



Context compression is what most agents reach for when conversations get long. It summarizes, truncates, prunes. It does not remember. It forgets more slowly.
External memory extracts facts before they disappear, stores them outside the context window, and retrieves them on demand. The two approaches solve adjacent problems and fail in completely different ways. Most production teams need both.
What context compression actually is
Context compression is any automated process that shrinks an agent's conversation history when it approaches the token limit. The input is a history that no longer fits. The output is a smaller history that does.
Six strategies are in production use.
Truncation. Drop the oldest messages. Zero compute cost. Breaks immediately when the agent needs a constraint or decision from earlier in the session.
Rolling summarization. When history exceeds a threshold, send the full history to a model and replace it with a prose summary. Simple to implement. Loses precision across multiple compression cycles.
Anchored incremental summarization. The current state of the art. The compressor maintains a persistent structured document and extends it per eviction span rather than regenerating from scratch. Factory's internal analysis of 36,000 engineering session messages reportedly found this approach outperforms full reconstruction, with anchored summarization scoring higher on their accuracy rubric than both Anthropic's and OpenAI's summarization approaches.
Structured handoffs. A fixed schema for the compressed summary: files modified, tools called, decisions made, in-progress state, constraints, preferences. Subsequent compressions update the existing document rather than regenerating it.
Selective pruning. Remove verbose content before any model call. Primary target: tool outputs. No LLM call required. High token savings per compute cost.
Embedding-based compression. Store historical turns as dense embeddings and reconstruct only semantically relevant segments. Achieves 80-90% token reduction. At this point, the line between aggressive compression and external memory with retrieval becomes definitional.
The five things compression reliably loses
Production analysis consistently identifies the same five loss categories under summarization-based compression:
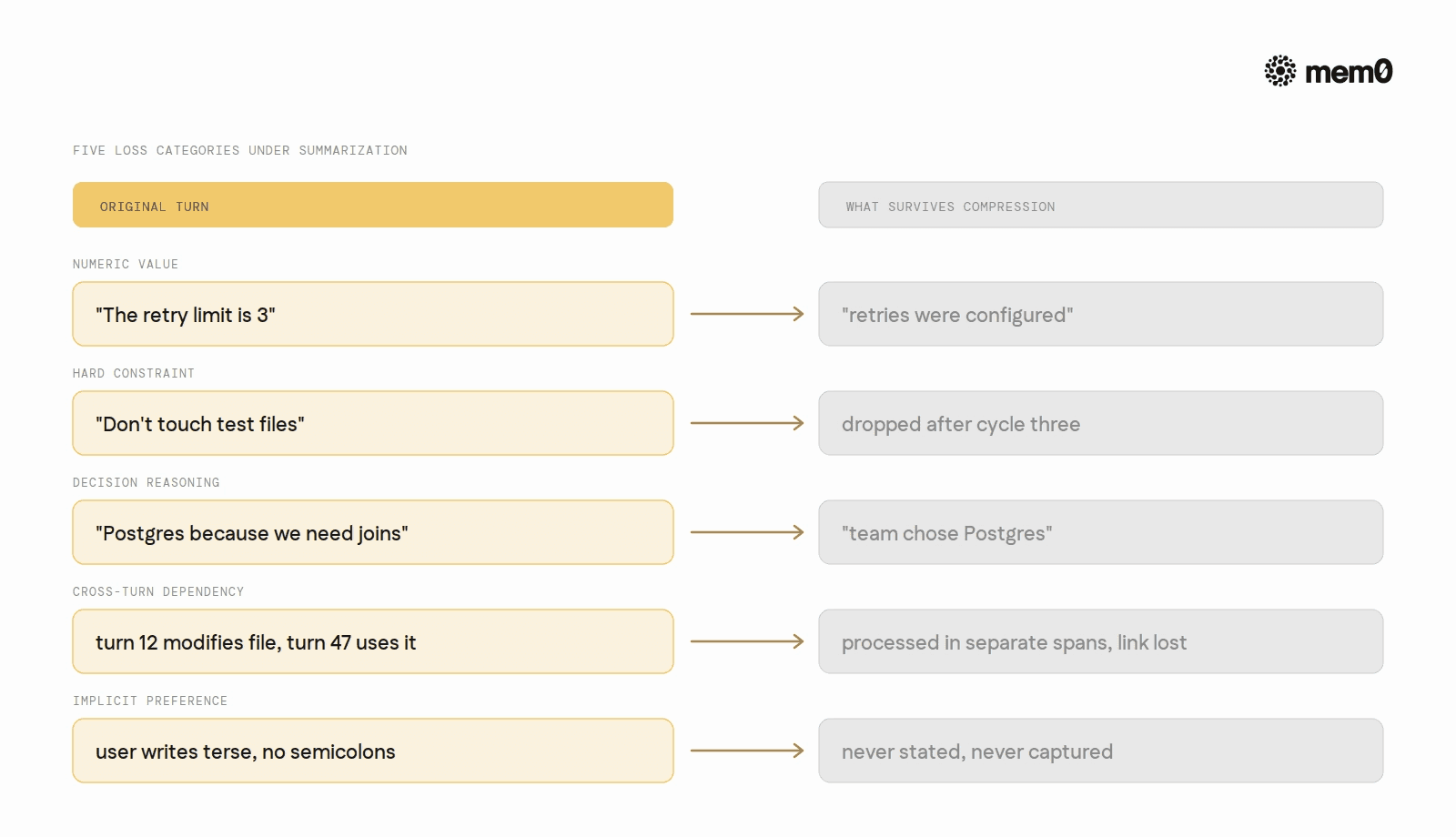
Exact numeric values. "The retry limit is 3" becomes "retries were configured." The 3 disappears.
Hard constraints. "Don't touch test files" and "no Redis in this environment" are stated once, assumed permanent by the user, and compressed out by cycle three.
Decision reasoning. The what of a decision survives. The why does not. An agent that knows the team chose Postgres but not why it chose Postgres over Redis makes the wrong call at the next decision point.
Cross-turn dependencies. A file modified at turn 12 that a tool at turn 47 depends on. Compressors process each eviction span independently and miss the link.
Implicit preferences. Coding style, tone, formatting patterns the user demonstrated but never stated explicitly.
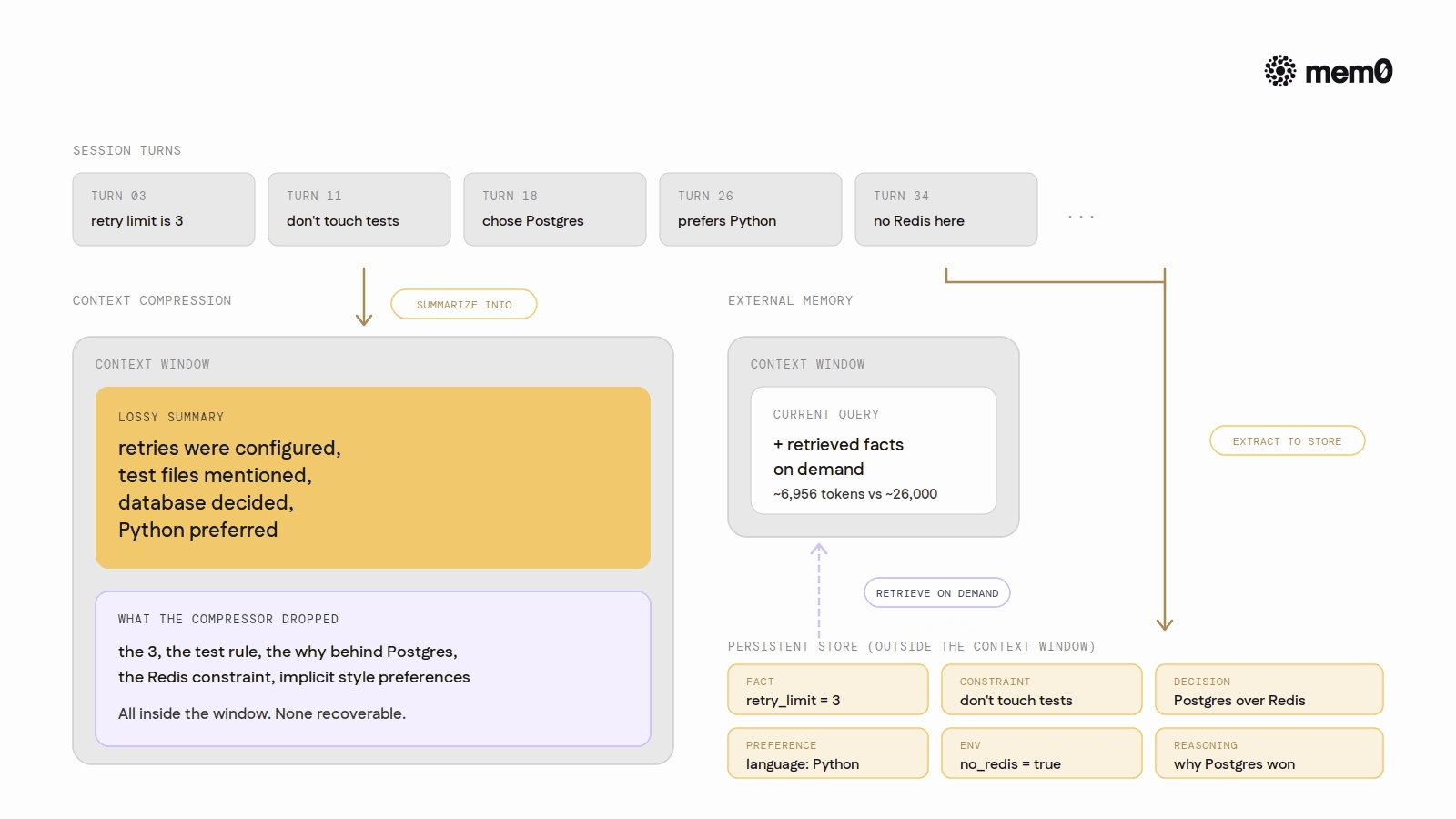
The timing problem: most compressors trigger at 50-70% context utilization. By that point, the session may contain 25 turns of constraints and preferences that need to survive. Extracting at compression time is already too late.
What external memory is
External memory is a storage layer that lives entirely outside the context window. Facts are extracted during a conversation, persisted to a store, and retrieved into future sessions based on relevance.
Three substrate types exist in production:
Vector stores. Memories are embedded and retrieved by semantic similarity. The query "programming language preferences" retrieves the stored fact "User prefers Python over JavaScript" even without word overlap. Supported backends include Qdrant, Chroma, Pinecone, PGVector, Redis, FAISS, and sixteen others.
Graph stores. Memories stored as entities and relationships. Enables traversal queries semantic similarity cannot answer: "What did the team decide about the database at project start?"
Structured stores. SQL or key-value for preference tracking, metadata filtering, temporal queries. Useful when memories carry structured attributes that need to be queried independently of their content.
The architectural contrast with compression:
Context compression | External memory | |
|---|---|---|
Scope | Single session | Cross-session |
What's kept | Lossy summary | Atomic extracted facts |
Retrieval | Implicit | Explicit, query-time |
Failure mode | Silent lossy degradation | Extraction gap |
Token cost | Grows with session length | Flat per query |
When compression is the right call
Compression wins when the task is single-session. No cross-session continuity required. It also wins when the agent is stateless by design: a tool-use agent, a single-shot analysis tool, a code review bot that sees a PR and responds once.
Infrastructure budget is the other factor. Compression adds no external dependencies. A working agent without a retrieval pipeline is the right starting point for most teams.
The honest ceiling: compression does not preserve. It reduces loss. For short, well-defined sessions this is acceptable. For long-running agents or any system where specific facts need to survive beyond one conversation, it is the wrong abstraction.
When external memory is the right call
External memory wins when conversations span multiple sessions. Compression has no story for this.
It also wins when user personalization is part of the product value. Preferences, communication style, and prior decisions need to surface without the user repeating them. And when facts need to survive compression, extract before the compressor fires and the facts persist regardless of what compression drops.
Token efficiency at scale is the third factor. In Mem0's published benchmarks on the LoCoMo dataset, retrieval-augmented approaches using Mem0 used approximately 6,956 tokens per query versus approximately 26,000 tokens for full-context approaches — a roughly 4x reduction. At 10,000 daily interactions, that difference changes infrastructure economics significantly.
External memory has its own failure modes. If the extraction model did not identify something as salient, it does not go into the store and there is no fallback. Retrieval degrades as the store grows with near-duplicate fragments. Retrieval pipelines add 200-500ms latency. An embedding pipeline, a vector store backend, and a retrieval layer are required before writing product code.
The production pattern
Neither approach replaces the other. The production consensus across 2025-2026 deployments is a three-tier architecture:
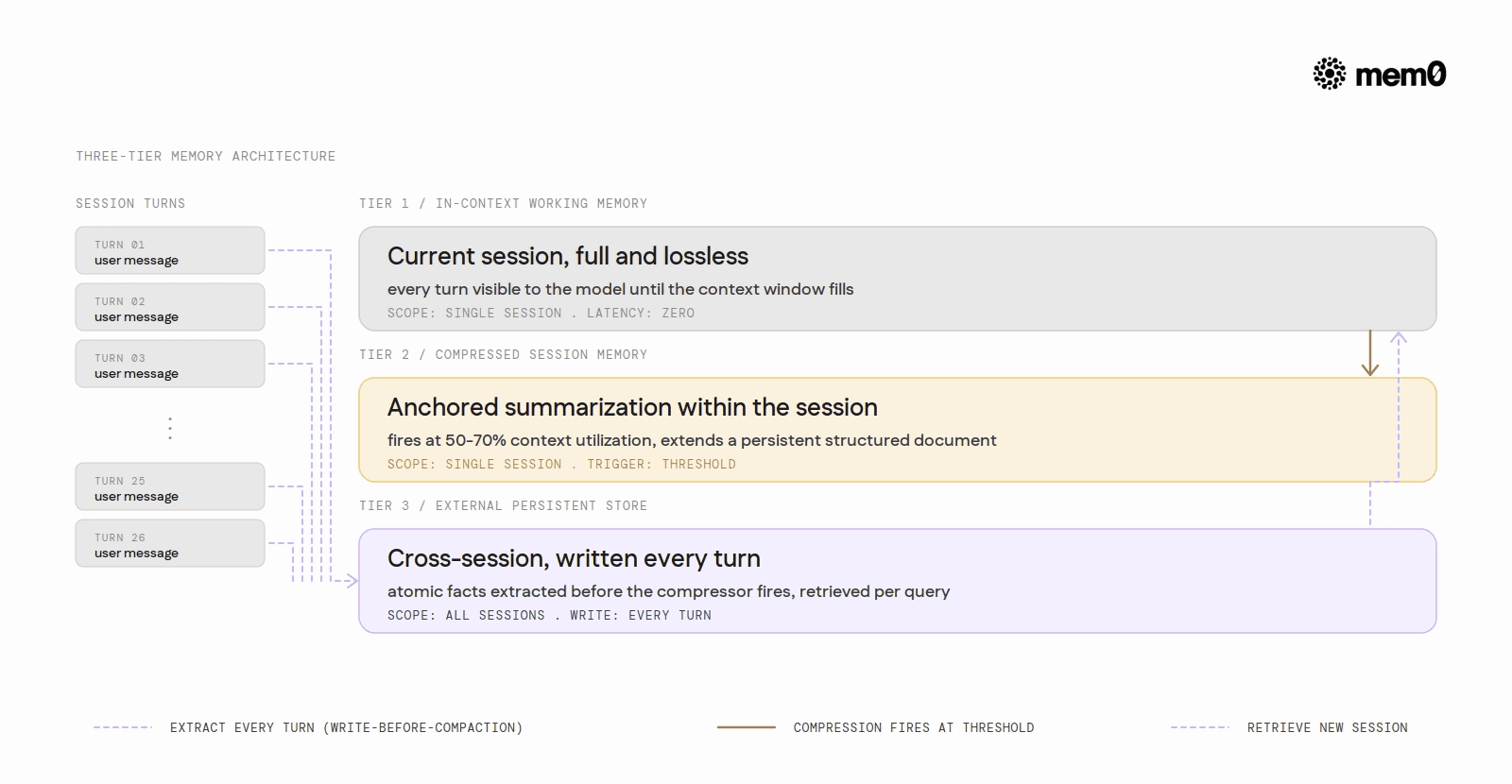
Tier 1: In-context working memory. The current session. Full, unmodified, lossless.
Tier 2: Compressed session memory. When the session grows long, anchored incremental summarization handles continuity within the session.
Tier 3: External persistent store. Cross-session knowledge. Extracted before compression fires, retrieved at the start of each new session.
The write-before-compaction pattern is the key implementation detail. Extract after every turn, not at compression time. By the time the compressor triggers at 50-70% context utilization, the session may have accrued 25 turns of constraints and preferences that need to survive.
Where Mem0 fits
Mem0 handles Tier 3: the persistent, cross-session layer.
The extraction pipeline runs a single-pass model call after each turn and stores facts to a dual-layer backend: a vector store for semantic retrieval and an entity collection for relationship traversal. Three signals fuse at retrieval time: semantic similarity, BM25 keyword matching, and entity matching. No single signal alone matches the combined score.
Async writes are the default. Extraction never blocks response generation. A circuit breaker disables API calls for two minutes after five consecutive failures and the agent continues running without memory during the outage.
For Tier 2, compression is still needed. Mem0 stores what survives across sessions. Within a session, anchored summarization handles the growing context. The two layers work in parallel.
Final Notes
Context compression manages what the agent sees this session. External memory manages what the agent knows across all sessions. Use compression to keep long sessions coherent. Use external memory to keep long-running agents informed.
The two failure modes are different. The two solutions are different. Running one without the other leaves a gap that users will feel before engineers notice.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

