



The distinction comes from Endel Tulving's 1972 paper "Episodic and Semantic Memory," which split human declarative memory into two systems with different jobs.
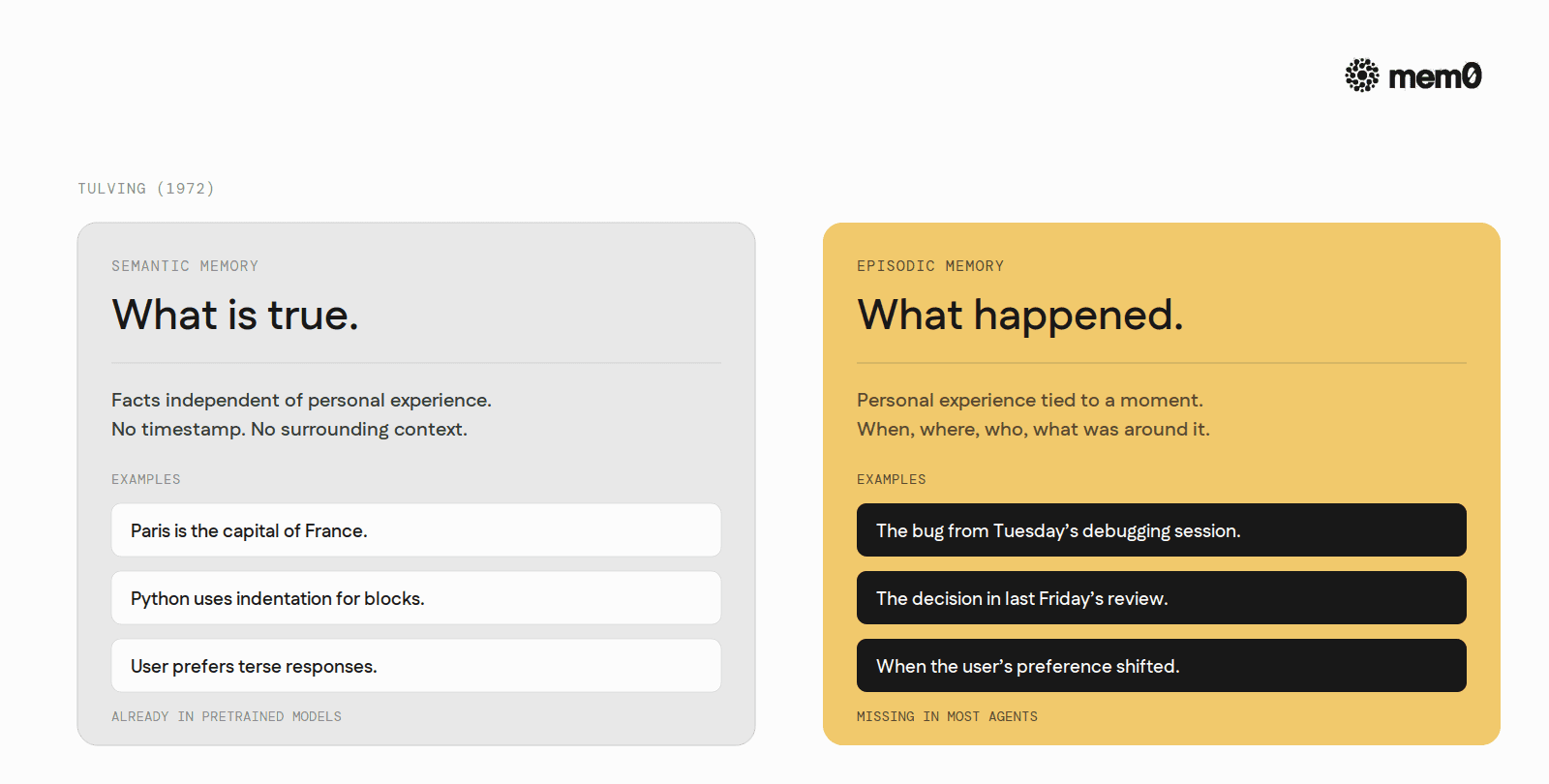
Semantic memory is the store of facts independent of personal experience. Paris is the capital of France. Mitochondria are the powerhouses of the cell. Python uses indentation for blocks. The fact does not carry a timestamp or a context. The knower remembers the fact without having to remember when or where they learned it.
Episodic memory is the store of personal experience tied to a specific time, place, and context. The bug from Tuesday's debugging session. The decision the team made in last Friday's review. The exact phrasing the user used when they pushed back on a feature. Each entry carries metadata: when it happened, what came before it, who was involved, what the surrounding context was.
Tulving's later work added a third property to episodic memory that semantic memory does not share. Autonoetic awareness. The sense that the rememberer is mentally traveling back to the original moment, rather than retrieving a free-floating fact. For human cognition this matters because it changes how memory feels. For AI agents it matters because it changes what data has to be stored alongside the fact for the recall to be useful.
The shorthand worth carrying through this post: semantic memory is "what is true." Episodic memory is "what happened to me, and when, and what was around it."
Why agents need episodic memory specifically
A language model already has plenty of semantic memory baked in. The training data taught it the capital of France, the syntax of Python, the rough shape of every popular framework. What the model does not have, and cannot acquire through pretraining, is episodic memory of the specific user it is currently helping.
The agent cannot reference its own past decisions. A coding agent that decided last Tuesday to use SQLAlchemy over Tortoise ORM will, this Tuesday, ask the user which ORM they prefer. Not because it forgot the fact (a semantic question), but because it has no record of the moment when the decision was made (an episodic question).
The agent cannot reconstruct cause and effect across sessions. The user fixed a bug last week by adding a connection-pool config. This week the same symptoms recur. Without episodic memory, the agent treats the new occurrence as novel and starts the diagnostic loop from scratch. With episodic memory, the agent retrieves the prior incident and starts from "we have seen this before, here is what worked."
The agent cannot personalize at the level of preference change. A user who liked verbose explanations in January and asked for terser ones in March needs the agent to track when the preference shifted. A semantic memory of "user prefers terse" overwrites the prior fact and loses the temporal information that the preference is recent. An episodic memory keeps both moments and lets the agent reason about which one is currently in force.
The pattern across all three: the recall the agent needs is not just what but when, where, and in what context. That is exactly the cargo episodic memory carries that semantic memory drops.
How agents implement episodic memory today

Raw conversation logs
The most common path. Every turn gets logged to a file or database, timestamped, keyed by session ID. When the agent needs episodic recall, it greps or full-text-searches the log and folds the matching turns back into the prompt.
This is what Hermes Agent's session_search tool does, what Claude Code's transcript history enables, what most production LangChain stacks rely on. The mechanism is simple and the data is honest: every turn is exactly what was said, exactly when. The cost is retrieval. Searching raw logs returns long passages that include the relevant moment plus a lot of surrounding noise. The agent has to summarize the result on the fly, every time, with whatever fidelity the summary model can manage.
Vector stores over message chunks
A step up. Instead of full-text search over raw logs, every turn (or every chunk of turns) gets embedded and stored in a vector index. Episodic recall becomes semantic search over message embeddings. The agent asks "what did we decide about the auth flow?" and gets back the most embedding-similar chunks across all sessions.
This works better than raw search for natural-language queries but inherits a different problem. Message embeddings encode what was said, not when or in what context. A vector index can return the relevant turn but cannot reliably surface the surrounding episodic detail (which session, what came before, what the user did with the answer). Some implementations attach metadata fields to the vectors and filter on them. Most do not, because the metadata model is left to the application.
Knowledge graph snapshots
A handful of agent stacks (Microsoft's Semantic Kernel memory, some LangGraph patterns, Mem0's own graph option) build a knowledge graph keyed by entities mentioned in conversations. The graph is updated each turn. Episodic recall becomes a traversal: find the node for "auth flow," walk to "decisions," sort by timestamp.
The graph approach captures more episodic structure than the vector approach but costs more to maintain. Every turn requires entity extraction, edge inference, and graph mutation. The schema is also opinionated. The graph that fits a customer-support use case looks nothing like the graph that fits a coding agent. Most teams underestimate the schema cost and end up with a graph that grows lopsidedly toward whatever the early conversations talked about.
These three patterns are the operational state of the art. Each captures part of episodic memory. None of them captures all of it cleanly without significant application-layer plumbing.
A walk through episodic memory in a real agent step
Consider a customer-support agent handling its third interaction with the same user.
In session one (three weeks ago) the user reported that exporting reports as PDF failed when the report was longer than 50 pages. The agent escalated. Engineering pushed a fix. The session was closed.
In session two (two days ago) the user thanked the agent and mentioned they would use a different tool until the fix shipped.
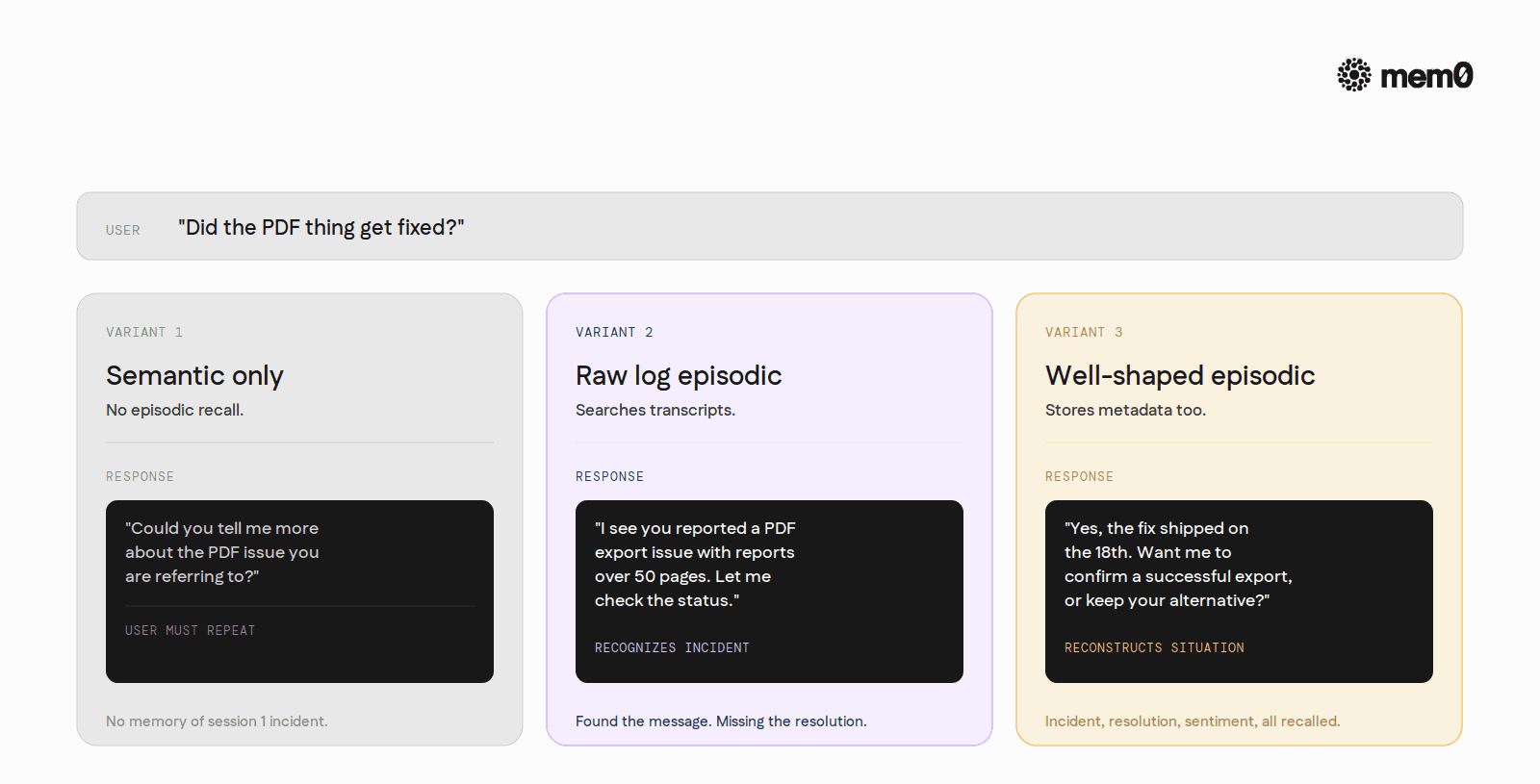
Today, session three, the user opens with: "Did the PDF thing get fixed?"
A semantic-memory-only agent has no idea what "the PDF thing" refers to. It has to ask the user to elaborate, which makes the user repeat themselves. The transcript ends in friction.
A raw-log episodic agent searches the user's prior sessions for "PDF," finds the session-one exchange, summarizes it back: "I see you reported a PDF export issue with reports over 50 pages. Let me check the status." The user's experience improves immediately.
A well-shaped episodic memory does more. It surfaces three things at once: the original incident (what broke), the resolution path (what engineering did), and the user's stated reaction (their workaround). The agent can now answer: "Yes, the fix shipped on the 18th. Would you like me to confirm a successful export now, or do you want to keep using your alternative tool?" The episodic recall is not just retrieving the fact. It is reconstructing the user's situation around that fact.
The difference between the second and third versions is metadata. The third version stored the original turn alongside the timestamp, the resolution status, and the user's expressed sentiment. The second only stored the message text. That metadata is what episodic memory is, in practice.
What episodic memory has to store to actually work
A useful episodic memory entry has, at minimum, four fields beyond the message text itself.
A timestamp. Not just session-relative ordering. Absolute time, so the agent can reason about how old the memory is and whether it is still in force.
A scope. Whose memory is this, and within which agent/run? The same user can have separate episodic streams for separate agents. A user's support-agent episodic stream and coding-agent episodic stream should not bleed into each other.
A surrounding context window. The turns immediately before and after. Episodic recall without surrounding context is just a quote with no source. The agent cannot judge whether the recalled moment was a question, a decision, an aside, or a misunderstanding without the frame around it.
A type tag. Was this an event the user reported, a decision the agent made, a preference the user expressed, a correction the user offered? The same English sentence ("we should use Postgres") means different things at different timestamps depending on what kind of moment it was. Tagging the type lets the agent reason about it later.
Most production agents store one or two of these. Few store all four. The agents that feel "they remember me" are the ones that store all four and surface the right combination at retrieval time.
The limits of current episodic memory designs
Three limits show up across the three implementation patterns.
Storage volume. Every turn is a candidate episodic memory. A heavy user generates thousands of turns a year. Storing every turn with full surrounding context blows up the index. Storing only "important" turns requires a model deciding what is important, and that model is fallible. Most teams ship with one of two failure modes: storing everything and paying for a bloated, slow retrieval, or storing too little and missing exactly the moment the user wants recalled.
Retrieval is not just nearest neighbor. Episodic recall often wants the most recent relevant memory, not the most semantically similar. The user asking "what did we decide about auth?" usually wants last Tuesday's decision, not a structurally similar decision from six months ago. Most vector-store retrieval does not weight recency by default. Adding recency requires a hybrid scoring function the application has to build.
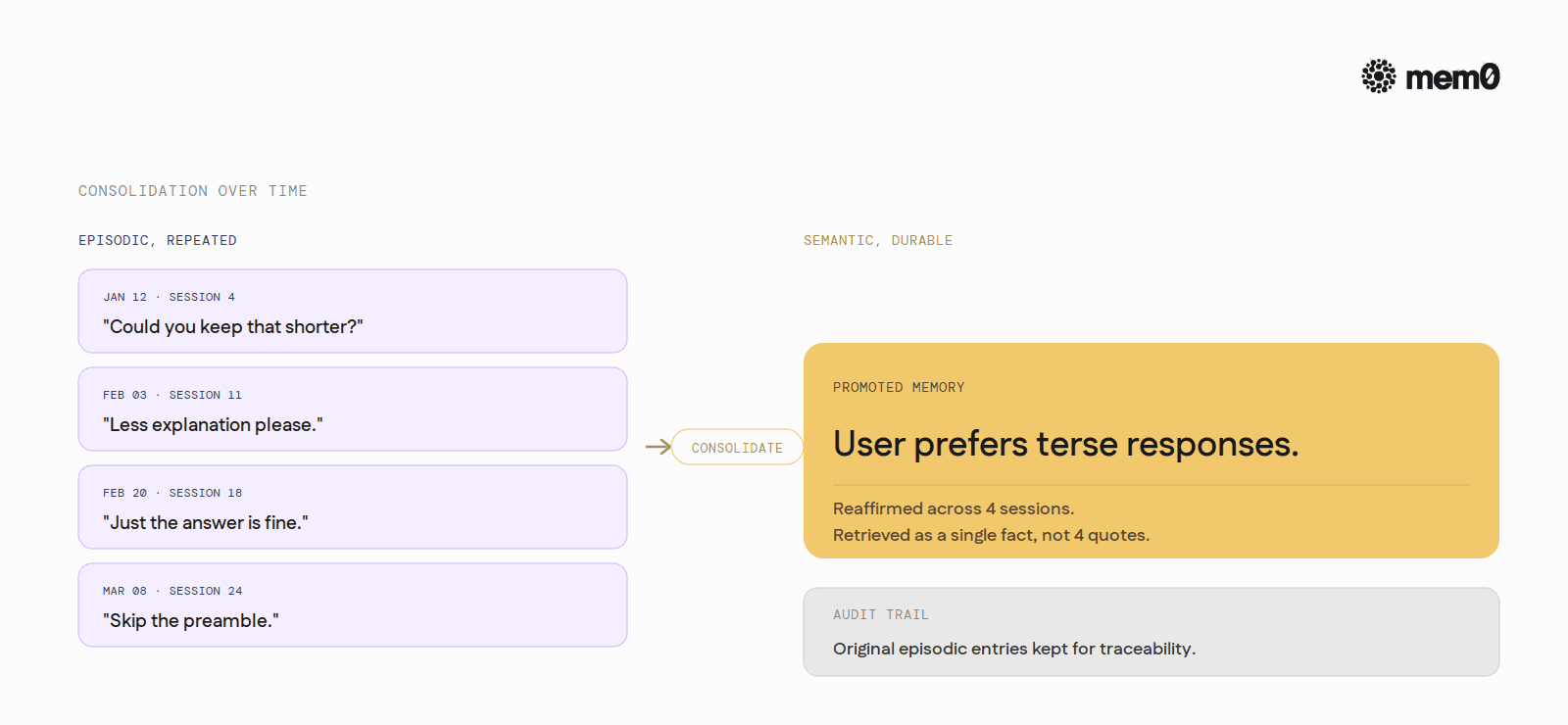
Episodic memory and semantic memory have to coexist cleanly. A user's preference ("I like terse responses") starts as an episodic memory of when they said it. Over time, if reaffirmed across sessions, it should graduate into a stable semantic memory ("user prefers terse"). The graduation is a design step most agents skip, leaving the same fact stored as twenty episodic entries that all retrieve when the prompt asks for tone preference. The fix is consolidation. Most agents do not do it.
Where Mem0 fits
Mem0's storage model is built around the four fields episodic memory needs. Every memory carries a timestamp, a scope (user_id, agent_id, run_id), and a metadata dictionary the application can use for type tags, source-message pointers, or anything else worth carrying alongside the text.
The concrete handoff in code is short. After each turn:
The server-side extraction step decides which parts of the turn are worth promoting to memory and stores each one with the timestamp the call arrived at, the scope passed in, and the metadata attached. Retrieval is the mirror image:
The filters narrow the search to the right scope and the right episodic type. The search itself runs by meaning, with recency available as a sort option. The result is a short list of episodic facts the agent can fold into the working memory at the top of the next prompt.
For longer-running deployments Mem0 also handles the consolidation step described in the limits section. Repeated episodic memories that point at the same underlying fact get collapsed into a single durable memory over time, with the original episodic entries kept for audit. The graduation from episodic to semantic happens without the application having to schedule it.
Episodic memory is the part of memory most agents are missing in 2026. Semantic recall (the closest passage to the query) is solved. Personal recall (what happened to this specific user, when, and in what context) is not. Closing that gap is what episodic memory is for, and what an agent needs to feel less like a search engine and more like someone who has worked with the user before.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

