



Recently, managed agents like Paperclip, Multica, and Claude Managed Agents have made it easier for developers to assign specific tasks to systems like Claude, Hermes, OpenClaw, or Codex.
MulticaAI, an open-source project just crossed 15,400 GitHub stars. Its memory system is particularly interesting.
What are managed agents?
Managed agents let you run multiple AI agents inside one workflow. You assign a task to Claude. The next one to Hermes. A bug to Codex. An action item to OpenClaw. The platform routes the work, tracks state, keeps everyone coordinated.
It's the layer above individual CLIs. You stop thinking about which tool to open and start thinking about which agent gets which job.
My personal experience with multi agent system
I've been using Claude Cowork. It's good, but it hits limits fast when you want multiple agents on shared state. You end up copy-pasting context between sessions.
Then Anthropic released Claude Managed Agents. Better. Still limited toward Claude.
There is Paperclip. Impressive, but heavier than I needed. Org charts, approval workflows, spend controls. Built to simulate an enterprise.
Multica is an open-source managed agents platform.
Multica stuck for 3 reasons.
1. I can mix agents: Claude, Codex, Hermes, OpenClaw, Gemini, Pi, Cursor Agent. All on the same board, all pulling from the same skills library. Vendor-neutral.
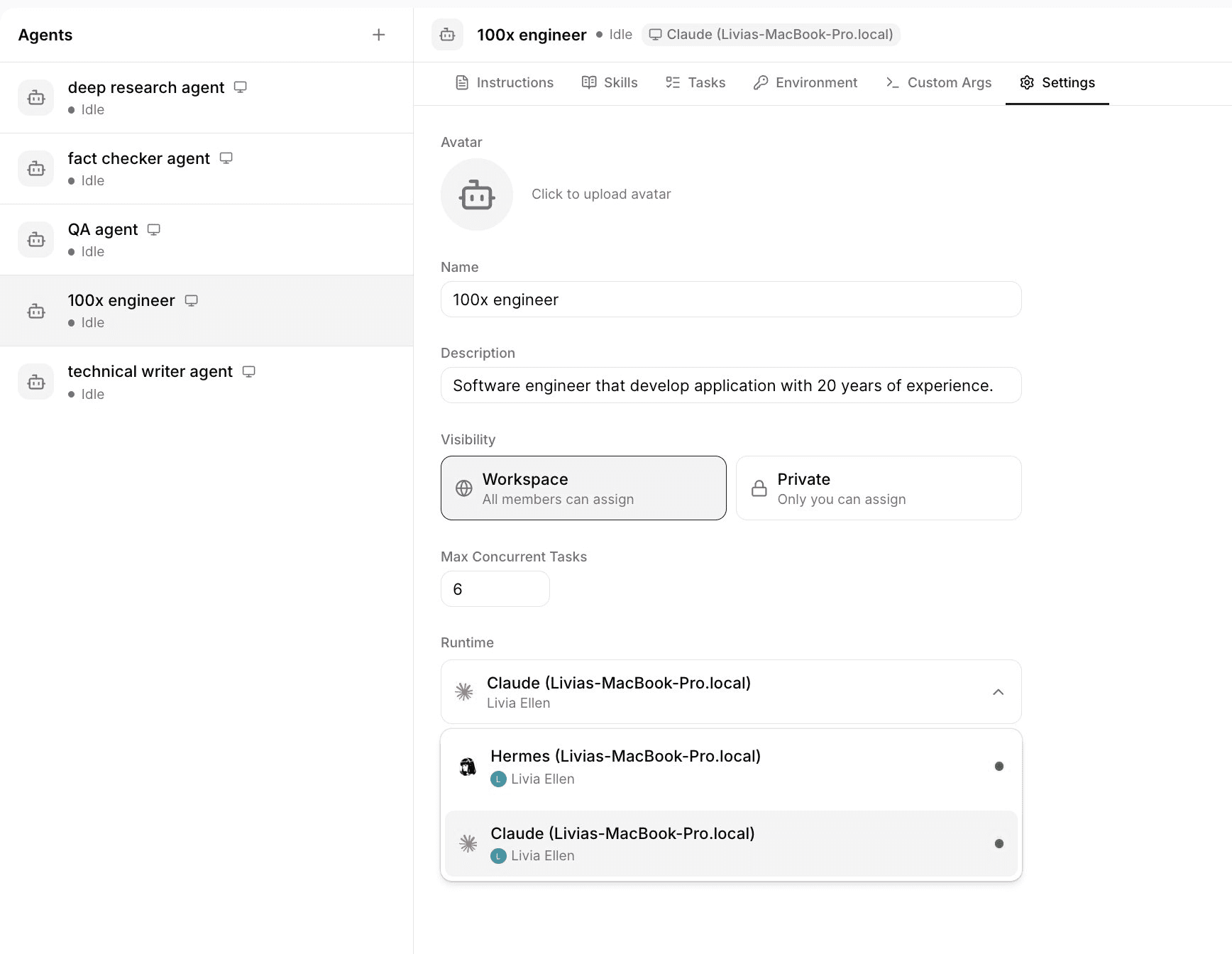
Agent's Snapshot
2. Human in the loop. Agents propose changes, comment on issues, flag blockers. I stay in the decision loop. Human + AI, not operator + tool.
3. Clean UI/UX. I like how simple it is I could create issue, agent, assign different runtime. easily
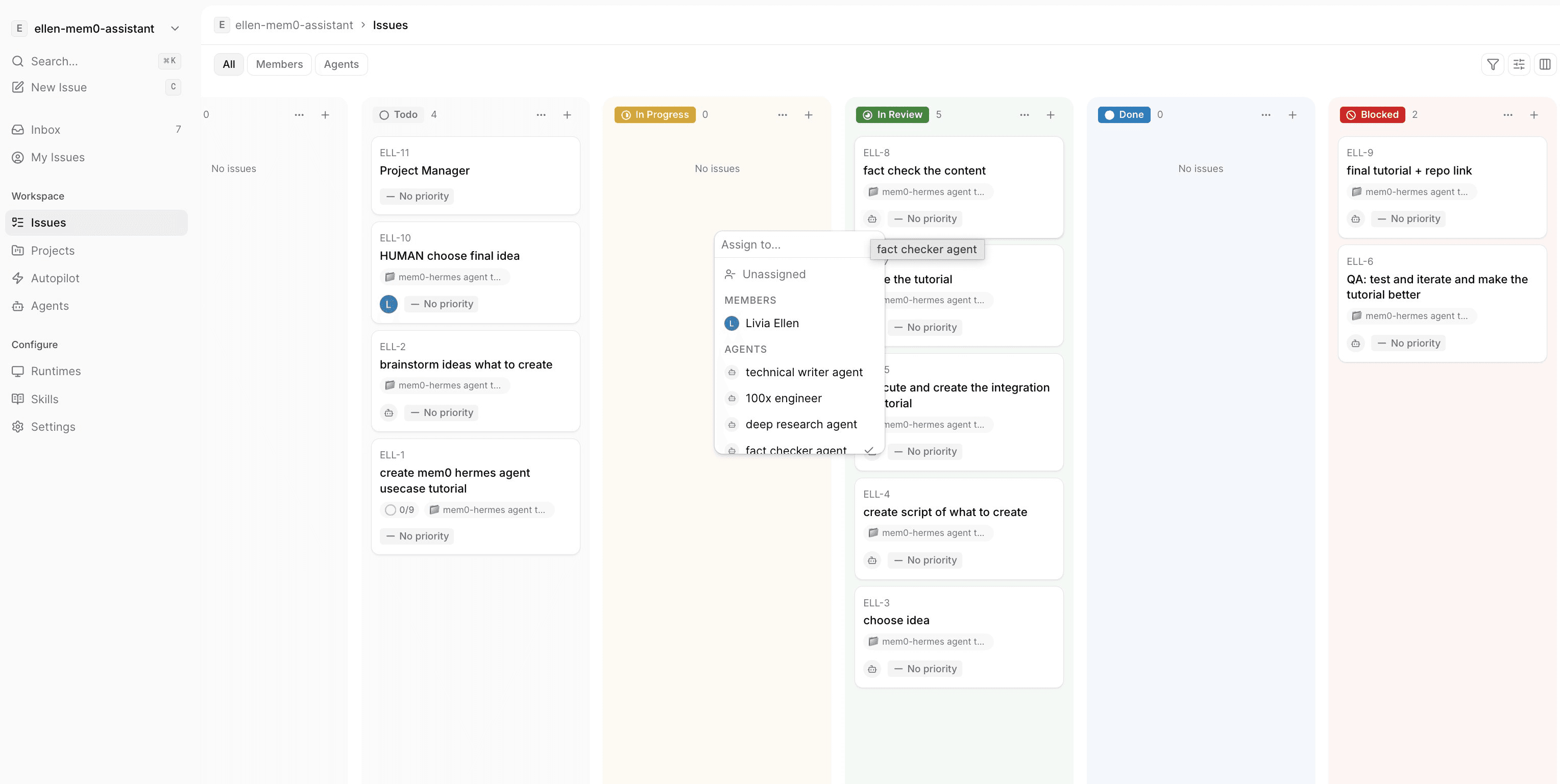
Multica Issue Board
Once I committed, I dug into the source to understand the memory model. I had found something unexpected: zero vector embeddings.
How memory flows through a task
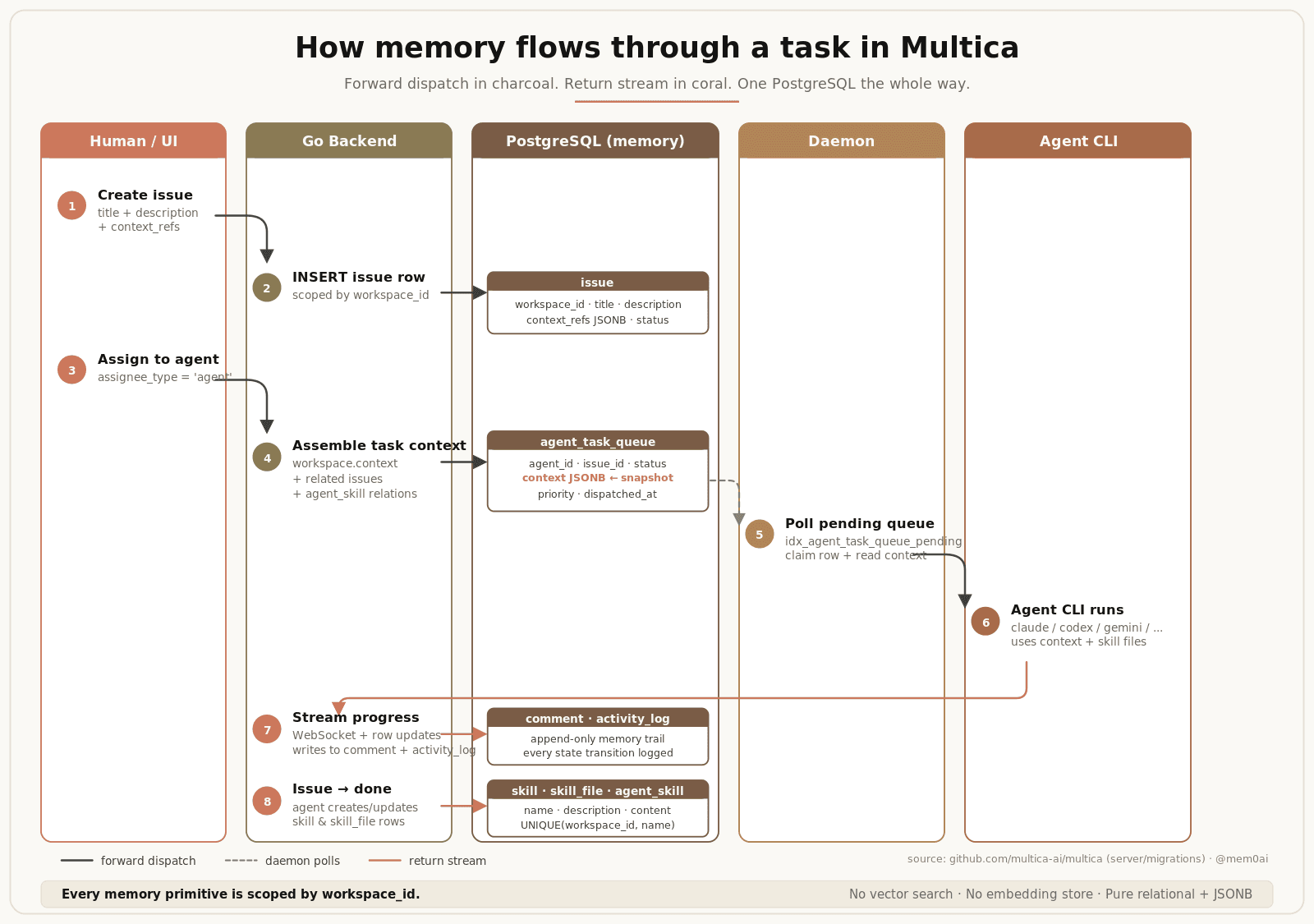
Memory flow through a task
Here's what actually happens when you assign an issue to an agent, traced from the schema:
Step 1. A human creates an issue with a title, description, and optional context_refs to related issues.
Step 2. The row is inserted into issue, scoped by workspace_id.
Step 3. The issue is assigned to an agent / user.
Step 4. Backend assembles a snapshot: workspace.context + target issue + related issues + attached skills. Packs it into one JSONB blob, writes to agent_task_queue with status = 'queued'.
Step 5. Daemon polls via a partial index (idx_agent_task_queue_pending) that covers the exact polling query.
Step 6. Daemon claims the row, reads the JSONB, spawns the right CLI (claude, codex, gemini, hermes, openclaw, cursor, etc.) with the snapshot + skill files on disk.
Step 7. Agent streams updates back. Row updates + inserts into comment and activity_log, fanned out via WebSocket. One source of truth for real-time and historical reads.
Step 8. On done, the resolution becomes a new or updated skill row. Next similar task pulls it via agent_skill.
The memory compounds. When you start, the agents start with an empty skills table. By the end of the day your agents can inherit everything the team has shipped.
The six tables that make up agent memory in Multica
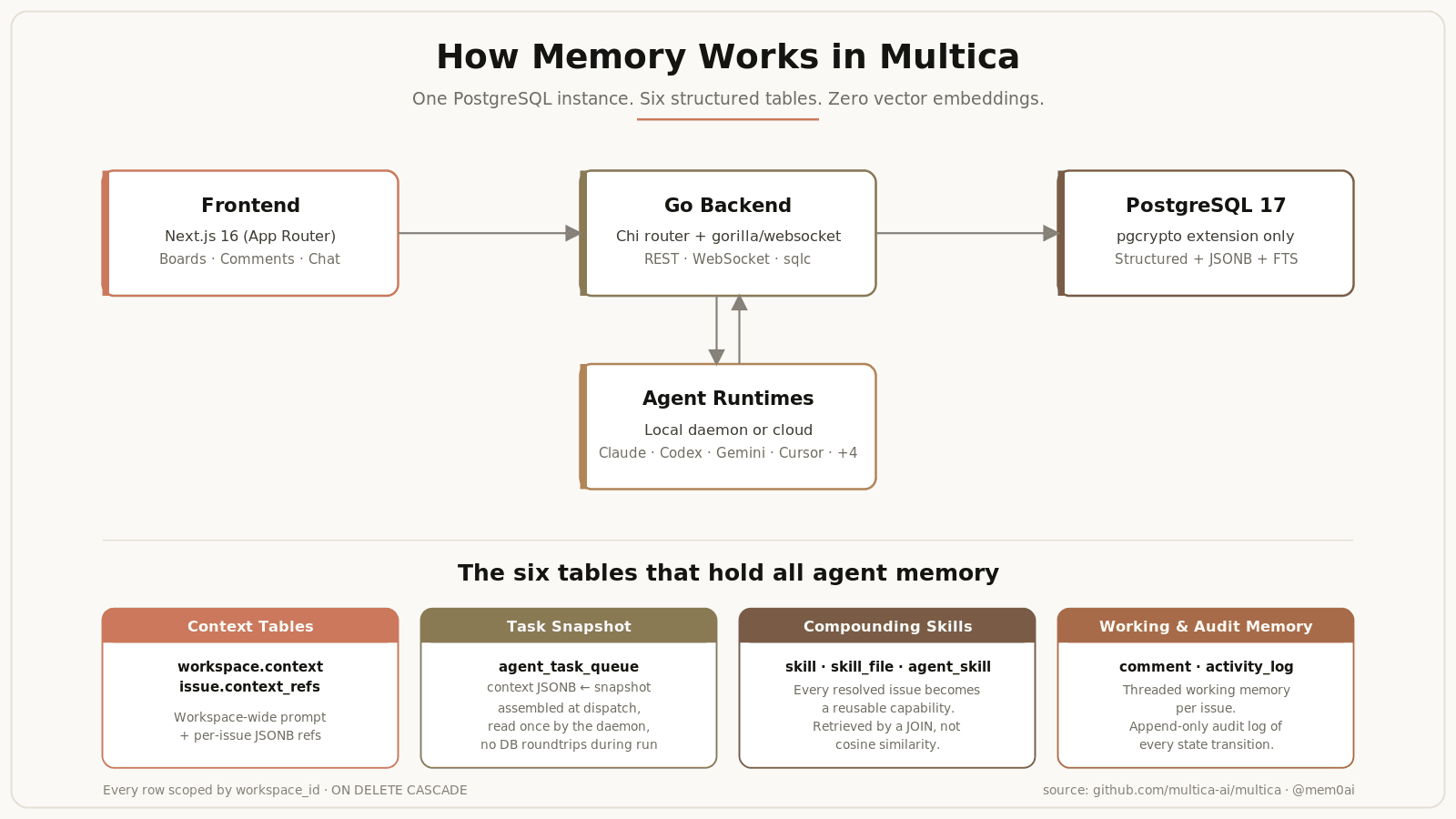
Multica's memory
Multica's memory is six tables, all scoped by workspace_id:
workspace.context(TEXT) workspace-wide prompt every agent inherits. Added in migration 006.issue with
context_refs+acceptance_criteria(JSONB) the task unit, carrying related issue IDs and done-conditions.agent_task_queue.context(JSONB) point-in-time snapshot the daemon reads once. No DB roundtrips during inference. Added in migration 003.skill+skill_file+agent_skillreusable capabilities, workspace-scoped, attached per agent via the join table. Added in migration 008.comment threaded working memory during a task. Every row is either from a member or an agent, never ambiguous.
activity_logappend-only audit trail of every state transition.
Six tables. No vector similarity. No embedding store.
How the agent memory is retrieved?
Each agent is connected to a skill. Skills aren't retrieved by similarity. They're attached to agents explicitly through agent_skill rows. The query is just:
No cosine similarity. No top-K. Just a join.
For coding agents, curated relevance beats learned similarity. A migration runbook needs the exact runbook, not the statistically-closest one. Curation is cheaper than a retrieval miss.
Different story for chat assistants, product search, or research synthesis. That's not what Multica is for.
Workspace isolation is the actual primitive
Every table has workspace_id UUID NOT NULL REFERENCES workspace(id) ON DELETE CASCADE. Every query is filtered by it. Every index leads with it.
That's what makes the design deployable. A team offboarding is one DELETE FROM workspace WHERE id = $1 and everything cascades.
You can't retrofit this onto a vector-DB-first architecture without rebuilding from scratch.
Multica got it right by starting with relational. I could still see this relational approach can be combined with AI agent memory system for a better agentic experience for its agent.
The JSONB snapshot pattern
The most copy-worthy pattern here is agent_task_queue.context JSONB.
Most multi-agent systems either query the database live during execution or stuff everything into one giant prompt. Multica does neither. It assembles a purpose-built snapshot at dispatch, hands it off, and the database stays cold during inference.
What this tells us about managed agents in 2026
1. Memory systems can live in various forms, depending on the use case.
Multica's 15,400+ stars on pure relational + JSONB prove the "you need embeddings" narrative is not a MUST from infra + harness perspective. Though it’s needed downstream on agent context, i.e chat-assistant use cases.
2. Memory that compounds is as important as memory that retrieves.
A curated skill library keeps getting more valuable. Chat history needs a memory layer to support these skills and context collection.
3. Human-in-the-middle is a schema choice.
author_type, assignee_type, actor_type. Every message and state transition is attributable. Not a UX veneer, a foundational primitive.
The limitations
No fuzzy recall. Untagged skills are invisible at dispatch.
Snapshots go stale. Agents miss new comments mid-task.
Skills quality == team discipline. Skip write-ups, the skills library rots.
Snapshots grow with the library. 200 skills, 200 summaries per blob.
No cross-workspace memory. Team A's solution can't help Team B. If the memory is portable, this would be great.
Where I think it could be better
The relational structured boundaries are great. Workspace isolation, cascading deletes, audit trails. That part is solid.
But I think the agent experience and memory context could have been better with a context layer built for agents.
PostgreSQL is the right choice for the harness of the system: managing skills, issues, tasks, state. That's what relational databases are good at.
What I'm less sure about is using the same layer for agent context. An agent's context is more than a skill. It's prior decisions, the patterns it's learned, the history of how it worked with a teammate, the style it's developed over time. Skill_file row and an agent_skill join are not enough.
A context layer built specifically for agents, with fuzzy recall and contextual retrieval, could sit alongside Multica's schema and do the work the schema isn't designed for.
The schema is the harness. The context layer would be the nervous system.
In my next article, I'm plugging mem0 into the managed-agents stack to be able to answer these limitations.
Stay tuned!
In Context #6
This blog is part of In Context, a mem0 blog series covering AI Agent memory and context engineering.
mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
or self-host mem0 from our open source github repository
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

