



Most agentic workflow frameworks solve the orchestration problem well and the memory problem not at all. State flows between nodes within a run, tools chain together cleanly, but when the run ends, everything resets, and the next run starts with no knowledge of what the last one learned.
What Agentic Workflows Are
An agentic workflow is a multi-step process in which an LLM drives execution across a sequence of tool calls, decision branches, and intermediate outputs. Unlike a single prompt-response exchange, a workflow structures the agent's behavior into discrete steps: gather information, analyze it, draft a result, verify the result, and deliver it.
Frameworks like LangGraph represent these workflows as graphs where nodes are processing steps and edges define control flow. A node receives the current state object, performs its work (calling tools, invoking models, writing intermediate results), and returns an updated state. Edges route execution to the next node based on the output. The graph can branch, loop, and terminate conditionally.
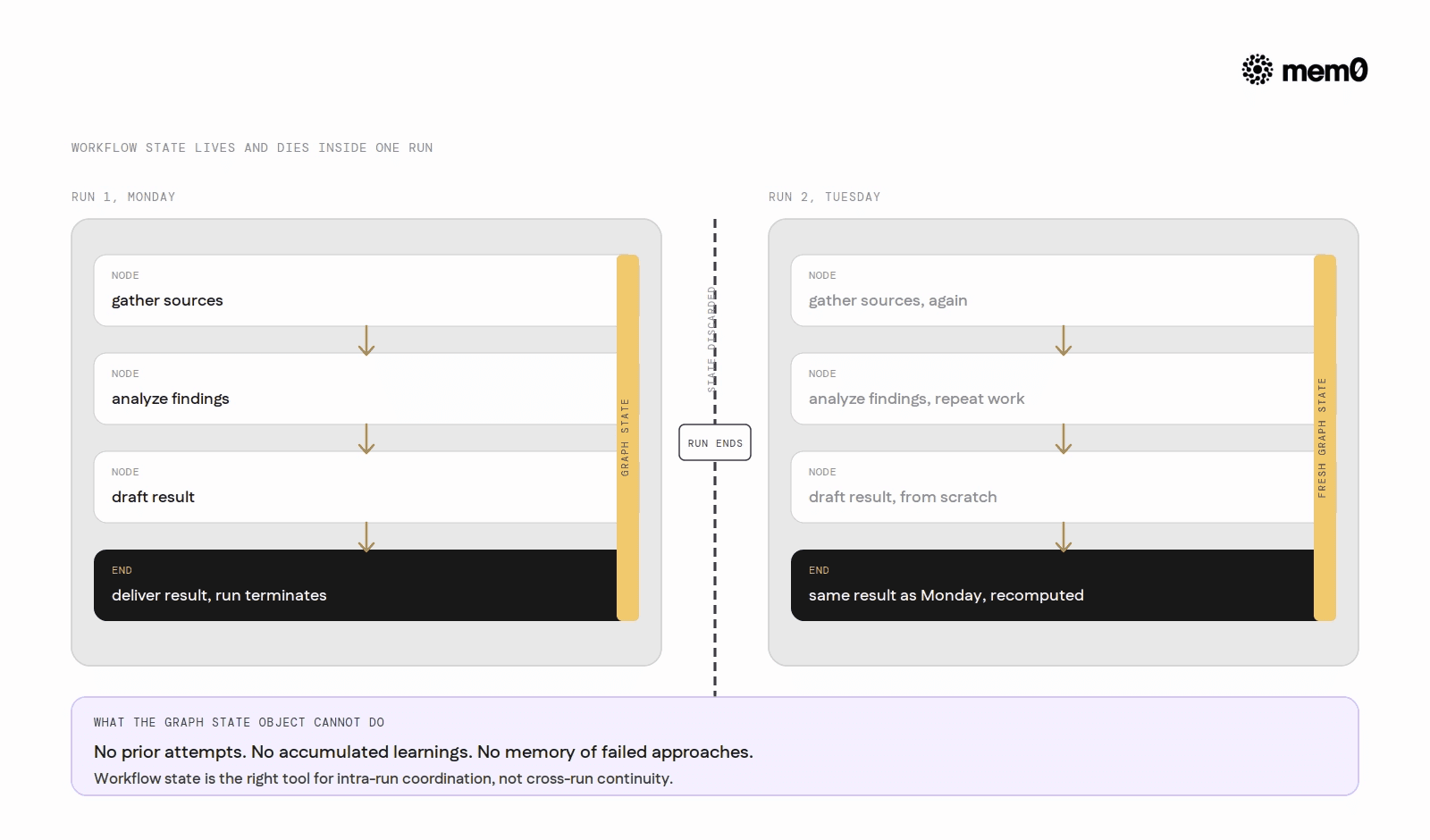
This model handles complex tasks elegantly within a single run. The difficulty is that run boundaries are hard boundaries: the graph's state object exists only for the duration of one execution. When the run ends, so does the state.
The Three State Problems in Agentic Workflows
Three distinct problems emerge from the absence of cross-run persistence, each with different costs.
No cross-session continuity. A research agent that gathers sources, analyzes them, and drafts a report across an afternoon of work cannot resume where it left off the next morning. The user must re-explain the task, re-specify constraints, and accept that any intermediate progress is gone. For long-horizon tasks, this is a fundamental capability gap, not just an inconvenience.
No personalization. A coding agent that does not know the user prefers type-annotated Python, targets Python 3.11, and works in a microservices architecture will ask about those preferences in every new run or produce generic output that requires manual adjustment. The agent re-learns the same facts repeatedly with no mechanism to retain them.
No learning from past runs. An agent that tried three approaches to a problem in a prior run, found two of them failed, and settled on a working solution has no way to encode that knowledge for future runs. The next run may repeat the same failed approaches before finding the same solution. At scale, across a large user base, this represents an enormous amount of redundant computation and degraded user experience.
Workflow State vs Persistent Memory
Workflow state is the structured data object that flows through the graph during a run. In LangGraph, it is a typed dictionary or dataclass that nodes read from and write to. It exists in memory during execution and is discarded when the run terminates (unless a checkpointer is configured for pause-and-resume within a single run).
Workflow state is the right tool for intra-run coordination: passing tool outputs from one node to the next, accumulating intermediate results, tracking which branches have been taken. It is scoped to a run and not intended to persist across runs.
Persistent memory is an external store that survives run boundaries. It is written to and read from by nodes during execution but lives outside the graph's state object. When the next run starts, the graph can query persistent memory to recover relevant context from prior runs.
The two are complementary, not competing. Workflow state manages the mechanics of execution within a run. Persistent memory manages continuity across runs. A well-architected agentic system needs both.
Memory at Different Workflow Layers
Persistent memory in agentic workflows is not a single category. Three distinct memory layers serve different purposes, and conflating them leads to poorly scoped retrieval and noisy context injection.
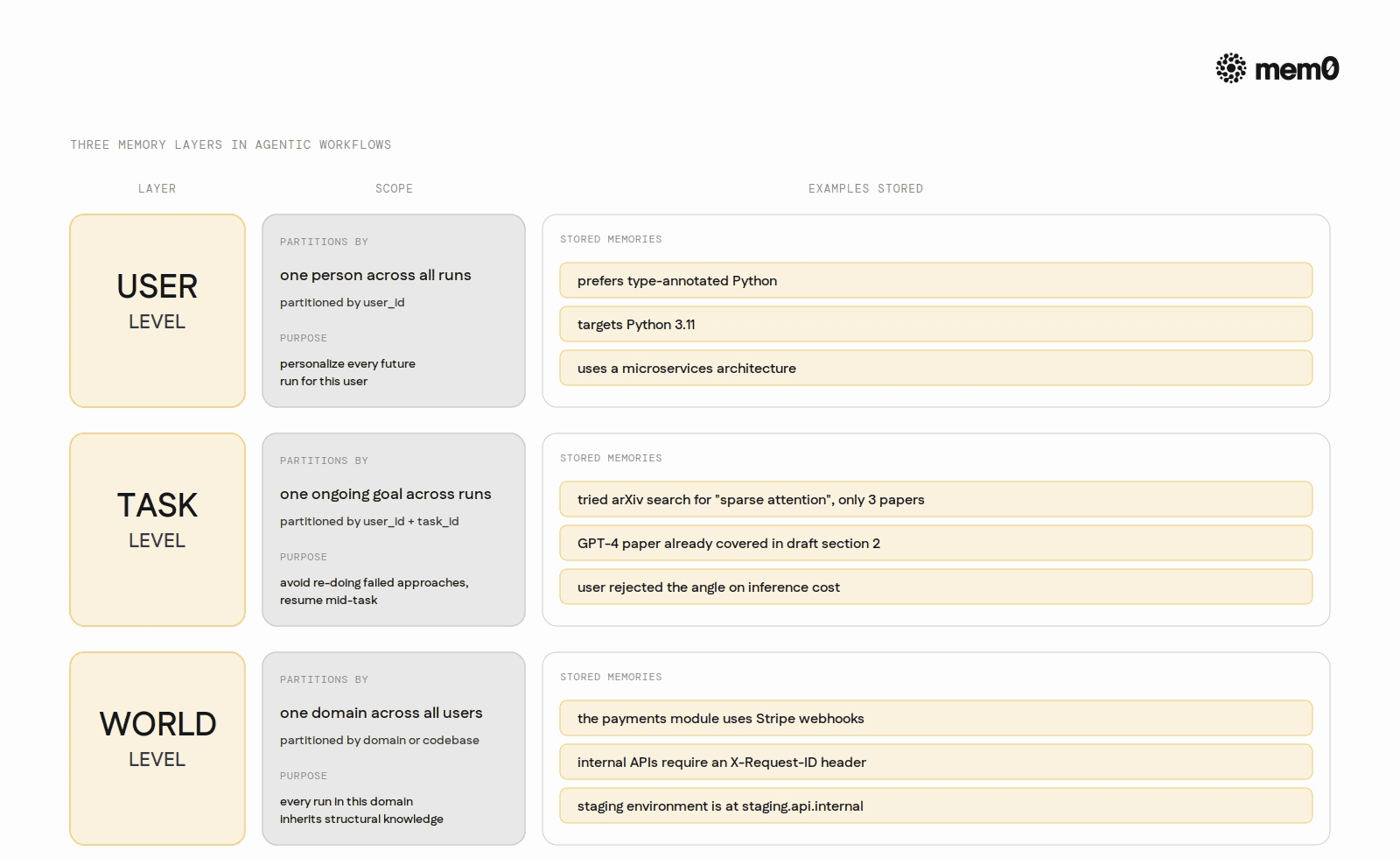
User-level memory captures durable facts about the person driving the workflow: their preferences, their domain, their constraints, their past decisions about project structure or tooling. This memory accumulates across all runs for a given user and is relevant to personalize every future run. Example: a developer who runs a code-review workflow repeatedly. After the first few runs, user-level memory holds "prefers type-annotated Python," "targets Python 3.11," and "uses a microservices architecture." Every subsequent run uses those facts without asking.
Task-level memory captures what was tried, what succeeded, what failed, and what constraints were discovered during work on a specific goal or project. This memory is narrower than user memory and scoped to a particular ongoing task. It helps an agent avoid repeating failed approaches and build on prior partial progress. Example: a research agent investigating a topic across multiple sessions. Task-level memory holds "tried searching arXiv for 'sparse attention': only three relevant papers found," "GPT-4 paper is already covered in draft section 2," and "user rejected the angle on inference cost." The next run picks up from that point instead of repeating the same dead ends.
World-level memory captures domain knowledge extracted from past workflow outputs: facts about a codebase, a dataset, an organization's systems, or a domain's conventions. This memory accumulates across all runs in a given domain and makes every subsequent run smarter, independent of who is running it. Example: a documentation agent that has processed a codebase repeatedly. World-level memory holds "the payments module uses Stripe webhooks," "all internal APIs require an X-Request-ID header," and "the staging environment is at staging.api.internal." New runs across the same codebase start with that structural knowledge already loaded.
The Retrieve-Then-Capture Pattern
The following pattern shows a LangGraph research agent with two memory-aware nodes. A retrieve node runs before the work node, loading relevant memories from prior runs into graph state before the model call.
A capture node runs after the work node, writing what was learned to persistent storage once the findings are confirmed. The graph's state object carries intra-run data between nodes; Mem0 carries cross-run data that survives when the run ends.
The two concerns are cleanly separated: graph state handles the mechanics of execution within a run, and the external memory store handles continuity across runs.
How Persistent Memory Changes What Workflows Can Do
The capabilities available to a memory-backed agentic workflow are qualitatively different from those available to a stateless one.
A stateless workflow can complete a task given the inputs provided at invocation time. A memory-backed workflow can complete a task better than it could the first time, because it has access to prior attempts, prior learning, and accumulated knowledge of the user's preferences and constraints.
A stateless workflow treats each run as independent. A memory-backed workflow treats each run as a step in a longer relationship with the user and with the problem domain. Failed approaches from past runs are not repeated. Successful patterns are reinforced. User preferences do not need to be re-specified.
For agents intended to handle ongoing, evolving tasks such as code generation for a specific codebase, research over a long project, or customer support for a specific account, persistent memory is the difference between a tool that is useful once and a tool that improves with use.
When to Read vs Write Memory in a Workflow
The timing of memory operations in a workflow matters for both correctness and performance.
Read at node start. Memory retrieval should happen before the node's primary work. The retrieved context shapes the node's inputs and prompts, so it must be available before the model call or tool invocation. Reading at node start also allows the workflow to branch differently based on what memory reveals, such as skipping an approach that is already recorded as having failed.
Write at node completion or workflow end. Memory writes should happen after the node's work is complete and its outputs are confirmed to be valid. Writing before the work completes risks storing partial or incorrect information. For multi-node workflows, a dedicated capture node at the end of the graph is cleaner than distributing write calls across every node.
For long workflows with many nodes, a middle ground is practical: write task-level progress notes at major milestones within the run, so that if the run fails partway through, the next run can recover from the milestone rather than starting over.
Comparison: Stateless Workflow vs Memory-Backed Workflow
Capability | Stateless Workflow | Memory-Backed Workflow |
|---|---|---|
Access to prior run outputs | No | Yes |
User preference personalization | No | Yes |
Avoidance of prior failed approaches | No | Yes |
Cross-session task continuity | No | Yes |
Knowledge accumulation over time | No | Yes |
Consistent output quality first vs tenth run | Same | Improves |
Infrastructure required beyond framework | None | Mem0 API or self-hosted |
State management complexity | Graph state only | Graph state + external memory |
Multi-user isolation | Manual | Enforced by user_id |
Mem0 with LangGraph
LangGraph handles the mechanics of execution within a workflow run. Mem0 handles everything that needs to survive when that run ends: what the user has told the agent before, which approaches have been tried, what constraints were discovered mid-task.
The integration slots directly into a LangGraph node. Before the model call, the node queries Mem0 for relevant memories and injects them as context. After the model responds, the exchange is written back to Mem0. Graph state carries the within-run data; Mem0 carries the cross-run data. The two never need to be aware of each other.
Every time this workflow runs for the same user, it starts with a richer context than the run before. Failed approaches from prior runs are not repeated. User preferences accumulate without any extra instrumentation. The LangGraph graph itself is unchanged: Mem0 is the layer outside it.
Final Notes
Agentic workflows without persistent memory are single-use tools; adding Mem0 at node boundaries turns them into systems that accumulate knowledge, personalize to users, and improve with every run.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
If you are a human- Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

