

Recently, a new paper, “Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs” (ICLR 2026), introduced BEAM, a benchmark designed to evaluate long-term memory in language models.
For the past year, context length has become the dominant metric for LLM progress. 128K → 1M → 10M tokens.
But this paper asks a deeper question:
Do models actually remember anything over long conversations and evolving situations?
Because reading more ≠ remembering better.
As context windows expand, memory benchmarks improve. It’s become the LLM race. But benchmarks need to catch up to measure real memory systems.
The Problem With Existing Benchmarks
Most long-context benchmarks look strong on paper, but they break under closer inspection.
Many of them construct “long” conversations by stitching together sessions from different users. This creates abrupt topic shifts and weak narrative continuity, which ironically makes the task easier. Models don’t need to maintain a consistent internal state, they can rely on local retrieval instead of true long-term memory.
At the same time, these benchmarks tend to operate in narrow domains and emphasize recall-heavy tasks. Models are rewarded for finding information, not for tracking how that information evolves, updates, or contradicts earlier context.
2 years ago, this was not a problem.
Recent LLM improvements , especially larger context windows (100k → 1M tokens), are increasing memory benchmark results.
When models can fit more information directly into the context window, systems that rely on memory or retrieval appear to perform better.
But this improvement often comes from the model’s increased capacity and reasoning ability, not from better memory architecture. In many benchmarks, the entire task can now fit inside the context window. As a result, retrieval and memory systems are no longer being meaningfully tested leading to artificially higher scores.
How BEAM Compares
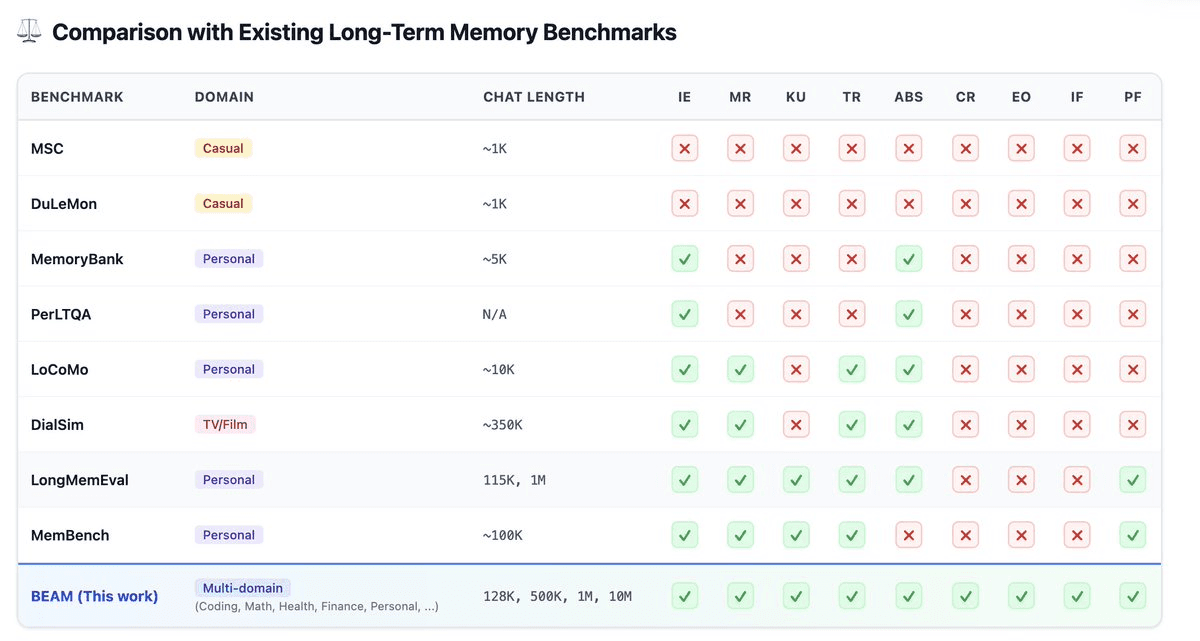
Memory Benchmark Comparison (Source: Igor Kudryk on X)
Earlier benchmarks like MSC and DuLeMon barely test any meaningful memory capabilities. Even stronger ones like LongMemEval and MemBench cover only a subset, mostly information extraction, retrieval, or limited reasoning.
But they consistently miss harder behaviors like:
Contradiction resolution
Event ordering
Preference tracking over time
Instruction persistence across long contexts
BEAM is the benchmark that systematically covers all of these dimensions at once, while also scaling to million-token conversations across multiple domains.
What is BEAM?
BEAM is a benchmark designed to test long-term memory in realistic conversations.
Instead of sampling data, it constructs conversations from scratch with:
Coherent narratives
Persistent user identity
Evolving facts, preferences, and events
It includes:
100 conversations
Up to 10M tokens
2,000 probing questions
And most importantly:
Every conversation forces the model to track state over time.
How BEAM Generates Conversations
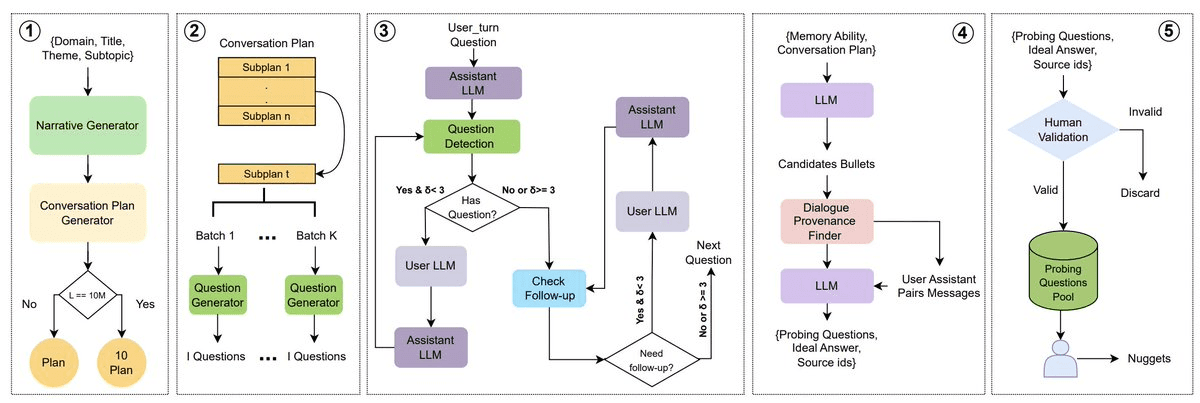
Overview of BEAM generation process
This is where BEAM stands out. Instead of sampling conversations, it builds them through a structured pipeline:
High-level plan → narrative, user profile, timeline
Subplans → stages with evolving state
Dialogue generation → multi-turn interactions
Then it injects realism:
Follow-ups and clarifications
Contradictions
Information updates
Under the hood, each subplan is broken into bullet points representing key events. These are used to generate user turns (e.g., via LLaMA-70B), ensuring the conversation follows a coherent narrative instead of random prompts.The interaction is then simulated iteratively.
The assistant responds, a module checks if a follow-up question is implied, and if so, the user model replies. This loop repeats for a few turns, mimicking natural back-and-forth dialogue.
A separate follow-up module adds clarifications when needed, creating conversations with dependencies across turns, evolving facts, and shifting context.
Most benchmarks test memory in isolation. BEAM forces models to use memory under continuous change.
What BEAM Actually Tests
BEAM doesn’t treat memory as one thing. It evaluates 10 different capabilities:
Tracking facts and entities
Updating information over time
Resolving contradictions
Understanding temporal order
Following instructions vs preferences
Multi-hop reasoning across turns
Summarizing long histories
This is much closer to real-world usage than simple recall.
The Experiment
To evaluate BEAM, the paper compares three setups:
Long-context LLMs → given the full conversation history
RAG baseline → retrieves relevant past turns
LIGHT (proposed) → structured memory system
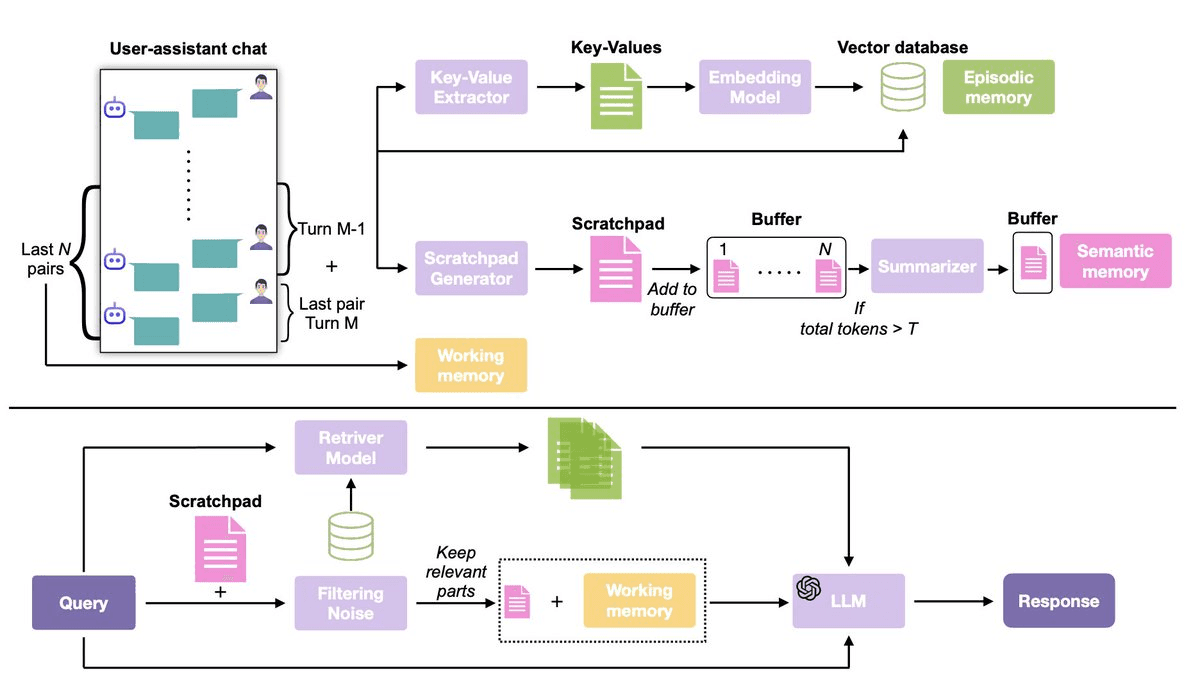
Overview of the LIGHT framework
They test across both proprietary and open models, including GPT-4.1-nano, Gemini-2.0-Flash, Qwen2.5-32B, and Llama-4-Maverick.
For RAG, each user–assistant turn is stored as a document in a vector database, and the top relevant chunks are retrieved at inference. For extremely long contexts (e.g., 10M tokens), since models can’t process the full history, they are evaluated on the largest segment that fits within their context window.
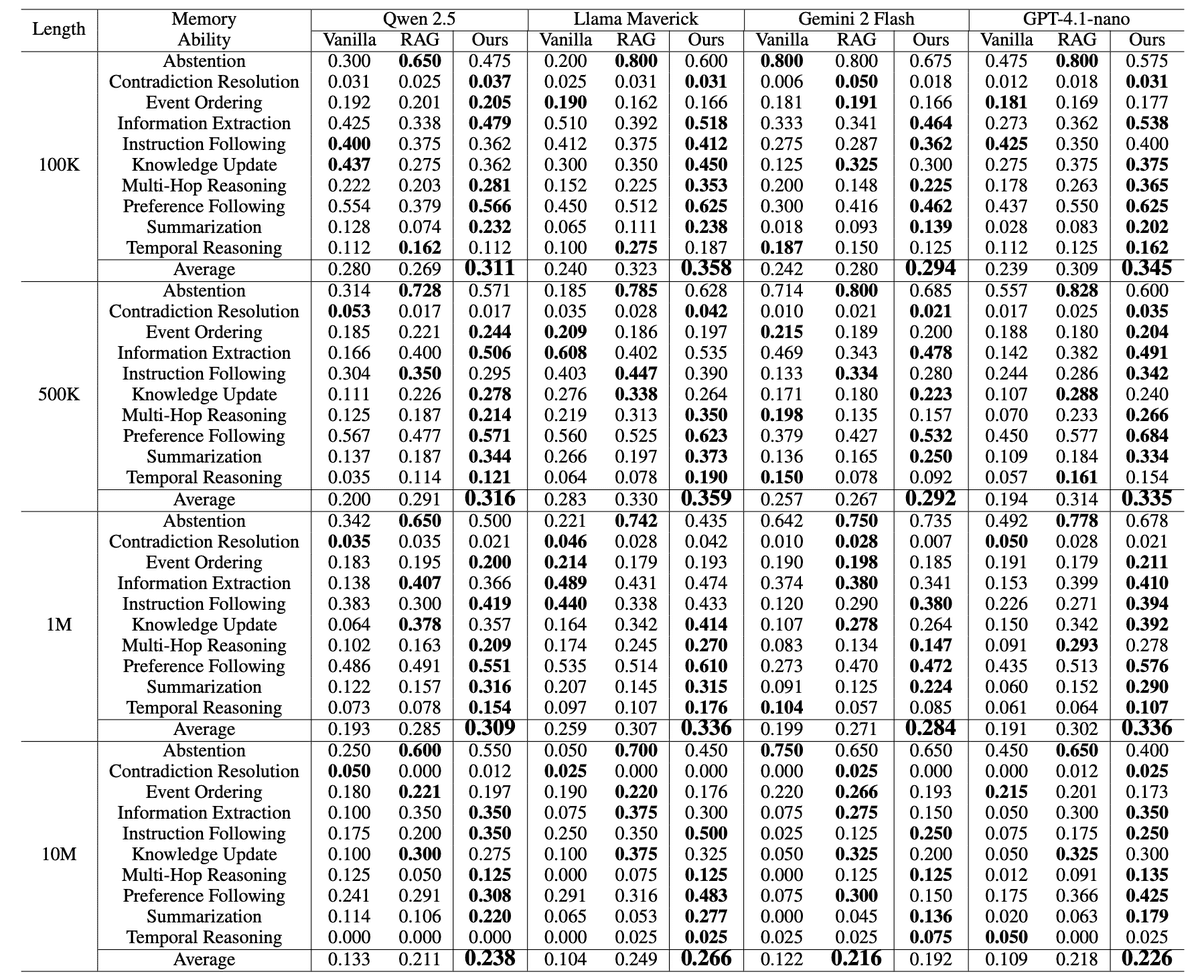
BEAM performance comparison of long-context LLMs vs RAG vs LIGHT
The figure above shows performance comparison of long-context LLMs vs RAG vs LIGHT across BEAM, evaluated on 10 memory abilities (e.g., summarization, multi-hop reasoning, preference following) over conversations ranging from 100K to 10M tokens. Models include Qwen2.5-32B, Llama-4-Maverick, Gemini-2.0-Flash, and GPT-4.1-nano.
Across all conversation lengths, from 100K to 10M tokens, BEAM consistently shows that structured memory systems outperform both standard long context LLMs and RAG baselines.
At shorter contexts, the gains are already significant, with improvements of over 40-50% on models like GPT-4.1-nano and Llama variants. But the real story appears as context grows.
At 1M tokens, improvements climb as high as ~75%, and at 10M tokens, where most models cannot even process full context, gains exceed 100% in some cases.
More importantly, these improvements are not uniform. The biggest gains appear in tasks that actually require memory:
summarization
multi-hop reasoning
and preference following.
In contrast, all models, including improved ones, still struggle with contradiction resolution, suggesting that maintaining globally consistent state remains an unsolved problem.
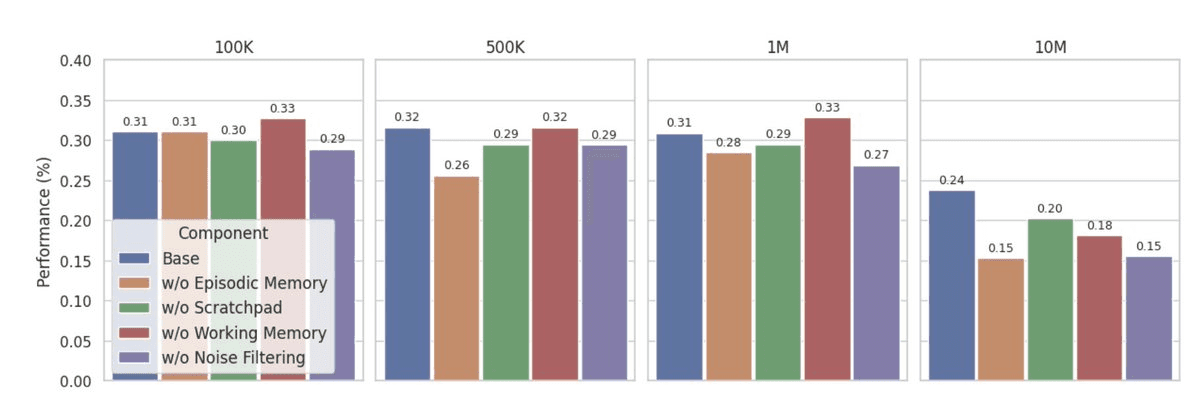
Ablation study illustrating the contribution of each component in LIGHT (retrieval, scratchpad, working memory, and noise filtering) across different conversation lengths.
Results
Even with:
1M token context windows
Retrieval augmentation
Models still:
Lose track of updates
Fail at contradictions
Forget user preferences
Struggle with long-range reasoning
Performance drops as conversations grow longer.
How BEAM Evaluates Memory
BEAM uses a more fine-grained evaluation approach than typical benchmarks.
Instead of marking answers as simply correct or incorrect, it decomposes each reference answer into smaller units called “nuggets”, atomic pieces of information. Each nugget is then evaluated independently:
1.0 → fully correct
0.5 → partially correct (minor inaccuracies or incomplete)
0.0 → missing
This allows BEAM to capture partial memory failures, which are common in long-context settings where models may recall some details but miss others.
Importantly, the evaluation is flexible. The judge accepts paraphrases, synonyms, and different writing styles, focusing on whether the underlying information is present rather than exact wording.
A Subtle Limitation (Personal Take)
That said, this setup introduces some ambiguity.
Because answers are decomposed into predefined nuggets, models may be penalized for responses that are valid but structured differently from the expected breakdown. This is especially noticeable in tasks like summarization, where there isn’t a single “correct” way to express the content.
There’s also a reproducibility concern. The paper does not clearly specify the judge model or fully standardize the evaluation prompts, which makes it unclear whether results are directly comparable across implementations.
In other words, the evaluation is more granular, but not necessarily more objective.
Conclusion
BEAM highlights a shift in how we should think about progress in LLMs.
For the past year, the focus has been on scaling context windows, making models capable of reading more. But BEAM shows that this is not enough. Even with massive context and retrieval, models still struggle to maintain consistent, evolving state over time.
The real bottleneck isn’t how much information a model can process.
It’s how that information is stored, updated, and used.
Long context solves capacity. Memory systems solve understanding.
BEAM doesn’t just introduce a new benchmark, it exposes a deeper limitation in current LLMs and points toward what comes next: structured memory, not just larger windows.
Reference
BEAM Paper: Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs
Content based on personal prompts. Images generated with Claude AI.
In Context #2
This blog is part of In Context, a mem0 blog series covering AI Agent memory and context engineering.
mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here : app.mem0.ai
or self-host mem0 from our open source github repository
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer











