



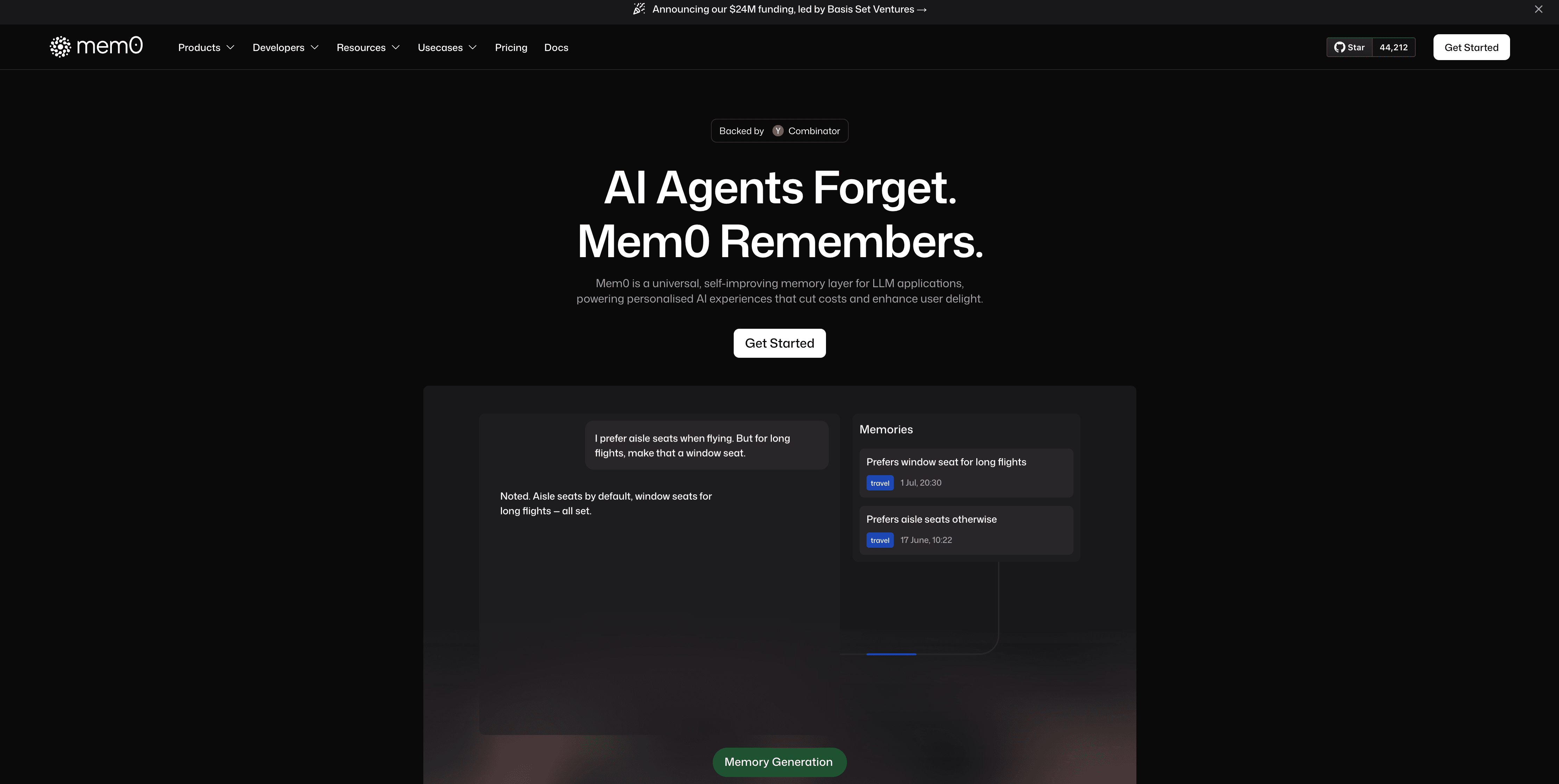
We're past the point where stateless AI agents make sense. Users expect systems that remember their preferences, recall past conversations, and adapt over time. But most agents forget everything the moment a session closes. They can't personalize because they lack persistent memory. Every interaction starts fresh, forcing users to repeat context and agents to reprocess the same information. Memory layers change this by storing facts across sessions and retrieving them when needed.
TLDR:
AI memory stores user context across sessions, allowing personalization that context windows can't provide
Memory layers cut token costs by ~90% and reduce latency by ~91% versus sending full conversation history
Vector databases handle semantic retrieval while graph structures track relationships between stored facts
Production systems need filtering, lifecycle policies, and compliance controls for GDPR, HIPAA, and SOC 2
What Is AI Memory

AI memory is the technology layer which can be implemented in AI Agents to store and recall information from earlier interactions. Without it, agents treat every conversation as brand new. No preferences are saved. No prior context is retained. Each session exists in isolation. When agents have a memory layer, they persist data across sessions. They store user preferences, past exchanges, and learned context in a retrieval layer. When the user returns, the agent accesses stored information and picks up where the conversation ended.
This difference determines whether an AI experience is personalized. An assistant that forgets your preferences or previous requests after every session can't adapt to your needs. Memory turns single-interaction tools into systems that adjust their responses based on accumulated context.
AI Agent Memory Adoption and Market Growth
78% of organizations already run AI in production, with 85% deploying agents in at least one workflow. Implementation has moved from pilots to live systems handling real user interactions. This is reflective of the the AI agent market, which reached $3.7 billion in 2023 and is projected to grow to $7.38 billion by end of 2025 and $103.6 billion by 2032. This acceleration tracks with deployment patterns in customer support, productivity tools, and personalized assistants where persistent memory directly impacts retention and cost per interaction.
But this kind of growth couldn't be supported unless agent memory adoption had demonstrable business impact. And it does. Agents that maintain cross-session context outperform stateless alternatives. Organizations report measurable gains in user retention when agents recall previous interactions instead of treating each session as new.
Still, there are a lot of AI agents that don't use memory layers and rely, instead, on a proven approach that, unfortunately, doesn't quite offer the same kind of long-term benefits: context windows.
Why Context Windows Are Not Enough for AI Memory
As an alternative to implementing an AI memory layer, developers rely on context windows to create some sense of continuity between sessions. But, this isn't always effective. And, what's more, when context windows become overly large, such as 100K + tokens, sending full conversation history with every request can greatly increase token costs (not to mention slowing down the user experience with increased latency). This is because when using a context window for session continuity, agents reprocess the same information repeatedly instead of storing it once.
But using context windows for session persistence exposes another short-coming of the approach as well: hardware constraints. While, server compute has scaled at 3.0× every two years, DRAM bandwidth has only grown 1.6× over the same period. So, as context windows grow, they rely more heavily on compute power, requiring additional hardware and increasing the overall cost of the agent.
How AI Agent Memory Works
Purpose-built memory layers, though, store and retrieve specific context instead of passing thousands of tokens per call. Agents query persistent memory for relevant facts, reducing costs and improving response time without hitting context limits. How does an AI memory system work?
AI agent memory splits into two layers:
Short-term memory handles active conversation context during a session. This kind of memory exists in the agent's working context. It contains recent messages and immediate state. Once the conversation closes, this information vanishes unless saved elsewhere.
Long-term memory stores facts, preferences, and learned information that survive after the session ends. This kind of memory needs external storage. During interactions, agents extract and write facts to a database. When the user returns, the agent queries this storage and pulls relevant memories before responding.
Understanding how AI agent memory works also requires knowing more about how memory is structured in AI agents. There are two structures to understand: memory types and memory hierarchy.
Types of Memory in AI Agents
AI agents implement three memory types that mirror cognitive models:
Episodic memory stores interaction-specific events. The agent recalls "user requested API documentation for webhook setup" or "discussed deployment errors in previous session." These entries include temporal markers that preserve when conversations occurred.
Semantic memory holds extracted knowledge without event context. The agent knows "user codes in TypeScript" or "prefers async/await over promises" without linking these facts to specific timestamps. Information generalizes across interactions.
Procedural memory encodes behavioral patterns. The agent learns which code formatting the user expects or how to structure multi-step responses. This guides execution logic instead of storing retrievable facts.
Memory Hierarchy
In addition to those three types of memory, there is also a memory-hierarchy for AI agents. And just like those types, there are three levels of memory hierarchy:
User-level memory maintains persistent context tied to individuals across all sessions. Communication preferences, technical background, and recurring needs stay accessible regardless of conversation scope.
Session-level memory contains task-specific details within isolated threads. Context relevant to one debugging conversation doesn't bleed into unrelated discussions. Starting a new session clears this layer while preserving user-level data.
Agent-level memory aggregates system-wide information independent of individual users. Operational rules, shared knowledge bases, or cross-user insights live here for collective access.
Building Memory Layers for AI Agents
While building and implementing an AI agent memory system is straight-forward enough, there is a consideration to be made regarding how the agent interfaces with that memory during user interactions: database selection.
One option is to use a vector database, such as Pinecone, to handle memory implementations. Each memory converts to a semantic embedding. Retrieval uses similarity search: the agent's current query finds related memories through vector proximity. An alternative option is to use a graph-based system. This approach adds structure to the storage of memories which become nodes with explicit connections between them. A user's preference links to specific projects. One conversation references another. But the most successful agents use a hybrid architecture which combines vector search with graph traversal for deeper context.
When retrieving information from the memory layer, then, agents query for relevant context, not loading everything. Filters, metadata tags, and ranking control which memories surface. This balances token usage against context quality.
A Note on Filtering, Quality Control, and Lifecycle Management
Retrieving information from memory can't be a brute force activity. It needs to have finesse and thoughtfulness to make the most efficient use of that memory. That comes down to filtering.
Memory filtering prevents irrelevant or sensitive data from accumulating. Rule-based filters applied at write time exclude content types that shouldn't persist such as temporary instructions, test data, or private information. Field-level controls let you specify which attributes get stored and which get discarded.
For example, in a customer support agent, system prompts like “respond politely” or one-off debugging messages may appear in every conversation but provide no long-term value. A filtering layer can prevent these from being written to memory, while still retaining durable facts such as a customer’s preferred language or past issue history. Without this kind of filtering, memory quickly fills with noise, and each low-value fact increases the likelihood of surfacing irrelevant context during retrieval, degrading response quality over time.
Lifecycle Management
Lifecycle policies determine how long memories persist and what happens when they update. Expiration rules remove outdated facts automatically, such as last year's address or an old product preference which shouldn't influence current behavior. Versioning tracks how memories change instead of overwriting previous values, which matters for auditing or rolling back incorrect updates. Export and audit capabilities support debugging and compliance. When an agent behaves unexpectedly, inspecting stored memories often reveals the source. Compliance requirements may mandate data portability or deletion workflows.
The Memory Wall Problem in AI Systems
As we mentioned previously, context window growth can expose hardware issues. But memory layers can also suffer from a similar problem. Called the "memory wall", this is the performance gap between processor speed and memory bandwidth. AI accelerators can execute trillions of operations per second, but they stall waiting for data to arrive from memory. This architectural mismatch creates idle cycles where compute sits unused while memory systems struggle to feed data fast enough.
AI workloads amplify this problem. Training and inference require moving massive weight matrices and activation tensors between memory and compute units. High-bandwidth memory helps but doesn't eliminate the bottleneck. Memory access latency and throughput remain the limiting factor for model performance. Most AI systems are now memory-bound, not compute-bound. Adding more processing cores doesn't improve speed if memory can't supply data at the required rate. Optimization now focuses on minimizing memory transfers and improving data locality.
Memory Management Challenges in AI Systems
But that memory wall is only one of the challenges to managing memory in AI systems. Consider the following additional challenges:
Persistence. Deciding what to persist requires filtering valuable context from conversational noise. Not every user statement warrants storage. Storing too much dilutes retrieval quality. Storing too little breaks continuity across sessions. Automated extraction models reduce manual effort but introduce classification errors that accumulate over time.
Pruning. Getting rid of outdated facts presents timing problems. Context decays at different rates. A project deadline becomes irrelevant after completion, while a communication preference may stay valid indefinitely. Manual deletion doesn't scale. Time-based expiration risks removing context that remains useful.
Distributed agent. When an AI agent is deployed in a distributed setup, there are often multiple running instances of the agent that can all serve the same user. If one instance writes new information to memory (for example, something the user just said), that update needs to be shared with the other instances. If another instance handles the next user request before that update has fully propagated, it may read outdated memory. This results in the agent missing or “forgetting” recent information, which can disrupt the conversation and make the agent feel inconsistent.
Privacy and Security in AI Memory Systems
Now that you understand what makes an AI agent memory system, and the challenges of building and implementing memory for your AI agent, it's time to look at some of the big-picture considerations like privacy and security.
Persistent memory creates compliance obligations. Systems storing user data across sessions fall under GDPR, HIPAA, and SOC 2 requirements depending on jurisdiction and data type. GDPR mandates explicit user consent and deletion rights. HIPAA requires encryption for any health-related information. SOC 2 controls cover access management and audit trails. Production memory deployments need these protections configured before handling real user data. What kind of methods can you use to protect that data? Here are a few to consider:
Encryption protects stored memories at rest and during transmission.
Access controls limit read and write permissions to authorized services.
Audit logs record every memory operation, creating a reviewable trail for compliance audits.
Organizations in regulated industries require these controls at the memory layer, not as bolt-on additions.
User control builds trust. For example, deletion endpoints allow users to remove specific memories or clear their complete history while export functions support data portability requirements. Retention policies automatically remove old memories based on time or relevance thresholds, preserving personalization while limiting data exposure.
Open Source vs Managed Memory Solutions
Finally, you are at the point to make a decision about the technology to use for your AI agent memory layer. And you've got choice. You could go open-source or you could choose a provider.
Open-source memory frameworks provide deployment control and code-level visibility. You run the infrastructure, modify retrieval logic, and keep data in your own environment. This matters for compliance requirements that mandate on-premise hosting or when you need customizations that hosted services don't support. The tradeoff is overhead. You handle vector database management, scaling decisions, security implementation, and ongoing maintenance. Teams without dedicated infrastructure resources frequently underestimate this burden. Managed services remove infrastructure work. Security certifications, encryption, audit logging, and scaling arrive pre-configured. You integrate through an API and pay for usage instead of provisioning servers.
Mem0's $24M-backed memory layer supports both approaches. The open-source SDK provides self-hosting with complete code access. The cloud service delivers SOC 2 compliance and managed infrastructure for teams that need deployment speed.
Final thoughts on memory layers for AI applications
Long-term memory for AI turns single-interaction tools into systems that adapt based on accumulated context. Your agents reduce token costs by retrieving stored facts instead of reprocessing full conversation history every call. Implement semantic search for retrieval, add filtering at write time to control what persists, and configure lifecycle policies that remove outdated information automatically.
FAQ
How do I add memory to an existing AI agent?
Most memory implementations require a vector database for storage, an embedding model to encode facts, and retrieval logic to query relevant context at runtime. With purpose-built memory SDKs, integration typically takes a few lines of code: initialize the client, call add() to store memories during conversations, and search() to retrieve context before generating responses.
What's the difference between RAG and memory in AI applications?
RAG retrieves information from static knowledge bases, such as documentation, articles, or reference material that doesn't change based on user interactions. Memory stores user-specific facts that evolve with each conversation including preferences, past exchanges, and behavioral patterns. Production agents typically need both: RAG for domain expertise, memory for personalization.
When should I use graph-based memory instead of vector search?
Start with vector search for semantic retrieval of relevant facts and preferences. Add graph structures only when your agent needs to understand explicit relationships between memories. This includes connecting user preferences to specific entities, tracking how facts evolve over time, or moving through hierarchical dependencies. Most implementations don't require graph complexity initially.
Why does my AI agent need persistent memory if context windows now support 100K+ tokens?
Sending full conversation history with every request increases latency and token costs without solving memory. Agents reprocess the same information repeatedly instead of storing it once. Memory layers extract and persist facts, then retrieve only what's needed for each query: reducing costs, improving response time, and avoiding the memory bandwidth bottleneck that limits performance as context expands.
Can I control what information gets stored in my agent's memory?
Field-level filters applied at write time exclude content types that shouldn't persist such as temporary instructions, test data, or sensitive information. Lifecycle policies determine retention periods, automatically removing outdated facts based on time or relevance thresholds. Export and deletion endpoints support compliance requirements and give users control over their stored data.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

