



The OpenAI Responses API changes how agents are built. Instead of a single chat completion call, it provides a unified interface for tools, function calling, and structured outputs. It aligns more closely with how agents operate in production: reasoning, taking actions, and streaming partial results.
This shift surfaces a persistent problem. Responses and real-time APIs are stateless from the server perspective. Long-term identity, preferences, and cross-session memory are left to the application. For toy projects, stuffing history into a context window works. For production agents, this breaks quickly.
A dedicated memory layer is required. Something that can track users, store evolving information, and inject only the relevant information into each Response call. Mem0 is designed as that layer.
What realtime agents actually need from memory
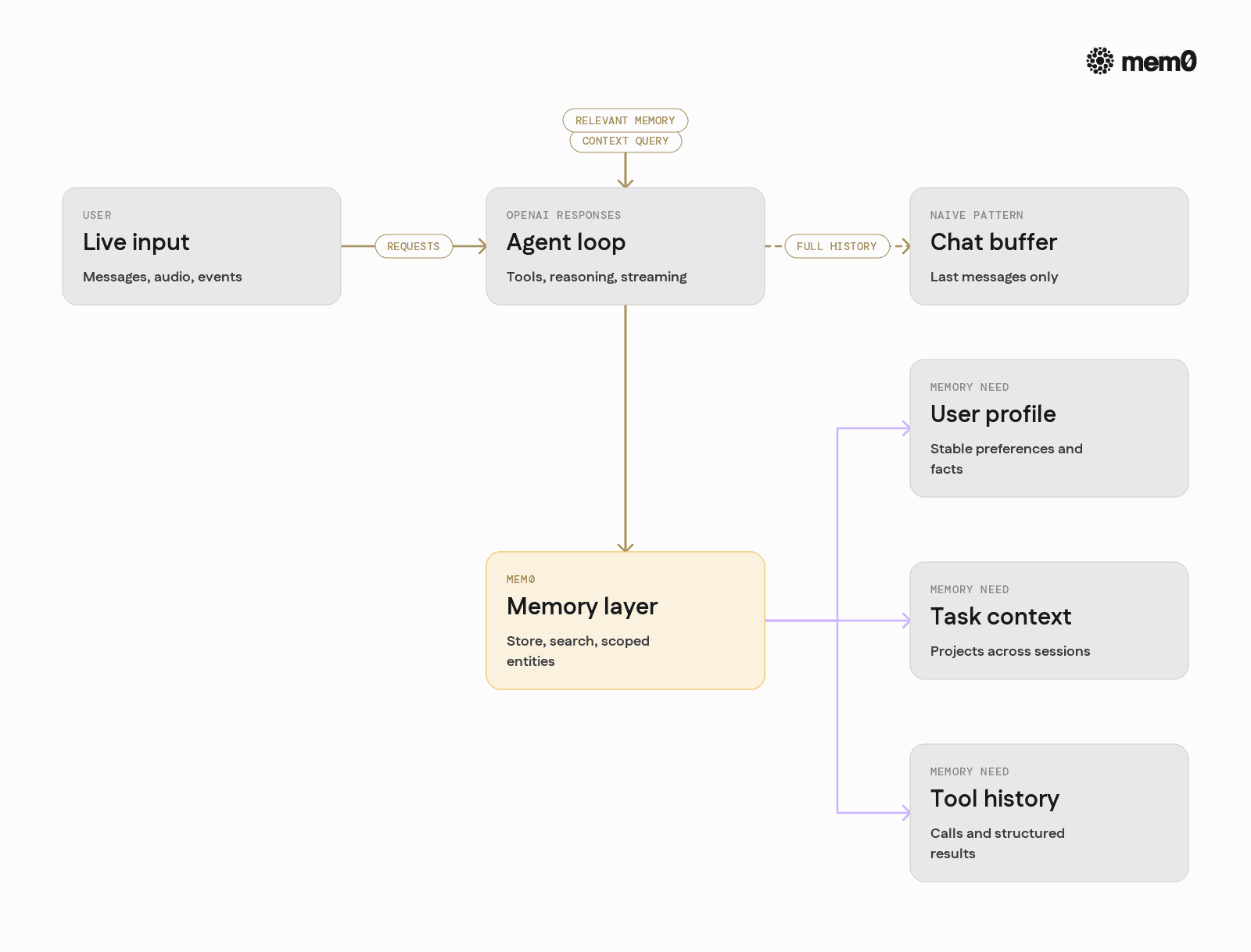
Realtime agents are different from synchronous chatbots. They must react to streams of events, respond with partial outputs, and maintain continuity across sessions and devices. That introduces several distinct memory needs:
Long-term user profile: Preferences, past choices, background, domain-specific facts tied to a user or entity.
Cross-session task context: Multi-step workflows that span sessions, for example, multi-day support tickets or projects.
Short-term ephemeral state: Recent messages, intermediate tool results, and local context that must not leak across users.
Tool-aware history: Records of which tools were used, with what parameters, and what they returned.
The OpenAI Responses API expects developers to feed in the relevant context. It does not know what to keep or discard. Without a focused memory layer, engineers end up reinventing ad hoc storage, sprawling context windows, and brittle heuristics.
Mem0 focuses on this missing middle. It tracks entity-scoped memories, retrieves relevant items per request, and keeps agent prompts lean even as memory grows.
How the OpenAI Responses API works for agents
The Responses API gives a single endpoint that covers several pieces:
Prompting with text or structured messages
Tool calling with schema definitions
Streaming of partial responses
Managed output formats for JSON or text
At a high level, a server-side agent loop uses it like this:
Collect user input and any relevant context.
Call the Responses API with tools and instructions.
Inspect output: text, tool calls, or both.
Execute tools and feed tool results back as inputs.
Repeat until the agent finishes.
For example, a basic Python call might look like:
This call knows nothing about the user. It does not remember that yesterday the same user said they prefer aisle seats or a specific airline. That knowledge must come from somewhere else.
Adding real-time streaming changes the memory problem
The OpenAI real-time stack enables bidirectional streaming of audio, text, and tool calls. A typical agent receives events like:
input_audio_buffer.appendinput_text_buffer.appendresponse.createdresponse.output_text.deltaresponse.completedresponse.output_tool_call.arguments.delta
Streaming changes timing and ordering. The agent may need to store memory when:
The user mentions a preference mid-conversation.
A tool returns structured data worth saving.
The agent finishes a multi-step task.
The real-time session itself does not persist memory. Once the WebSocket or session closes, the context is gone. A memory layer must attach to a stable key, such as user_id or session_id, and must be designed to handle frequent small updates.
Mem0 focuses on this exact pattern. It ingests small, structured memory items in near real time and can retrieve relevant context for the next Responses call or the next session.
The core memory problem in Responses and Realtime flows
With the Responses API and real-time, the core memory problem has three dimensions:
Quantity: History grows unbounded, and keeping everything in the context is impossible and expensive.
Relevance: Only some pieces of past interactions matter. The agent must focus on the right subset.
Structure: Many pieces are structured facts, not raw text. That structure should be stored and retrieved.
Without a memory layer, engineers try:
Dumping the full chat history into each request.
Maintaining manual JSON files or relational tables.
Writing custom embedding pipelines for search.
These approaches either break at scale or turn into brittle systems that are hard to extend. A memory layer must:
Accept raw text or structured data.
Index for semantic retrieval.
Attach to entities, such as user, project, device, or ticket.
Expose a simple API for add, search, and delete.
Mem0 provides that API, and can sit between the OpenAI agent loop and your storage.
How Mem0 fits into an OpenAI Responses agent architecture
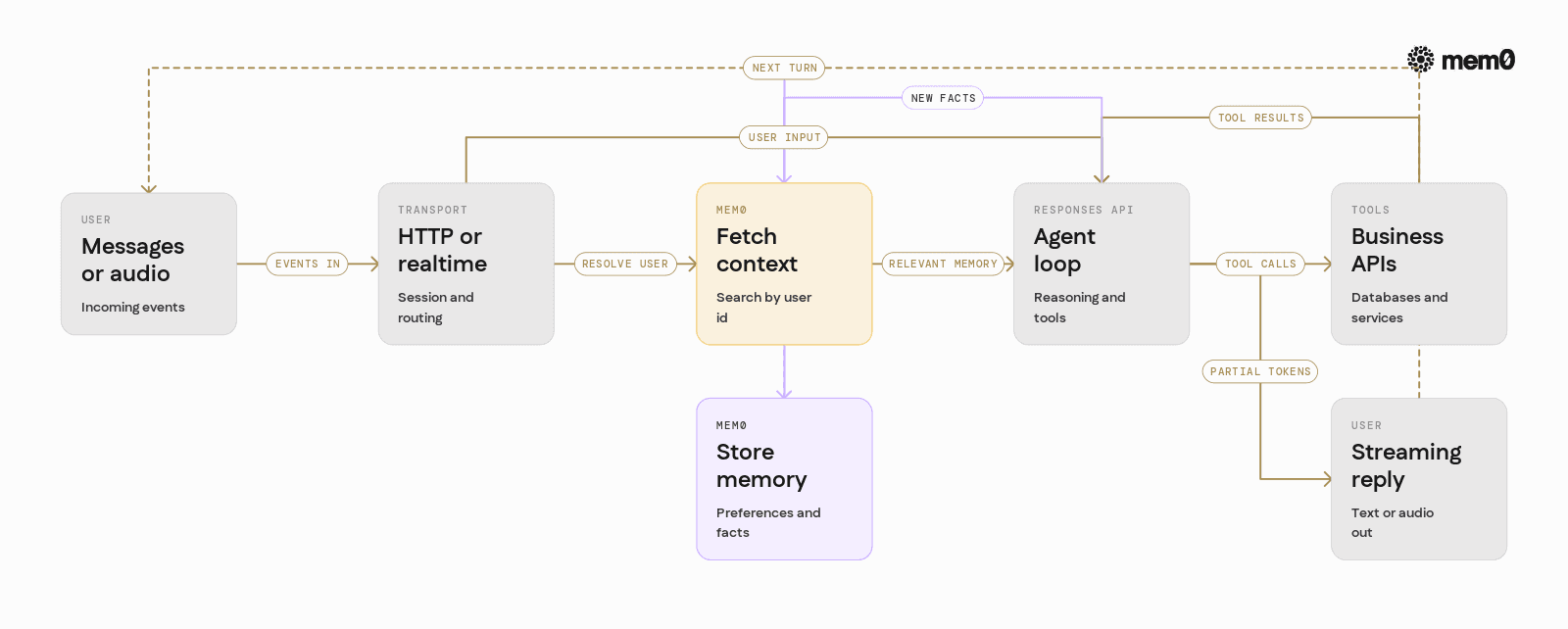
A practical architecture for agents using the Responses API with Mem0 usually has these components:
Transport: HTTP or real-time WebSocket handling user input and streaming output.
Memory layer (Mem0): Stores and retrieves long-term and mid-term memory per entity, often
user_id.Agent loop (Responses API): Orchestrates calls to
client.responses.createprocesses tools, and uses Mem0 for context.Application tools: Business-specific functions: databases, search, external APIs.
Data flow for a typical turn:
User sends a message or audio event.
Server resolves
user_idand calls Mem0 to fetch relevant memories: preferences, prior tasks.Server assembles
inputfor the Responses API, including retrieved memories as system context.Responses API streams partial outputs and/or tool calls.
When the agent expresses a new fact worth remembering, the server calls Mem0 to store it.
On the next interaction, Mem0 retrieves the updated memory.
This pattern keeps concrete responsibilities:
OpenAI handles reasoning and language.
Mem0 handles memory across time.
Application code glues them together.
Integrating Mem0 with the OpenAI Responses API in Python
The following Python example shows a simple integration for a text-based agent using the Responses API and Mem0. It focuses on long-term user preferences.
First, install dependencies:
Then implement a minimal agent loop:
💡 You'll need a free Mem0 API key to follow along.
This example keeps the memory logic explicit:
Fetch memories with
mem0_client.searchbefore each call.Build a system prompt with only relevant items.
Store new memories when the model suggests them.
In a realtime setup, the same pattern applies. The main change is event handling and streaming partial outputs instead of waiting for a single response object.
Comparing naive context management and Mem0
Engineers often start with a simple context buffer. The difference between that pattern and a dedicated memory layer like Mem0 is significant once agents are deployed.
Aspect | Naive chat history buffer | Mem0 memory layer |
|---|---|---|
Storage scope | Per session | Per user or entity across sessions |
Growth behavior | Unbounded, context window bound | Unbounded in storage, bounded at retrieval time |
Retrieval | Last N messages | Semantic search over all memories |
Structure | Mostly raw text | Text and structured fields with metadata |
Relevance filtering | Position-based (recent only) | Embedding similarity and metadata filters |
Multi-tenant support | Manual partitioning | Built-in user or entity scoping |
Tool output storage | Ad hoc or none | First-class, searchable memories |
Upgrade path | Hard to refactor once large | Designed for incremental extension |
Naive buffers can be enough for prototypes or small internal tools. For production agents, the lack of structure and search quickly limits context quality. Mem0 provides a consistent way to store and query memory without rewriting the agent loop.
Designing memory schemas for real-time agents
The effectiveness of memory depends on what is stored and how it is organized. For agents using the Responses and real-time APIs, a practical schema often includes:
User-level memory
Preferences (tone, format, domain interests).
Biographical details relevant to the tasks.
Repeated patterns (work hours, decision criteria).
Task-level memory
Ongoing project descriptions.
Previous intermediate outputs.
Past tool results that may be reused.
Interaction-level artifacts
Summaries of long conversations.
Extracted entities like companies, tickets, or topics.
In Mem0, this can be expressed via metadata:
During retrieval, metadata filters help select the right memory subset for a specific task:
This pattern ensures that the agent can adapt context depending on whether the user is asking a general question or continuing a specific project.
Limitations of memory patterns for Responses and real-time agents
Memory improves agent behavior, but it does not remove core constraints.
Models hallucinate: Persisted memory does not guarantee that the agent will respect it. Prompt design and tool use still matter, especially when mixing long-term memories with fresh inputs.
Relevance: Retrieval via embeddings and metadata can return noisy or partial context. There is always a tradeoff between recall and precision. Some tasks need stricter filters or a smaller set of memories.
Over-sharing: If memory is not scoped correctly, the agent may pull in irrelevant or sensitive data, for example, mixing two users with similar names. Clear entity boundaries and privacy controls are essential.
Latency and cost: Every additional retrieval and larger prompt increases latency and token usage. Memory must be used selectively. Not every interaction requires hitting the memory layer.
Concept drift and stale data: These can degrade behavior. Preferences or facts change. Without pruning or decay strategies, the agent might overfit to outdated knowledge. Memory systems need policies for updates, expiration, and correction.
These limits exist regardless of the memory layer used. Effective production agents combine memory with strict scoping, validation, and monitoring.
Frequently Asked Questions
What problem does Mem0 solve for the OpenAI Responses API?
Mem0 provides persistent, entity-scoped memory that the Responses API does not natively manage. It lets agents store and retrieve user preferences, facts, and prior tool outputs across sessions without inflating the context window.
How does Mem0 interact with real-time streaming agents?
Mem0 runs on the server side alongside the real-time session handler. The agent fetches relevant memories before sending prompts to the Responses API and writes new memories when the streaming interaction surfaces stable facts or preferences.
When should a Responses-based agent write to memory?
Agents should write to memory when the user provides stable information, such as preferences, profile data, or long-lived project details, and when tool outputs represent reusable knowledge. Transient or highly time-bound data usually belongs in short-term state, not long-term memory.
How much memory should be injected into each Response call?
Only a small, relevant subset should be injected, typically a few short paragraphs or bullet points. Mem0 helps by performing semantic search and filtering by metadata, so the agent receives concise context instead of full interaction logs.
Why not just use the full chat history with the Responses API?
Using full history quickly becomes expensive, slow, and eventually impossible as token limits are reached. It also mixes relevant and irrelevant context, which confuses the model. A memory layer stores everything but only retrieves what is useful for the current turn.
Can Mem0 handle different memory scopes like user and project simultaneously?
Yes, memories can be tagged with metadata to represent different scopes such as user, project, device, or ticket. Retrieval queries can filter on these tags so the agent can focus on the context that matches the current task.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

