



Why memory benchmarks for agents are hard
Agent memory is not just a bigger context window. Production agents need to remember facts across hours, days, and sessions, update them when reality changes, and use them reliably when it matters.
This raises hard questions:
What counts as a “successful” memory?
Is the agent recalling the right thing at the right time, or just pattern-matching?
How to score memory quality without manually inspecting every interaction?
Traditional LLM benchmarks focus on single-shot QA, code, or reasoning. They say little about whether an agent can maintain consistent beliefs about a user, a task, or a world state across time. BEAM targets exactly this gap.
What BEAM is and why it matters
BEAM (Benchmark for Evaluating Agent Memory) is a task-driven benchmark that evaluates how well an agent can form, retain, update, and apply memories in realistic scenarios.
The key properties that make BEAM useful for production-facing teams:
Scenario-based: Agents interact in multi-step environments with evolving states, not static prompts.
Temporal structure: Important information appears early and is needed much later, so naïve context stuffing fails.
Memory operations: Tasks test writing, updating, and reading memories under ambiguity and changing facts.
Automatic scoring: Ground-truth states allow quantitative evaluation without hand-labeling every run.
For teams building agents that schedule, personalize, or coordinate multi-step workflows, BEAM approximates the type of longitudinal memory behavior that matters in production.
How BEAM is structured
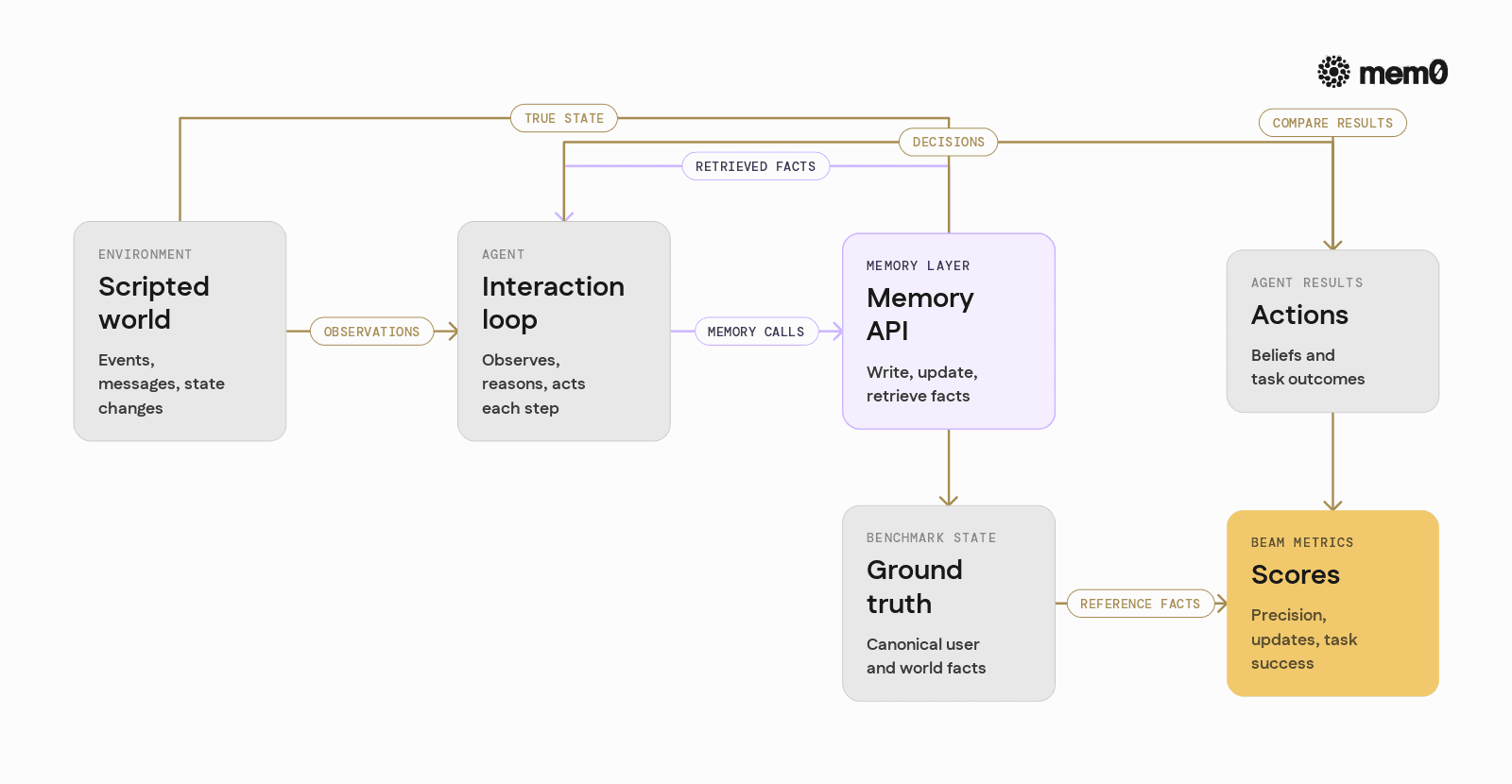
BEAM is built around scripted scenarios that simulate the kind of interactions memory-centric agents face. While implementations vary, most share a common pattern:
Environment simulation
A controlled environment generates events, messages, and state changes. These could be user preferences, plans, or world changes.Agent interaction loop
The agent receives observations and produces actions or responses. It may call tools, ask clarifying questions, or take decisions.Memory interface
The agent has an explicit memory API, such as:Write candidate memories
Update existing memories
Retrieve relevant memories for a query
Ground truth and scoring
BEAM tracks the canonical “true” state. The agent’s beliefs and actions are compared against this ground truth to compute metrics for:Precision and recall of stored facts
Correctness of updates
Downstream task success dependent on memory
This design isolates the memory layer’s contribution. The agent may use a strong foundation model, but poor memory handling will still show up in BEAM’s scores.
What BEAM measures in practice
From an engineering perspective, BEAM is valuable because it decomposes memory performance into interpretable dimensions.
Common measurement angles include:
Memory extraction quality
Does the agent decide which events deserve to become persistent memories, or does it store noise? Poor extraction leads to bloated, unhelpful memory stores.Temporal recall
Can the agent retrieve the right fact when needed, even after many unrelated interactions?Update consistency
When the world changes, such as a user moving to a new city, does the agent overwrite or deprecate old facts and use the new ones consistently?Task impact
Most importantly, does memory actually improve downstream task success, instead of just increasing latency and complexity?
This aligns well with how production owners think. The benchmark does not just reward having many stored vectors. It rewards the ability to maintain a coherent, up-to-date “belief state” that improves outcomes.
Mem0 performance on BEAM and AgentMemBench
Open agent memory benchmarks, such as AgentMemBench, have started incorporating BEAM-style tasks. These setups provide an apples-to-apples comparison between different memory implementations and strategies.
Within this context, Mem0’s approach, which combines structured memory objects, hybrid retrieval, and update-aware logic, achieves state-of-the-art scores. In Mem0 research results on BEAM-style tasks, Mem0 consistently outperforms baselines such as vanilla hindsight-style retrieval approaches.
In particular, Mem0 improves:
Recall of long-range facts in multi-session scenarios
Consistency under updates, where older facts must be replaced or marked obsolete
Downstream task accuracy, which is the metric that matters most for production agents
The comparison is not about raw vector search performance, but about whether the memory layer supports the types of operations BEAM stresses: extraction, updating, and use in context.
Benchmark scores across LoCoMo, LongMemEval, and BEAM
Benchmarked across LoCoMo, LongMemEval, and BEAM, powered by single-pass hierarchical extraction and multi-signal retrieval:
Benchmark | Coverage | Overall Score | Mean Tokens |
|---|---|---|---|
LoCoMo | 1,540 questions • 5 categories | 92.5 | 6956 |
LongMemEval | 500 questions • 6 categories | 94.4 | 6787 |
BEAM 1M | 700 questions • 35 conversations | 64.1 | 6719 |
BEAM 10M | 200 questions • 10 conversations | 48.6 | 6914 |
How Mem0 models memory for BEAM-like workloads
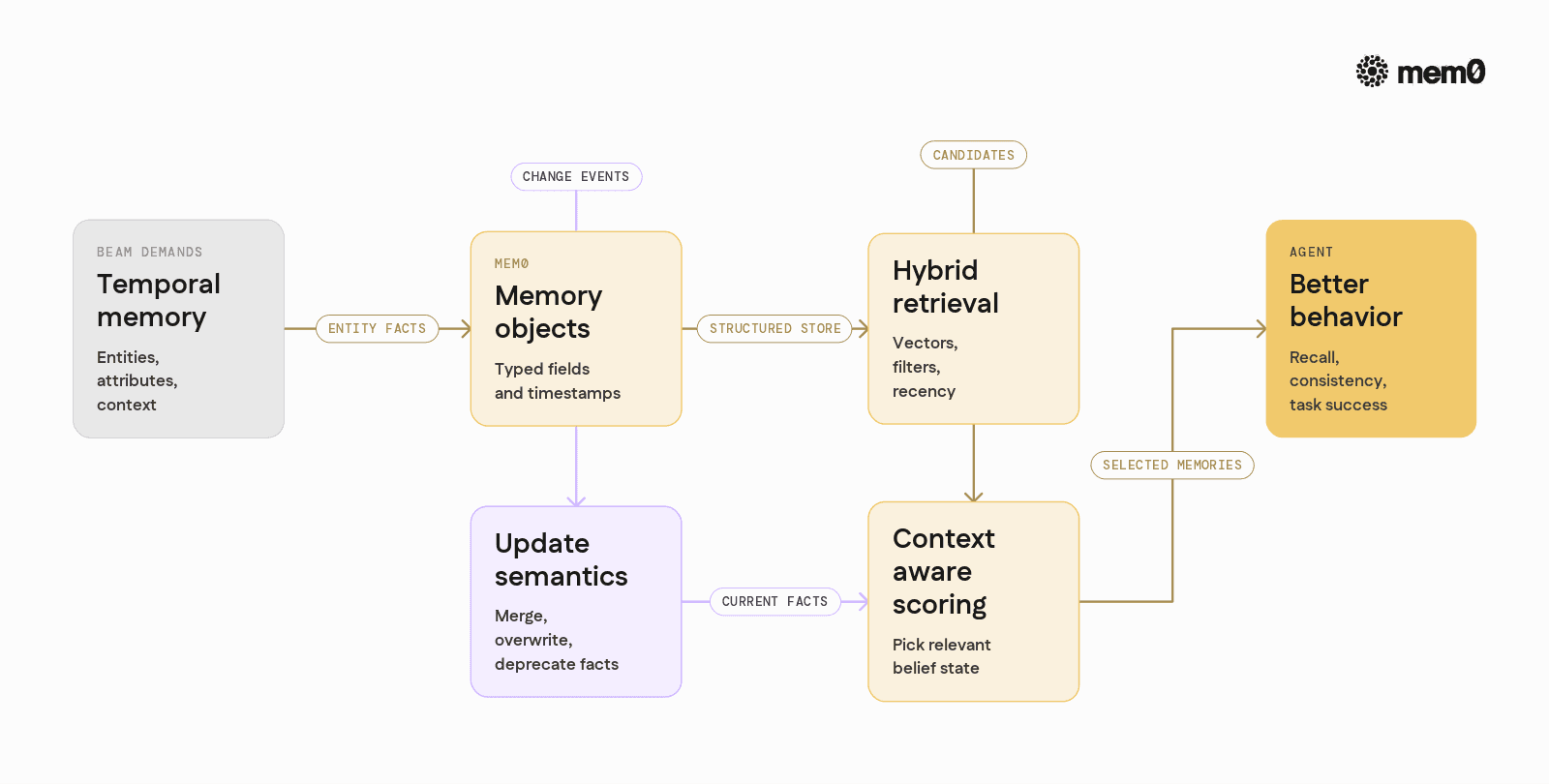
Mem0 treats memory as a first-class resource with structure, rather than a bag of embeddings. This lines up well with BEAM, where the benchmark expects:
Persistent entities
Evolving attributes
Temporal context
Key parts of Mem0’s design that map to BEAM challenges:
Memory objects instead of raw text chunks
Mem0 stores memories as typed objects with fields such asuser_id,topic,metadata, and timestamps. This makes updates and filtering more precise.Hybrid retrieval
Mem0 combines vector similarity with symbolic filters and recency signals, which improves recall for long-lived facts without flooding retrieval with irrelevant context.Update semantics
Mem0 supports updating or merging memories rather than just appending. When a fact changes, the memory store can be amended, so BEAM’s update tasks are handled accurately.Context-aware scoring
Retrieval is aware of the query context, which is critical when multiple similar memories exist and only one is relevant to the current goal.
These design choices are exactly what benchmarks like BEAM reward, because they allocate points for correct temporal and logical handling of memory, not just storage capacity.
Where BEAM and similar benchmarks fall short
No benchmark captures every aspect of production reality. BEAM is strong at evaluating structured memory tasks, but it has limits that engineers should keep in mind:
Synthetic or semi-synthetic environments
Many BEAM tasks are constructed. They are carefully designed, but they may not capture the messiness, noise, and ambiguity of real users or real business processes.Limited domain diversity
Benchmarks often focus on a handful of domains, such as scheduling, simple preferences, or toy knowledge. Complex enterprise domains, with rich schemas and edge cases, are underrepresented.Focus on explicit facts
BEAM is better at evaluating persistent facts and explicit changes, such as “user moved city”, than implicit, fuzzy, or tacit knowledge, such as style preferences or non-verbal cues.Latency and cost awareness
Benchmarks usually focus on logical correctness and ignore resource constraints. Production agents must trade off retrieval breadth, model context size, and latency.Static evaluation
Once a benchmark is defined, agents can overfit to the scenarios. Real systems need to handle distribution shifts and novel patterns, which no static benchmark fully captures.
These constraints do not make BEAM less useful. They define the boundaries within which its scores should be interpreted. BEAM is very effective for evaluating memory mechanics, but it is not a full proxy for production reliability or user satisfaction.
Using Mem0 and BEAM together in production workflows
For teams shipping agents today, the practical approach is to use BEAM-like benchmarks as part of a layered evaluation strategy, with Mem0 as the memory substrate:
Offline evaluation with BEAM-like tasks
Run agents against BEAM and related benchmarks, with Mem0 as the memory layer, to evaluate extraction, update, and retrieval logic.On-policy replay of production traces
Feed real conversations or tool traces into a BEAM-like harness. Use Mem0 to reconstruct memories and analyze where memory helps or fails.Instrumentation and logging
Use Mem0’s APIs and metadata to log when a memory was written, retrieved, or updated. Correlate these events with task success and user feedback.Iterative tuning
Adjust Mem0 configuration, such as retrieval limits, scoring weights, and update policies, then observe score changes on BEAM and on internal traces.
By combining a benchmark that stresses the right properties with a memory layer designed for temporal consistency and updates, teams can iterate on memory behavior with measurable feedback, rather than guesswork.
Frequently Asked Questions
What makes BEAM a better memory benchmark than simple recall tests?
BEAM evaluates memory in multi-step, temporally structured scenarios, instead of single-shot questions. It measures extraction, updating, and usage of memory in context, which mirrors how production agents must behave.
How does Mem0 achieve high scores on BEAM-style tasks?
Mem0 uses structured memory objects, hybrid retrieval, and explicit update semantics, so it can maintain consistent user and world state across time. These design choices align closely with the aspects BEAM rewards, such as correct updates and long-range recall.
When should an engineering team invest in BEAM-style evaluation?
Teams should adopt BEAM or similar benchmarks once agents rely on user history, preferences, or evolving state for critical tasks. If incorrect or outdated memories can break workflows or frustrate users, a temporal benchmark becomes important.
How does Mem0 integrate into an existing agent architecture for BEAM?
Mem0 sits alongside the LLM and tools as a dedicated memory service, with APIs for adding, searching, and updating memories. Agents call Mem0 on each step to store new facts and retrieve relevant information before generating responses or taking actions.
Why is memory updating a key part of BEAM and not just retrieval?
Real users change jobs, locations, and preferences, and systems that only append memories will quickly accumulate contradictions. BEAM tasks highlight this by requiring agents to overwrite or adjust prior beliefs, so updating is just as critical as recall.
Can BEAM alone guarantee that an agent’s memory will work in production?
No, BEAM is a strong signal for memory mechanics but does not capture all real-world noise, domain complexity, and latency constraints. It should be combined with replay of production traces, user feedback, and domain-specific tests.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

