



The term "agent model" gets used to mean two different things: the LLM powering the agent, and the structural pattern of the agent itself. Confusion between the two leads to architectural choices that feel correct at prototype scale and fail in production.
This post focuses on the second meaning, specifically the design pattern that determines whether an agent stays fast, resumable, and cost-predictable as task complexity grows.
What "agent model" and "deep agents" mean in current usage
In the first sense, an agent model is the LLM backbone: GPT-4o, Claude Sonnet, Gemini 1.5 Pro. Choosing the right backbone matters for reasoning quality and cost per token.
In the second sense, an agent model is an architectural pattern: how the agent is structured, how it manages state, how it decides what to do next. This is what the "deep agent" pattern describes. A deep agent is not defined by the LLM it uses but by its operating characteristics: sequential, multi-step, tool-using, potentially long-running, often running unattended.
A shallow agent takes input, makes one or a few tool calls, and returns a result. A deep agent decomposes a complex task into subtasks, executes them over many steps, adapts based on intermediate results, and may run for minutes, hours, or across multiple sessions. The architecture requirements for these two patterns are radically different.
Why context window is the binding constraint for deep agents
The naive assumption is that context window length is the problem: if the model supports 128k tokens, a long-running task with lots of tool outputs will eventually hit the limit and fail. This happens, but it is not the primary failure mode in practice.
The binding constraint appears much earlier. Research and engineering experience consistently shows that retrieval quality degrades as context grows well before the hard token limit. When a model has 80k tokens of accumulated conversation history, tool outputs, and intermediate reasoning in its context, it struggles to locate and weight the most relevant facts from early in the conversation. Relevant information from step 5 gets diluted by the noise from steps 6 through 47.
The second constraint is cost. A deep agent processing 50 steps at 20k tokens per step is billing 1M input tokens on every reasoning call after step 50, assuming the full context is included. At $3-15 per million input tokens depending on the model, the economics of full-context deep agents are unsustainable at any real deployment scale.
The four failure modes of context-heavy architectures
Cost at scale. Context grows linearly with task length. Cost grows with it. A task that costs $0.05 at 10 steps costs $2.50 at 50 steps if the full context is retained and re-sent on every call. This is not a hypothetical: it is the operational reality for teams that build deep agents without context management.
Retrieval degradation in long contexts. LLMs have positional bias. Facts buried in the middle of a very long context receive less attention than facts at the beginning and end. A deep agent that stuffed everything into context by step 30 may effectively "forget" constraints it was given at step 3, even though those constraints are technically in the context window.
Compressor-induced fact loss. The common mitigation is summarization: compress the context at intervals and continue with the summary. This helps with cost but introduces a new failure mode: the compressor loses specific facts. A constraint like "do not call the external billing API during business hours" survives in a detailed log but may be dropped by a summarizer that abstracts it away.
Inability to resume. A context-heavy agent that crashes or is interrupted at step 35 has no recoverable state. The entire context lives in memory. Restarting means rerunning from the beginning, re-incurring all the cost and tool calls of the first 35 steps.
Four principles of memory-first architecture
Extract-before-compress. Before any context compression step fires, the agent writes what it has learned to a persistent memory store. Compression then operates on raw output, not on extracted facts. The facts survive compression because they were written out first.
Read-before-act. At the start of each agent turn, the agent retrieves relevant memories and injects only what is needed into the current context. The context stays small and task-focused regardless of how long the overall task has been running. The agent does not need to see every previous step, only the facts from previous steps that are relevant to the current one.
Task memory vs user memory. These are different stores with different lifecycles. Task memory records state specific to the current job: what has been tried, what failed, what constraints were discovered mid-execution, current progress. It is ephemeral and scoped to a single task run. User memory records durable facts about the user or domain: preferences, background, recurring patterns. It persists across sessions. Conflating these two leads to either stale task state polluting user memory or user preferences being discarded when a task completes.
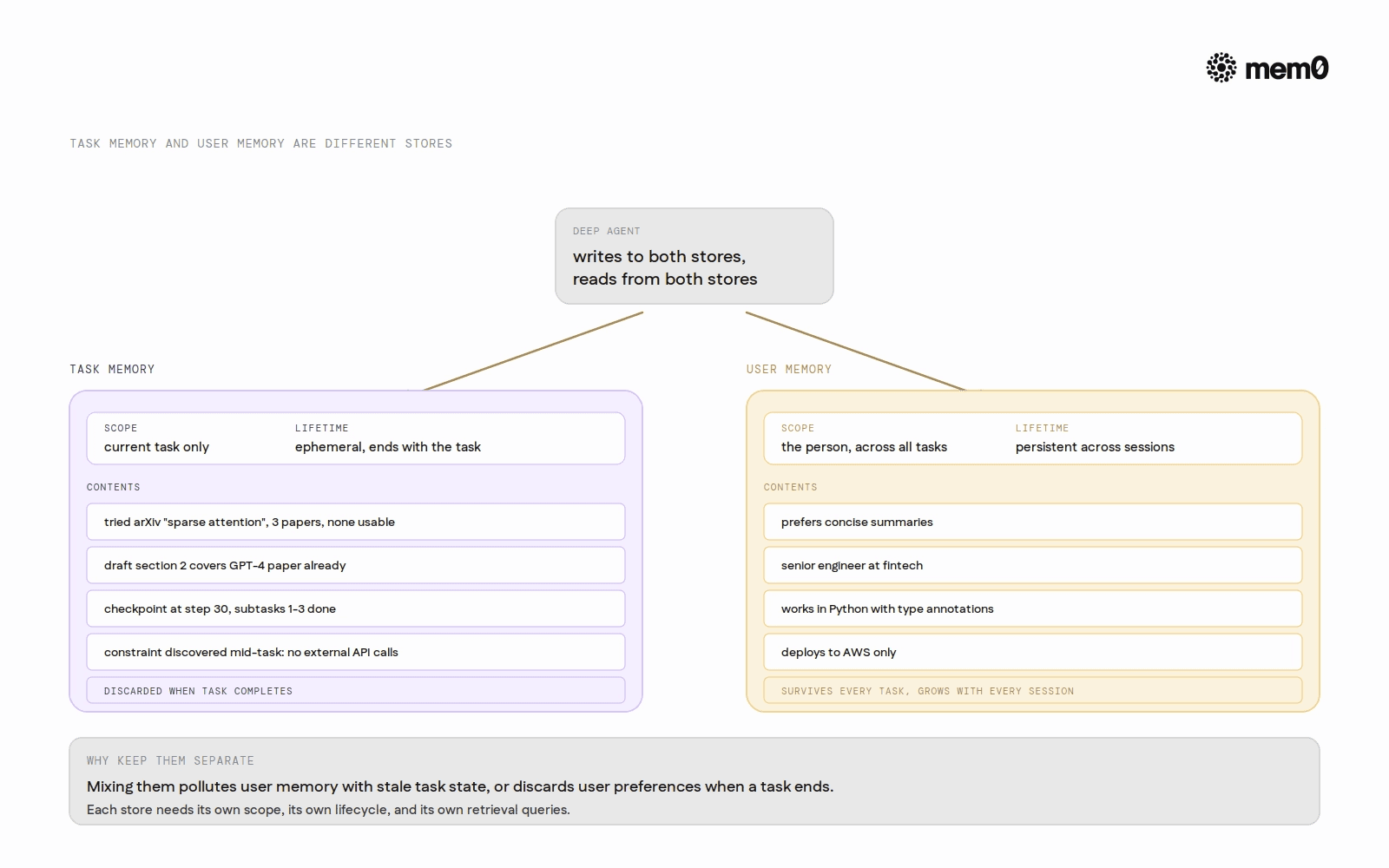
Checkpoint pattern. At each major workflow milestone, the agent writes a structured memory checkpoint that includes current state, decisions made, constraints discovered, and what remains. The checkpoint is explicit, not a summary of the conversation. It is a structured record that another process can read and act on.
The Three Functions of Memory-First Architecture
The pattern implements three functions. agent_step retrieves both task-scoped and user-scoped context at the start of each step, injects it into the model prompt, executes the step, then writes the result to memory before any compression. write_checkpoint stores a structured record of current state at major milestones: which subtasks are complete, which are pending, and what constraints were discovered during execution. resume_task retrieves the latest checkpoint so the agent can continue from where it stopped, without rerunning prior steps.
Context-heavy vs memory-first compared
Dimension | Context-heavy architecture | Memory-first architecture |
|---|---|---|
Context size at step N | Grows linearly with N | Bounded (retrieved slice only) |
Input token cost at step N | O(N) | O(1) |
Retrieval quality at step 50 | Degraded (dilution) | Stable (targeted retrieval) |
Crash recovery | Full restart from step 1 | Resume from last checkpoint |
Cross-session continuity | None (context lost) | Preserved (memory persists) |
Compressor fact loss risk | High | Low (extract-before-compress) |
Task vs user memory separation | None | Explicit (metadata-scoped) |
How memory-first changes the economics of deep agents
The cost math for context-heavy vs memory-first architecture is straightforward to model. Consider a 50-step research agent where each step generates 2,000 tokens of output from tool calls and reasoning.
In a context-heavy architecture, step 50 sends all 100,000 accumulated tokens plus the step's prompt as input to the model. At $3 per million input tokens, that single step costs $0.30 in input alone. Over 50 steps with accumulating context, the total input cost is approximately $3.75 per task run, before counting output tokens.
In a memory-first architecture, each step sends a fixed-size context: the system prompt (500 tokens), the retrieved memories (1,000-2,000 tokens), and the current step input (500 tokens). Total input per step stays around 3,000 tokens regardless of step number. Total input cost for 50 steps is approximately $0.45 per task run, a reduction of more than 80%.
The savings compound further when the same task type runs thousands of times per month. A context-heavy agent that costs $3.75 per run at 10,000 runs per month generates a $37,500 monthly input token bill. The memory-first equivalent costs $4,500. The difference funds significant engineering investment in memory infrastructure.
The resume pattern
The resume pattern is one of the most practical advantages of memory-first architecture. A context-heavy agent that crashes at step 35 of a 60-step task is gone. All intermediate state was in RAM. Starting over means re-running every tool call, re-incurring every API cost, and re-generating every intermediate result.
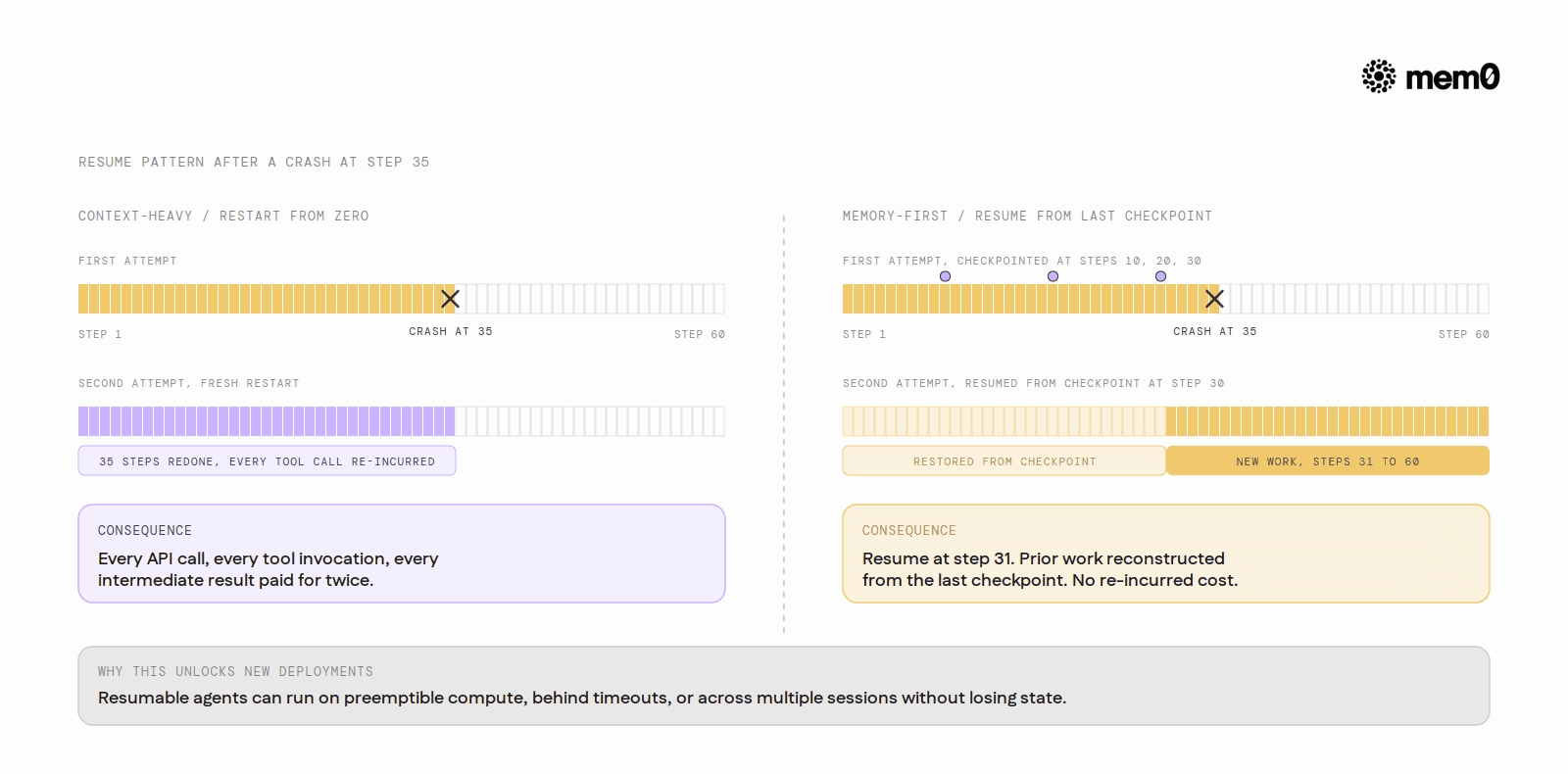
A memory-first agent writes checkpoints. To resume, the orchestrator queries for the latest checkpoint associated with the task ID, reconstructs enough context to continue, and picks up at the next step. The agent does not need to know it was interrupted.
This makes deep agents deployable in environments with time limits, preemptible compute, or unreliable infrastructure, since it no longer requires the task to complete in a single uninterrupted execution.
Mem0 in a Memory-First Agent
Mem0 implements all three principles of memory-first architecture in a single API. The same client handles task-scoped memory (what happened in this job) and user-scoped memory (what this person prefers across all jobs), with deduplication running automatically so checkpoint writes do not pile up.
The agent's context window stays bounded because each step retrieves only what is relevant to that step: not the full accumulated history. The checkpoint function gives the agent a resume point: if a long-running job is interrupted, the next invocation queries for the latest checkpoint and picks up from there rather than restarting from the beginning.
Final Notes
Memory-first architecture is not an optimization for deep agents; it is the prerequisite for building them at production scale: without it, task length and cost grow together until the economics become unworkable.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
If you are a human- Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

