



When you're developing AI agents, it's not enough to think in terms of individual interactions and basic prompt crafting. You need to design complete information systems. Context engineering is the systematic approach of structuring context and memory so AI systems behave intelligently over time. This guide will show you how to implement context engineering techniques that change stateless AI demos into production-ready systems that learn, remember, and adapt over time.
TLDR:
Integrating RAG, memory systems, and context orchestration turns AI from reactive responders into adaptive systems that understand relationships and evolving context.
Enterprise-grade context engineering treats context as infrastructure, requiring scalable architectures, governance, and security to power reliable, compliant AI at scale.
Context poisoning and overload are solved through adaptive memory updates and intelligent relevance filtering.
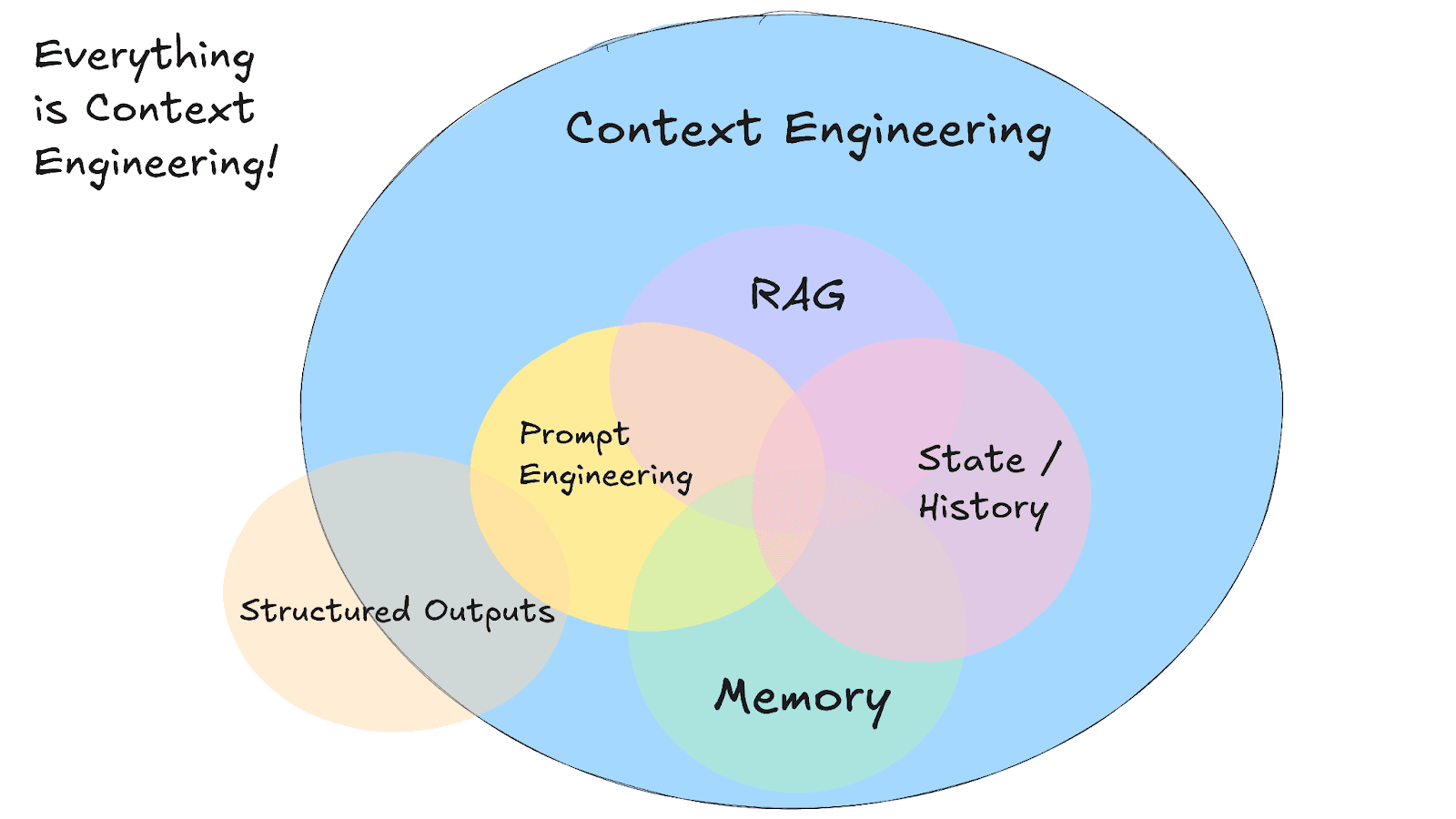
Image Source: @dexhorthy on X (formerly Twitter). Included for analysis and discussion.
What Is Context Engineering?
While prompt engineering asks, "What words should I use?" context engineering tackles a broader question: "What configuration of context is most likely to generate our model's desired behavior?"
This distinction matters because most agent failures today aren't model failures; they're context failures. When your AI agent gives irrelevant responses or forgets previous interactions, a lot of the times, the underlying LLM is usually working fine. The problem lies in the information that you're feeding it.
Context engineering focuses on the systematic design of information flow to AI agents, moving beyond simple prompting to sophisticated context management for production-ready applications.
Traditional prompt engineering worked well for one-off tasks, but building reliable AI agents requires a different approach. Context engineering covers everything from how you structure system prompts to how you manage long-term memory and retrieval systems. It's about creating the right information architecture so your AI agents can access relevant context when they need it.
Core Components of Context Engineering
Context engineering brings together several interlocking disciplines that work together to create intelligent AI agent behavior. Understanding these building blocks is important for designing systems that can handle complex, multi-turn interactions effectively. Below is a list of these components, from lowest level to system level:
Context sources. These are the raw inputs that can be injected into the model. Some examples include user input (queries, conversations), system instructions and policies, and retrieved documents (RAG).
Representation and encoding. This is how information is structured before entering the model. So plain text versus structured schemas (JSON), embeddings versus symbolic representations, summaries versus verbatim content, etc.
Selection and filtering. This building block represents the decision making of what to include and also what not to include. You can thing of this component in terms of relevance scoring, recency weighting, and importance/salience thresholds.
Compression and distillation. This reduces the context size without losing meaning and can include extractive summaries, abstractive summaries, and key-value or fact distillation.
Temporal management. This building block is about handling how context evolves over time. For example, short-term versus long-term memory, session versus cross-session memory, and forgetting and decay policies.
Context assembly and ordering. This determines how context is composed inside the prompt. Elements of this building block can include instruction hierarchy, tool results placement, and memory ordering (recent versus foundational).
Reasoning scaffolds. These are the structures that guide how the model uses context. This can include task decomposition hints, planning artifacts, and role or perspective framing.
Feedback and adaptation loops. Finally, this is how context improves itself over time and can address elements like error analysis and correction memory, preference learning, and reinforcement from outcomes.
Vector embeddings power much of this infrastructure, allowing semantic understanding across all components. Modern context engineering requires sophisticated orchestration of these elements.
Memory Management in Context Engineering
Memory management is one of the core pillars for effective context engineering, determining what information persists across interactions and how it gets retrieved when needed. The challenge goes beyond storing data: it's intelligently curating what matters most for future conversations.
Short-term memory handles immediate conversation context, typically spanning a single session. This includes recent exchanges, current task state, and working variables that help maintain conversational flow. But raw conversation history quickly overwhelms context windows, making compression important.
Long-term memory preserves knowledge across sessions: user preferences, past decisions, learned behaviors, and relationship history. This is where most traditional approaches fail, either losing critical context or drowning agents in irrelevant historical data.
Effective memory management requires intelligent compression that preserves meaning while discarding noise, making sure agents remember what matters without cognitive overload.
The key breakthrough is adaptive memory compression. Instead of storing raw transcripts, sophisticated systems extract and compress meaningful insights. OpenAI's session memory shows basic approaches, but production systems need more detailed strategies.
Memory retrieval strategies determine which stored information surfaces during conversations. Semantic search, recency weighting, and relevance scoring work together to surface the right context at the right time.
Context Engineering Techniques and Strategies
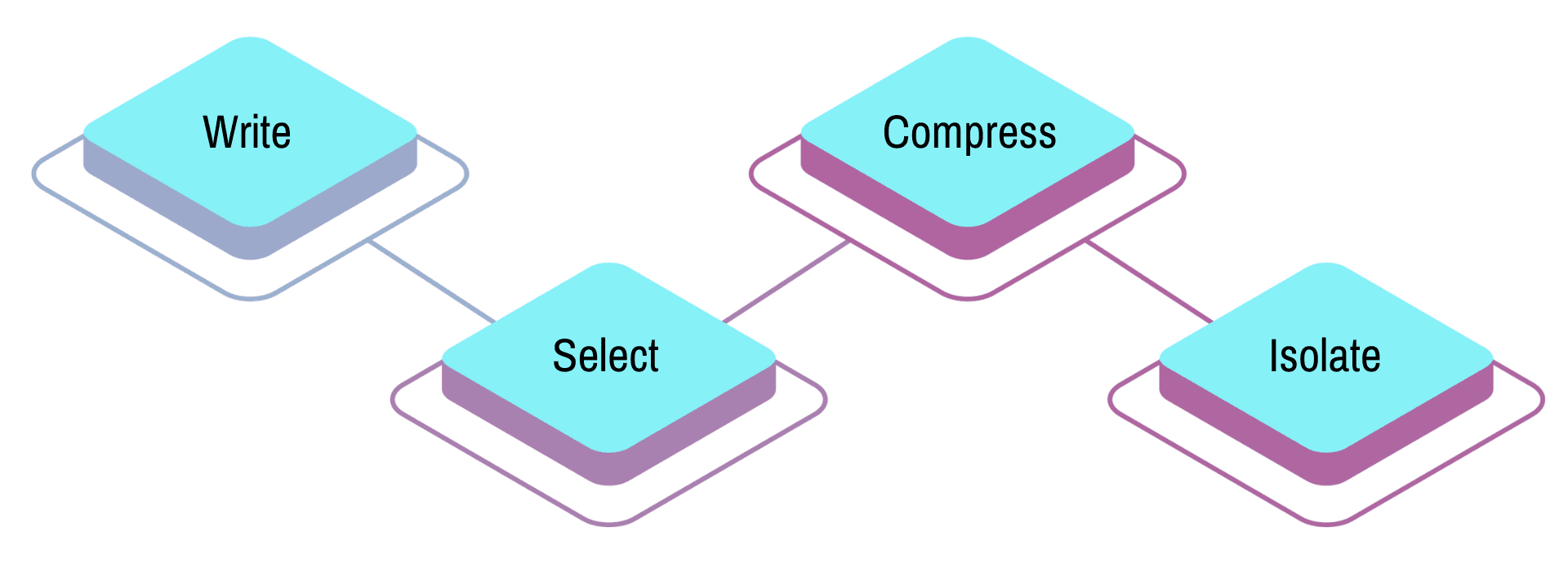
Context engineering techniques fall into four strategic categories that handle different aspects of information management: write, select, compress, and isolate. Each approach tackles specific challenges in maintaining optimal context for AI agents.
Write strategies involve persisting information outside the immediate context window. The most common implementation is the "scratchpad" approach, where agents maintain working notes during task execution. This technique helps agents track progress, store intermediate results, and maintain state across complex multi-step processes.
Select strategies focus on intelligent information filtering. Rather than including everything, these techniques identify and surface only the most relevant context for each interaction. Semantic search and relevance scoring determine what historical information deserves inclusion in the current context window.
Compress strategies retain important information while reducing token consumption. This involves summarizing conversations, extracting key facts, and creating condensed representations that preserve meaning without overwhelming the context window.
Context engineering is most effective when it combines all four strategies, creating systems that write selectively, compress intelligently, and isolate appropriately based on task requirements.
Isolate strategies separate different types of context to prevent interference. This might involve maintaining separate memory stores for different conversation topics or user relationships.
LangChain's research shows these techniques in practice, while academic work provides theoretical foundations.
RAG and Context Engineering Integration
RAG represents a powerful technique embedded within the broader context engineering framework. While RAG handles retrieval, context engineering manages the complete information flow: combining retrieval with compression, memory management, and intelligent formatting to deliver precisely the right information at exactly the right moment.
Traditional RAG systems retrieve relevant documents and stuff them into context windows. But sophisticated context engineering takes this further, using advanced techniques to organize and present information more effectively. This involves breaking documents into meaningful chunks, ranking information by relevance, and fitting the most useful details within token limits.
Multi-source integration becomes important when combining RAG with memory systems. Your agent needs to balance retrieved documents with stored user preferences, conversation history, and learned behaviors. This requires sophisticated coordination to prevent information conflicts.
The evolution from basic RAG to context-aware retrieval represents the difference between finding information and understanding what information matters for each specific user and situation.
Contextual compression enhances traditional RAG by filtering retrieved content based on current conversation context. Instead of including entire documents, advanced RAG techniques compress and filter information to surface only relevant portions.
The key is treating RAG as one component in a larger context engineering system rather than a standalone solution.
Enterprise Context Engineering in Practice
Enterprise context engineering changes how organizations deploy AI agents at scale, moving beyond proof-of-concepts to production systems that handle complex business workflows. The challenge goes beyond technical issues: it's organizational, requiring coordination across fragmented knowledge systems and diverse stakeholder requirements.
Knowledge unification is the primary enterprise challenge. Most organizations have information scattered across Confluence, Jira, SharePoint, Slack, CRMs, and countless databases. Context engineering provides the architecture to unify these disparate sources into coherent, searchable knowledge graphs that AI agents can work with effectively.
Compliance and security become critical in enterprise deployments. Unlike consumer applications, enterprise context engineering must meet strict regulatory requirements. Security compliance requirements aren't optional: they're table stakes for handling sensitive business data and customer information.
Enterprise context engineering succeeds when it aligns AI systems with company culture, business processes, and strategic objectives rather than technical features.
Scale and performance requirements differ dramatically from smaller implementations. Enterprise systems need to handle thousands of concurrent users, maintain sub-50ms query latency, and process massive knowledge bases without degradation.
Cognizant's deployment of 1,000 context engineers shows the industrial scale of this change. Companies are building dedicated teams to manage context engineering as a core competency.
The key is treating context engineering as organizational infrastructure, rather than a technical implementation.
Context Engineering Tools and Implementation
Context engineering implementation requires the right combination of frameworks, tools, and architectural patterns. The field has evolved rapidly, with specialized tools appearing to handle different aspects of context management, from memory persistence to retrieval optimization.
LangGraph leads the framework space with built-in support for both thread-scoped and long-term memory. Its checkpointing system persists agent state across all steps, creating an effective "scratchpad" for maintaining context throughout complex workflows. This architecture allows agents to write information to state and retrieve it at any point in their path.

Popular Implementation Patterns include memory-augmented agents, context-aware RAG systems, and hybrid architectures that combine multiple memory types. GitHub repositories showcase practical implementations across different frameworks and use cases.
Integration Features become important when building production systems. Modern context engineering requires smooth integration with existing AI stacks, from OpenAI APIs to custom LLM deployments.
The best context engineering tools provide one-line integration while offering sophisticated customization options for complex enterprise requirements.
Best practices and frameworks focus on starting simple and scaling complexity as needed.
The key is choosing tools that grow with your needs while maintaining simplicity in initial implementation.
Context Engineering Challenges and Solutions
Context engineering faces four critical challenges that can derail even well-designed AI systems: context poisoning, context overload, token management, and performance optimization. Understanding these pitfalls and their solutions is important for building reliable production systems.
Context Poisoning occurs when incorrect or outdated information contaminates the context window. This happens frequently in multi-stage processes where early model responses contain incomplete answers that persist and influence final outputs. The solution involves context pruning: systematically removing conflicting or outdated information as new data arrives.
Context Overload overwhelms agents with too much information, degrading response quality and increasing latency. Research shows that more context doesn't always improve performance. Intelligent filtering and relevance scoring become important for maintaining optimal information density.
Token Management challenges arise from balancing full context with cost constraints. Raw conversation histories quickly exhaust context windows and inflate API costs. Effective compression strategies can reduce token usage by 80% while preserving important information.
Performance Optimization becomes critical at scale. Sub-50ms query latency requirements demand sophisticated caching, indexing, and retrieval strategies. Enterprise implementations require careful architecture to maintain responsiveness.
Mem0's Role in Context Engineering
Mem0's memory compression engine writes important context to persistent storage, selects relevant memories through semantic search, compresses information intelligently, and isolates different memory types. Companies like RevisionDojo use these techniques for personalized education applications.
Mem0's memory compression engine intelligently distills conversations into optimized representations, cutting token usage by up to 80% while preserving fidelity. Our system handles both AI companion memory and specialized applications like healthcare, where memory persistence is important for patient continuity.
And Mem0's semantic search and relevance scoring complement traditional RAG approaches by adding personalized context layers. Companies like OpenNote combine RAG with memory systems for personalized learning, while sales applications use this integration to maintain customer context alongside product information.
As for context poisoning, Mem0's adaptive memory updates handle it by resolving contradictions automatically. Our OpenMemory MCP integration shows how intelligent filtering prevents overload, while our compression engine tackles token management. And our research continues advancing solutions to these fundamental challenges.
FAQ
How do I get started with context engineering for my AI application?
Start with basic memory management by implementing short-term conversation history and gradually add long-term memory storage. Most teams can integrate a memory layer such as Mem0 with a single line of code and see immediate improvements in context retention.
What's the main difference between context engineering and prompt engineering?
Prompt engineering focuses on crafting individual prompts, while context engineering designs complete information systems that manage data flow to AI agents. Context engineering handles what information to feed your agent and when, rather than how to phrase requests.
When should I implement memory compression in my AI system?
Consider memory compression when your token costs are high or your agents lose important context in long conversations. If you're seeing degraded performance after 10 to 15 conversation turns or spending a lot of budget on tokens, compression can reduce usage while preserving conversation quality.
How can I prevent context poisoning in multi-turn conversations?
Implement adaptive memory updates that automatically resolve contradictions and filter outdated information. Use relevance scoring to focus on recent, accurate information over older data, and create clear policies for when to overwrite conflicting memories with new information.
Final Thoughts on Context Engineering for AI Agents
Context engineering represents the missing piece that changes basic AI demos into production-ready systems that truly understand and remember. The shift from crafting better prompts to designing intelligent memory architectures is what separates functional prototypes from AI agents that provide genuine value. Mem0 handles the complex orchestration of memory, compression, and retrieval so you can focus on building great user experiences rather than wrestling with context management. Your AI agents can finally remember what matters and forget what doesn't.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

