



AI engineers are increasingly pushing inference to the edge, where models run on devices that are compute-constrained, intermittently connected, and short on storage. These agents still need long-term memory. They must remember users, devices, and environments across restarts and across locations.
That requirement conflicts directly with edge constraints because the local storage is limited and network links are unreliable. The result is a hard design problem where agents must feel stateful and contextual, while behaving stateless in practice.
Remote memory is the pattern that reconciles these constraints. This post explains what remote memory is, how it works for edge agents, where it breaks down, and how Mem0 provides a practical implementation that can ship in production systems today.
What remote memory means for edge agents
Remote memory is a storage and retrieval layer for agent state that lives off-device and out-of-process. The agent runs on an edge device. Its long-term memory lives in a network-addressable service.
Conceptually, the agent is split into three parts:
Stateless core: The model, prompt templates, tools, and behavior logic. This part runs at the edge and can be restarted or upgraded without losing continuity.
Short-term working set: Recent conversation turns or sensor readings that fit within context limits. This often stays in RAM and dies with the process.
Remote long-term memory: User profiles, device history, multi-session context, and derived facts stored in a shared memory layer, accessed over the network.
This pattern is particularly valuable in three scenarios:
Devices that reboot frequently or rotate instances
Agents that must share memory across multiple devices or channels
Systems that must enforce privacy boundaries while still maintaining personalization
Remote memory gives edge agents the illusion of continuity across sessions and surfaces, without requiring them to carry state locally for long periods.
Why edge agents cannot rely on local memory alone
Edge deployments push compute closer to users and sensors, but introduce constraints that make local memory difficult.
Storage and compute limits
Many edge devices have:
Limited persistent storage, sometimes only a few hundred megabytes
Low-power CPUs or small NPUs
No support for heavy local databases or vector indexes
Keeping full conversation histories or embeddings locally is often not feasible. Even when it fits initially, it does not scale across thousands or millions of devices.
Intermittent connectivity and mobility
Agents that run on:
Mobile devices
Industrial sensors
Retail kiosks
These often move between networks. They lose connectivity, change IPs, and may not always be able to reach a central service.
A purely cloud-based agent would fail under these conditions. A purely local memory design would fragment context across devices and make cross-device personalization impossible.
Privacy and regulatory constraints
Local memory can be good for privacy, but it also introduces challenges:
Devices may change owners or users
Data retention policies may require centralized audit and control
Encryption at rest and key management are harder to enforce uniformly across heterogeneous hardware
Remote memory, when done correctly, allows centralized control over what is stored and for how long, while still enabling personalization at the edge.
How remote memory architectures work
A practical remote memory architecture for edge agents typically uses four layers:
Identity and scope
Observation capture
Storage and retrieval
Summarization and pruning
Identity and scope
Every memory must be associated with an identity:
User ID
Device ID
Workspace or household ID
Application or agent namespace
For edge agents, identities may need to be:
Derived from login or authentication tokens
Derived from device serials or hardware IDs
Combined, for example
(user_id, device_id)
The memory layer must support queries by these keys and enforce isolation between them.
Observation capture
The agent decides what to remember. Common categories:
User preferences and routines
Device configuration and calibration
Summaries of long conversations
Extracted facts and goals
These are usually extracted from:
Model outputs
Parsed logs
Direct instrumentation in the agent code
Storage and retrieval
Remote memory needs indexing, search, and relevance ranking:
Vector search for semantic recall
Filters by metadata such as timestamps, tags, and user IDs
Sorting by recency, importance, or a scoring function
The agent then merges retrieved memories into prompts. At the edge, this must be efficient in terms of tokens and latency.
Summarization and pruning
Raw histories grow unbounded. A useful remote memory layer:
Periodically summarizes older entries into compact representations
Prunes low-value items
Maintains a mixture of raw facts and higher-level summaries
For edge agents, this also reduces bandwidth. Devices send fewer, richer updates to the remote memory store.
Remote memory patterns for edge deployments
Several practical patterns appear again and again in edge systems.
Pattern 1: Remote long-term, local short-term
Local: last N interactions or sensor frames
Remote: distilled facts, user profile, task history
Flow:
The agent runs at the edge and interacts with the user or environment
It keeps a sliding window of the most recent context locally
At significant events, it writes distilled observations to remote memory
In each new session, it fetches relevant memories from remote storage
This gives responsiveness and resilience to disconnections while still benefiting from long-term memory.
Pattern 2: Shared memory across devices
Multiple edge devices serve the same user or household:
Smart home devices
Retail or hospitality kiosks
Vehicle fleets shared by drivers
Each device writes to and reads from a shared remote memory keyed by a common user or group ID. The agent experiences cross-device continuity without local state replication.
Pattern 3: Hierarchical memory
Some deployments use a hierarchy:
Device-level edge memory
Gateway or local server memory
Cloud-level memory
Memories propagate upward for aggregation and downwards for personalization. The remote memory layer provides consistent APIs across these levels.
How Mem0 provides remote memory for edge agents
Mem0 is an open-source memory layer that implements these patterns through simple APIs. For edge use cases, three design points matter most:
Identity-aware memory: Every memory item is associated with an
entity_idand metadata. Agents can read and write with fine-grained control over scope.Semantic retrieval with metadata filters: Mem0 stores embeddings and metadata, then exposes query APIs that return relevant memories as structured objects.
Deployment flexibility: Mem0 can run as a hosted service or be self-hosted near the edge gateway. Edge devices only need to speak HTTP, so they remain lightweight.
Mem0 focuses on the memory problem: how to store, retrieve, and manage long-term context for AI agents, regardless of where inference runs. This separation is ideal for edge systems.
Mem0 integration in an edge agent
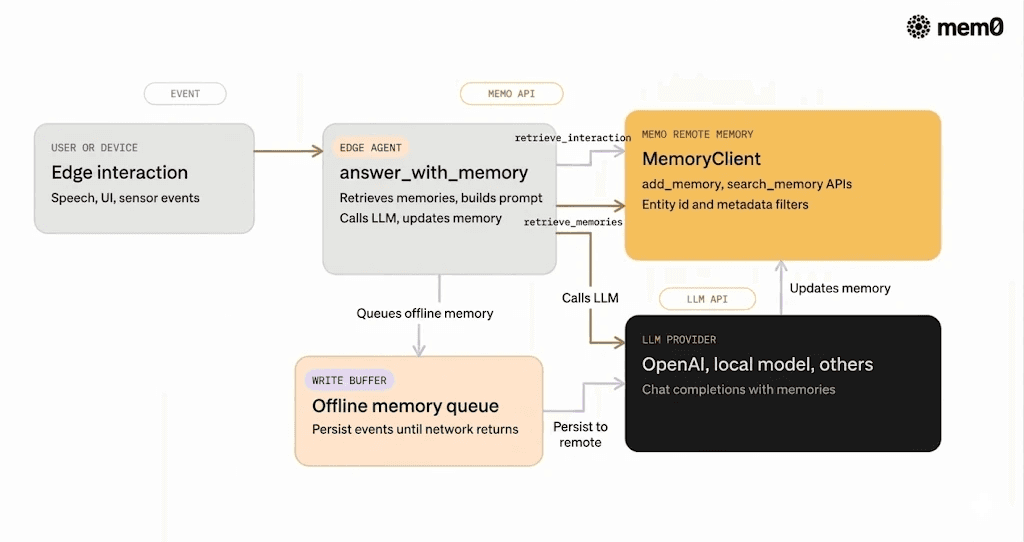
The core integration pattern is:
Initialize a Mem0 client with API credentials
When significant events occur, write memories with metadata
Before each LLM call, query Mem0 for relevant memories
Build prompts that combine the current context and retrieved memories
Optionally write back new summaries or updates
Below is a concrete Python example that fits an edge assistant scenario.
Setup: installing dependencies
On the edge device or gateway:
Python example: Edge assistant with remote memory
💡 You'll need a free Mem0 API key to follow along.
Get one at app.mem0.ai
This script assumes the edge agent has short bursts of connectivity to talk to Mem0 and the LLM. In practice, engineers usually:
Wrap calls in retry logic
Queue memory writes for later if offline
Cache a small set of recent memories locally
Comparing remote and local memory for edge agents
The choice is not binary. Most systems combine both. The table below summarizes the tradeoffs.
Aspect | Local memory on device | Remote memory with Mem0 |
|---|---|---|
Persistence across reboots | Fragile unless carefully managed | Durable and centralized |
Cross-device personalization | Hard, requires sync | Native, shared by entity_id |
Storage limits | Constrained by device hardware | Scales with backend resources |
Connectivity requirements | None for access | Needs network for reads and writes |
Privacy control and auditing | Distributed and heterogeneous | Centralized policies and audit trails |
Update and schema evolution | Requires device firmware updates | Handled in the memory service |
Token and prompt efficiency | May be high without summarization | Can be centrally summarized and deduplicated |
Implementation complexity | Simple locally, complex at scale | Simple device code, complex logic centralized |
Edge agents benefit from keeping critical short-term context locally. Remote memory, especially with a dedicated layer like Mem0, handles long-term, cross-device, and cross-session context where local solutions struggle.
Designing identity and namespaces with Mem0
For production edge deployments, identity design is often the hardest part of memory modeling. Mem0 provides flexible identifiers and metadata that help with this.
Common patterns include:
User identity:
entity_id = user_idUser identity is good when users authenticate on each device. Memories follow the user.Device identity:
entity_id = device_serialThis is useful for device-specific calibration or maintenance history.Composite identity: Encode both user and device in metadata
For example:entity_id = user_id, with metadata{"device": device_serial}. Retrieval filters can then choose between user-level or device-level context.
Mem0 APIs support:
Structured metadata on each memory item
Filters on metadata during retrieval
Independent namespaces for different agents or applications
This lets engineers run several edge agents that share or isolate memory as needed, without multiplying infrastructure.
Handling disconnections and sync at the edge
Remote memory must tolerate interruptions. In an edge environment, connectivity planning is as important as API design.
Common strategies with Mem0:
Write buffering: When the device cannot reach Mem0, it appends memory writes to a local queue. A background worker flushes this queue when the network returns.
Graceful degradation: If retrieval fails, the agent uses a fallback prompt built only from local context. It behaves like a stateless agent but continues to function.
Consistency model: If a user talks to two devices that are offline, their memories merge when connectivity returns. Mem0’s identity and metadata help reconcile these histories at query time.
Bandwidth shaping: Devices can throttle memory writes by summarizing several events locally into a single memory item before sending it to Mem0.
These patterns keep edge agents responsive and useful even when remote memory access is partial or delayed.
Limitations of remote memory patterns at the edge
Remote memory is powerful, but it is not a universal solution. Certain constraints and pitfalls remain.
Connectivity dependency: Even with buffering and fallbacks, many of the benefits of remote memory require network access. In fully air-gapped deployments, remote memory is not applicable.
Latency sensitivity: If memory reads occur in the critical path of user interactions, p95 latency can suffer. Engineers must either colocate Mem0 near edge gateways or design agents that can proceed without immediate remote recall.
Over-collection of data: Without disciplined extraction logic, agents may send too much raw data to remote memory. This increases cost and makes retrieval noisy. Summarization and filtering policies are essential.
Identity ambiguity: In shared devices or multi-user environments, incorrect identity assignment can leak context between users. Identity management and authentication must be designed and enforced carefully.
Prompt bloat: Remote memory can surface many relevant items. If agents naively dump all of them into prompts, token usage and model latency grow. Pragmatic selection and summarization are required.
These limitations are intrinsic to the pattern itself. Mem0 provides tools to manage them, but engineers still need to design policies, thresholds, and fallbacks aligned with their specific product and compliance requirements.
Frequently Asked Questions
What is remote memory in the context of edge AI agents?
Remote memory is a service that stores and retrieves long-term state for agents outside the device where inference runs. The edge agent queries this service for relevant memories and remains mostly stateless locally.
How does Mem0 integrate with agents running on constrained edge hardware?
Edge agents call Mem0 through lightweight HTTP APIs using small JSON payloads. Most of the heavy work, such as indexing and semantic search, happens in the Mem0 service, so edge devices stay minimal.
When should an engineer prefer remote memory over purely local storage?
Remote memory becomes essential when agents must persist context across reboots, share state across devices, or comply with centralized privacy and retention policies. Local-only approaches break down when personalization and history must span multiple surfaces and long timeframes.
Why not store everything in the LLM context window instead of remote memory?
Context windows are limited, expensive, and tied to each individual inference call. Remote memory persists beyond a single request and can be searched semantically so that only the most relevant pieces are added to prompts.
How does Mem0 handle identities and multi-tenant deployments for edge agents?
Each memory in Mem0 is scoped by an entity_id and may include application-specific metadata. This lets engineers isolate users, devices, and tenants while still sharing infrastructure across many agents.
What happens if an edge device loses connectivity while using Mem0?
The agent can continue working with local short-term context and queue memory writes for later transmission. When connectivity returns, queued updates can be sent to Mem0 and future queries will again benefit from the full long-term memory.
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

