



AI engineers who ship agents to production eventually run into the same wall i.e, the model forgets. Context windows and vector databases do help, but the agents that interact with users over days or weeks need a different approach to memory.
This article walks through what long‑term memory means for agents, how traditional patterns fall short, and how Mem0 provides a focused memory layer that fits into modern agent stacks. Code examples use Python and can be adapted to LangChain, LlamaIndex, or custom orchestration.
What long term memory means for AI agents
For interactive agents, "long‑term memory" is not just bigger context. It is the set of facts, preferences, and histories that should persist across sessions and influence future behavior.
Typical categories include:
User profile: identity, role, constraints, goals
Preferences: tone, formats, tools the user likes, recurring choices
Ongoing work: project state, draft versions, open tasks
Learned patterns: how the user writes, what they ignore, their schedule
Environment knowledge: organizational rules, domain configuration
Long‑term memory should be:
Persistent across sessions and devices
Selective so only relevant pieces are used in each step
Evolutive so knowledge can be updated, fixed, or forgotten
Attribution friendly so the system knows why something was stored
Without this structure, agents repeat questions, ignore past decisions, and feel "stateless" even with powerful models.
Core components of an agent memory system
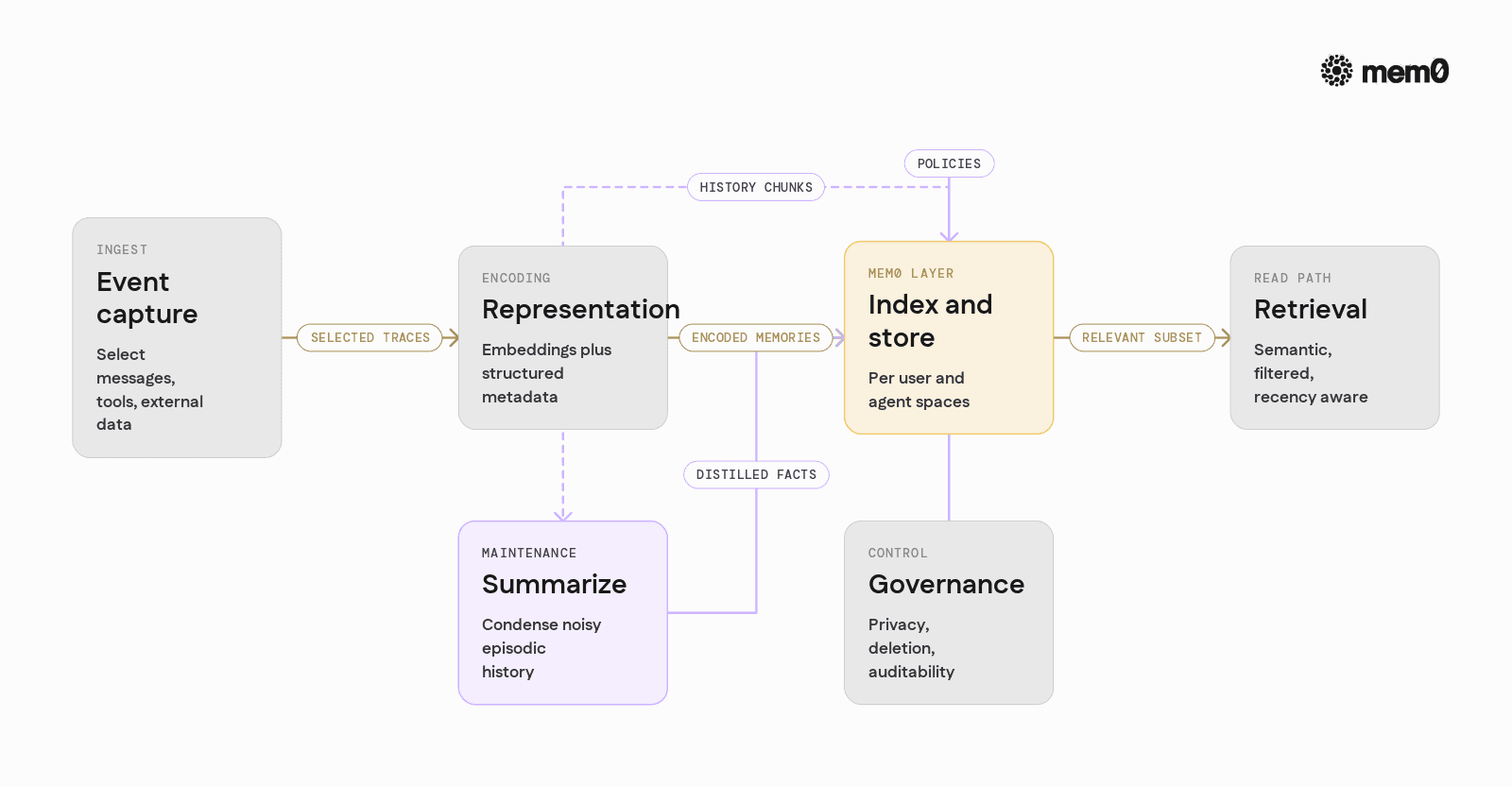
Any long‑term memory layer needs to solve a few concrete problems including.
Event capture: Decide what to store from raw traces: messages, tool calls, external data. This often uses heuristics, LLM-based classifiers, or explicit flags from the agent logic.
Representation: Convert text into a form that supports retrieval. Commonly embeddings plus metadata, sometimes also structured fields or key‑value projections.
Indexing and storage: A store for potentially large collections of memories, organized by user, topic, or task. It must support updates, soft deletes, and efficient search.
Retrieval: Pull a small set of relevant memories per step, based on the current query, user, and task. This can combine semantic search, metadata filters, and recency.
Summarization and distillation: Systems need summarization to condense history into more stable facts and keep indexes manageable.
Governance and privacy: Memories contain sensitive data. Isolation across users, environments, and tenants, plus auditability and explicit deletion, is essential for production.
In a basic prototype, engineers often embed messages on the fly and store them in a generic vector DB. This works for demos but hits limits once sessions and users multiply.
Why naive context and vector patterns fall short
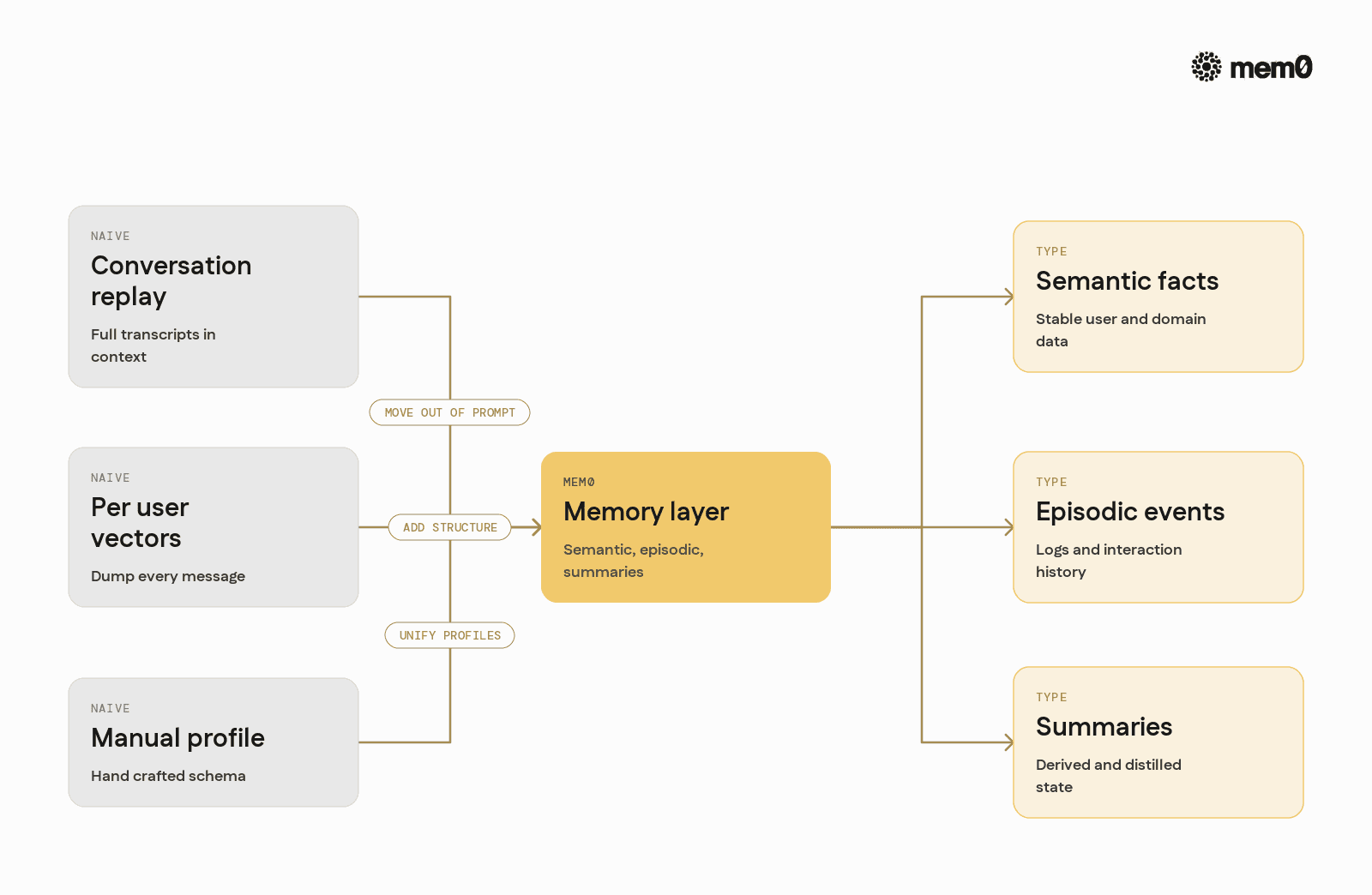
Three common patterns appear in first‑generation agent systems.
Huge conversation replay: Store entire transcripts and pass them back into the model each time.
Problems: context window limits, high latency, cost, and increased risk of leaking sensitive segments into prompts.
Direct vector store per user: Dump every message into a vector store and retrieve top‑k by similarity.
Problems: mixed granularities, no notion of memory type, poor control over what gets stored, and eventual retrieval noise as collections grow.Manual user profile storage: Keep preferences in a hand‑crafted schema, update them via LLM calls.
Problems: rigid structure, duplication of logic across agents, and limited support for unstructured episodic memories.
These approaches ignore that agents need different classes of long‑term memory including stable facts (semantic), episodic events (logs), and derived state (summaries). They also push engineers to re‑implement the same "memory plumbing" for each new agent.
How Mem0 frames agent memory
Mem0 focuses on being a dedicated memory layer for LLMs and agents. It handles how text and events turn into long‑term memories, and how those memories are retrieved in later interactions.
Key concepts:
Memory as first‑class object: Each memory has content, metadata, score, and timestamps. It is not just an embedding row.
Agent and user scoping: Memories are keyed by
user_idand optionally byagent_idor other identifiers. Each agent can have its own memory space, while sharing user knowledge when desired.Automatic extraction: Mem0 can use LLMs under the hood to decide what to store from a conversation, not just store every message blindly.
Multi‑source memories: Support for conversational snippets, documents, tool outputs, and explicit "facts" inserted by application logic.
Retrieval modes: Different retrieval strategies such as semantic similarity, recency biased queries, or type‑filtered search.
Mem0 is not an orchestration framework, router, or full agent runtime. It focuses on long‑term memory, which allows it to integrate with any agent stack.
Architecting agents with Mem0 as a memory layer
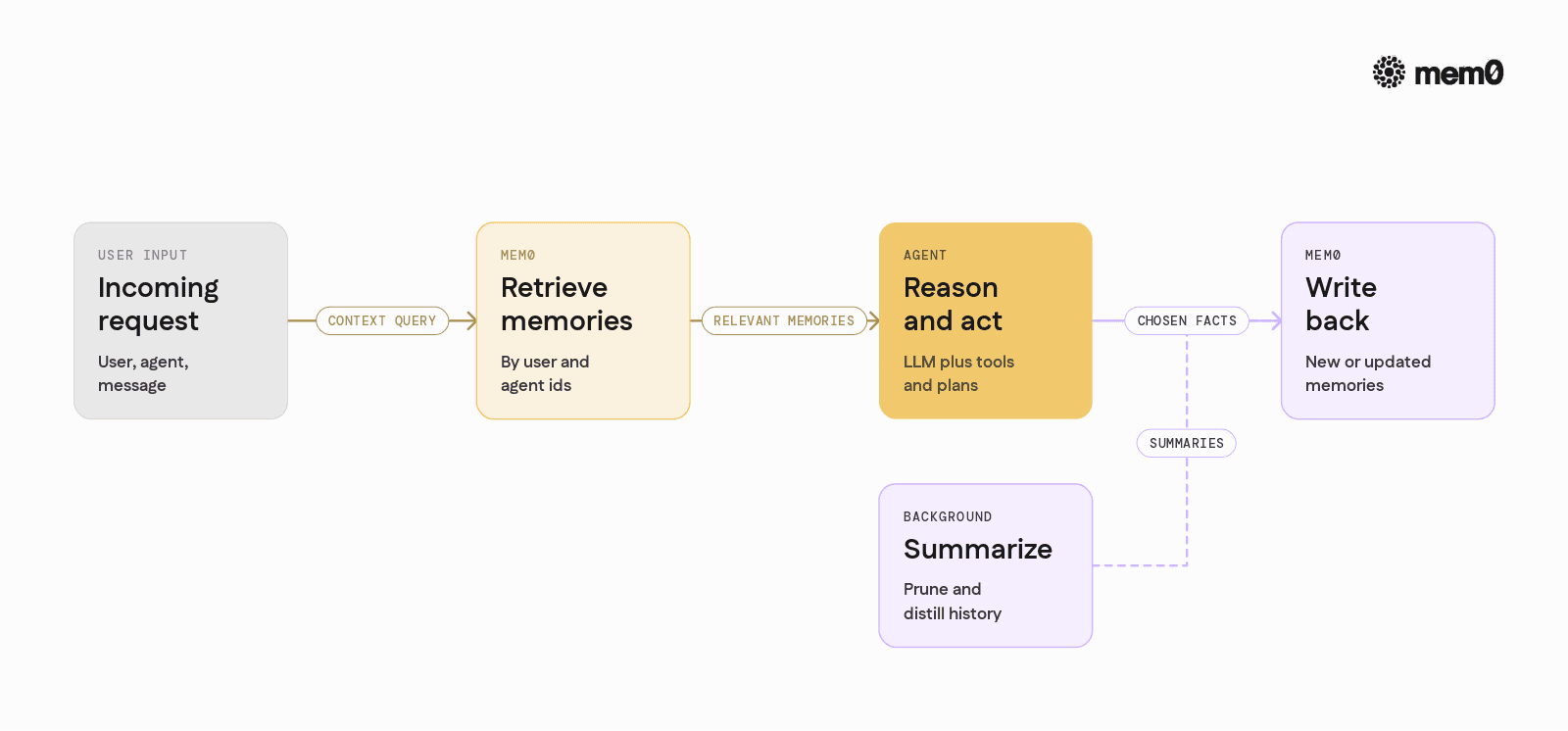
A typical production agent architecture with Mem0 looks like this:
Request comes in: Request includes user identifier, agent identifier, and query or message.
Memory retrieval: Mem0 is queried using
user_id, possiblyagent_id, and the current input text. Returned memories are injected into the prompt or used to prime tools.Agent reasoning and tools: The agent uses an LLM plus tools (APIs, databases, internal systems) to respond. It calls Mem0 again during multi‑step reasoning.
Memory writeback / refinement: After the agent completes a step, selected parts of the interaction are sent to Mem0 as new memories or as updates to existing ones.
Periodic maintenance: Background jobs apply summarization or pruning strategies to keep memories relevant and compact.
The integration points are retrieval at the beginning of each step and writeback at the end. This can be added incrementally to an existing agent without changing the whole runtime.
Basic Python integration with Mem0
Let's build a chat loop for a support agent that pulls from and updates long‑term memory using Mem0.
🔑 Get your Mem0 API key free: app.mem0.ai.
This example keeps the logic simple:
Mem0 is queried with
user_idandagent_idfor relevant memories.Returned memories are formatted into a "Known user context" section.
A basic heuristic picks up sentences that likely contain preferences or identity and stores them as new memories.
In a real system, the extract_memory_candidate function is often replaced with an LLM prompt that identifies and normalizes memories, then passes those to Mem0.
Using Mem0 in multi agent and tool heavy systems
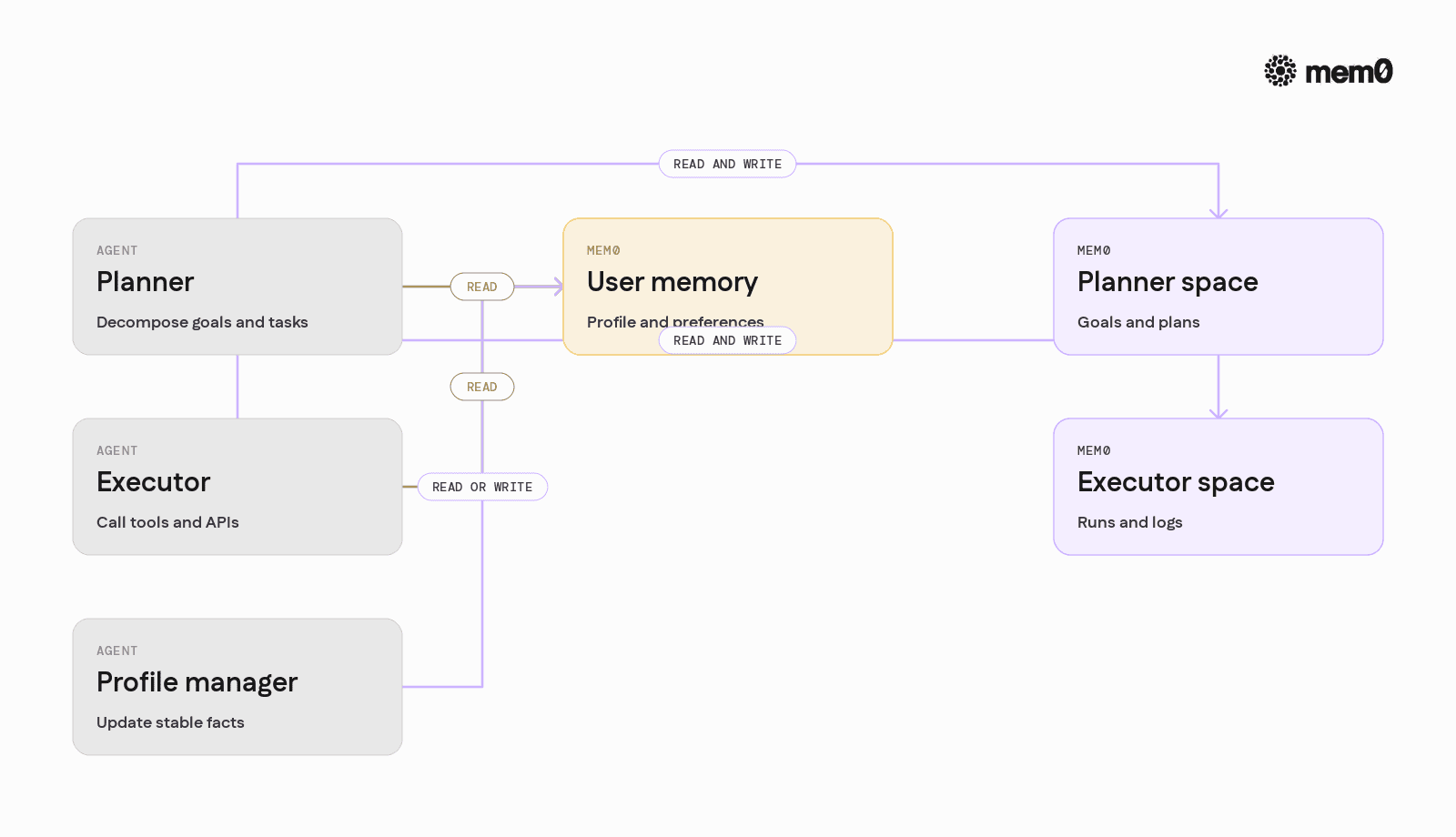
Production agents often involve multiple autonomous components: planners, executors, critics, or specialized sub‑agents. Each of these can interact with Mem0 differently.
Common patterns:
Shared user memory, scoped agent memory: A global space stores user profile and long‑term preferences, while each agent has its own task specific memories such as "projects", "tickets", or "drafts".
Role specific writeback: Some agents only read from memory, others are allowed to create or update. For example, a "profile manager" sub‑agent might have permission to update stable facts, while a "chat agent" only writes ephemeral notes tagged accordingly.
Tool enriched memories: Mem0 can store not just text from the conversation, but also tool outputs and decisions, for example "On 2026‑05‑10 the agent synced calendar events from Provider X".
Python pseudo‑code for a multi‑agent pattern:
In each case, Mem0 acts as a shared memory fabric across agent roles.
Comparison with ad hoc memory stacks
The table below outlines how a dedicated memory layer like Mem0 typically compares with common ad hoc setups.
Aspect | Raw vector DB per user | Custom key value store | Mem0 as memory layer |
|---|---|---|---|
Primary abstraction | Embedding rows | Arbitrary JSON blobs | Memories with content, metadata, and retrieval APIs |
Memory extraction logic | Manual per app | Manual per app | Built in extraction patterns, configurable |
Retrieval modes | Similarity search only | Manual filtering and queries | Semantic, filtered, and recency aware search |
Support for user and agent IDs | Needs custom schema | Needs custom schema | First class fields on memory objects |
Summarization and distillation | Custom jobs and prompts | Custom jobs and prompts | Integrated patterns and hooks |
Tool output and event storage | Possible but unstructured | Possible but unstructured | Designed for multi source memories |
Operational overhead | Schema design and indexing per agent | Logic and schema per feature | Shared layer for multiple agents and surfaces |
Using Mem0 reduces the amount of "glue code" needed to get a workable long‑term memory system, and makes it feasible to standardize patterns across multiple agents or products.
Patterns for controlling what agents remember
Long‑term memory needs discipline. Agents that store everything become noisy, and agents that store nothing feel forgetful. Mem0 supports patterns that help keep memory relevant.
Some practical strategies:
Memory types: Tag memories as
preference,profile,task_state,log, orsummary. Retrieval calls can filter by type depending on the agent action.Confidence and score: Include model confidence or heuristic scores in metadata. Later, a summarization job can prioritize high confidence facts and downgrade others.
Temporal decay: For episodic memories, use timestamps and explicit TTL policies. Old logs can be summarized into coarser descriptions, reducing clutter.
Human editable facts: Store key profile facts as distinct memories so external systems or admin tools can update them without touching raw conversation logs.
In Mem0, many of these controls can be implemented through consistent metadata and periodic background processes that call the Mem0 API to read, summarize, and write.
Limitations of long term memory patterns
Long‑term memory does not remove fundamental constraints around LLMs and data quality. It introduces its own trade‑offs.
Error propagation: If an early interaction produces an incorrect fact and it is stored, future interactions may reinforce the error. Systems need mechanisms for correction and conflict resolution.
Prompt injection and poisoning: Attackers can attempt to insert malicious content into memory, for example by stating false preferences or injecting prompt instructions. Filters, trust scoring, and role based write permissions are important.
Cost and latency trade‑offs: Each retrieval and write adds overhead. For high QPS agents, pipelines must balance memory depth with performance, possibly by caching or limiting retrieval to key actions.
User expectations and control: Users may expect the agent to "forget" some information. Memory systems need deletion APIs and UX patterns that expose what is remembered.
Semantic drift over time: As models or embeddings change, old memories may not align perfectly with new representations. Migration and re‑indexing strategies are often required for long lived systems.
Mem0 simplifies many operational and representational details, but it does not remove the need for thoughtful design of what agents should remember and why.
Frequently Asked Questions
What is the main benefit of long‑term memory for AI agents in production?
Long‑term memory lets agents remember user preferences, ongoing tasks, and past decisions across sessions. This reduces repetition, improves personalization, and allows agents to handle multi‑day or multi‑week workflows reliably.
How does Mem0 integrate with existing agent frameworks?
Mem0 is framework agnostic. It is called as a separate memory service from within your agent logic, usually at the start of each reasoning step for retrieval and at the end for writeback, whether you use custom orchestration or libraries like LangChain or LlamaIndex.
When should an agent write to memory instead of just using short‑term context?
Write to memory when information is likely to be useful beyond the current interaction, such as stable preferences, project state, or important events. Transient details needed only for a single multi‑turn exchange can remain in the short‑term context window.
How can engineers control what the agent remembers with Mem0?
Engineers control memory through extraction logic, metadata tags, and retrieval filters. They can use heuristics or LLM prompts to decide what becomes a memory, then query Mem0 with constraints on type, recency, or score for each agent action.
Why not just use a vector database directly for agent memory?
Vector databases provide raw similarity search but do not define what a "memory" is or how to manage it over time. Mem0 builds on embeddings to provide memory‑aware APIs, user and agent scoping, and patterns for extraction, retrieval, and summarization that are tuned for LLM agents.
How does long‑term memory handle privacy and deletion requirements?
A well‑designed memory system scopes data by user and tenant, tracks metadata, and exposes deletion operations for specific memories or entire user histories. Application logic should use these capabilities to implement user‑facing controls and comply with data handling policies.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

