



If you need your AI agent to remember relationships (people, entities, timelines, tasks, preferences, etc.) and not just surface similar snippets of past context, then you'll need semantic memory + relational/graph-style representation. Embeddings will not be sufficient.
The difference between vector retrieval and graph memory comes down to relationships. Vectors find similar text, but graphs preserve how facts connect across sessions, letting your agent track changes in preferences and reason about entity relationships over time. We assessed five solutions that approach graph memory differently. Some automate entity extraction and relationship modeling, while others require manual setup and ongoing maintenance from your team. In this blog, we'll go through these top five graph-based memory solutions for your AI agent to help you make the best choice possible for your use case.
TLDR:
Graph-based memory stores AI context as connected entities and relationships, not flat text.
Vector memory retrieves similar exchanges but loses connections between facts over time.
Graph memory tracks how preferences change and preserves relationship structure across sessions.
Mem0 combines vector search with graph memory for 91% faster responses and 90% lower token costs.
What is Graph-Based AI Memory?
Graph-based AI memory stores conversational context as nodes and relationships instead of flat text or isolated vectors. Each piece of information becomes an entity connected to related facts through edges. Edges define their node's relationships.
How does this compare to the other primary AI memory approach? Vector-based memory embeds text as numerical representations for similarity search but loses explicit relationships between facts. Here's an example to really compare the two: a vector database might surface that a user likes coffee, but a graph memory knows that user prefers coffee from a specific shop, ordered last Tuesday, and mentioned it while discussing their morning routine. Just remember the difference like this: vector memory retrieves similar past exchanges but treats each memory independently while graph memory preserves how information connects across time, letting AI agents reason about relationships, track changes in preferences, and recall context with the structure intact. According to VentureBeat's 2026 enterprise AI predictions, contextual memory will become table stakes for operational agentic AI deployments rather than a novel technique, with agentic memory expected to surpass RAG in usage for adaptive AI workflows.
How We Assessed Graph-Based Memory Solutions
We assessed graph-based memory solutions based on five criteria that matter when building AI agents with persistent context:
Entity relationship modelling: can the system store facts as nodes with typed connections? An agent that remembers "Sarah manages the Chicago office" needs to represent Sarah, the office, and the management relationship as separate, queryable elements.
Temporal tracking: does the memory layer timestamp facts and handle updates? Preferences change. A user who switched from tea to coffee six months ago shouldn't trigger outdated recommendations.
Retrieval performance: how quickly can the system traverse relationships to surface relevant context? Graph queries that take seconds break conversational flow.
Integration ease: what does the setup look like? Can you add graph memory with a few API calls, or does it require rewriting your entire agent architecture?
Scalability: how does the system perform as memory grows from hundreds to millions of facts per user?
Best Overall Graph-Based Memory Solution: Mem0
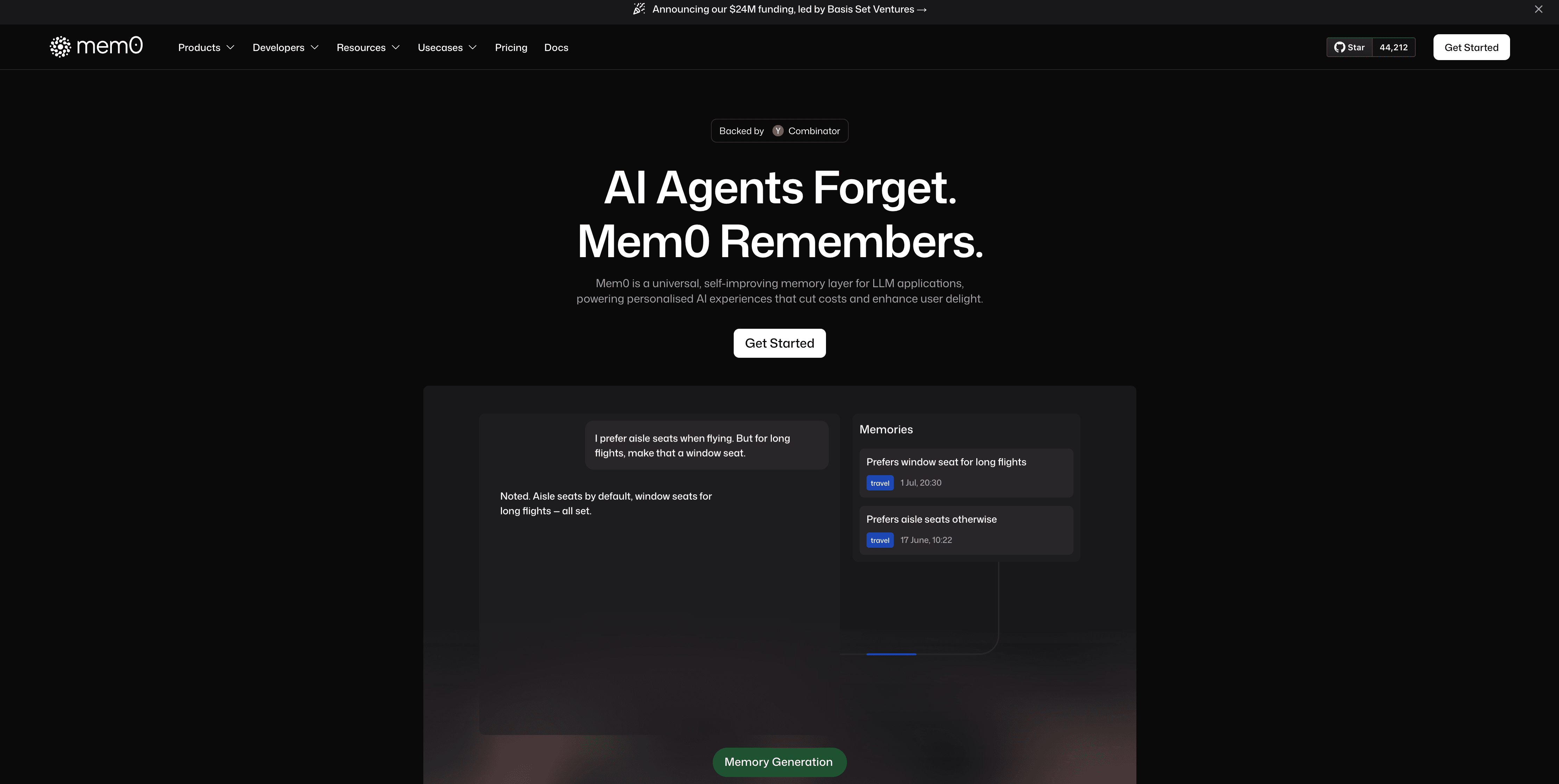
Mem0 combines vector-based semantic search with optional graph memory for entity relationships. The system maintains cross-session context through hierarchical memory at user, session, and agent levels while automatically extracting and organizing facts from conversations. It supports both open-source self-hosting and a managed cloud service with SOC 2 compliance.
Key Features
Hierarchical memory architecture organizing context at user, session, and agent levels for multi-layered personalization
Automatic memory extraction and summarization from conversations without manual orchestration
Hybrid vector and graph retrieval combining semantic search with relationship-aware context when needed
Dual deployment model offering open-source self-hosting or fully managed cloud service with enterprise compliance
Framework-agnostic integration through simple add() and search() APIs that work across LLM providers
Limitations
Graph memory capabilities require additional configuration beyond basic vector retrieval setup
Self-hosted deployments need infrastructure management for vector databases and optional graph engines, though the hybrid architecture mitigates performance degradation issues that occur in pure graph databases as relationship density increases
Memory extraction quality depends on the underlying models used for fact identification and summarization
Advanced features like custom categories and filtering rules add learning curve for complex use cases
Teams wanting complete control over memory editing logic may prefer tool-based approaches over automatic extraction
Bottom Line
Mem0 works well for development teams building AI agents that need persistent memory without framework lock-in or complex infrastructure management. Organizations requiring both quick integration and enterprise-grade compliance benefit most from the managed service, while teams wanting code-level control can use the open-source version. Teams seeking automatic context extraction with hierarchical organization across multiple users and sessions find Mem0's approach more straightforward than tool-driven memory systems that require manual orchestration.
LangMem
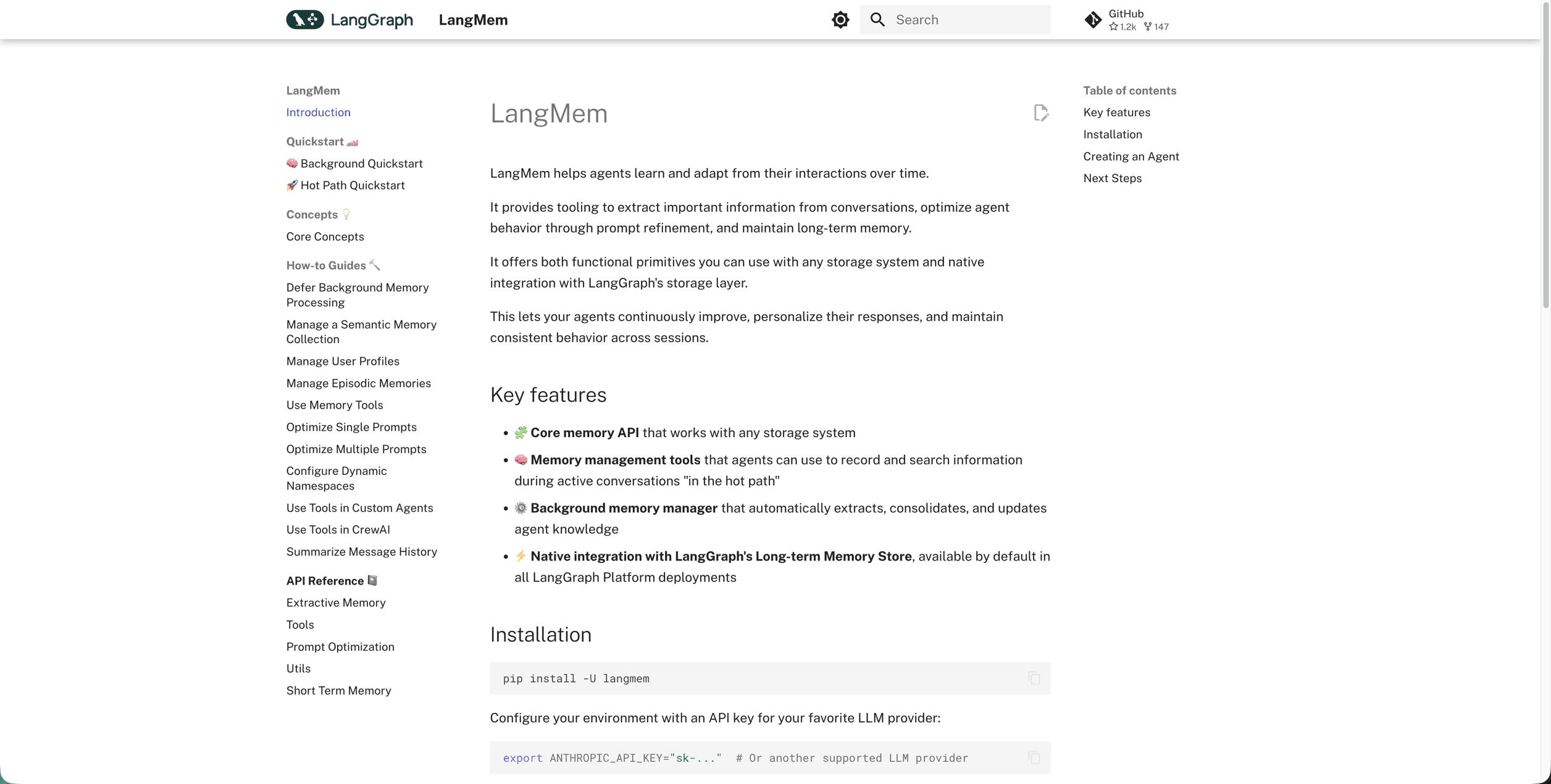
LangMem extracts information from conversations and maintains long-term memory through LangGraph's storage system. The framework provides memory tools that integrate directly with LangGraph workflows, letting agents call memory functions to store and retrieve context. Memory operations happen through explicit tool calls instead of automatic extraction, requiring developers to determine when and how agents access stored information.
Key Features
Memory tools integrate with LangGraph workflows through manage and search APIs that agents call directly
Namespace partitioning organizes memories by user, project, or context for multi-tenant scenarios
Persistent storage uses LangGraph's BaseStore with embedding support for semantic retrieval
Tool-based approach where agents explicitly invoke memory functions during execution
Built-in memory management capabilities for updating, deleting, and organizing stored context
Limitations
Requires LangGraph as the underlying framework, coupling memory infrastructure to a specific orchestration system
Agents must call memory tools manually instead of extracting and retrieving context automatically
Teams handle orchestration complexity themselves, including when to trigger memory operations
No managed service option, requiring self-hosting and infrastructure management
Framework dependency limits flexibility for teams using other agent architectures or wanting to switch orchestration layers
Bottom Line
LangMem works well for teams already building agents with LangGraph who need memory tooling that fits their existing workflow orchestration. Development teams comfortable with LangGraph's architecture and tool-driven patterns benefit most, particularly when they want tight integration between memory operations and their agent's decision-making process. Teams seeking framework-agnostic memory or automatic context extraction without manual tool orchestration should consider alternatives that decouple memory infrastructure from specific agent frameworks.
Letta
Letta is an agent runtime built around self-editing memory where agents manage what stays in-context versus archival storage through dedicated memory management tools. The system provides a complete agent framework with REST API and development environment for building stateful AI services. Agents directly edit their own memory blocks using specialized tools instead of relying on automatic extraction and retrieval.
Key Features
Core memory blocks that agents edit directly using memory-specific tools for explicit control over what gets remembered
Agent runtime with REST API and Agent Development Environment for building stateful services
Memory architecture supporting in-context, archival, and external data sources with clear separation between memory types
White-box memory where developers inspect and modify agent memory state at any point
Tool-driven memory editing where agents decide what information to store, update, or remove during execution
Limitations
Delivers a complete agent runtime instead of a standalone memory layer, requiring adoption of the entire framework
Tool-based memory editing adds complexity for teams that just need persistent context without orchestration overhead
Agents must explicitly manage their own memory through tool calls instead of automatic context extraction
Runtime architecture couples memory operations to Letta's execution model, limiting flexibility for existing agent systems
Teams wanting simple memory integration without rebuilding their agent infrastructure face a lot of migration effort
Bottom Line
Letta works well for teams building sophisticated agent applications from scratch that need runtime orchestration, tool ecosystems, and explicit control over memory editing operations. Development teams creating complex multi-tool agents with specific memory management requirements benefit most from the white-box approach and integrated runtime. Teams seeking straightforward memory persistence for existing agents or wanting retrieval-based context without tool-driven editing should consider lighter-weight alternatives that integrate without runtime dependencies.
Zep
Zep stores memory as a temporal knowledge graph that tracks how facts change over time and integrates structured business data with conversational history. The system combines graph-based memory with vector search to handle complex enterprise scenarios requiring relationship modeling and temporal reasoning. Memory operations support multi-hop queries across entity relationships while maintaining timestamps for fact evolution tracking.
Key Features
Temporal knowledge graph tracking fact evolution and relationship changes across sessions
Integration of structured enterprise data from CRM systems and business events with unstructured conversations
Multi-hop and temporal query support for complex reasoning scenarios requiring relationship traversal
Hybrid vector and graph retrieval combining semantic search with explicit entity relationships
Rich relationship modeling for workflow-heavy enterprise agents that need connected context
Limitations
Temporal graph architecture adds complexity that most straightforward agent use cases do not require
Enterprise data integration features create overhead for teams needing simple persistent memory without business system connections
Graph query performance can degrade with deeply nested relationship traversals at scale
Setup and configuration demand more infrastructure knowledge compared to simpler memory solutions
Temporal tracking and relationship management require ongoing maintenance as data models evolve
Bottom Line
Zep works well for enterprise teams building agents that need to reason about how facts and relationships change over time while integrating multiple business data sources. Organizations with complex workflows requiring temporal audit trails and multi-system data merging benefit most from the graph-based approach. Teams building straightforward conversational agents or those wanting quick memory integration without enterprise workflow complexity should consider alternatives that deliver persistent context without temporal graph overhead.
Supermemory

Supermemory is an open-source personal knowledge management system for storing and retrieving information across different sources. The platform focuses on individual user memory vaults instead of production AI agent infrastructure. It targets consumer personal assistant scenarios where users want to remember notes, documents, and web content in a unified interface.
Key Features
Personal memory vault for notes, documents, and web content
Cross-application information retrieval for individual users
Open-source codebase for consumer personal assistant scenarios
Local-first approach for user-controlled storage
Browser extension and desktop app for capturing information from various sources
Limitations
Designed for individual consumer use instead of production AI agent deployments
Lacks multi-tenancy support required for applications serving multiple users
No managed service option or enterprise-grade infrastructure for scaling
Missing hierarchical memory levels (user, session, agent) needed for complex agent systems
API-first design absent, making programmatic integration into agent workflows difficult
Bottom Line
Supermemory works well for individual users or hobbyists building personal AI assistants that need to remember information from various personal data sources. Developers creating single-user productivity tools or personal knowledge management experiments benefit most from the local-first, privacy-focused approach. Teams building production AI agents serving multiple users or requiring scalable memory infrastructure should consider purpose-built agent memory solutions with multi-tenancy, managed hosting, and developer APIs.
Feature Comparison Table for Graph-Based Memory Solutions
We've assembled a side-by-side comparison of the solutions we assessed. This provides a quick overview of the detailed information provided for each solution, comparing them along the most critical vectors for any developer team considering a graph memory solution for their AI agent memory layer.
Feature | Mem0 | LangMem | Letta | Zep | Supermemory |
|---|---|---|---|---|---|
Graph Memory Support | Yes | Limited | Limited | Yes | No |
Managed Service | Yes | No | Yes | Yes | No |
Framework-Agnostic | Yes | No | Yes | Yes | Yes |
Hierarchical Memory Levels | Yes | No | Yes | No | No |
Automatic Memory Extraction | Yes | No | Yes | Yes | No |
Enterprise Compliance | Yes | No | Yes | Yes | No |
Sub-Second Retrieval | Yes | No | No | Conditional (depends on query complexity) | No |
Why Mem0 is the Best Graph-Based Memory Solution for AI Context
Mem0 offers graph-enhanced memory without requiring complex temporal architectures or runtime dependencies. The optional graph layer adds entity relationships when needed, while vector-based retrieval handles straightforward use cases. The dual deployment model lets teams self-host the open-source version or use the managed service with built-in compliance. Hierarchical memory at user, session, and agent levels creates cross-session persistence that adapts as preferences change.
For teams building AI agents that need relationship-aware context, Mem0 balances capability with simplicity.
Final Thoughts on Graph Memory for AI Agents
The right knowledge graph memory solution depends on your agent's complexity and your team's infrastructure preferences. Graph capabilities matter most when your agent needs to reason about relationships between entities across multiple sessions. For straightforward persistent context, vector retrieval handles the job. When your use case requires relationship awareness, graph memory should integrate without forcing you to rebuild your entire agent architecture.
FAQ
How do I choose between graph-based and vector-only memory for my AI agent?
Graph-based memory works best when your agent needs to track explicit relationships between entities (like user preferences connected to specific products or locations). Vector-only memory handles straightforward similarity search well. If your agent just needs to recall similar past conversations without reasoning about how facts connect, vector memory is simpler and faster to implement.
Which graph memory solution works best for teams without dedicated infrastructure resources?
Mem0 offers the fastest path to production with its managed service that handles graph database infrastructure, compliance, and scaling automatically. LangMem and Supermemory require self-hosting and manual setup, while Letta and Zep provide managed options but come with more complex architectures that need configuration time.
Can graph memory handle millions of facts per user without slowing down retrieval?
Yes, but performance depends on the implementation. Mem0 and Zep both deliver sub-second retrieval at scale through optimized graph traversal and hybrid vector-graph architectures. Systems that rely purely on graph queries without vector indexing typically see slower performance as memory grows beyond thousands of nodes per user.
What's the difference between temporal graphs and standard graph memory?
Temporal graphs track how facts change over time, storing timestamps and relationship evolution (like Zep's approach). Standard graph memory stores current entity relationships without historical tracking. Most AI agents only need current context, making temporal features unnecessary overhead unless you're building enterprise systems that require audit trails or reasoning about how preferences evolved.
Do I need to adopt a specific agent framework to use graph memory?
Not with framework-agnostic solutions like Mem0 or Zep. LangMem requires LangGraph, and Letta comes with its own agent runtime. If you're already using a specific framework or want flexibility to switch orchestration layers later, choose a memory solution that works independently through standard API calls instead of framework-specific integrations.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

