



Voice agents are going mainstream with AI tutors, therapy companions, customer service bots, and personal assistants. Since these agents use LLMs as the foundation for response generation, they carry the model's statelessness over by default. Each inference call is independent.
The model has no awareness of prior turns unless that context is explicitly passed in.
If we were discussing single conversations, statelessness doesn’t matter. You pass the message history in the prompt and the model appears to "remember" within that session.
But the problem surfaces across sessions. When a user comes back the next day, that history is gone. A language tutor has no memory of last week's pronunciation work.
A therapy companion has no record of what coping strategies the user found helpful. That means every session starts with a blank slate, which forces users to re-explain the context they've already given, and makes the agent feel generic rather than personal.
Fortunately, adding memory to a voice agent is a solved problem architecturally. This guide walks through the key decisions and trade-offs teams work through when building this out in production.
How Memory Fits Into a Voice Agent
Memory in a voice agent operates around two moments in the interaction loop: before the LLM call and after the response is delivered.
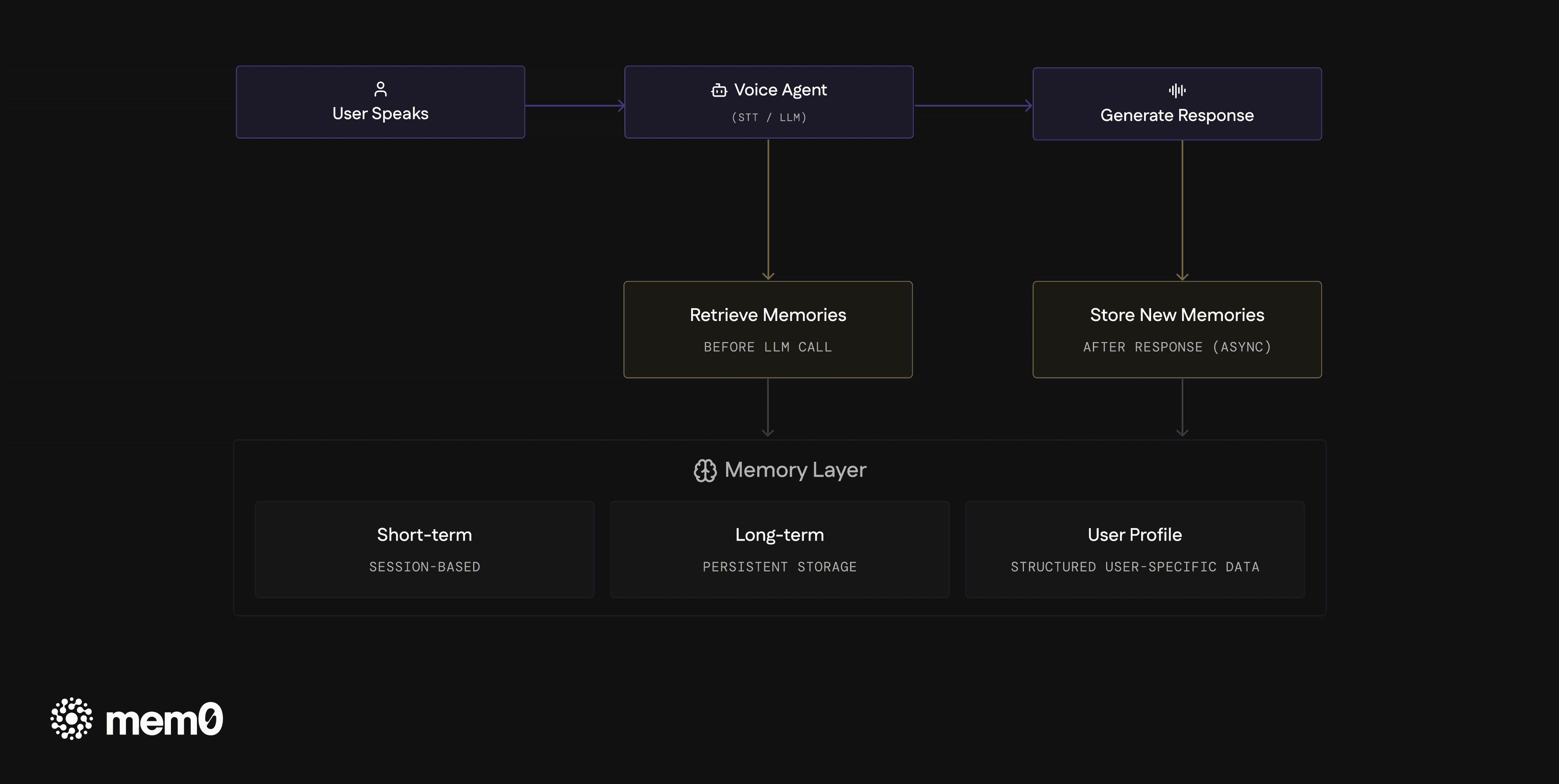
Before the LLM generates a response, relevant memories are retrieved and injected into the prompt as context. After the response is delivered, new information from the exchange is extracted and written to the memory store. Storage is async so it doesn't block the response.
That separation is load-bearing. Voice agents have tight latency requirements, and anything that adds time before the LLM call is felt by the user. Keeping writes off the critical path gives you flexibility to do more sophisticated memory extraction without affecting response time.
The Four Decisions Behind Designing the Memory Layer
Once you understand the basic loop, the next step is making four decisions that define your memory architecture: when to write memories, what to actually remember, how to retrieve context at query time, and where memory processing happens in your infrastructure.
These decisions interact with each other, so it's worth thinking through them in order before writing any code.
1. When Should You Write Memories?
There are two approaches here: per-round writes and per-session writes.
Per-round writes happen after every exchange. As soon as the user speaks and the agent responds, that pair gets processed for memory extraction. The practical benefit is resilience. If the user closes the app mid-session, every exchange up to that point has already been written.
Also, smaller and more frequent writes tend to produce higher-quality extractions because you're asking the model to analyze a short exchange rather than a 30-minute transcript.
Per-session writes batch everything and process it once when the session ends. This reduces API calls and gives you a complete picture of the conversation for summarization. The risk is data loss on early exits. If the user hangs up at the 15-minute mark and the session-end hook doesn't fire, everything is lost.
But while per-session writes are more efficient, you’ll see teams run per-round writes. The cost difference is real but manageable, and recovering from dropped sessions is not a problem you want to debug in a live product.
2. What Should You Write to the Voice Agent’s Memory?
The naive approach is to extract everything from every exchange and store it. But this produces a lot of irrelevant data that degrades retrieval quality over time.
A better framing is: what information would actually change how this agent responds in a future session?
For a language tutor, that's pronunciation errors, vocabulary gaps, and preferred learning pace. For a therapy companion, it's patterns in the user's emotional state, which interventions they responded to, and topics they want to avoid. General pleasantries, greetings, and filler are noise in both cases.
There are three approaches for controlling what gets extracted from conversations:
Generic extraction lets the memory system decide what's important. This works reasonably well for general-purpose assistants where the range of relevant information is broad, but it consistently over-captures for domain-specific agents.
Domain-specific instructions give the memory system explicit guidance about what to look for. For instance, you write a prompt that says: "Extract pronunciation errors, vocabulary the user didn't know, and any stated learning preferences. Do not extract greetings, filler phrases, or off-topic conversation." This requires more setup but produces significantly cleaner memory stores.
Structured schemas define explicit categories and extract into typed buckets. A tutoring agent might have categories like pronunciation_errors, vocabulary_gaps, session_milestones, and learning_preferences. This gives you the most control, makes retrieval more predictable, and lets you query specific memory types rather than running semantic search across everything. It's also the most work to design and maintain.
The more specialized your domain, the more structure you need.
Generic extraction is a reasonable starting point. Structured schemas become necessary once your agent's usefulness depends on retrieving very specific kinds of information accurately.
3. How Do You Retrieve Memories?
Your retrieval strategy has the biggest impact on response quality, and it's also where latency gets introduced.
There are four patterns teams commonly use, each with different trade-offs on latency, relevance, and complexity.
Dump everything loads the user's complete memory store into the system prompt on every turn. Simple to implement, and it works well when users have fewer than 20-30 memories. Past that point, you're consuming too many tokens and the model starts ignoring context that's too far from the instruction.
Semantic search queries the memory store based on the user's most recent message. You embed the message, run a nearest-neighbor search against stored memory embeddings, and inject the top results into the prompt. This produces highly relevant context, but it adds a network round-trip before every LLM call, typically 50–200ms depending on your vector store and infrastructure.
Pre-loaded context retrieves a curated set of memories once at session start and keeps them in the prompt throughout the conversation. You typically load recent sessions, core user preferences, and any ongoing topics. There's no per-turn latency cost, but the context becomes stale during long sessions as new information emerges in the conversation.
Hybrid combines pre-loading with conditional semantic search. You load core memories at session start, then trigger a targeted search only when topic detection signals a shift in the conversation. That way you avoid paying the search cost on every turn while still surfacing relevant memories when the conversation moves into new territory. It does require a topic-shift detection mechanism, which adds its own complexity.
Starting with a pre-loaded context is the right default. Semantic search is worth adding once you have evidence that pre-loaded context is producing specific gaps in response quality.
4. Where Does Memory Processing Happen?
This decision affects the entire system design, not just the memory layer, so it's worth thinking through carefully before committing to an architecture.
Inline processing
Puts memory retrieval and storage inside the main voice pipeline. It's the simplest architecture to build, but any slowdown in memory operations directly impacts response latency. If your memory extraction call takes 300ms longer than expected, the user waits 300ms longer.
Parallel agent
Runs a dedicated memory agent alongside the voice agent as a separate process. It listens to the conversation, extracts memories asynchronously, and can inject context back into the voice agent through a side channel without interrupting the conversation flow.
The voice path stays clean and fast. The memory agent can do slower, more sophisticated extraction without being a bottleneck. The trade-off is orchestration complexity. You're now running two coordinated agents rather than one, and you need a mechanism for them to communicate. Frameworks like LiveKit support this multi-agent pattern natively. OpenAI's Agents SDK and Gemini Live can support it with some additional plumbing.
Post-processing
Handles everything after the session ends. A background job picks up the full transcript, extracts memories, and stores them for future sessions. Zero latency impact during the conversation, but also no within-session memory benefits. If a user tells the agent something important at the 10-minute mark of a 60-minute session, the agent won't be able to reference it until the next session.
If your use case only requires cross-session memory, post-processing is the lowest-complexity path. If you need the agent to recall earlier parts of the current conversation, you need inline or parallel processing.
Managing Memory for Long Voice Conversations
The four decisions above cover the memory layer at a turn-by-turn level. But there's also a separate challenge at the session level: what happens when conversations run long.
Models can generally support context windows covering roughly 20–30 minutes of conversation. Sessions longer than that start dropping early context as newer turns push older ones out of the window.
For therapy or tutoring sessions that run 60-90 minutes, this limitation won’t help.
There are three ways to handle this problem:
Recursive summarization periodically compresses older conversation segments. The agent reads the last N turns, generates a summary, replaces those turns with the summary, and continues. This keeps the context window manageable, but specific words a user said and the exact phrasing of important moments get lost in the process. It works well when the general arc of a session matters more than specific details.
Sliding window with memory writes keeps only the most recent N minutes in the context window, while relying on the memory layer to preserve important details from earlier in the session. Because memory writes happen per-round, the agent has access to anything from earlier in the conversation through retrieval, even if it's no longer in the context window. This is the most common pattern in production because it handles long sessions gracefully without requiring a separate summarization step.
Chunked sessions break conversations at logical boundaries, such as topic changes or natural pauses, and treat each chunk as an independent unit for memory purposes. This preserves more fine-grained detail than summarization, but introduces complexity in detecting where to chunk and how to maintain continuity across chunks when the user expects a seamless experience.
Each approach loses something. Summarization loses detail. Sliding windows lose continuity. Chunking loses conversational flow. The right choice depends on which of those losses your use case can absorb.
Then There’s the Latency
Memory operations compete with everything else for the time users are willing to wait. Here's how each approach typically contributes to total response latency:
Operation | Typical Latency | When It Occurs |
|---|---|---|
Memory retrieval (semantic search) | 50–200 ms | Before LLM call |
Memory storage (async) | 0 ms (non-blocking) | After response |
Pre-loaded context | 0 ms per turn | Session start only |
Parallel memory agent | 0 ms on voice path | Background |
What users tolerate in terms of latency, can vary significantly by context. Casual conversational agents need to stay under 1 second total. Tutoring and guided sessions can accommodate 1–2 seconds. Customer service interactions can stretch to 2–3 seconds before users start expressing frustration.
You have to determine your tolerance ceiling before you design the retrieval layer.
A Note on Audio-Native Memory
The standard memory pipeline works on text transcriptions:
Audio → Speech-to-Text → Text → Memory Extraction
Transcription often discards information. Tone, hesitation, pacing, and emotional register are all gone by the time you're doing memory extraction.
For many use cases this doesn't matter. But there are domains like language learning being the clearest example, where how something is said is as important as what was said. A student's hesitation before producing a sound, or the confidence in their phrasing, is a signal that transcription reduces to the word they eventually produced.
Multimodal models like GPT-4o (and beyond) and Gemini can process audio directly, which means memory extraction can operate on the raw audio rather than a text approximation. This is still early in terms of production readiness and cost efficiency, but it's worth tracking if your domain depends on paralinguistic signals.
Use Cases for Memory in Voice Agents and Assistants
General Voice Assistant: Pre-load recent memories at session start, write per-round, and use generic extraction. Add more sophisticated retrieval only after identifying specific failure cases in production.
Educational/Tutoring Agent: Domain-specific instructions and structured schemas are worth the setup time. Per-round writes with per-turn semantic search make sense here because response relevance directly affects learning outcomes, and users have higher latency tolerance than in casual conversation.
Therapy/Wellness Companion: Structured schemas with careful filtering prevent the memory store from accumulating noise that resurfaces at the wrong moment. The parallel agent pattern works well because the memory agent can do deliberate reasoning about what to extract without affecting conversational flow. Also, memory retention policies and user controls over stored data are not optional here, both from a product standpoint and an increasingly regulatory one.
Customer Service: Within-session context management matters more than persistent cross-session memory. Focus on summarization and sliding window approaches to handle long calls. Cross-session memory for repeat callers improves experience but is not a foundational requirement.
Common Failure Modes
Ignoring memory decay: Preferences and patterns change over time. A user's stated preferences from six months ago may no longer reflect how they want to interact with the agent. Time-weighting memories so recent context takes priority in retrieval reduces this problem significantly.
Synchronous memory operations on the voice path: Any blocking call in the voice pipeline is directly felt as latency. Writes must be async. Retrieval should be as fast as your infrastructure allows, or moved off the critical path with pre-loading or parallel processing.
No user visibility or control: Users should be able to see what the agent has stored about them and delete specific memories. Beyond being a reasonable product expectation, it is increasingly a regulatory requirement in jurisdictions with data protection laws that cover AI-generated personal profiles.
Putting 2 and 2 Together
The architecture you choose for memory determines how relevant the injected context is, how much latency it adds, and how well it holds up when sessions run long or users drop off mid-conversation. The decision compounds as retrieval quality depends on what you stored, which depends on when you wrote it, which further depends on where in the pipeline that happens.
So instead of being overwhelmed by the complexity, I’d recommend starting with the simplest combination that covers your use case. Pre-loaded context and per-round writes handle most applications well. Semantic search, structured schemas, and parallel agent architectures are worth layering in once you have production evidence that something simpler is falling short.
Building a voice agent that needs memory? Mem0 provides the memory layer — retrieval, storage, and lifecycle management — so you can focus on the experience.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

