



By default, every API call to an LLM is a fresh event. The model knows everything about the world up until its training cutoff, but it knows nothing about you, your preferences, or the conversation you had five minutes ago irrespective of how many times you repeat yourself.
So, if you're planning to build an agent that feels truly intelligent, a better model is not enough. You need an agent with memory.
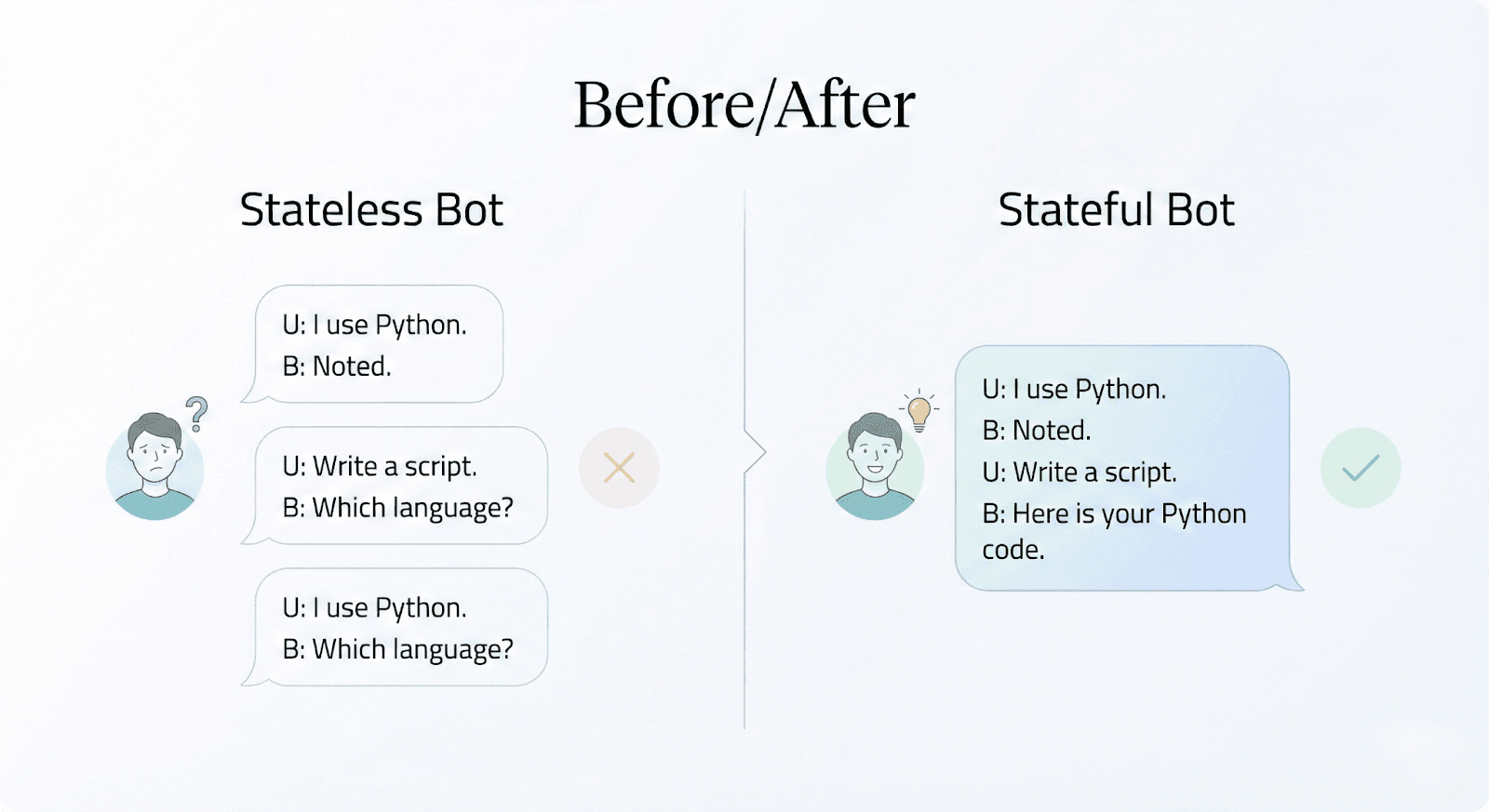
TL;DR
The Problem: Every time you call an LLM API, it starts fresh with no memory of previous conversations. It's like talking to someone with amnesia.
Why It Matters: Sending entire conversation histories with every request gets expensive and slow. You need a smarter way to remember what's important.
RAG is for facts, AI Memory is for state: RAG retrieves static knowledge. AI Memory must manage evolving user state, including updates and contradictions.
Mem0 is the bridge: Mem0 provides a managed AI memory layer that handles extraction, retrieval, and preference updates so agents remain consistent over time.
What is context retention?
Context retention in AI engineering is the system architecture that enables a model to recall information from previous interactions and apply it to the current generation.
It's often marketed as "Personalization" or "Long-term Recall," but let's strip away the buzzwords.
At its core, context retention is string manipulation and database queries. But the difficulty lies in deciding what to store and when to retrieve it.
At the lowest level, an LLM API call looks like this: function(prompt) -> response. To give an LLM "memory," you're simply changing the function to: function(retrieved_history + prompt) -> response.
The challenge is in engineering. You have to decide what information is worth storing, how it should be retrieved, how long it should persist, and when it needs to be updated or removed. These choices directly affect cost, latency, and model behavior.
You need a retrieval policy for past messages. If you send the full history every time, you'd be overpaying for API tokens. If you send irrelevant history, you increase model hallucinations.
That's why you need well-implemented context retention. Your agents should be able to store user state and only pull the most relevant memories based on the current user query.
Building memory: From Naive to Production-Ready
We're going to build a chatbot that evolves from having no memory to having perfect recall. We'll start with the naive approach to see why it breaks, examine the architecture of stateful agents, and then implement a production-grade solution using Mem0.
Level 1: The naive approach (list appending)
The first way every developer tries to solve memory is by keeping a Python list running in the application RAM. This is often called "Buffer Memory."
Here's a simple script using Google's Gemini 3 Flash model.
The output:
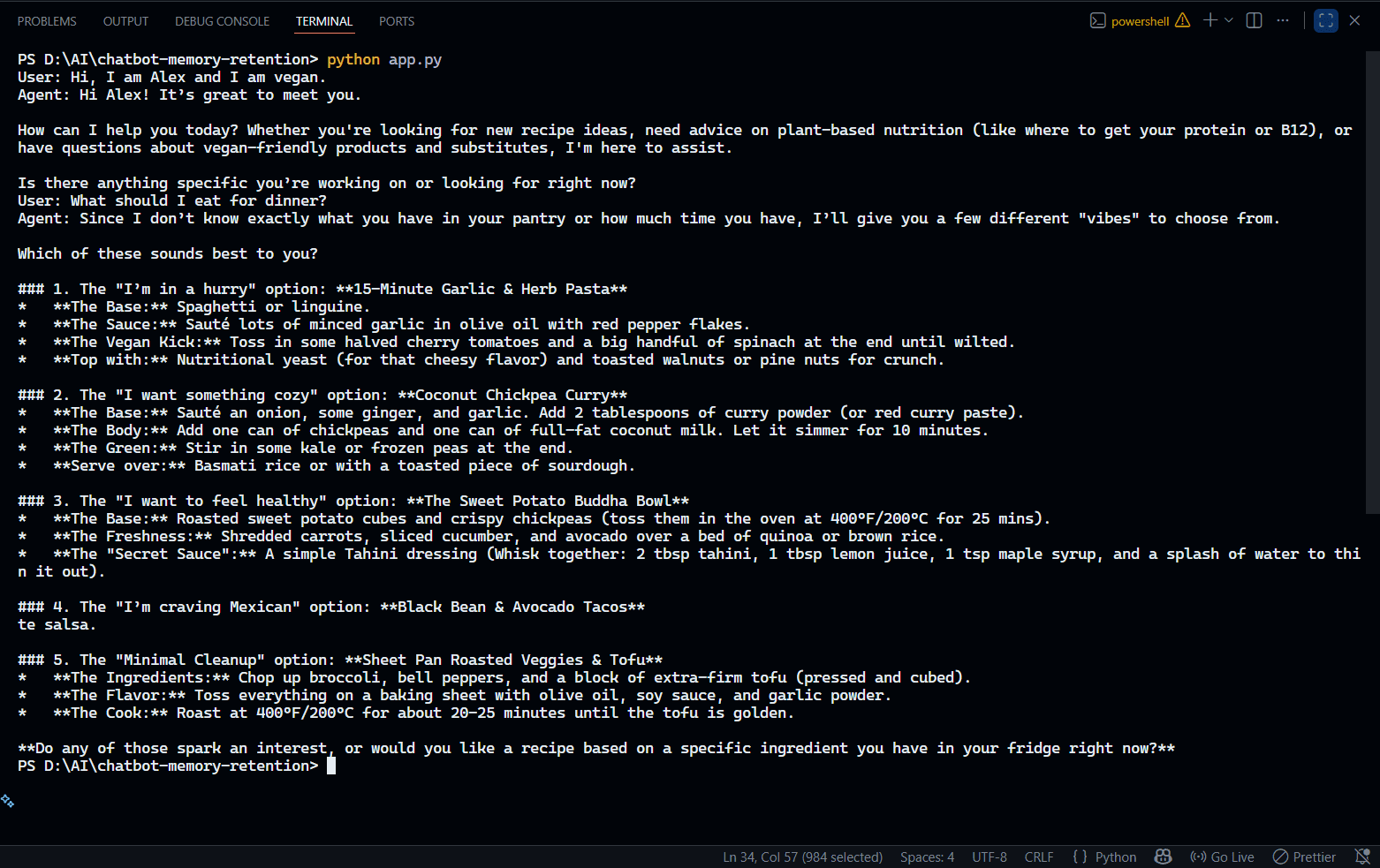
It works, but let's look closer at the mechanics.
In the first call, we sent around 15 tokens. In the second call, we sent 60 tokens. By the 10th turn of the conversation, we’re sending thousands of tokens for every single request.
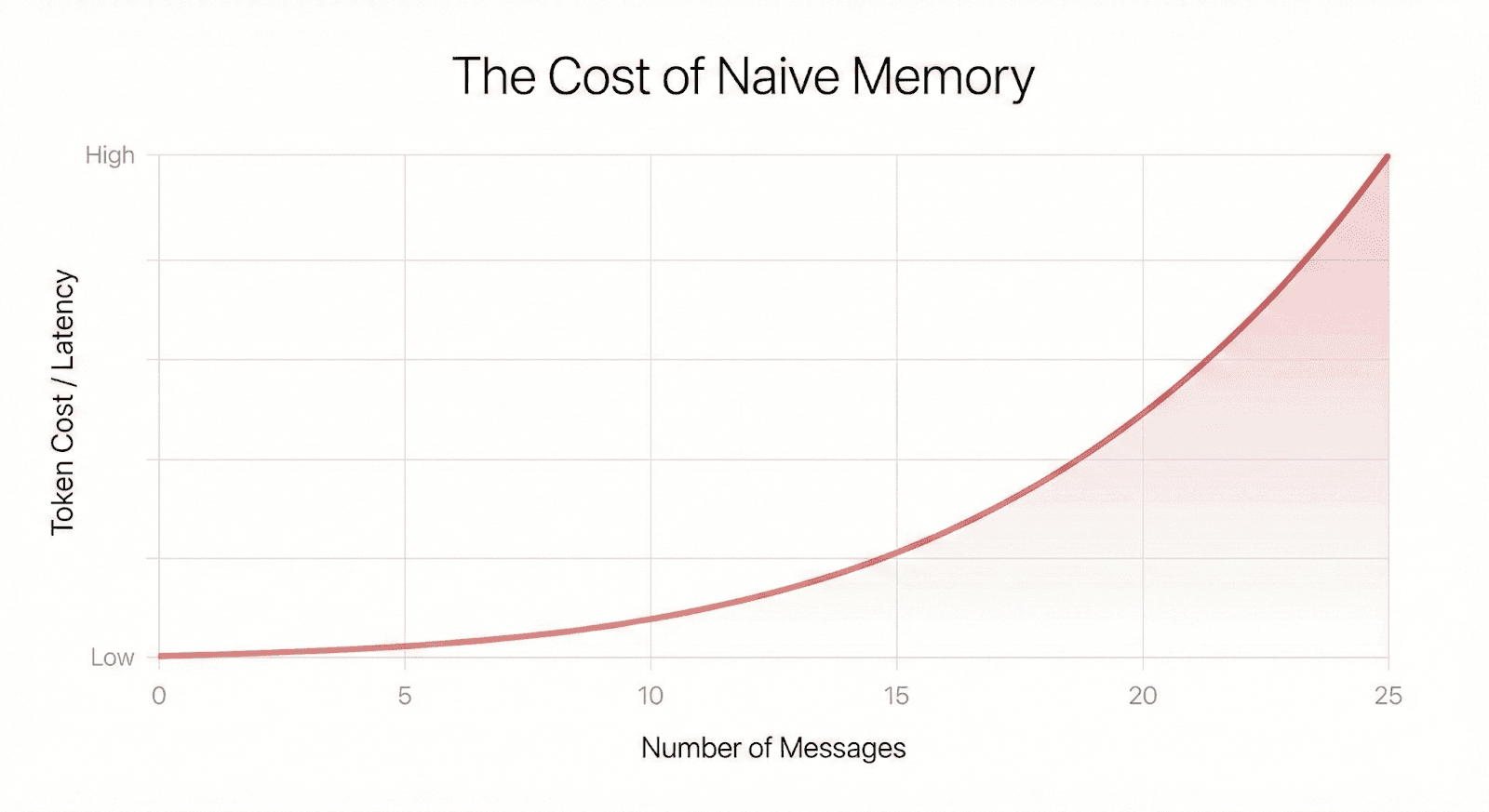
This approach fails in production for three reasons:
Cost: You pay for the entire history on every turn. With Gemini 3 Flash, a long conversation history can cost significant money over time.
Latency: Processing long contexts takes time. Time to First Token (TTFT) degrades linearly with prompt size.
Persistence: If the Python script crashes or the server restarts, conversation_history is wiped. The user is a stranger again.
Level 2: The architecture of persistent memory
To fix the issues above, we need to move state out of the application RAM and into a durable storage layer.
However, we can't just dump everything into a database and retrieve it all. We need a system that mimics human memory. When you talk to a friend, they don't recall every word you've ever said to them chronologically. They recall relevant information based on the current context.
A proper memory architecture requires three components:
Storage: A place to keep data (Vector Database + Relational Database).
Retrieval: A mechanism to find relevant data (Semantic Search).
Management: A way to update, delete, and resolve conflicts in data (Memory consolidation).
Most developers try to build this stack themselves using LangChain and a raw vector database like Pinecone or Qdrant. They usually run into the "Update Problem."
The update problem:
Monday: User says "I love Python." → Vector DB stores embedding for "Loves Python".
Tuesday: User says "I hate Python, I only use Go now." → Vector DB stores embedding for "Hates Python".
Wednesday: User asks "Write me a script." → Vector Search retrieves both conflicting memories. The LLM gets confused.
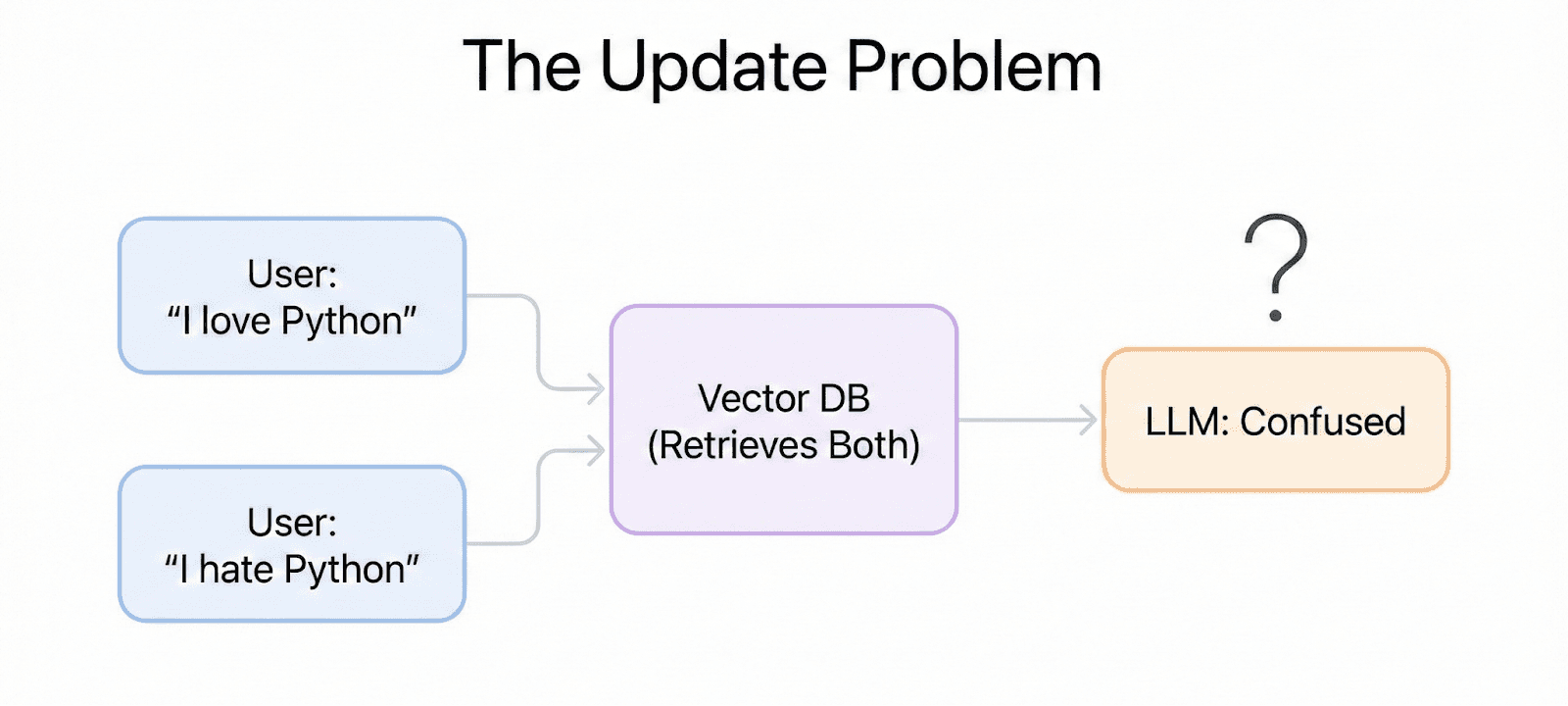
You need a management layer that understands entities and updates. Mem0 is one way to handle this.
Level 3: Implementing production memory with Mem0
Let's build a personalized travel assistant. The goal is for the bot to remember my preferences across different sessions without me repeating them, and to handle updates gracefully.
Prerequisites:
Setup your environment variables:
Create a .env file in your project root:
GEMINI_API_KEY=your_gemini_api_key_here
MEM0_API_KEY=your_mem0_api_key_here
You can get:
Gemini API key from Google AI Studio
Mem0 API key from app.mem0.ai
Step 1: Storing memory
First, let's initialize Mem0 and store some initial context. In a real app, this happens dynamically as the user chats, but we'll seed it manually here to demonstrate the storage.
The output:
Terminal Output
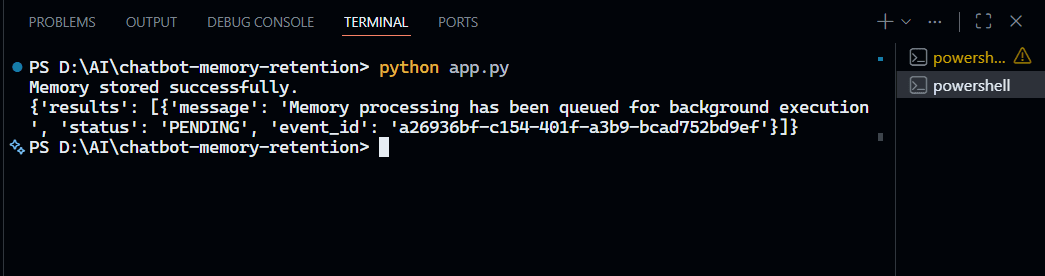
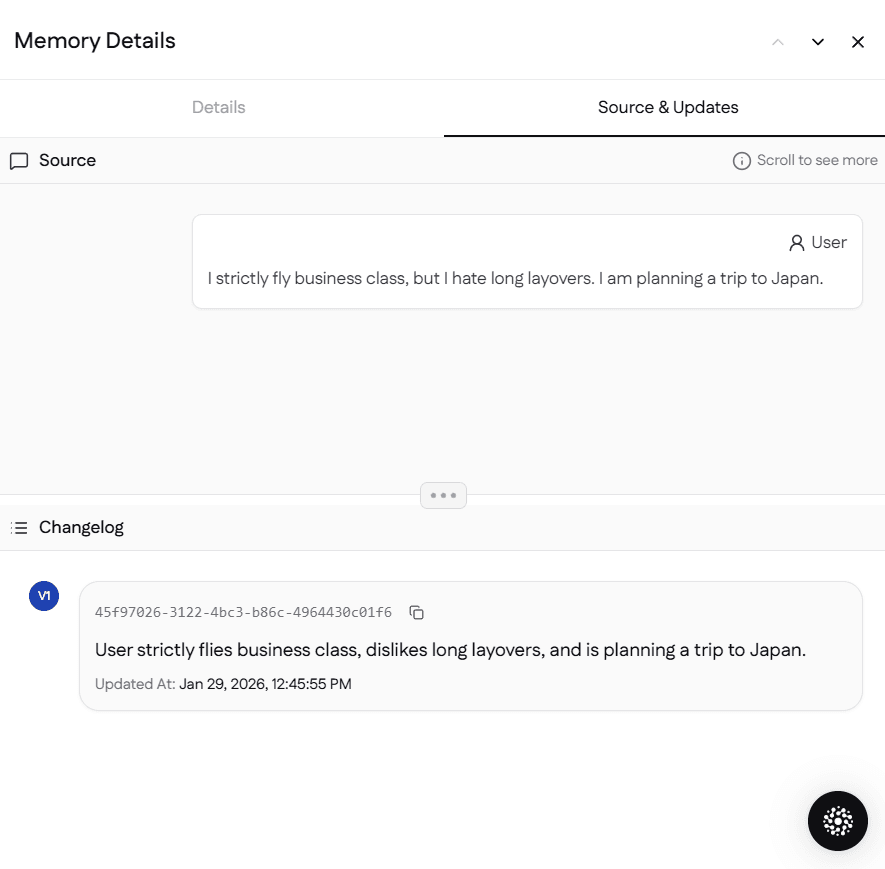
Notice that with the current Mem0 API, memory processing happens asynchronously in the background. The memory extraction and storage is queued, and you can check the Mem0 dashboard to see the extracted facts once processing is complete.
When you check the dashboard (as shown in the screenshots), you'll see Mem0 extracted specific facts:
"The user strictly flies business class, dislikes long layovers, and is planning a trip to Japan."
This is distinct from RAG, which splits documents into fixed chunks. By extracting facts, we make the memory more usable for the LLM.
Step 2: Retrieving context
Now, imagine the server restarts. A week passes. The user comes back. In a naive system, we would have to ask "Where do you want to go?" and "What is your budget?" again.
With Mem0, we retrieve only the user-specific memories that are relevant to the current request before calling the LLM.
The output:
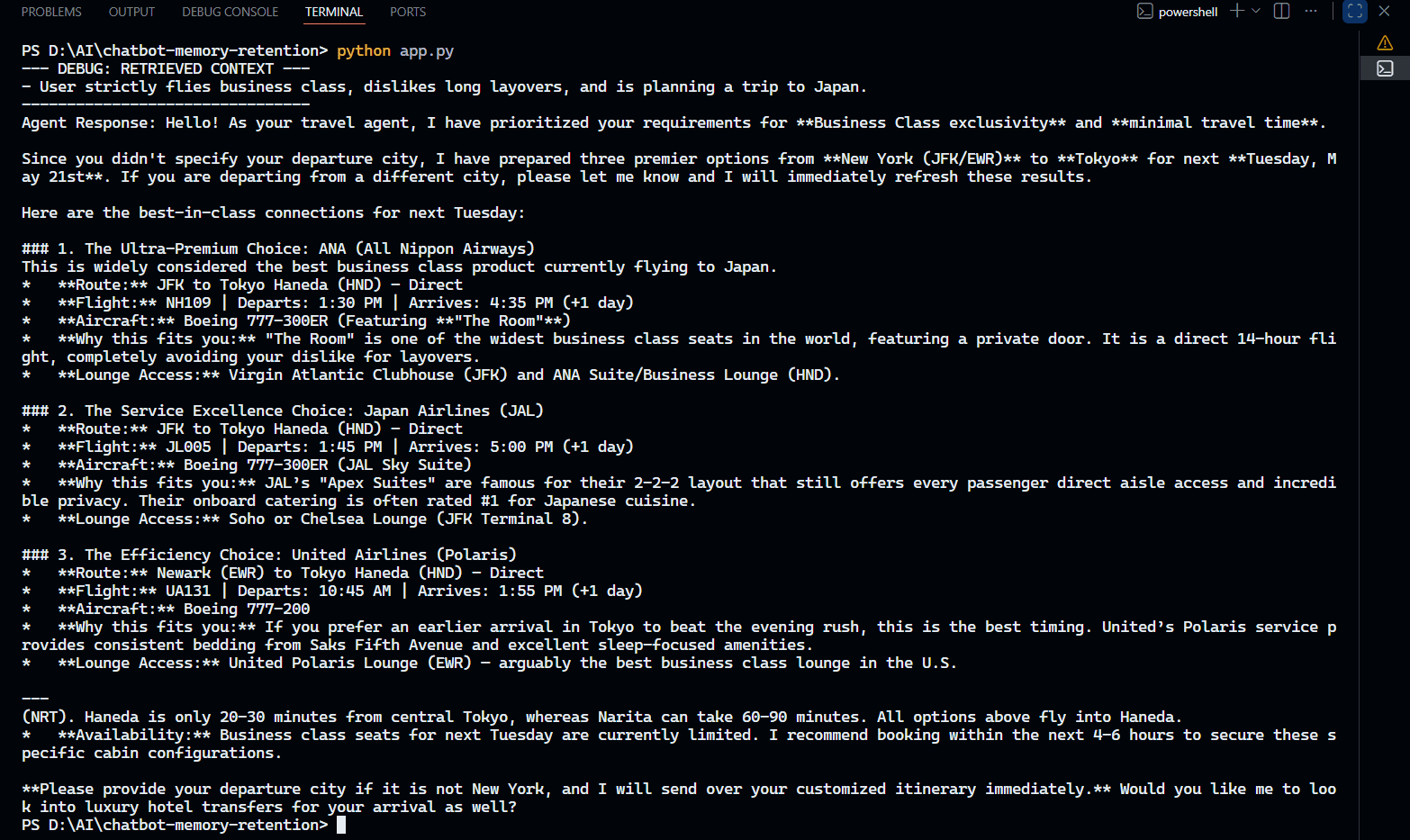
Why this is powerful: The user never mentioned "Japan," "Business Class," or "Tokyo" in their second query. They just said "flight options."
The Mem0 search() function took the query "Find me flight options," looked at the vector store associated with traveler_01, and realized that previous memories about Japan and flying preferences were semantically relevant.
If the user had 1,000 other memories about "liking cats" or "hating JavaScript," Mem0 would have filtered those out because they're irrelevant to a flight search. This keeps your context window lean and your costs low.
Step 3: Handling updates (memory consolidation)
Let's look at the "Update Problem" we mentioned earlier. What if the user's situation changes?
The output:
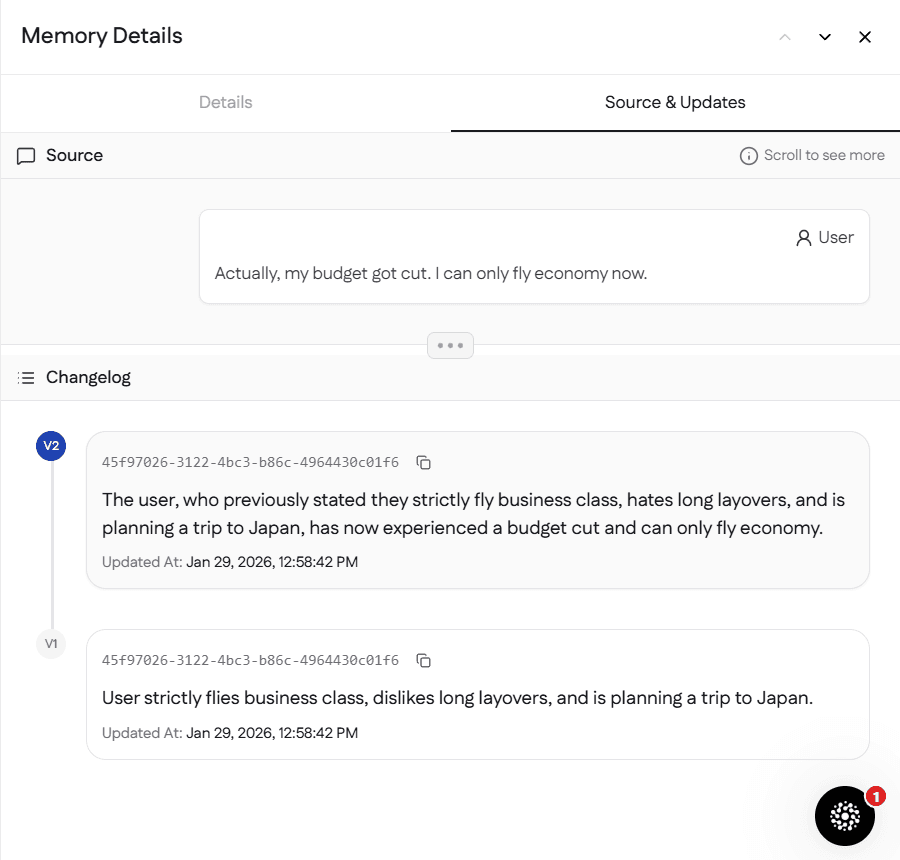
Mem0 detected the conflict regarding flight class and intelligently updated the memory. Rather than simply replacing "business class" with "economy class," it preserved the context that this was a change from a previous preference. This nuanced understanding makes Mem0’s memory management better suited than simple key-value storage for long-running agents.
This "Dynamic Forgetting" is essential for long-running agents. Without it, your agent eventually becomes internally inconsistent, holding onto every contradictory belief the user has ever held.
Looking at the Mem0 dashboard (as shown in the screenshots), you can see the changelog tracking how memories evolve:
Changelog in Mem0 Dashboard:
v1: "The user strictly flies business class, dislikes long layovers, and is planning a trip to Japan."
v2: "The user, who previously stated they strictly fly business class, hates long layovers, and is planning a trip to Japan, has now experienced a budget cut and can only fly economy."
This version tracking allows you to understand how user preferences change over time while maintaining only the most current, relevant information. The system preserves context about why preferences changed, which is invaluable for maintaining conversational coherence.
Level 4: Advanced patterns for robust agents
Once you have the read/write loop working, you need to consider how to structure the data for complex use cases.
1. Session vs. user memory
Not all memory is created equal. You should categorize memory based on its lifespan.
Short-term (Session): "I just asked you to debug this specific function." This is relevant for 10 minutes.
Long-term (User): "I prefer TypeScript over Python." This is relevant forever.
In Mem0, you can handle this by using metadata filters or by separating user_id (for long term) and session_id (for short term). A common pattern is to dump the raw chat logs into a short-term buffer (passed directly to the LLM) and asynchronously process them into Mem0 for long-term storage.
2. Graph memory (advanced)
For most applications, the vector-based memory retrieval we've covered is sufficient. However, it's worth mentioning that Mem0 also supports graph-based memory for advanced use cases requiring complex relationship tracking between entities.
Graph memory is beyond the scope of this tutorial. I’d recommend learning about vector-based memory first before exploring graph memory. If you're curious, you can check the Mem0 graph memory documentation.
Note: Graph memory features are only available with Mem0's Pro plan or higher.
3. Separation of truth vs. memory
In highly reliable agents, you should distinguish between "Truth" and "Memory."
Truth: Hard data in a SQL database (e.g., active reminders, account balance). This is deterministic.
Memory: Soft preferences in Mem0 (e.g., "User usually snoozes reminders by 15 mins"). This is probabilistic.
Your system prompt should ingest both: "Here is the exact status of your tasks (SQL). Here is how you usually like to handle them (Mem0)."
Start building your memory layer
Context retention is the difference between a demo and a product. Users will forgive a hallucination or two, but they won't forgive an assistant that forgets their name or their preferences.
The trap developers fall into is trying to build their own vector pipeline. You'll spend weeks optimizing chunk sizes, debating overlap strategies, and fighting with re-ranking algorithms. And after all that, you'll still have to solve the "Update Problem" manually.
In many cases, your job is to build the agent, not maintain database infrastructure.
Start by implementing the simple read/write loop with Mem0 shown above. Test it with conflicting information. Watch how the agent "changes its mind" based on new data without you touching the prompt manually. Once you see that happen, you won't go back to stateless bots.
FAQs
Does adding memory increase latency?
Yes, there’s an extra retrieval call. But because Mem0 sends shorter, more relevant prompts to the LLM, generation is often faster, offsetting the added latency.
Can I use Mem0 with local LLMs like Ollama?
Yes. Mem0 is model-agnostic. You can pass the retrieved text into local models like Llama 3 just as you would with hosted models.
How is this different from built-in memory features?
Built-in memory is usually a black box. You can’t programmatically access, edit, or move it across models. Mem0 gives you full control and ownership of your memory data.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

