



AI agents in production live or die by how they handle context. Users expect agents to remember preferences, past decisions, and prior conversations, and to show that memory at exactly the right moment. The core technical challenge is routing ambiguous user requests to the right memory operations.
Context queries are at the center of this problem. Some queries ask for new work, some ask for answers based on external tools, and some implicitly refer to prior context the user expects the agent to recall. Agents need a reliable way to detect these context queries, decide what to fetch, and link that with their memory layer.
This article explains what context queries are, how routing works, why naive approaches fail, and how Mem0 can serve as a dedicated memory layer that makes context routing reliable and maintainable in production agents.
What context queries are in AI agents
A context query is any user input where the correct response depends on prior interactions, user state, or historical data, and not just the current message. They are not just "remember this" instructions. They include implicit references such as:
"Can you book the same hotel as last time?"
"Use the configuration we used for the last benchmark."
"What did I say about alert thresholds earlier?"
From the agent's perspective, these queries require:
Detecting that the user expects continuity with the past.
Locating the right memory slice that satisfies this expectation.
Providing that memory to the model in a structured way.
Without a clear memory strategy, agents either ignore context, guess from conversation history only, or overload the prompt with irrelevant data.
In production, context queries show up in at least three patterns:
User profile and preferences: These include personal details, preferences, and constraints that shape decisions and responses.
Session and task state: Plans, intermediate results, and previous tool outputs that affect the current step.
Organizational or account context: Shared documents, configs, and policies relevant to a specific workspace or project.
Each pattern needs its own routing logic, and all of them need a memory abstraction that is separate from the LLM itself.
Why context routing is a memory problem
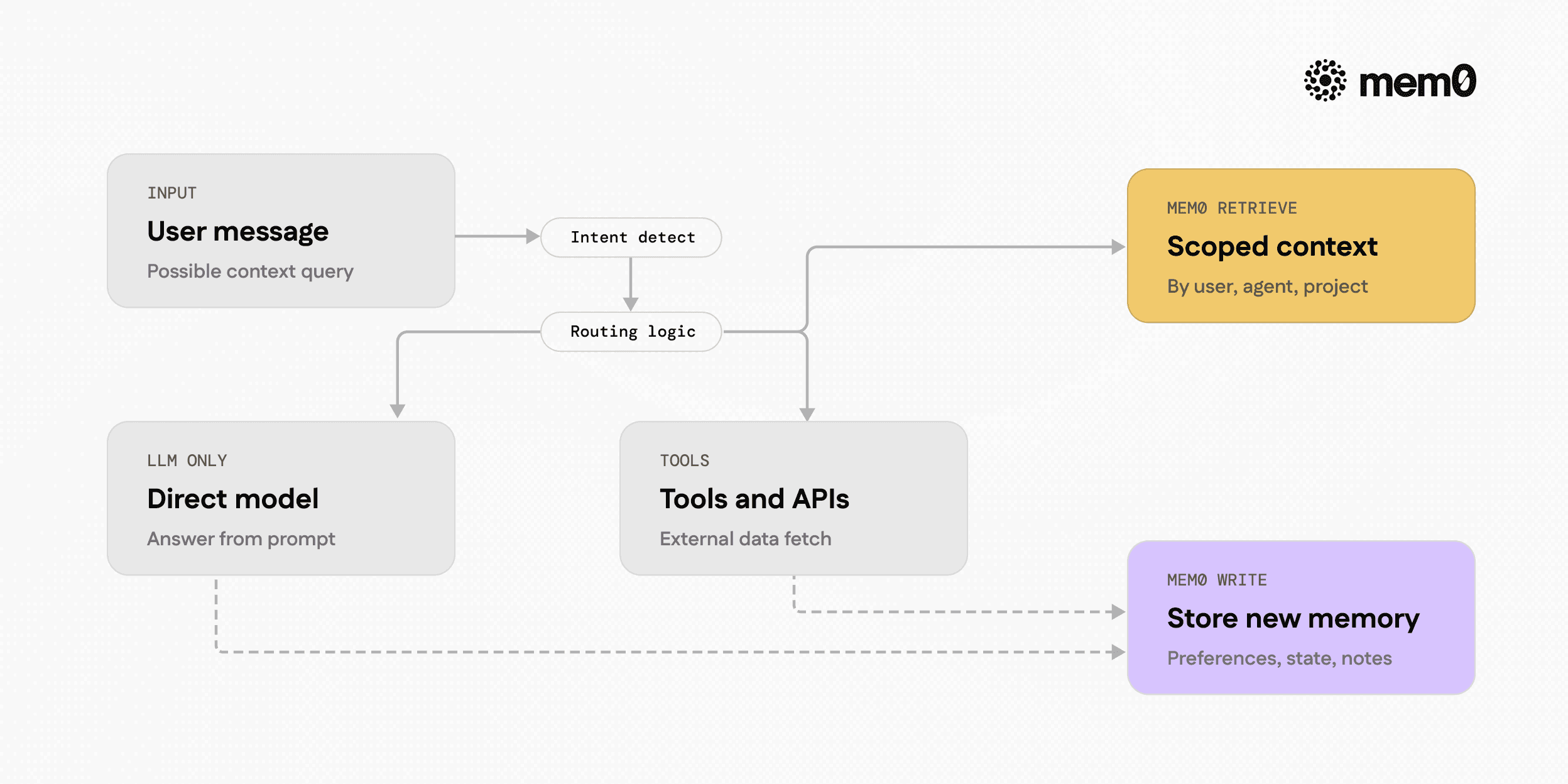
Fig: Incoming user message is classified into routing choices for direct answer, tools, or Mem0-backed memory operations
At first, context routing looks like a classification task. Given an incoming message, the agent must decide whether to:
Answer directly from the model,
Call a tool or external API,
Retrieve from memory, or
Combine several of these options.
The difficulty is that memory access is both semantic and structural. The agent not only needs to retrieve "similar" past text, but it also needs to understand which memory store to query, with which filters, and how to shape the retrieved content so the LLM can use it.
Common failure modes include:
Retrieving entire past conversations and hitting context limits.
Missing relevant information because the retrieval index is too coarse.
Retrieving conflicting memory entries with no ranking logic.
Mixing user-specific and global knowledge incorrectly.
All of these are symptoms of memory being treated as a vague vector store rather than a first-class component with schema, policies, and routing.
Mem0 approaches this as a structured memory layer. It attaches memory operations to identities, agents, and sources, and exposes retrieval and write APIs that agents can call deterministically. This supports routing decisions like:
"This looks like a preference query: retrieve user memories for user_id X."
"This is project-specific, retrieve for org_id Y and workspace Z."
"User asked about a previous plan, retrieve agent memories for agent_id A."
Core patterns for routing context queries
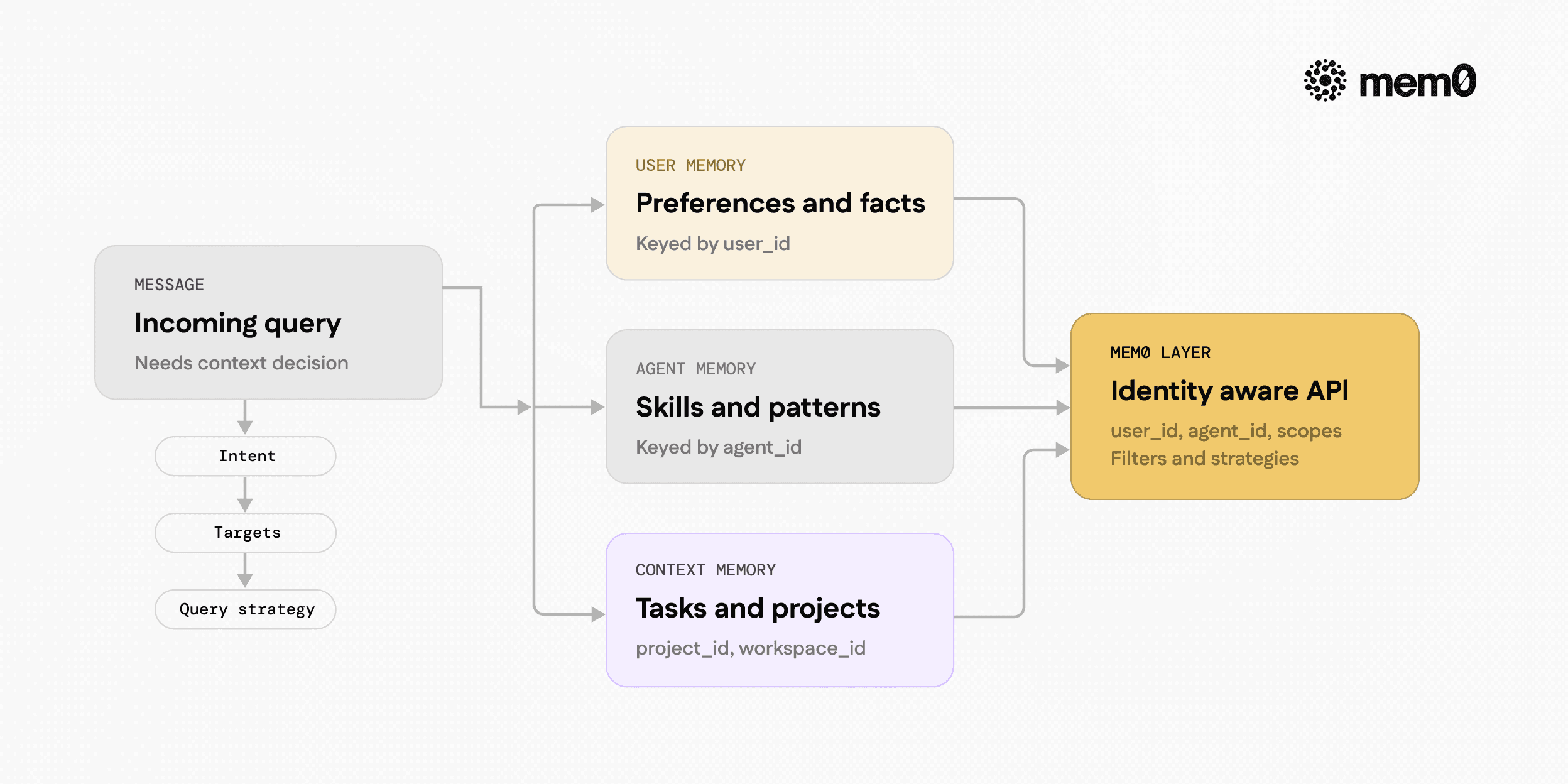
Fig: How user, agent, and contextual memory dimensions relate to identities
Designing context routing starts with structuring memory types and their entry points. A useful approach is to define memory dimensions and attach routing logic per dimension.
Typical dimensions include:
User memory: Personalized facts and preferences keyed by
user_id.Agent memory: Long-term knowledge the agent accumulates about tasks, tools, and patterns, keyed by
agent_id.Contextual memory: Task or project-scoped state, keyed by entities such as
project_id,workspace_id, orconversation_id.
Routing then becomes a function that examines the incoming message, the current execution context, and decides which memory dimension to query.
In practice, this function has three parts:
Intent detection: Is the user referencing past information, specifying a new preference, or working with an existing entity?
Target resolution: Which IDs or scopes apply, for example
user_id,agent_id,project_id,thread_id.Query strategy selection: Should the agent run a semantic search, filter by tags, retrieve the last N items, or a combination?
These parts can themselves be mediated by an LLM, but the memory operations they drive should be explicit and observable. Mem0 provides the memory layer that these strategies can call.
How Mem0 models context for routing
Mem0 organizes memory around identities, sources, and metadata. This structure enables agents to route context without guessing how to talk to the underlying storage.
Key concepts relevant to context routing:
Identities:
user_id,agent_id, and optionallysession_idor any arbitrary identifier used to scope memory.Memory types: Mem0 can store unstructured text, structured data, and references. Agents can tag intended use, such as
preference,task_state, ornote.Metadata and filters: Custom metadata fields that can encode project, workspace, topic, or tool identifiers.
Retrieval strategies: Semantic search, keyword search, recency-based retrieval, or hybrid approaches exposed through a unified API.
The agent does not need to know how embeddings are stored or which database backs them. It only needs to supply the right identity and metadata to route the query to the correct subset of memory.
This is crucial for production agents that need to ensure that user A never sees user B's memory while still sharing agent knowledge across users when appropriate.
Integrating Mem0 in an agent loop
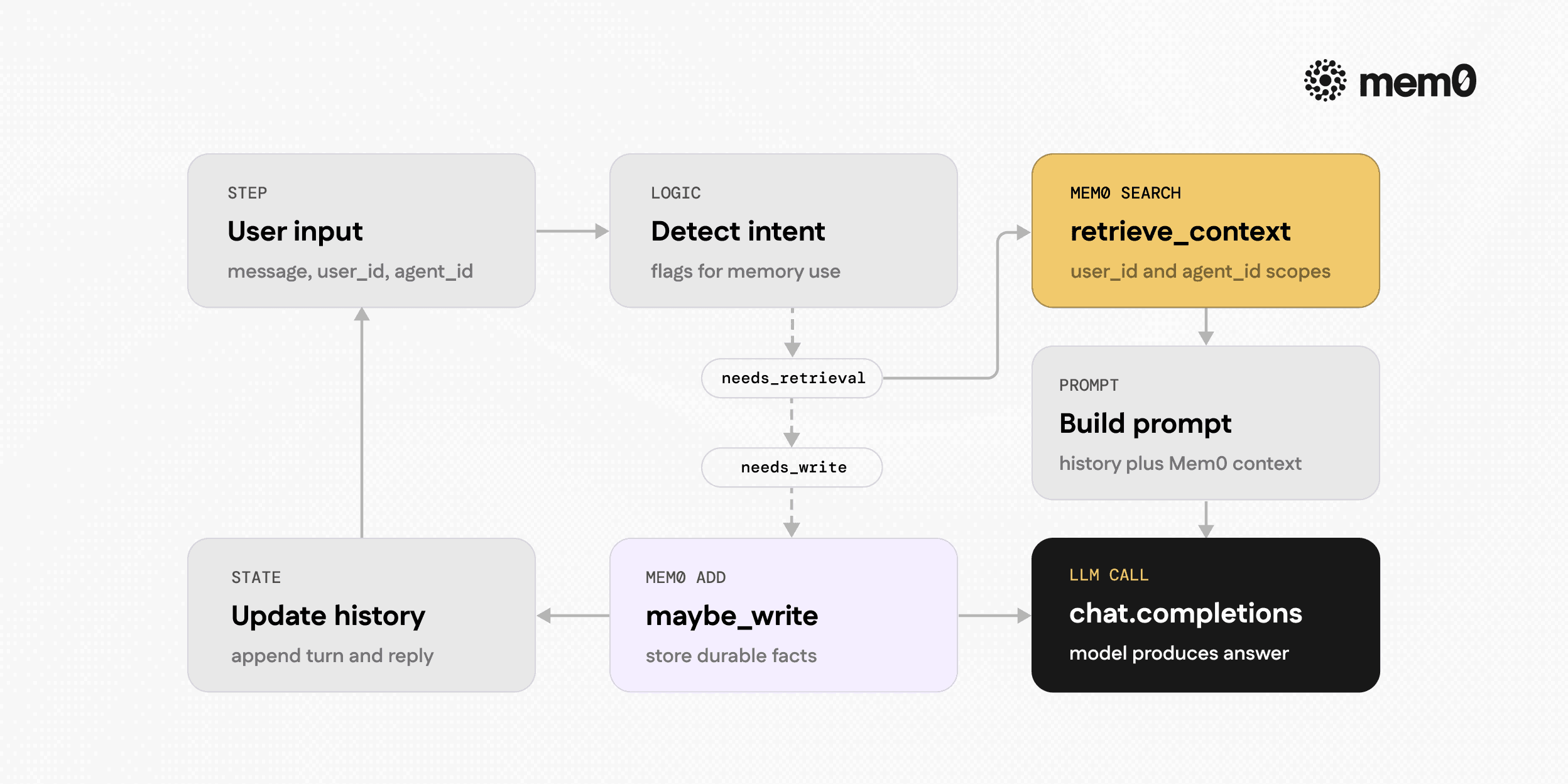
Fig: Visualize the agent loop from the code sample
The simplest way to see context routing in action is to add Mem0 calls into the agent's main loop. The loop usually:
Receives user input.
Updates the conversation state.
Fetches relevant context.
Calls the LLM with tools and context.
Writes new memory if needed.
Below is an example that illustrates a minimal integration with Mem0 using Python. It assumes the agent has user_id and agent_id available, and routes context queries to Mem0 before each LLM call.
💡 You'll need a free Mem0 API key to follow along. Get one at app.mem0.ai
This example uses a naive intent detector for brevity. In production environments, the detector is usually based on a lightweight language model or a fine-tuned classifier that flags context queries and preference updates. The key point is that Mem0 is only accessed in two meaningful places: retrieval and write, which keeps the agent loop clean.
Designing routing strategies with Mem0 metadata
Mem0 metadata is a central tool for routing. Instead of multiplexing all memory into a single embedding space, agents can label entries and then selectively query them.
Common metadata fields:
memory_type: "preference","task_state","observation","note".scope : "user","project","global".project_id,workspace_id,conversation_idIdentifiers for task or organization-scoped memories.
These keys enable strategies such as:
For preference queries, search only
memory_type="preference"scoped touser_id.For ongoing tasks, search
memory_type="task_state"filtered byproject_id.For general agent improvements, store summaries as
scope="global"underagent_id.
In code, this is just a matter of passing filters into Mem0 calls:
By standardizing memory metadata upfront, engineers can add complex routing logic without changing the core memory store. Mem0 handles the underlying retrieval once the filters are defined.
Comparison of routing approaches
There are several ways to route context queries, each with different tradeoffs. The table below summarizes common patterns used in production agents.
Routing approach | How it works | Pros | Cons |
|---|---|---|---|
Rule-based keyword detection | Match phrases like "last time" or "remember" | Simple to implement, predictable behavior | Misses subtle cues, language dependent |
LLM-based intent classification | Use a small model to label the message intent | Captures nuances, adaptable | Adds latency and cost, needs prompt maintenance |
Heuristic based on thread size | Retrieve memory when the conversation exceeds N tokens | Easy thresholding | Not aligned with user expectations |
Always retrieve N recent items | Fetch the last K memories for the user or project | Very simple, low overhead | Includes irrelevant context, risks confusion |
Hybrid rules and LLM | Rules for obvious cases, LLM for ambiguous ones | Good recall and precision | More complex orchestration |
Tool-call-based routing | LLM decides which memory search tool to call | Flexible, centralized logic in LLM | Harder to debug and constrain |
Mem0 is compatible with all of these because it focuses on exposing memory as a clean API rather than dictating the routing strategy. Teams can start with rules and gradually move to more sophisticated routing without refactoring the memory layer.
Where naive context routing fails
Naive approaches work in demos but often fail in production. Common issues include:
Overloading the prompt: Dumping entire conversation history and all retrieved memories into the LLM context. This leads to higher costs, slower responses, and unpredictable attention from the model.
Inconsistent identity handling: Using different identifiers across services so the memory store cannot reliably tie data to users or agents.
Lack of memory pruning: Never expiring or summarizing old entries, which causes retrieval to surface outdated or conflicting data.
No separation of user and agent memory: Mixing personal preferences with agent knowledge, which makes routing more complex and increases the risk of privacy leaks.
These problems are not solved by a better retrieval model alone. They require a structured memory layer that can enforce scopes, identity boundaries, and policies.
Mem0 addresses these by:
Separating memory by identity dimensions.
Exposing filters and metadata for routing.
Supporting summarization and cleanup workflows.
Providing APIs that keep retrieval and write operations explicit.
Using Mem0 for production-grade context routing
A production agent often needs more than a simple text search. It needs workflows that clean, summarize, and reorganize memory so context queries remain accurate over months or years.
Mem0 supports patterns such as:
Incremental summarization: Periodically summarizing long conversation histories into compact memory entries tagged as a
summary. Retrieval can then favor summaries when token budgets are tight.Conflict resolution policies: Storing multiple preferences with timestamps and tags so that the agent can favor the most recent or most explicit entry.
Context templates: Standardizing how memories are formatted into prompts, for example, separating preferences, task state, and notes sections.
Multi-tenant separation: Using metadata and identity fields to enforce hard boundaries between tenants, while still allowing shared agent memory.
In code, summarization may look like this:
Agents can call this periodically or when conversations exceed a length threshold. Future context queries will then retrieve compact summaries instead of raw history.
Limitations of context routing patterns
Context routing is not a complete solution to agent memory. It operates within several important limits:
Implicit expectations are hard to detect
Users often expect the agent to remember aspects that were never clearly stated. Neither rules nor LLM-based routing can recover information that was never stored.
Ambiguity in references
Phrases like "what you said earlier" are ambiguous if multiple relevant events exist. Routing can surface several candidate memories, but the model still needs to choose among conflicting entries.
Token budget constraints
Even with good routing, only a subset of memories can be supplied to the model. Important details may be summarized away or omitted.
Domain drift
As domains evolve, old memories become obsolete. Routing and retrieval alone cannot decide when a memory is no longer valid; this requires explicit expiry, versioning, or external signals.
Privacy and compliance
Routing strategies that combine user and global memories need explicit policies to comply with privacy requirements. Memory layers can enforce scopes, but engineers must define correct policies.
Mem0 reduces operational and engineering complexity, but it does not eliminate these fundamental challenges. Teams still need to design prompts, policies, and summarization strategies that align with product requirements and domain constraints.
Frequently Asked Questions
What is a context query in an AI agent?
A context query is any user message that expects the agent to use past interactions, preferences, or state to answer correctly. It goes beyond the current message and requires access to stored memory, such as prior conversations or user profiles.
How does Mem0 help route context queries to the right memory?
Mem0 attaches memories to identities and metadata, which allows agents to query by user_id, agent_id, and custom scopes like project_id. Routing logic uses these dimensions to selectively retrieve only relevant memories for each query.
When should an agent write to memory versus only retrieve it?
Agents should write to memory when the user expresses durable preferences, decisions, or long-lived facts rather than ephemeral questions. Retrieval is appropriate whenever the user references past actions, settings, or conversations that affect the current response.
How can latency be managed when adding memory retrieval to agents?
Latency can be controlled by using lightweight intent detection, limiting retrieval to specific memory types, and constraining the number of memories returned. Mem0’s API design supports targeted searches so agents do not pay the cost of broad, unfocused retrieval on every message.
Why not just pass full conversation history instead of using a memory layer?
Passing full history quickly hits token limits, increases costs, and dilutes attention across many irrelevant messages. A dedicated memory layer lets agents store and retrieve only the most relevant and persistent information, which results in better performance and more predictable behavior.
Can Mem0 be used with tool-using agents and function calling?
Yes. Tool-using agents can expose Mem0 retrieval and write operations as tools or functions, and the LLM can decide when to invoke them based on the user query. This keeps the memory layer explicit and inspectable while giving the model flexibility in how it uses context.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source GitHub repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

