



Every time you send a request to a Large Language Model (LLM), it looks at you for the first time. It has read the entire internet, but it has no idea who you are, what you asked ten seconds ago, or why you are asking it.
For the architects of the modern web, this statelessness was a feature. Developers aligned with Roy Fielding’s REST principles, accepting that servers shouldn't remember client state to ensure scalability. But for the AI agents I build (autonomous entities designed to perform complex, multi-step tasks), this is a major failure. An agent without memory is merely a function.
Memory bridges the "eternal now" of the LLM inference cycle with the continuity required for intelligence. But what exactly is it?
What is AI memory?
AI memory is an AI system's ability to store, recall, and use past information and interactions to provide context, personalize responses, and improve performance over time, moving beyond simple, stateless processing to maintain continuity like a human does. It allows AI to remember user preferences, conversation history, and learned patterns, making interactions more coherent and effective, much like human memory supports learning and reasoning.
How does AI memory mimic the mind?
To understand how to build memory for machines, we must first categorize what we are trying to simulate. Cognitive science offers a taxonomy that maps surprisingly well to software architecture. Human memory functions as a complex system of interconnected storage mechanisms rather than a single bucket.
Sensory memory vs. the context window
In biological systems, sensory memory holds information for a split second. In AI, the closest analogue is the context window, functioning as the immediate scratchpad of the model. Information placed here is instantly accessible, processed with high fidelity, and fully integrated into the "thought process" of the LLM.
However, the context window is finite. While models like Gemini or Claude boast windows of millions of tokens, filling them comes with high latency and financial cost. More importantly, the "Lost in the Middle" phenomenon reveals that models often fail to retrieve information buried in the center of a massive context prompt. The context window is the working RAM rather than the hard drive.
Short-term memory (STM)
Short-term memory in agents typically refers to the conversation history of the current session. It allows the agent to recall that you asked for a Python script three turns ago so it can now iterate on that script. This is transient, ephemeral, and usually discarded when the session ends.
Long-term memory (LTM)
Long-term memory allows for persistent context across sessions, days, and distinct interactions. It enables an agent to learn user preferences ("Ninad prefers TypeScript over JavaScript"), recall project structures ("The utils folder contains the date formatting logic"), and build a cumulative understanding of the world. LTM implies a database, but the structure of that database determines the intelligence of the recall.
What are the architectures of AI agents with memory?
While basic memory is often equated with "storing chat logs in a vector database," 2024 and 2025 have seen the rise of cognitive architectures that mimic human processing in agentic toolchains.
Generative agents and the reflection mechanism
I read a recent research project that proposed a memory architecture that goes beyond storage. It introduced the concept of the Memory Stream, which is a comprehensive list of an agent's experiences.
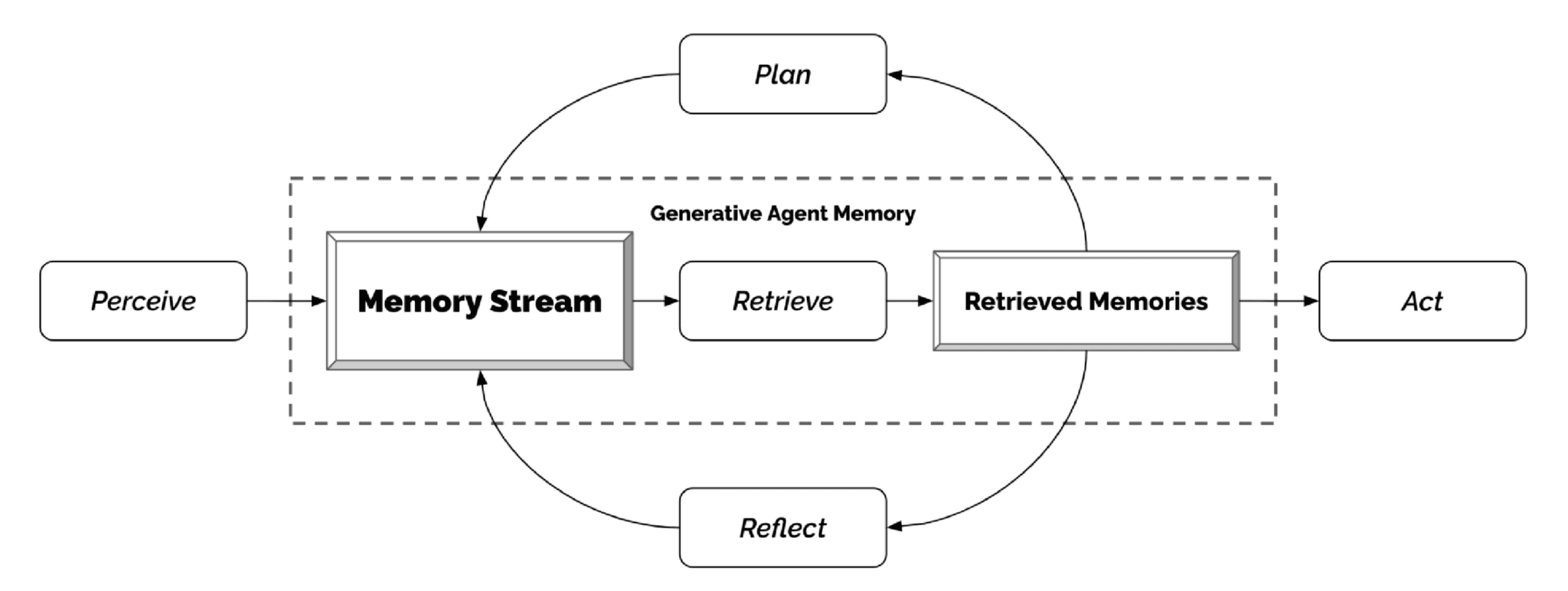
What was interesting to me was the Reflection aspect. Reflections are periodic, high-level abstract thoughts generated by the agent. The agent does not just retrieve raw observations (e.g., "User ate lunch"); it synthesizes them into insights (e.g., "User creates a pattern of eating at 1 PM").
Likability: How important is this memory? (Rated by the LLM).
Recency: How long ago did this happen?
Relevance: Does this matter to the current context?
This architecture allows agents to behave with credible social dynamics, organizing their "thoughts" rather than just regurgitating data.
The operating system analogy for AI memory
Another powerful approach facilitates treating the LLM not just as a text processor, but as an Operating System. This paradigm explicitly divides memory into hierarchies akin to computer architecture:
Main Context (RAM): The immediate prompt window. Expensive and finite.
External Context (Disk): Massive storage in databases. Cheap and infinite.
Crucially, this architecture enables the LLM to manage its own memory via function calls. The model can decide to move critical facts (like a user's birthday) to persistent storage or search historical records when needed. This "self-editing" capability prevents the context window from overflowing with noise while maintaining access to vast amounts of data.
How are AI memory systems built?
Building a memory system requires moving beyond simple list appending. It means constructing a storage and retrieval system that must effectively mimic the associative nature of the human brain.
The vector store: The hippocampus
The most common implementation of agent memory today relies on Vector Databases. When text is ingested, be it a user query, a document, or a log file, it is passed through an embedding model (like OpenAI's text-embedding-3). This model converts the semantic meaning of the text into a high-dimensional vector, a list of floating-point numbers.
These vectors are stored in a database like Pinecone, Weaviate, or Qdrant. When the agent needs to "remember" something, it converts the current query into a vector and performs a similarity search (often using Cosine Similarity) to find the nearest vectors in that high-dimensional space.
This mimics the human hippocampus, which is essential for forming new memories and connecting related concepts. If you search for "apple," a vector store naturally surfaces concepts like "fruit," "red," and "pie," even if the word "apple" is not explicitly present, because they reside close together in the semantic vector space.
GraphRAG: The association cortex
Vector stores have a weakness: they struggle with structured relationships and multi-hop reasoning. Vectors are "fuzzy." They know that "Paris" and "France" are related, but they might not explicitly encode the directional relationship "Paris is the capital of France."
GraphRAG (Graph Retrieval-Augmented Generation) solves this by combining the unstructured strength of vectors with the structured rigidness of Knowledge Graphs. Mem0's Graph Memory, for example, allows for dynamic relationship mapping that evolves as the agent learns more about its environment.
Using graph databases (like Neo4j), developers can store information as nodes and edges: (Entity: Paris) --[RELATION: CAPITAL_OF]--> (Entity: France).
For an agent, this is essential for complex problem-solving. If an agent is managing a supply chain, broad semantic similarity is insufficient. It needs to traverse specific paths: "Supplier A provides Part B, which is used in Product C." Graph-based memory allows the agent to "hop" across these nodes to answer questions that a simple vector similarity search would miss.
Hybrid systems
The state-of-the-art in 2026 is Hybrid Memory. This approach uses:
Vector Search: For unstructured retrieval (finding relevant emails, documents, or loose notes).
Graph Traversal: For structured facts and rigid relationships.
Episodic Storage: For temporal sequences of events.
This combination provides the "intuition" of embeddings with the "precision" of graphs, ensuring the agent is both creative and factually grounded.
Why should AI memory matter to developers?
The "stateless chatbot" market is saturated and the next generation of applications requires context-aware personalization.
Consider a coding assistant. A standard LLM-based tool can write a function if you paste the relevant code. A memory-enabled agent can look at your entire repository history, remember that you refactored the authentication module last week, and suggest a change that aligns with your new security patterns. Rather than just processing your request, it understands the continuity of the work.
Existing frameworks and integrations for building AI memory applications
Developers do not need to build these complex Retrieval-Augmented Generation (RAG) pipelines from scratch. Usually, they lean on orchestration frameworks:
LangChain: Offers various
Memoryclasses (likeConversationBufferMemoryorVectorStoreRetrieverMemory) that wrap the complexity of saving and loading history.LlamaIndex: Focuses heavily on the indexing strategy, allowing for composable indices where a list index can sit on top of a vector store, which sits on top of a graph.
AutoGPT: One of the earliest autonomous agent projects, which demonstrated the necessity of a purely memory-driven loop where the agent writes its thoughts to a file or database to "sleep" on them.
However, these frameworks often treat memory as part of the application logic. The logic is tightly coupled with the control flow of the agent, which limits portability compared to more decoupled approaches aligned with OpenMemory MCP.
Is there a need for a dedicated AI memory layer?
If you’re building an AI agent in 2026, it’s highly likely you’d need an AI memory layer to integrate personalization. That’s the alpha your product would have compared to the competitors.
But, you don’t need to build memory from scratch. There’s already a concept of Memory as a Service (or the Memory Layer) that decouples the memory logic from the agent's reasoning loop. Instead of manually coding "retain this context, summarize that history, store this embedding," you can use a dedicated layer that handles the cognitive overhead.
We built Mem0 for exactly this use case. It acts as an intelligent memory layer that sits between the application and the LLM. It manages the complexities we discussed: vector storage, user personalization, and session handling through a simple API.
The advantage here is specificity and meaningful filtering.
A raw vector store will return the top-K chunks of text, regardless of whether they are repetitive or outdated. A dedicated memory layer like Mem0 can implement "memory management" logic: updating old memories when new conflicting information arrives (e.g., the user moved from "San Francisco" to "New York"), decaying irrelevant memories over time, and prioritizing information based on utility. For enterprise use cases, features like privacy and security compliance become critical advantages over home-rolled solutions.
It integrates with the existing ecosystem. Whether using OpenAI's API, Anthropic's Claude, or frameworks like LangChain, I can plug a memory layer in to instantly upgrade "stateless" calls to "stateful" interactions.
Where can intelligent memory be applied?
The application of these architectures extends far beyond simple chatbots. By enabling agents to retain context, we unlock new possibilities in personalized education, healthcare, and professional services.
Customer support
Support agents often fail because they lack context. Using memory, an agent can instantly recall a user's previous tickets, frustration level, and purchase history. It stops asking "How can I help you?" and starts asking "Is this about the refund request from Tuesday?"
Healthcare
For elderly care or chronic disease management, an AI companion must remember medication schedules, reported symptoms from a week ago, and the names of family members. Hallucinating a dosage or forgetting a severe allergy is not an option. Here, the precision of graph-based memory is vital.
Education
An education agent should not treat a student like a stranger every day. It should remember that the student struggled with Quadratic Equations yesterday and offer a review session today before moving to Calculus. This requires a persistent user profile memory that grows with every interaction.
Sales & CRM
Closing a deal often takes weeks. A memory-enabled sales agent remembers every stakeholder mentioned in passing, every feature request, and every objection raised in previous calls. It turns a fragmented sequence of chats into a cohesive, ongoing relationship.
E-commerce
Shopping is personal. Instead of generic recommendations, a memory-aware agent recalls that you prefer sustainable brands and hate wool. It powers personalized shopping at scale, curating a storefront that feels uniquely yours.
What does the future of recall look like?
We are moving away from the era of "Prompt Engineering," where the user is responsible for stuffing the context window with the necessary background information, toward "Context Engineering," where the system automatically retrieves the perfect set of memories for the task at hand.
The goal is an agent that functions as a capable colleague. It knows your shorthand. It anticipates your needs based on past interactions. It does not need to be told the same thing twice. This level of seamless interaction is only possible when memory is treated not as a database problem, but as a core component of the AI's cognitive architecture.
To build agents that truly serve us, we must give them the capacity to remember.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

