



When one agent delegates a task to another, the receiving agent starts from zero. It has no knowledge of the calling agent's user, no awareness of prior delegations, and no accumulated context from past interactions, even if the same two agents have exchanged hundreds of tasks before.
What Agent-to-Agent Protocols Are
A2A (Agent-to-Agent) is an open protocol originally published by Google in April 2025 and now donated to the Linux Foundation, that standardizes how autonomous agents discover each other and collaborate on tasks. The protocol data model is binding-agnostic — defined in Protocol Buffers — with official bindings for JSON-RPC 2.0 over HTTP, gRPC, and HTTP/REST. Implementations typically surface JSON-RPC 2.0 over HTTP, and the protocol supports synchronous requests, streaming via Server-Sent Events, and asynchronous push notifications.
The protocol revolves around three constructs. AgentCards are JSON capability declarations that agents publish so other agents can discover what they offer and how to call them. Tasks are units of work with a defined lifecycle. The core states are submitted, working, completed, and failed. The specification also defines canceled, input_required (agent needs more information to proceed), rejected (agent declined the task), and auth_required. Each task receives a unique identifier and can carry text, files, or structured JSON data in its message parts. Critically, the A2A specification describes how agents communicate, not what state they share.
MCP (Model Context Protocol) operates at a different layer. Anthropic's protocol standardizes how a single agent accesses tools and data sources, such as databases, browsers, and APIs. A2A handles agent-to-agent conversation. MCP handles agent-to-tool connection. They are complementary and often used together in multi-agent systems.
Why Multi-Agent Systems Lose Memory at Handoff Points
This problem exists in every multi-agent architecture, not just A2A systems. In a single-agent system, the context window holds everything: the conversation history, tool results, and accumulated reasoning. When a second agent enters, it gets its own context window. The first agent can include information in the task payload it sends, but there is no automatic transfer of all prior state.
A2A makes this gap more visible because its task model is explicit. Tasks have a defined structure, a unique ID, and a typed payload. That clarity makes it obvious what travels across the boundary and what does not. In a looser multi-agent setup built on ad hoc function calls or message queues, the same gap exists but is easier to miss until production.
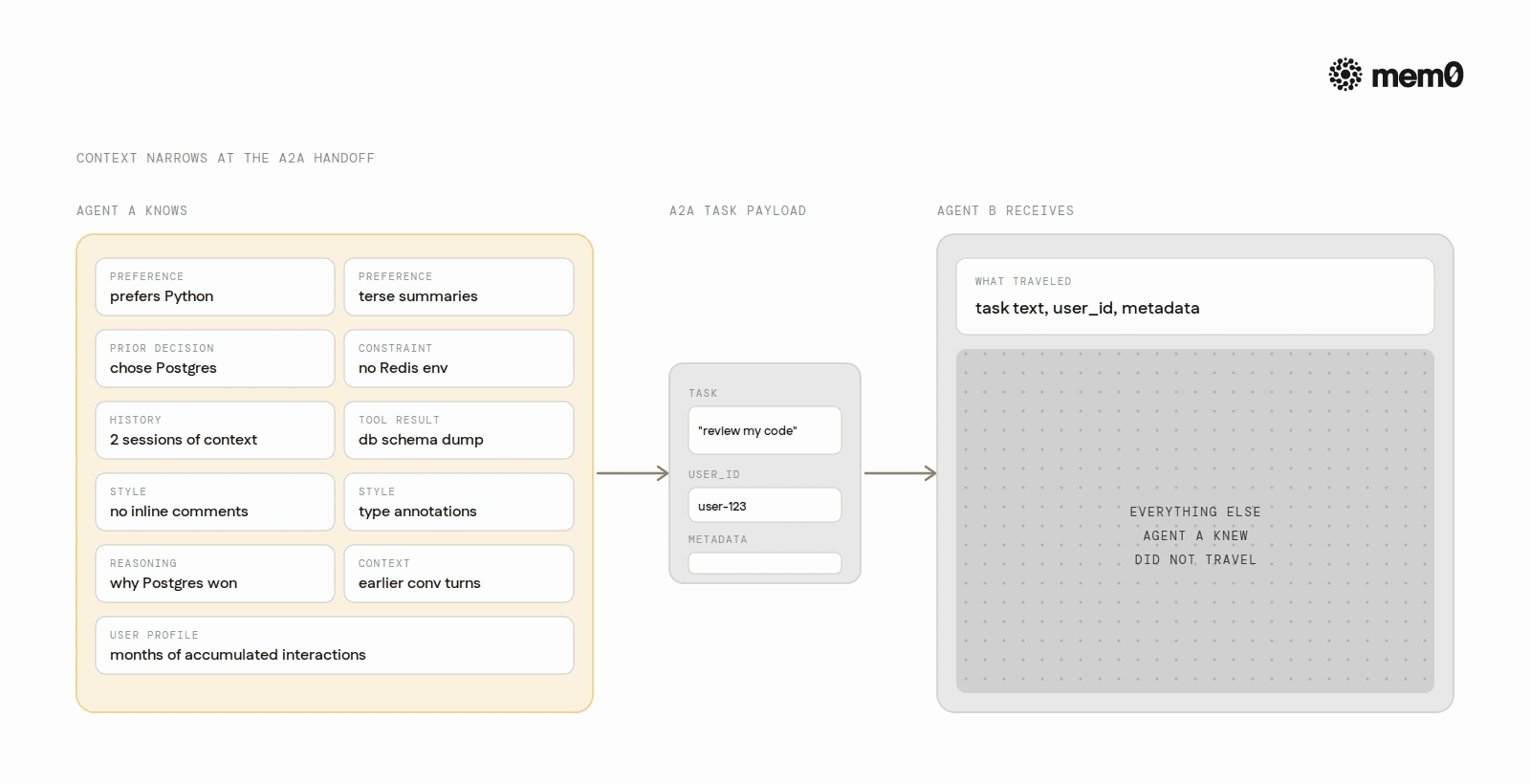
The gap matters because delegating agents typically know things about the user that the receiving agent needs to do its job well. Which programming language the user prefers. Whether the user wants verbose explanations or terse summaries. The prior decisions the user made two sessions ago that constrain what the agent should suggest now. None of this travels with an A2A task by default.
The receiving agent sees only what the delegating agent explicitly includes in the task message. If the delegating agent did not anticipate a particular piece of context, the receiving agent works without it. This is not a protocol bug, it is an architectural consequence of how context windows and task passing work together.
The Three Memory Gaps in Agent Networks
Multi-agent systems face three distinct memory gaps, each at a different layer.
Per-agent isolation is the first. Each agent in a network has an independent context window. There is no shared working memory that all agents read from and write to in real time. Agent B cannot observe Agent A's reasoning or tool results unless Agent A sends them explicitly.
Task handoff loss is the second. When Agent A creates an A2A task for Agent B, the task payload contains only what Agent A chose to include. User preferences, historical patterns, and accumulated context that live in Agent A's session are not automatically serialized into the task. Agent B therefore handles the task without them.
Cross-session amnesia is the third. Even within a single agent, the next session starts fresh. If a user interacted with Agent B yesterday, Agent B has no record of that interaction today unless something external preserved it. Multiply this across multiple agents in a network and the problem compounds: any agent in the graph could be the one handling a task, and none of them remember past interactions with the user.
The Naive Fix and Why It Breaks
The most direct response to task handoff loss is to include more context in the A2A task payload. If Agent A knows the user prefers Python over JavaScript, it adds that fact to the task message. If there is relevant conversation history, it serializes and attaches it.
This approach works at small scale and breaks predictably at larger scale. Context windows are finite. As the amount of user history grows, the task payload grows with it. Eventually, payloads exceed what models can meaningfully process, and latency increases with payload size. The delegating agent must also maintain a complete record of all user state to include it, turning every orchestrating agent into an implicit user database.
There is also a correctness problem. User context is not owned by any single agent. In a system where multiple agents handle requests, each agent has a partial view of the user's history, specifically the portion that passed through it. No single agent has the complete picture. Centralizing context in the orchestrator requires routing all requests through one node, which introduces bottlenecks and single points of failure.
Shared Memory Architecture
The pattern that avoids these problems is a shared memory layer that all agents read from and write to, keyed by user identifier. Instead of agents holding user state themselves, they query the shared store at task start and write back relevant outcomes at task end.
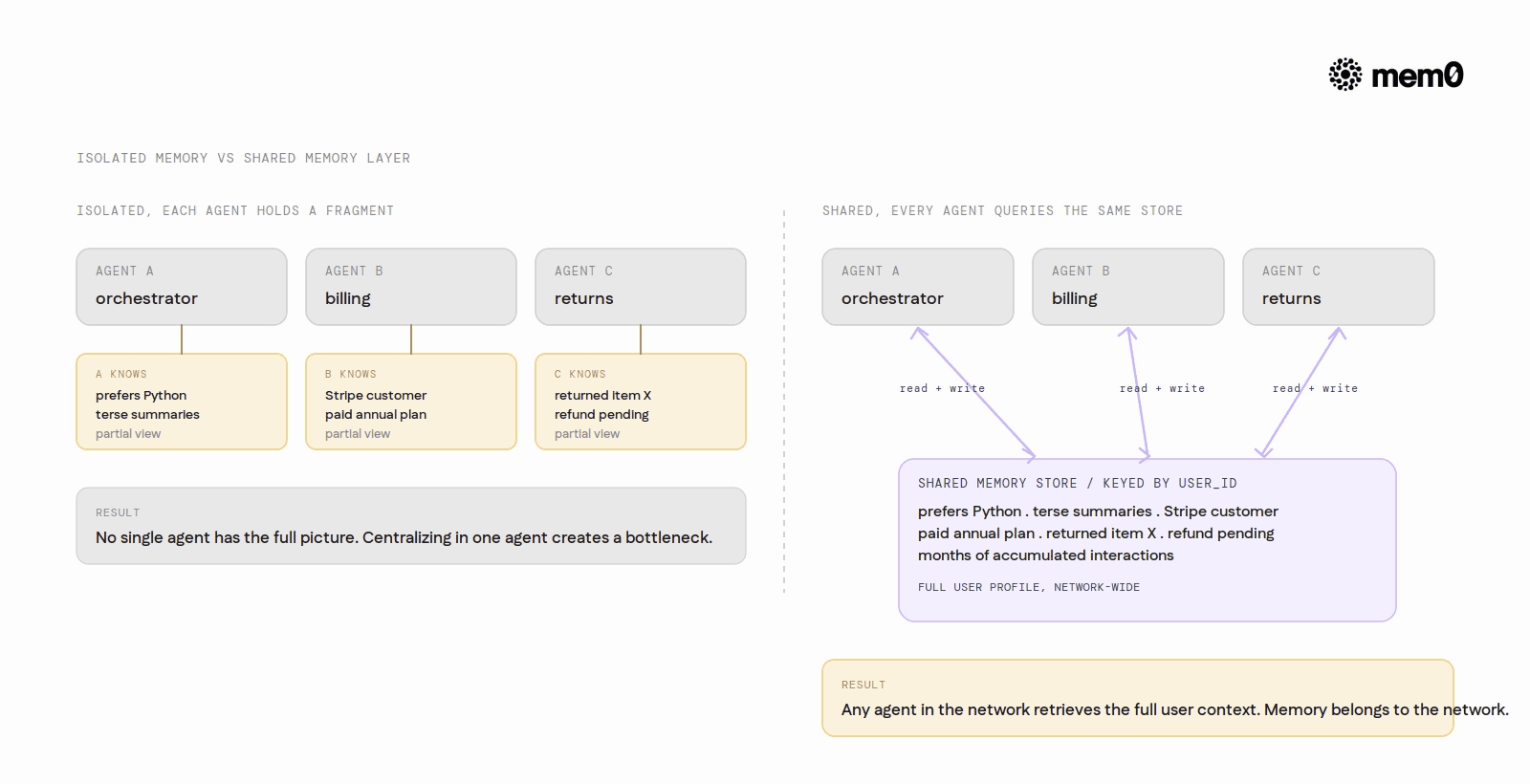
Any agent in the network can retrieve the user's full context, not just the fraction of history that passed through it. Agent B and Agent C both query the same store and see the same user profile, regardless of which agent handled prior requests.
Code Example: Agent A Stores, Agent B Retrieves
Consider a customer support system where an orchestrating agent triages requests and routes them to specialist agents - a billing agent, a technical support agent, a returns agent. Each specialist needs to know the user's account type, their history of prior issues, and their communication preferences (terse vs. detailed). None of that arrives in the A2A task payload automatically. With Mem0 as the shared layer, every specialist agent queries the same store for the same user before responding, and each interaction writes back to that store so the next specialist sees the full picture.
The following example shows this pattern in code: Agent A handles the user's initial request and stores the outcome. Agent B picks up a delegated task and retrieves the same user context before working.
Both agents query filters={"user_id": user_id} against the same Mem0 instance. The user's preferences stored by Agent A in the first interaction are immediately available to Agent B in the next.
Comparison: Isolated Memory vs Shared Memory
Dimension | Isolated Agent Memory | Shared Memory Layer |
|---|---|---|
User context at handoff | Only what delegating agent sends | Full history, all agents |
Payload size as history grows | Grows unboundedly | Query returns relevant subset |
Context available to new agents | None without explicit transfer | Full, via user_id lookup |
Cross-session continuity | Only within one agent | Across all agents, all sessions |
Implementation complexity | Low initially, high at scale | Moderate upfront, stable at scale |
Single point of failure risk | Distributed (each agent fails alone) | Memory store becomes critical path |
When Shared Memory Causes Problems
Shared memory introduces coordination hazards that isolated memory does not have.
Concurrent writes are the most common. If Agent B and Agent C both handle tasks for the same user simultaneously and write memories back to the shared store at the same time, the outcome depends on write ordering. Mem0 does not offer transactional guarantees equivalent to a relational database. Applications with high concurrency for the same user should serialize memory writes or implement optimistic concurrency at the application layer.
Memory contamination is a subtler problem. If Agent B stores a memory that is incorrect, that memory is now available to every other agent querying the same user. In isolated architectures, a bad memory in Agent B stays in Agent B. In a shared architecture, it can influence Agent A, Agent C, and any future agent.
Stale context can mislead agents when user preferences change. A user who migrated from Python 2 to Python 3 six months ago will have old Python 2 preferences in memory if they were never updated. Agents should treat memories as signal, not ground truth, and reconcile retrieved context with the current request before acting on it.
Where Mem0 Fits
Mem0 functions as the memory substrate for multi-agent systems where no single agent can own the complete user history. Each agent in the network reads and writes to the same Mem0 instance using the same user identifier, giving the network a coherent, personalized view of every user regardless of which agent handles a given request.
This eliminates the task payload inflation problem. Instead of the orchestrating agent embedding user history into every A2A task, receiving agents pull exactly the context they need at execution time.
Final Notes
Agent-to-agent protocols solve the coordination problem but not the memory problem. A shared Mem0 layer gives every agent in a network access to the same user context, making memory a property of the network rather than of any individual agent.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

