



LangGraph, AutoGen, CrewAI, and LangChain are all open source. Each one ships with some form of memory handling.
Each one's memory story is different, and the gap between what the documentation implies and what actually happens in production is wide enough to cause real problems.
This article covers what each framework does for memory, where the gaps are, and how a framework-agnostic memory layer fills them.
What these frameworks are
LangGraph is a graph-based workflow orchestration library from LangChain. Workflows are defined as directed graphs where nodes are processing steps and edges are control flow. It prioritizes explicit state management and reproducibility: the developer sees exactly what state flows through each node.
AutoGen is a multi-agent conversation orchestration framework from Microsoft. It makes it straightforward to define agents with different roles, have them converse, and orchestrate complex tasks through back-and-forth exchange between agents.
CrewAI focuses on role-based task delegation. Developers define a crew of agents with specific roles and assign tasks. The framework handles the execution order and coordinates between agents.
LangChain is a composable library for building LLM-powered applications. Chains connect prompts, models, memory, and tools into pipelines. It is the most general-purpose of the four and the most widely deployed.
All four are open source and actively maintained.
The memory story in each framework
LangGraph. The built-in persistence mechanism is MemorySaver, a checkpointer that saves the full graph state at each step. When a workflow is interrupted and resumed, the entire graph state (all node outputs, channel values, pending tasks) is restored.
This handles workflow resumability well. It does not handle user memory. The full graph state from a run is not the same thing as curated facts about the user.
A production deployment receiving thousands of runs per day accumulates graph state that no agent will ever query for user context. Cross-thread memory, where facts from one conversation are available in future conversations for the same user, requires an additional layer beyond MemorySaver.
AutoGen. AutoGen defines a Memory protocol with add, query, update_context, and clear methods. Built-in implementations include ListMemory (in-process only), ChromaDBVectorMemory, and RedisMemory. The update_context method injects retrieved memories into the model context automatically.
The limitation is deduplication: if a user states "I prefer Python" in one session and "I work in Python" in another, both records accumulate in the ChromaDB store as independent vectors. There is no conflict resolution, no merging of near-duplicate facts. Stores degrade over time as redundant records accumulate.
CrewAI. CrewAI ships the most complete native memory system among the four. The current architecture uses a unified Memory class with composite scoring: semantic similarity, recency, and importance are combined at retrieval time.
The default backend is LanceDB, stored at ./.crewai/memory. Deduplication fires at a 0.85 cosine similarity threshold, which prevents exact and near-duplicate memories from accumulating. This is a meaningful improvement over a raw vector store.
LangChain. LangChain provides ConversationBufferMemory (stores the full conversation history) and ConversationSummaryMemory (stores an LLM-generated summary of prior turns).
Both are scoped to a single chain run. Neither does fact extraction, deduplication, or cross-session persistence.
For agents that need to carry user preferences forward across sessions, the developer handles the memory lifecycle explicitly.
The problem that cuts across all four
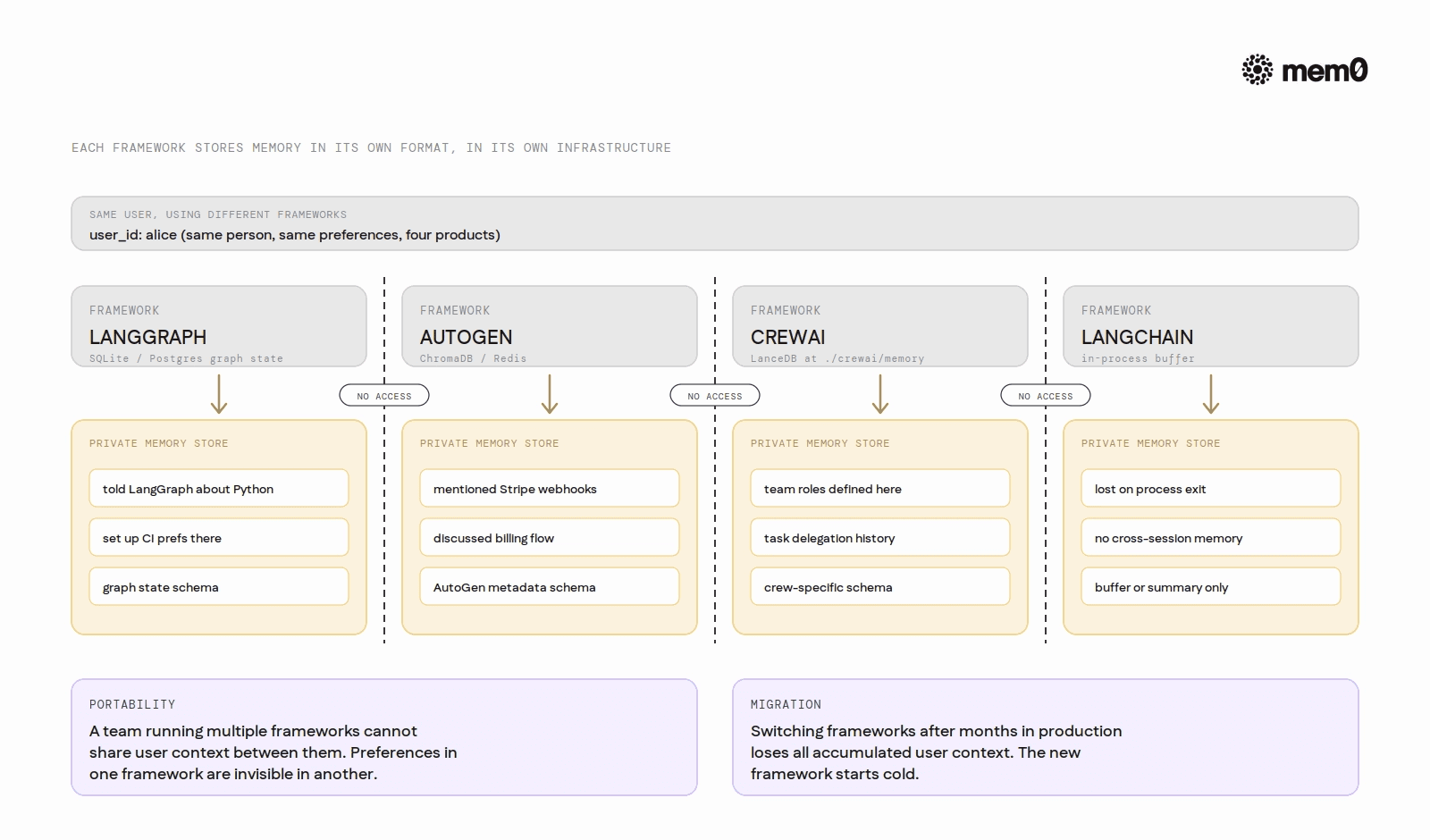
Each framework stores memory in its own format, in its own schema, backed by its own infrastructure. LangGraph state lives in SQLite or PostgreSQL with a LangGraph-specific schema. CrewAI memories live in LanceDB at ./.crewai/memory. AutoGen's ChromaDB store uses AutoGen-specific metadata. LangChain's buffer memory exists only in the running process.
This creates two practical problems.
The first is portability. A team running LangGraph for orchestration and AutoGen for sub-agent conversation cannot share user context through native memory. The two stores are incompatible. Preferences a user expressed in an AutoGen session are invisible to the LangGraph orchestrator.
The second is migration. When a team switches frameworks after six months in production, the accumulated user context does not transfer. The new framework starts cold. Every user who had established preferences with the old system loses that history.
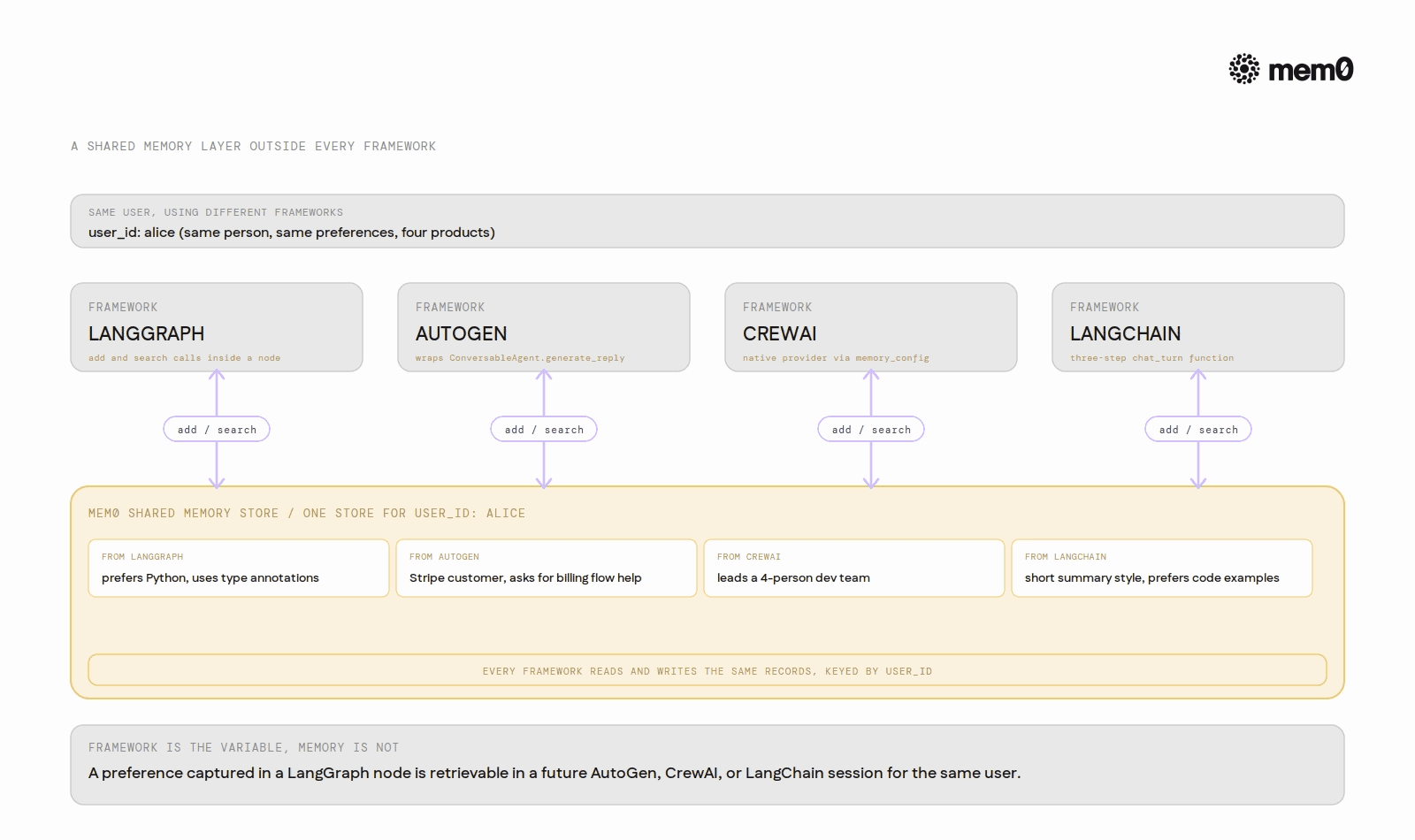
A framework-agnostic memory layer sits outside all four frameworks. It has its own API, its own storage, and is callable from any of them. The framework is the variable; the memory store is not. A preference captured during a LangGraph workflow is retrievable in a future AutoGen conversation for the same user because both call the same external memory API.
Comparison of built-in memory capabilities
Framework | Persistence | Fact extraction | Deduplication | Cross-session user memory | Mem0 integration |
|---|---|---|---|---|---|
LangGraph | Graph state (SQLite/Postgres) | No | No | Manual | Yes (direct API) |
AutoGen | ChromaDB / Redis | No | No | Manual | Yes (direct API) |
CrewAI | LanceDB (0.85 threshold) | LLM-powered | Built-in | Scoped | Yes (native provider) |
LangChain | In-process buffer/summary | No | No | Manual | Yes (direct API) |
Mem0 with LangGraph, AutoGen, CrewAI, and LangChain
The Mem0 API is the same across all four frameworks: add() to store a conversation exchange, search() to retrieve relevant memories by query. The framework wrapping the call changes; the memory store does not.
LangGraph (integration docs): Mem0 is called directly inside a graph node. The node searches memories before invoking the model and writes the exchange back after generating a response.
AutoGen (integration docs): Mem0 wraps the ConversableAgent call. Retrieve before generating, write after. The Mem0 search result is injected into the prompt manually before calling generate_reply.
CrewAI (integration docs): Mem0 is a native memory provider. No manual add or search calls are needed; the framework handles context injection and storage automatically when memory_config is set.
LangChain (integration docs): The pattern is a three-step chat_turn function: retrieve context from Mem0, generate a response with that context injected, then save the exchange.
Because all four patterns write to and read from the same Mem0 store, a preference captured in a LangGraph node is retrievable in a LangChain chat_turn for the same user. The memory follows the user, not the framework.
Final Notes
Open-source agent frameworks are the right tools for building agents. They are not designed to be shared memory stores. When memory is left to the framework, it becomes framework-specific, non-portable, and hard to migrate. Separating the memory layer from the agent framework keeps both concerns clean and makes the memory available across any part of the system.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
If you are a human- Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

