



Most developers who claim their agent "has memory" have actually built a retrieval system. Plugging Chroma or Pinecone into an agent pipeline gives the agent the ability to find similar text, but similarity search and memory are not the same thing.
What a vector database actually is
A vector database stores dense numerical representations of text, called embeddings, and retrieves them by approximate nearest neighbor (ANN) search. When a query arrives, the database embeds it, computes similarity scores against stored vectors (typically cosine similarity or dot product), and returns the top-k results above a score threshold.
Chroma, Pinecone, Qdrant, Weaviate, FAISS, and PGVector all do this. Their differences are operational: Chroma runs in-process or as a server, Pinecone is managed cloud-only, Qdrant supports payload filtering with strong consistency, PGVector lives inside PostgreSQL so it shares the same ACID guarantees as the rest of the database.
What they all share is the same fundamental design: they are embedding stores with ANN retrieval. They know nothing about the content of what they store. They cannot distinguish a user preference from a random sentence. They have no awareness of time, contradiction, or relevance to a task.
Why developers reach for vector databases as memory
The intuition is sound. Memory retrieval should surface things that are semantically related to the current context, not just exact keyword matches. A user who asked about "Python async patterns" three weeks ago probably finds that relevant when they're debugging asyncio today. Embedding-based retrieval handles this gracefully.
The workflow seems natural: embed conversation turns, store them, query at agent startup. This approach works for simple cases. When the task is pure document retrieval or FAQ lookup, a vector database is often exactly the right tool.
The problem surfaces when the developer expects the vector database to behave like memory, which involves more than retrieval. Memory implies knowing what is worth remembering, keeping information consistent over time, and updating beliefs when new information contradicts old ones.
The four things vector databases cannot do for memory
Extraction. A vector database stores whatever it is given. If the developer passes an entire conversation turn, the database embeds and stores the whole thing, including filler, greetings, and noise. Deciding which fragments of a conversation represent durable facts worth storing is a separate problem. Vector databases do not solve it.
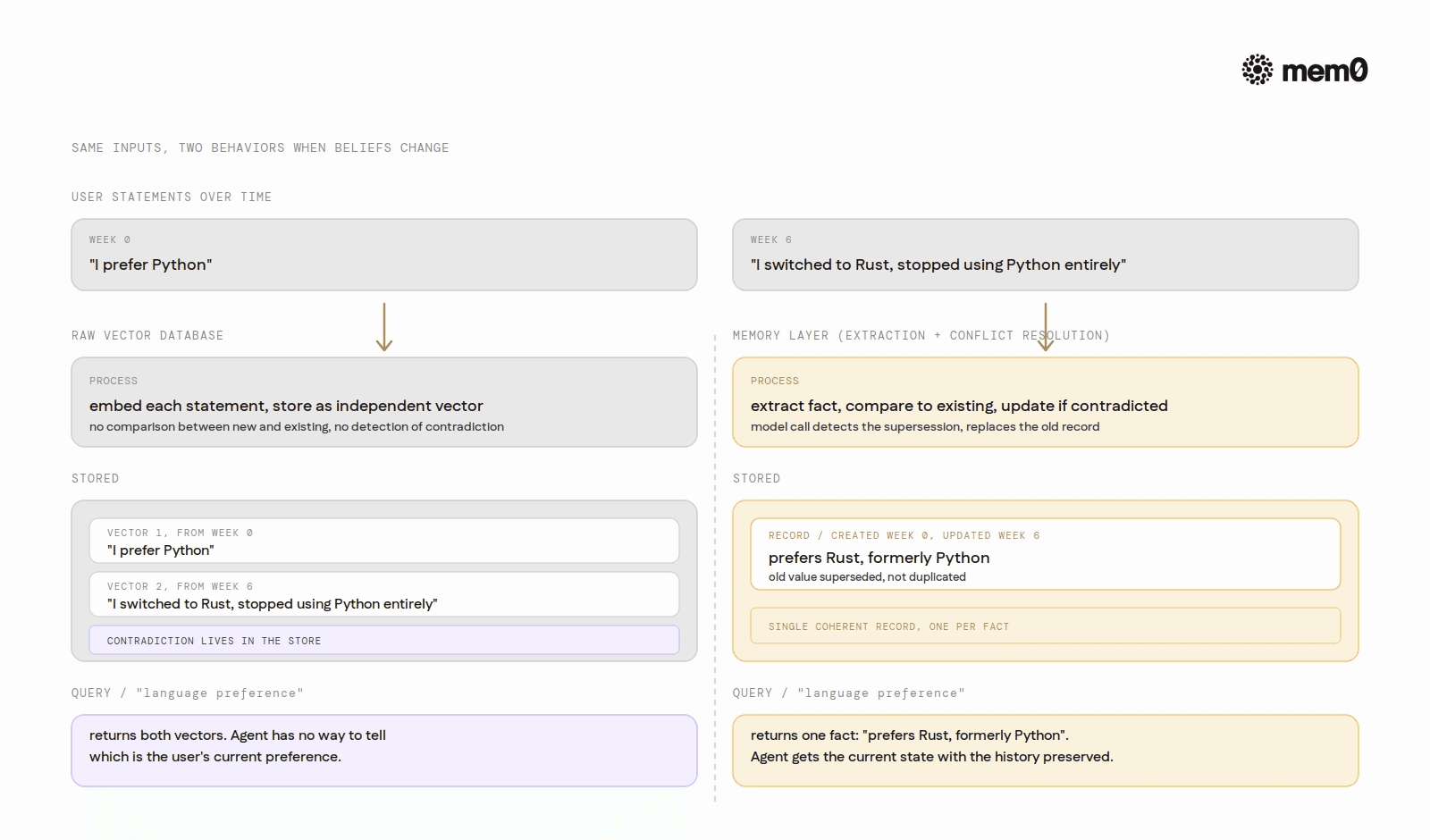
Conflict resolution. If a user tells an agent "I prefer Python" and six weeks later says "I switched to Rust, stopped using Python entirely," both statements live in the store as independent vectors. A similarity query for "programming language preference" may return both, or may return only the older one if its embedding happens to score higher. The database has no mechanism to detect that the newer statement supersedes the older one.
Temporal reasoning. Vector databases can filter by metadata fields like timestamps, but filtering and reasoning are different things. The database does not understand that "I used to use Python" should be weighted less than "I now use Rust." Recency must be encoded manually by the developer, and most implementations do not bother.
Relevance beyond similarity. ANN retrieval ranks by vector distance, not by task relevance. A stored fact about a user's hometown may have a higher cosine similarity to a query than a fact about the user's technical background, even if the technical fact is what the agent actually needs. Similarity is a proxy for relevance, not the same thing.
What a real memory layer needs on top of vector infrastructure
A memory layer handles three responsibilities that a vector database leaves to the developer:
First, extraction: given a raw conversation or document, identify which statements represent durable facts worth storing. This requires a model call, not just an embedding.
Second, deduplication and conflict resolution: before writing a new fact, check whether a semantically similar fact already exists. If it does and the new fact contradicts it, update the existing record. If it is consistent, skip or merge.
Third, structured retrieval: semantic similarity search alone misses facts that share topic but not vocabulary. A hybrid approach that combines vector similarity with keyword matching (BM25 or equivalent) captures both.
Comparison of approaches
Capability | Raw vector database | Vector database with memory layer |
|---|---|---|
Store arbitrary embeddings | Yes | Yes (handled internally) |
ANN retrieval by similarity | Yes | Yes |
Extract facts from raw conversation | No | Yes |
Detect and resolve contradictions | No | Yes |
Update memories when facts change | No | Yes |
Temporal reasoning / recency weighting | Manual | Built-in |
Keyword + semantic hybrid retrieval | Partial | Yes |
Multi-user isolation | Manual (metadata filters) | Built-in |
Raw Vector Database vs Memory Layer
Raw Chroma approach requires the developer to handle chunking, metadata, and all retrieval logic manually:
With a memory layer, the developer passes raw conversation turns and the system handles extraction, deduplication, and conflict resolution automatically. The critical difference is that the add call runs a model-based extraction step before writing to storage: if a user previously stated 'I prefer Python' and a new message says 'I switched to Rust,' the existing memory is updated rather than creating a duplicate.
Supported vector backends in Mem0
Mem0 uses vector databases as a backend, not as a replacement for them. The memory layer sits on top. Supported backends for the open-source Memory class include: Qdrant (default), Chroma, Pinecone, PGVector, Redis, FAISS, Weaviate, Milvus, MongoDB, Elasticsearch, OpenSearch, Supabase, Azure AI Search, Upstash Vector, Valkey, Amazon S3 Vectors, Databricks, Turbopuffer, and others. The full list is maintained at the Mem0 vector database docs.
Switching backends requires a config change, not a code change: the memory layer API remains identical regardless of which vector store is underneath.
How memory store quality degrades over time
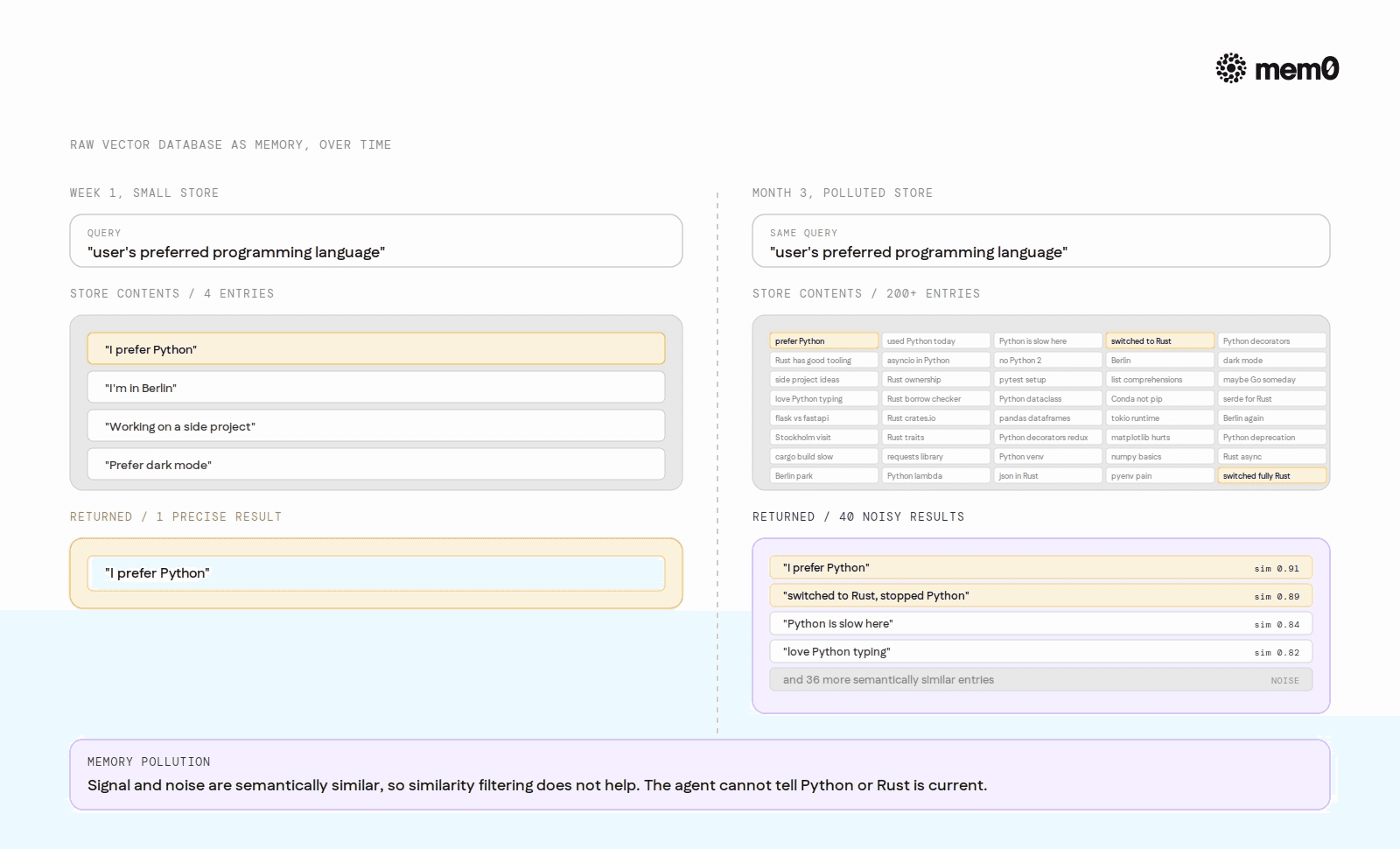
The failure of a raw vector database as a memory layer is not always immediate. It is progressive. In the first week of deployment, the store has few entries and retrieval is reasonably accurate. At three months, the picture is different.
A store that receives every conversation turn without extraction accumulates hundreds of redundant and partially overlapping records. A query for "user's preferred programming language" might return 40 results: the original statement, dozens of sessions where the user mentioned Python in passing, and newer statements about switching to Rust. The agent receives all of them, weighted only by cosine similarity, with no way to determine which represent the current state.
The result is memory pollution: the store has grown to contain more noise than signal, and the noise is semantically similar to the signal, so similarity filtering does not help. Developers who have not designed for this discover it when users report that the agent seems confused about their preferences, or when they examine the store directly and find hundreds of conflicting records with no mechanism to resolve them.
This degradation is predictable and avoidable. Extraction prevents noise from entering the store. Conflict resolution prevents contradictions from accumulating. Without both, any store that receives raw conversational data will degrade with use rather than improving.
When raw vector databases are enough
Not every use case needs a full memory layer. Raw vector databases are sufficient when:
The task is document retrieval, not personalization. A chatbot over a knowledge base needs to find relevant passages, not track user preferences.
The agent is stateless by design. If each session is independent and no user state carries forward, there is nothing to deduplicate or update.
The developer controls what gets stored. Pre-processed, clean documents with no conflicts are a different problem from raw conversational data.
Latency is the primary constraint and the additional model call for extraction is too expensive for the use case.
For any agent that accumulates information about users or tasks across sessions, raw vector search will eventually produce stale, contradictory, or redundant context.
Mem0 on Top of Your Vector Store
Mem0 is not a replacement for the vector database. It is the extraction, deduplication, and fusion layer that sits above it. The vector database you already have (Qdrant, Chroma, Pinecone, pgvector) continues to handle storage and ANN retrieval. Mem0 decides what goes in, keeps it consistent, and retrieves through both semantic and keyword channels.
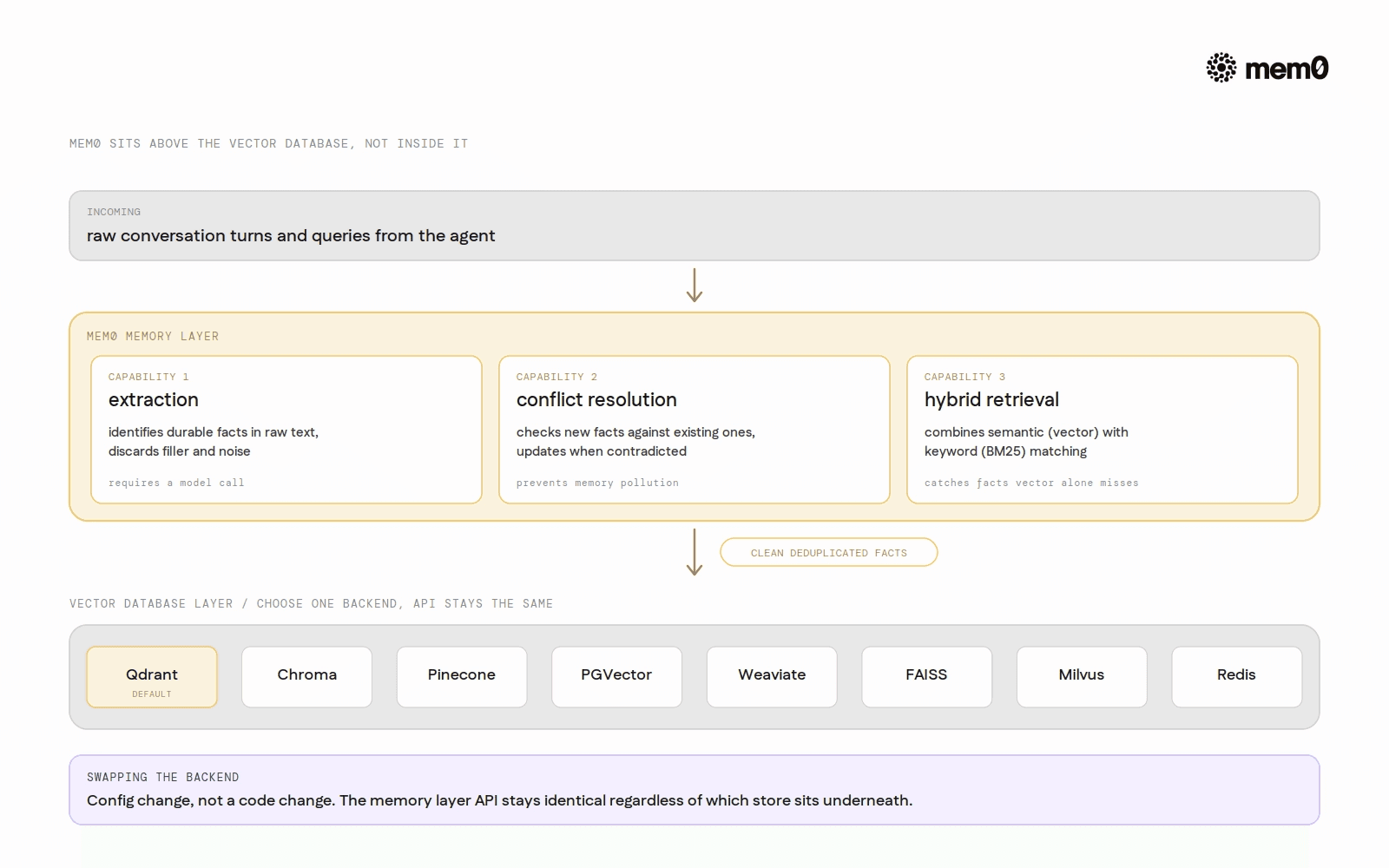
Switching the underlying store is a config change. The memory API stays the same.
The extraction step runs before anything hits the vector store. What gets embedded is a clean, deduplicated fact: not a raw message. Swapping to Chroma or Pinecone as the backend does not change the add or search API, and does not change the quality of what gets stored.
Final Notes
A vector database stores vectors. Memory understands what those vectors mean, keeps them consistent over time, and retrieves them in context. That distinction is what separates a retrieval system from an agent that actually remembers.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
If you are a human- Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

