
Let's test our financial agent with and without Mem0. In Session 1, the analyst states their preferences:
In Session 2, on a new call with no conversation history, the analyst asks:
Without memory, the agent retrieves the table and reasons from scratch:
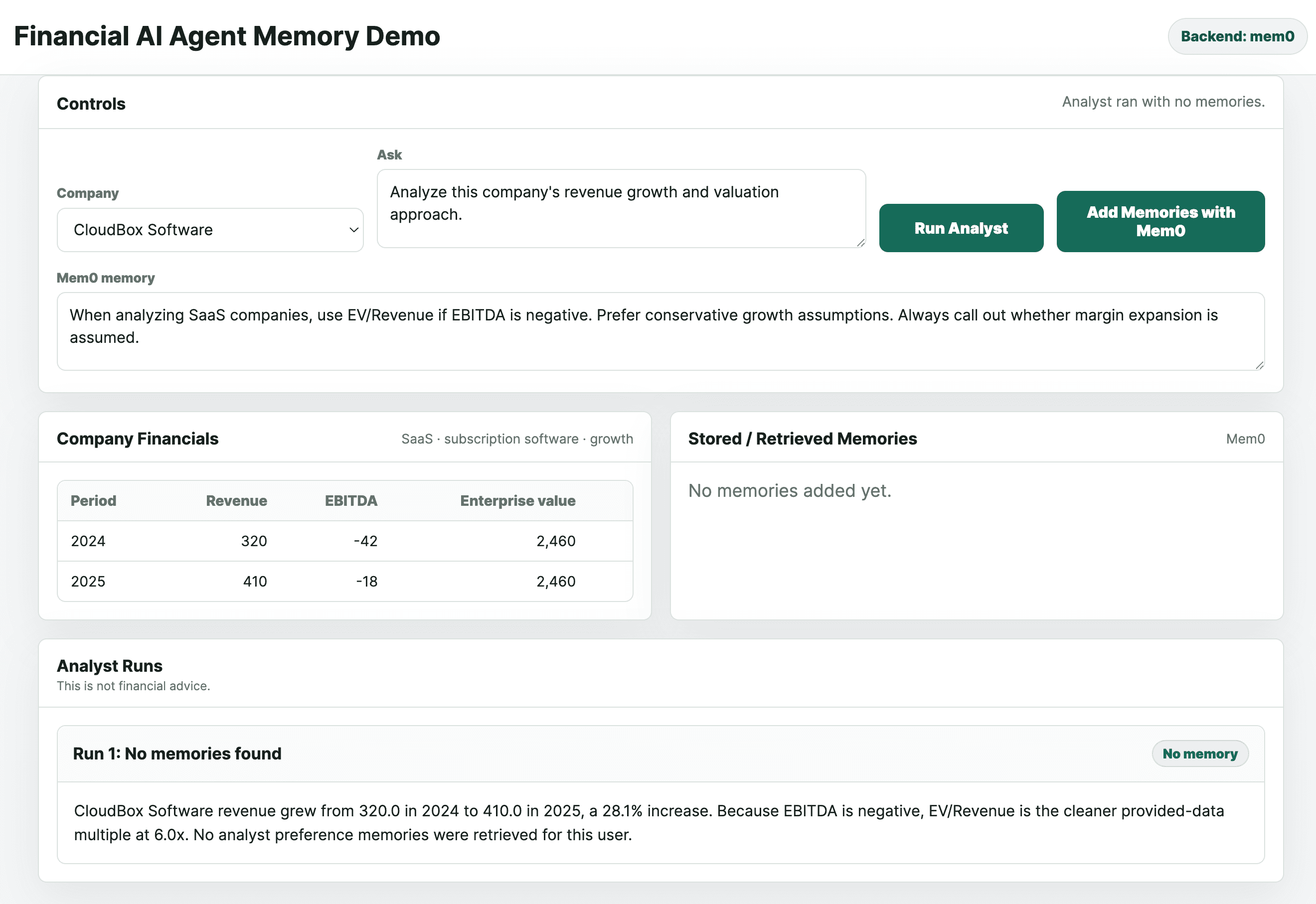
With Mem0, the agent retrieves the table and the analyst's stored preferences before generating a single token:
That is the whole article. The first answer retrieves the table. The second answer retrieves the table and remembers the analyst.
Why RAG Is Not Enough?
RAG and analyst memory are orthogonal context types, and conflating them is the root cause of most financial agent failures at scale.
RAG retrieves financial facts:
Mem0 retrieves analyst preferences:
The financial table says what happened. Analyst memory says how this user wants to reason about what happened. If you store analyst preferences in the same vector database as financial facts, you have created a retrieval problem that gets worse with every analyst on the team. analyst_002's conservative growth preference will surface when analyst_001 asks about the same company, not because of a bug, but because the memory is unscopable. That is exactly the failure mode Mem0's user_id scoping is designed to prevent.
The naive workaround is to stuff every prior analyst message into the prompt:
This works for a small demo and breaks as soon as the analyst has real history. A memory layer does something much narrower: only relevant analyst memories come back, the company facts stay in the financial retrieval layer, and the preferences stay in the memory layer.
The core distinction: RAG remembers the table. Mem0 remembers the analyst.
What We'll Build
The demo has the following architecture:
💡You can find the complete code on the GitHub repository.
Run the command-line demo:
Run the browser demo:
Run the hosted Mem0 path:
Dataset note: The demo uses a local ConvFinQA-style sample by default so it runs immediately without a Hugging Face account. ConvFinQA is the right dataset family because it focuses on conversational financial question answering over tables and tests multi-turn financial reasoning rather than single-shot lookup. The local sample follows this schema:
To experiment with
directly:
If the Hugging Face dataset path changes, keep using the local JSON schema in this repo and map the original records into it.
Three Sessions: How Analyst Memory Accumulates
Session 1: Storing preferences
The analyst states their working style, and the agent stores each preference as a discrete memory entry scoped to their user ID:
💡 You'll need a Mem0 API key for the above code snippet.
The expected durable memories after Session 1 are three discrete entries: analyst prefers EV/Revenue for negative-EBITDA SaaS companies, analyst prefers conservative growth assumptions, and analyst wants margin expansion called out explicitly. The demo stores each preference separately so the UI can show exactly what was remembered.
Session 2: Retrieving preferences during analysis
When the analyst asks about a company in a new session, the agent searches memory before composing the answer.
The agent loads the financial table, runs the calculations, and the answer now combines source data and memory:
Session 3: Company-pattern assumptions
Analyst memory is not only generic preference memory. It can also store reusable business-model assumptions that apply to specific company types:
When the selected company is consumption-based, the agent applies the assumption with explicit attribution rather than silently baking it in. The important constraint is scope: the consumption-volatility assumption should apply to consumption-based software companies, not industrial hardware or mature SaaS.
The Hard Part: Stale Assumptions
Memory bugs are not only about forgetting. Sometimes the agent remembers too much from the wrong point in time.
Suppose the analyst later says: "For mature SaaS companies, I now prefer FCF margin over EV/Revenue." The old rule still exists: use EV/Revenue if EBITDA is negative for SaaS. Both are now in the memory store, and both will surface for mature SaaS companies. The agent needs to resolve the conflict, not silently prefer one over the other.
The demo handles this explicitly:
Production systems should store timestamps, scope metadata, and provenance for every memory entry. Do not silently delete old assumptions. Retrieve both, resolve the conflict, and explain the resolution to the analyst so they can correct it if the agent got it wrong.
Evaluation
The benchmark tests five scenarios:
whether the agent remembered EV/Revenue for negative EBITDA,
whether it maintained conservative framing and margin callouts across sessions, whether analyst_002 avoided analyst_001's preferences,
whether consumption volatility applied only to relevant company types, and
whether mature SaaS used the newer FCF-margin preference over the older EV/Revenue rule.
To test this, run:
Expected output:
The most important number is Scope leaks: 0. A personalized financial agent is useful only if personalization stays scoped to the right analyst. An agent that leaks analyst_001's conservative growth assumptions into analyst_002's DCF is not a personalization feature: it is a correctness bug.
Production Considerations
A production financial AI agent needs more than this demo provides. Real retrieval from filings, transcripts, data warehouses, and market data APIs replaces the local sample. Every financial number needs a citation. Memory operations need scoping at the user, team, workspace, and permission boundary levels. Audit logs showing which memories influenced which answers are non-negotiable in any compliance-adjacent workflow.
The architecture stays the same regardless of scale:
Four specific gaps to address before production:
Memory deletion and correction: Analysts change their minds. Your system needs a path for an analyst to view, edit, or explicitly delete stored assumptions, not just add new ones that compete with old ones.
Stale memory resolution with timestamps: Store
created_aton every memory entry and sort by recency when retrieving conflicting preferences. The newer preference wins for the same scope. Document this policy explicitly so analysts know how the resolution works.Compliance review: Any workflow that produces analyst-style output needs a review process before it touches investment decisions. The agent is a preference-aware calculator, not an investment advisor.
Scope boundaries:
user_idalone is insufficient for enterprise deployments. Add organization ID, workspace ID, and permission-level scoping to prevent memory from crossing team or client boundaries.
Your analyst agent should remember the assumptions, not just retrieve the numbers. Start free at app.mem0.ai or self-host from GitHub.
Frequently Asked Questions
What is a financial AI agent?
A financial AI agent is an AI system that retrieves financial context, reasons over company data, performs calculations, and produces analyst-style answers. In this demo, the agent also remembers analyst preferences across sessions using Mem0 so that valuation choices, growth assumptions, and margin callouts carry forward without the analyst repeating them.
Why use Mem0 instead of just RAG?
RAG retrieves facts from a dataset. Mem0 retrieves durable user assumptions. Financial facts and analyst preferences are different kinds of context with different scoping requirements: a preference stored for analyst_001 must never surface for analyst_002, even when both analysts are analyzing the same company. Mem0's user_id scoping enforces that boundary by design.
What does Mem0 store?
Mem0 stores analyst preferences and company-pattern assumptions: use EV/Revenue for negative-EBITDA SaaS, prefer conservative growth assumptions, call out margin expansion, treat consumption businesses as potentially volatile, and prefer FCF margin for mature SaaS companies. Each preference is stored as a discrete entry with metadata so retrieval can filter by type and scope.
How do you prevent one analyst's assumptions from leaking to another?
Every memory operation is scoped with user_id. The evaluation creates analyst_002 and verifies that they do not inherit analyst_001's preferences. Production systems should extend this with organization-level and workspace-level scoping to handle multi-tenant deployments where multiple teams analyze the same companies.
How should stale assumptions be handled?
Do not delete old assumptions. Store the newer assumption with a timestamp and scope, retrieve both when relevant, and have the agent explain which one applies and why. In this demo, a mature-SaaS FCF margin preference overrides the older EV/Revenue preference only for mature SaaS companies. The conflict resolution is always surfaced to the analyst, never silently applied.
References:
Mem0 SDK changelog: https://docs.mem0.ai/changelog/sdk
Mem0 search memories API: https://mem0.mintlify.app/api-reference/memory/search-memories
ConvFinQA paper: https://huggingface.co/papers/2210.03849
ConvFinQA GitHub: https://github.com/czyssrs/ConvFinQA
FinQA paper: https://arxiv.org/abs/2109.00122
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

