



Most coding agents work well for short tasks, then collapse as soon as the interaction spans multiple files, refactors, or days. The root cause is not model quality. It is memory.
Production coding agents must track things like:
Project structure and entry points
Key abstractions and their evolution over time
Decisions from previous reviews and incidents
User preferences around style, libraries, and constraints
Standard approaches rely on:
Long prompts with repository context on every call
Ad hoc vector searches over embeddings of files
Temporary per-session context objects
These approaches treat codebases as static documents and conversations as disposable. Real projects are neither. Engineers refactor, delete, and redesign. Teams revisit patterns that were discussed weeks earlier. An agent who forgets these details creates extra review work and trust issues.
A memory layer like Mem0 gives coding agents a persistent, structured view of the codebase and the user's past interactions. The agent can then act more like a long-term collaborator than a stateless autocomplete tool.
What is code-aware memory?
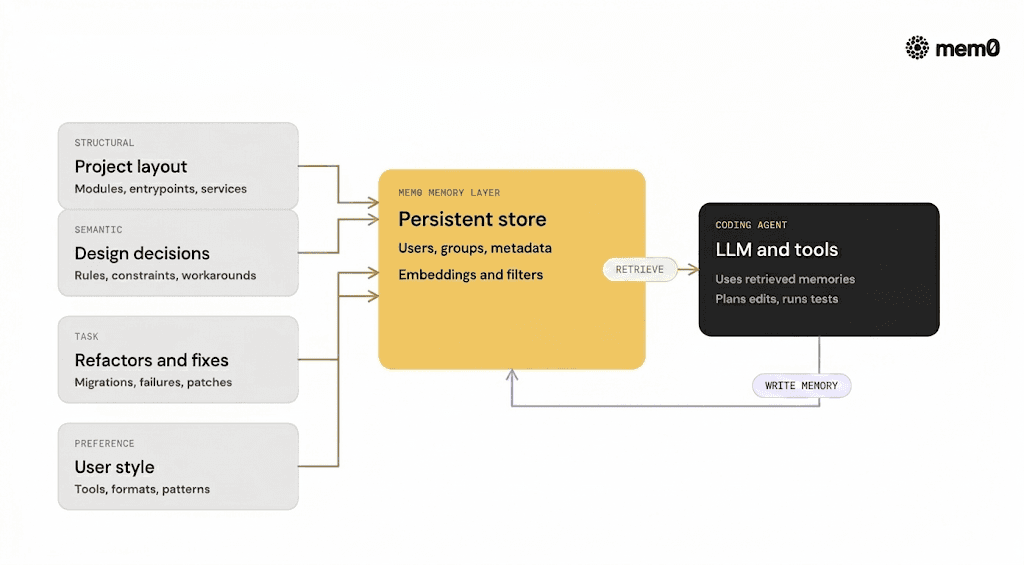
A code-aware memory is not just a vector store of source files. It includes several distinct types of information:
Structural memory
Project layout, build system, frameworks
Key modules, entrypoints, and service boundaries
Semantic memory
Design decisions and architectural constraints
Invariants and non-obvious business rules
Known workarounds and technical debt items
Task memory
Past tasks, patches, and migration steps
Open threads, half-finished refactors
Linked test failures and fixes
Preference memory
Style and linting preferences
Tooling preferences (pytest vs unittest, FastAPI vs Flask, and so on)
Response formats and level of verbosity
A useful agent must be able to:
Persist these memories across sessions
Update or delete them when they become stale
Retrieve only the relevant subset for a particular request
Attach them to the right user, project, or environment
This is the layer Mem0 provides.
How do coding agents usually try to remember?
Without a dedicated memory layer, teams usually assemble some combination of:
Raw embeddings over files and docs
A relational database for task metadata
Custom schemas in a vector database
Prompt templates that inject retrieved snippets
This can work for prototypes, but common issues appear in production:
No distinction between user-level and project-level knowledge
Context pollution from irrelevant or outdated snippets
Manual schema management and migrations
Difficulty sharing memory between different agents or tools
The result is an agent that sometimes repeats past mistakes, sometimes ignores past instructions, and often retrieves the wrong file versions.
Mem0 is positioned as a consistent abstraction for long-term memory, with built-in handling of users, groups, and data sources.
Typical baseline architecture
A common pattern for a coding agent without Mem0:
Index each file as an embedding.
On every query, embed the user message.
Retrieve top-k similar file chunks.
Stuff everything into the prompt.
Call the LLM and return the result.
That pipeline has three serious problems for large codebases:
It ignores temporal information about refactors and migrations.
It cannot represent higher-level design decisions or user preferences.
It often exceeds token limits with redundant or outdated context.
A memory-aware design solves these by storing derived, compressed, and curated memories, not just raw static text.
Core requirements for persistent coding memory
When the agent is part of a production engineering workflow, memory must satisfy requirements that mirror real software engineering practices.
Multi-tenant and multi-repo
Different users share some context (the repository)
Each user has personal preferences and workflows
Some memories are specific to a project or service
Others are reusable across multiple repos (for example, company coding standards)
Time-aware and mutable
Refactors and migrations invalidate old patterns
Documentation updates replace outdated explanations
Feature flags and experiments come and go
Incidents produce new rules that must override prior behavior
A memory system must support updates, deletions, and soft deprecations, not just append-only writes.
Queryable by more than similarity
Filter by repository, language, domain, or component
Distinguish between "design decisions" and "test failures."
Sort by recency or reliability, not just vector similarity
This is especially important when codebases reach tens of thousands of files.
Mem0 exposes metadata-based filtering and scoring control in addition to semantic similarity, which makes it suitable as a memory infrastructure for coding agents.
Mem0 basics for coding agents
Mem0 provides an intelligent memory layer designed to sit beside an LLM and tools like code search or issue trackers. At a high level:
Stores memories that are free-form text plus metadata
Automatically embeds and indexes content
Supports users, groups, and sources
Offers retrieval with semantic search and filters
Works via a simple API or Python client
Can be hosted as a managed service or self-hosted
For coding agents, Mem0 can track both:
Repository-level knowledge: module roles, architecture notes, incident retros
User-level knowledge: the engineer's preferred patterns, tools, and constraints
Conceptual mapping
These conceptual mappings cover the core use cases:
user_id→ the person interacting with the coding agentgroup_id→ the repository, team, or servicemetadata→ file paths, component names, labels likedesign_decision,lint_rule,migration_step
The agent writes to Mem0 each time a conversation produces a reusable insight. On every new request, it retrieves relevant memories and feeds them into the model as context.
Building a code-aware agent with Mem0
This section walks through a concrete Python setup for an LLM coding agent that can remember repository structure and user preferences.
Basic environment
Assume the following:
Python 3.10+
An LLM accessible via an OpenAI-compatible API
The
mem0Python client installed
Initializing Mem0 and an LLM client
Defining identifiers
Storing repository structure as memory
Suppose a code indexer has summarized key modules. The agent can inject these summaries into Mem0 as structural memory.
Storing design decisions and preferences
When the agent helps design a feature or adopts a pattern, it should persist that decision.
Typical examples:
"Prefer FastAPI for new HTTP services instead of Flask"
"Use pytest with fixtures, avoid unittest.TestCase"
"Return errors as structured JSON with
code,message, anddetails"
Retrieving relevant memory for a coding query
Now the core step: given a user request like "add an endpoint to create invoices," the agent retrieves memories that combine repository structure, design decisions, and preferences.
Constructing an LLM prompt with memory
This pattern allows the agent to "remember" that for this repository:
HTTP endpoints live under
payments/api.pyDomain logic belongs in
payments/domain/invoices.pyThe team prefers FastAPI and pytest
The model does not need to rediscover these rules from scratch every time.
Handling evolving codebases and refactors
Real repositories change over time. Without care, a memory system will drift and feed the LLM obsolete guidance.
Mem0 does not automatically infer refactors from git history, so the agent must orchestrate updates. Common patterns include:
Memory invalidation with metadata
Tag memories with a version or commit range, then add newer memories with later versions.
When querying, filter out deprecated memories.
Refactor-aware ingestion
A background worker can:
Listen to CI events or git hooks
Detect moved or renamed files
Update or recreate structural memories based on the new layout
Mem0's job is to store and retrieve; the ingestion logic lives in the agent stack.
Task-level memories
For long-running refactors, it is often helpful to create task-specific memories:
"Migration: move all decimal money computations to the Money class in
core/money.py""Refactor: split
payments/api.pyinto separate routers by resource."
The agent uses these to keep continuity across steps and across different engineers who collaborate with the same agent.
Comparison with purely local context approaches
The table below compares a coding agent powered only by local context (prompt stuffing and raw vector search) to one that uses Mem0 as a memory layer.
Aspect | Local context only | With the Mem0 memory layer |
|---|---|---|
User personalization | Per session, lost after restart | Persistent user preferences across sessions and projects |
Repository structure | Recomputed or re-indexed on each query | Stored as structured memories with metadata |
Design decision tracking | Buried in past messages or docs | Explicit memories, retrievable by type and scope |
Cross-session continuity | None or manual, relies on the user | Automatic via user and group identifiers |
Handling refactors | Embeddings of stale files linger in the index | Memories updated or deprecated explicitly |
Query expressiveness | Mostly similarity search | Similarity plus metadata filters and temporal reasoning |
Multi-agent collaboration | Hard to share context between tools | Shared memory across tools via Mem0 APIs |
Operational complexity | Ad hoc schemas, multiple stores | Unified memory abstraction, internal indexing |
The key difference is that Mem0 turns "context" into a first-class, queryable layer, rather than a throwaway byproduct of each interaction.
Limitations of this pattern
Memory, even with Mem0, does not remove the need for careful system design. There are several important limitations and tradeoffs to consider.
Memory cannot replace the source of truth
The codebase and its tests remain the source of truth. Memories should summarize, highlight conventions, and capture decisions, but they can be wrong or outdated. The agent must still read actual files when making changes.
An overreliance on memory can lead to hallucinated patterns if ingestion is incomplete or if the repository changes without updating associated memories.
Quality depends on what gets stored
Mem0 handles storage and retrieval, but the agent controls what content enters the memory. If the agent stores noisy or redundant information, retrieval quality will degrade.
Production systems often need:
Filters to decide which interactions are worth persisting
Deduplication or compression of similar memories
Periodic pruning of low-value or low-usage entries
Without this curation, the memory layer behaves like an unstructured log.
Temporal reasoning is not automatic
Mem0 supports metadata and updates, but the agent must encode temporal semantics explicitly. For example:
Distinguishing current coding standards from deprecated ones
Marking "experiment" decisions as lower confidence
Resolving conflicts between older and newer memories
If these patterns are not implemented, the model may receive conflicting guidance and produce inconsistent responses.
Multi-repo and multi-branch complexity
In organizations with many services, forks, and long-lived branches, mapping memory to the correct context becomes harder. A simple group_id = repo_name mapping may be insufficient.
Some additional design is required:
Use branch or environment identifiers in metadata
Store global organization-wide standards separately
Decide when to share memories across related repositories
These are architectural decisions outside Mem0's scope.
Privacy and compliance constraints
For some teams, storing long-term memories of code and discussions may trigger policy or compliance reviews, especially when self-hosting is not used.
Engineers must ensure:
Appropriate separation between users and groups
Respect for data retention policies
Clear handling of secrets and sensitive snippets
The memory layer simplifies the technical parts but does not replace governance.
Integrating Mem0 into a production agent stack
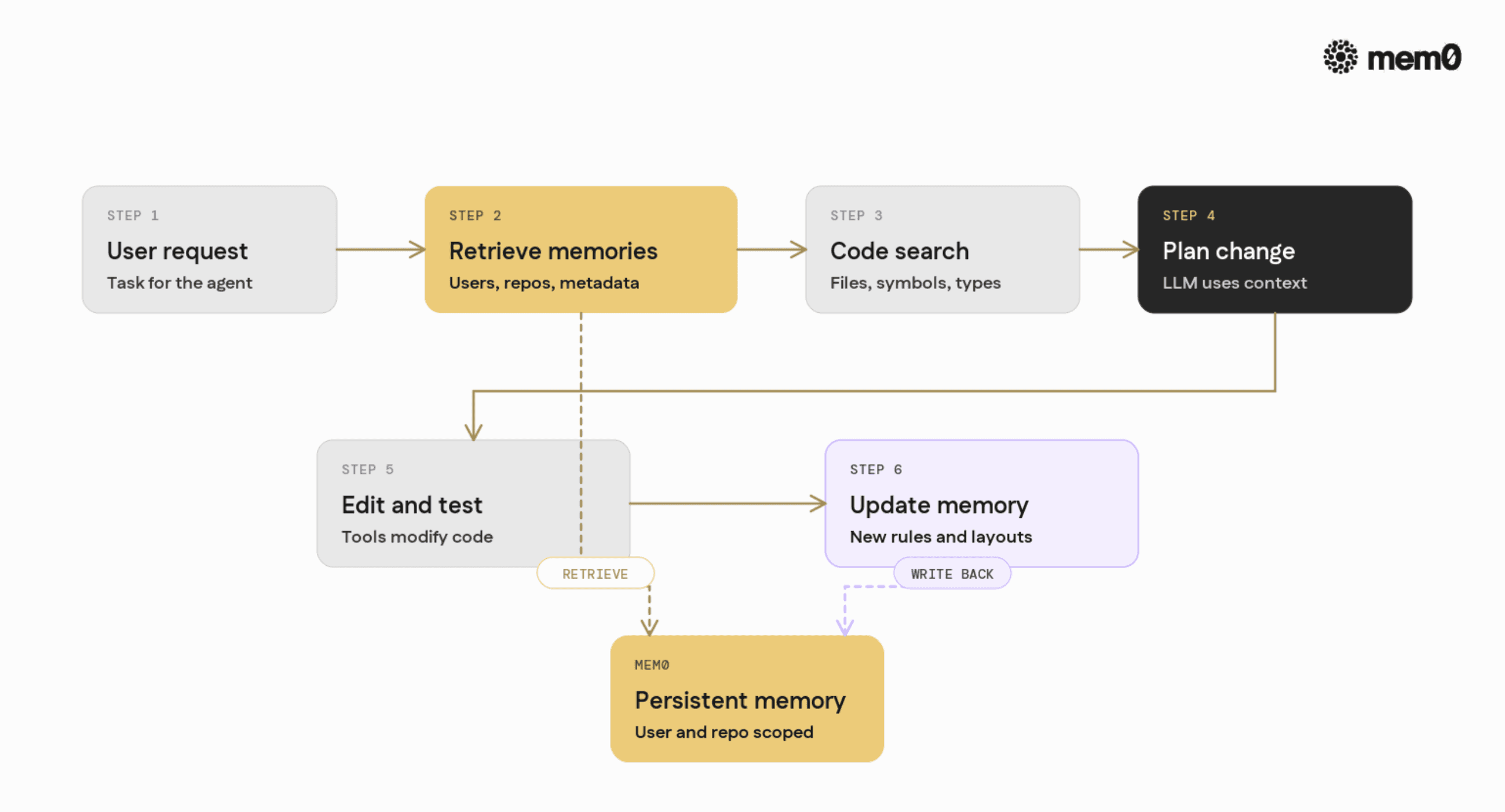
In a full production setting, Mem0 typically sits alongside:
A code search system (ripgrep, tree-sitter-based index, or a code-aware search service)
A task planner or orchestrator that sequences calls and tools
CI and git integration for event-driven memory updates
Analytics to monitor memory usage and impact on agent quality
A practical pattern for coding agents looks like this:
User request arrives
Example: "Add an endpoint to refund a payment."
Retrieve memories from Mem0
User preferences (API style, testing tools)
Repository structure memories for the relevant service
Design decisions around payments and refunds
Perform code search and static analysis
Find relevant files and symbols
Resolve actual function definitions and types
Plan the change
LLM uses both memory and current code to outline modifications
Apply edits and run tests
Tools modify files, run tests, record results
Update memory
Store new design decisions and patterns
Store key learnings from test failures and fixes
Deprecate memories that reference removed files or patterns
Mem0 provides the persistent layer for steps 2 and 6. The planner and tooling orchestrate everything else.
Closing thoughts
AI coding agents start to feel credible when they remember decisions from weeks ago, adapt to a repository's style automatically, and stop suggesting patterns that were explicitly rejected in past reviews. This behavior requires more than long prompts. It requires a durable, queryable memory layer that sits outside any single interaction.
Mem0 offers that layer for AI engineers building production agents. It provides persistent, structured memory that spans users, repositories, and sessions, without forcing each team to reinvent embeddings, metadata schemas, and retrieval logic.
By treating design decisions, repository structure, and user preferences as first-class memories, coding agents can progress from reactive code generators to long-term collaborators that evolve with the codebase.
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

