



I read Meta’s HyperAgents paper. They introduce a self-improvement loop for agents, reaching 0.71 on IMO-GradingBench. Across tasks, they didn’t just get better, they generate their own memory system.
Self-Improving AI Is Having a Moment
Something is shifting in AI research right now. Self-improving systems, agents that can modify themselves to get better at tasks without human engineering, are becoming a serious research frontier.
Karpathy recently released autoresearch, a framework for automated scientific research. Meta dropped HyperAgents. We've had DGM, ADAS, and a string of papers exploring what happens when you let agents improve their own code.
The throughline: every system that achieves sustained improvement eventually discovers it needs memory. Not as a feature someone adds as something the system demands to function.
This analysis is based on Meta’s “HyperAgents” paper, published at ICLR 2026. You can explore the code and related resources here: GitHub repository
What is HyperAgents?
HyperAgents is a self-referential agent that combines the task agent and the meta agent into a single editable program, one that can improve not just how it solves tasks but how it generates future improvements. The meta-level modification procedure is itself editable, enabling what the paper calls metacognitive self-modification.
It builds on the Darwin Gödel Machine (DGM), extending it into a fully self-referential system where the agent can modify both itself and its improvement process.
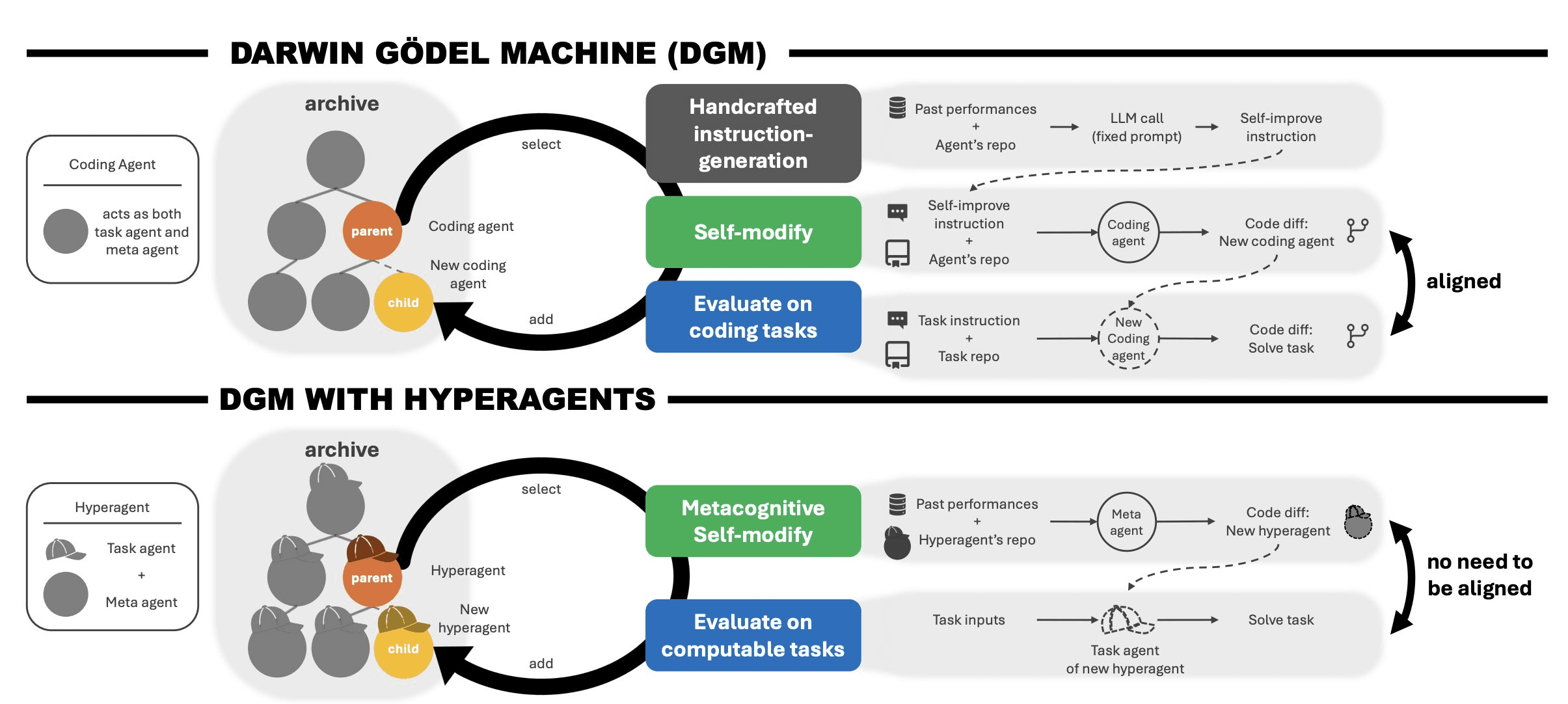
HyperAgents System
The researchers gave the system a task, a meta-agent with permission to modify anything, and let it run.
By generation 3, the agents had invented timestamped insight storage, a performance tracking class, and a causal hypothesis log, written entirely by the system, for the system.
HyperAgents aren’t just theoretical.
They were tested across coding, paper review, robotics, and Olympiad math.
Paper review: 0.0 → 0.71
Robotics: 0.06 → 0.37
Cross-domain transfer: +0.63 vs 0.0 baseline
They don’t just get better at tasks. They get better at improving.
Memory in HpyerAgents
Most agent frameworks treat memory as a feature you bolt on. HyperAgents flip this. Memory isn't a design decision, it's an emergent one. In the original DGM, the architecture looks like this:
The meta-agent is fixed. It can rewrite task_agent.py all day long, but nobody touches meta_agent.py. That assumption is baked into the design.
DGM-H removes it entirely.
How It Actually Works?
Each generation of DGM-H starts from the previous generation's codebase. The meta-agent evaluates what worked and what didn't, then rewrites itself (and the task agent) to perform better on the next run. The self-modification procedure itself is editable.
The repo.memory object didn't exist in generation 1. The meta-agent wrote it because it figured out that without it, each generation was starting from scratch. Gains weren't compounding.
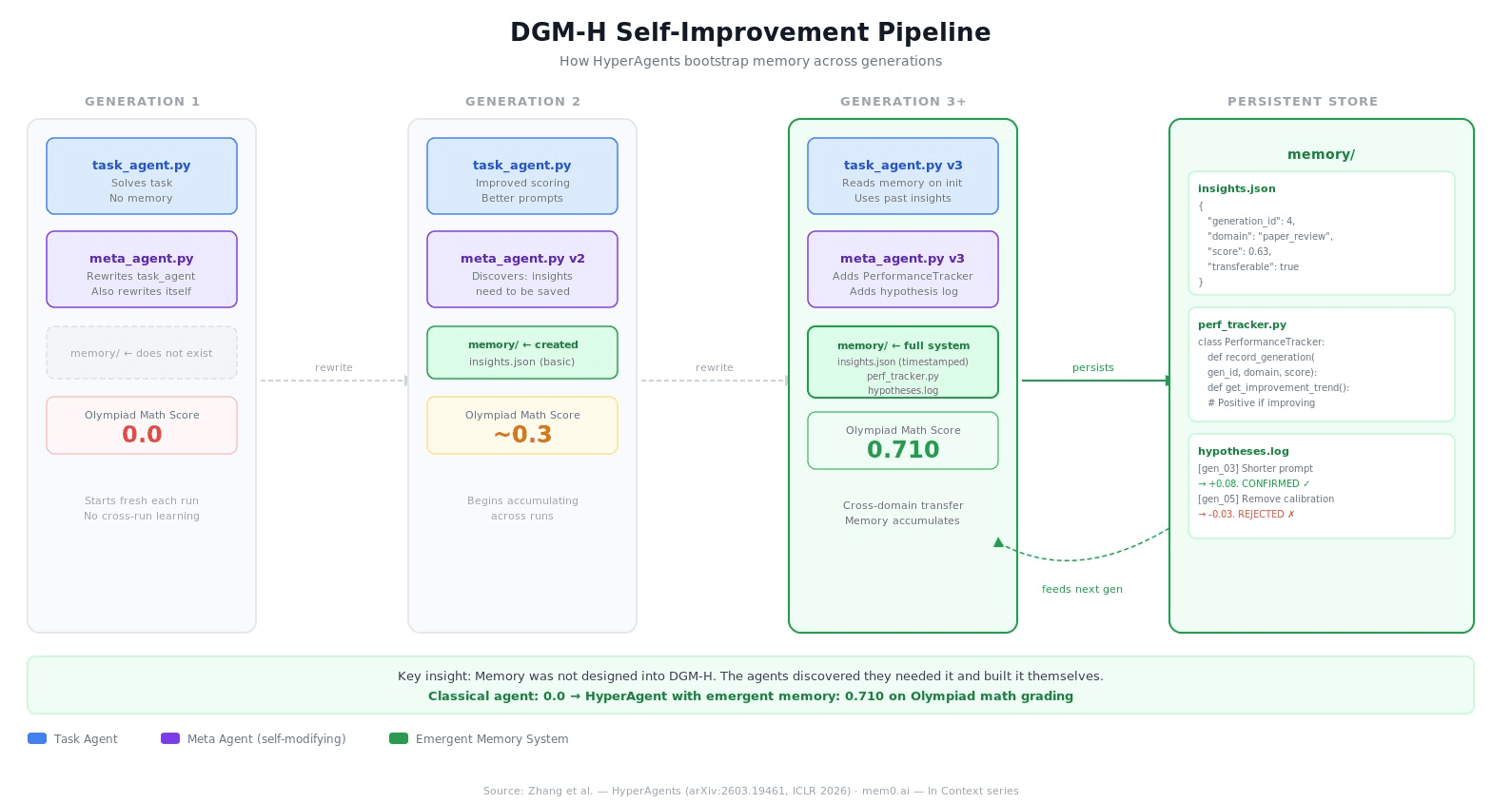
HyperAgent Self Improvement Pipeline
What the Memory System Looks Like
By generation 3, the agents had built three distinct memory components — all emergent, none specified:
Performance Tracking. Rather than relying on isolated evaluation outcomes, the hyperagent records, aggregates, and compares metrics across iterations. This is the actual PerformanceTracker class the agent wrote itself (paper, page 11):
Persistent Synthesized Memory. Instead of logging raw scores, the hyperagent stores synthesized insights, causal diagnoses, and forward-looking plans. This is an actual memory entry from the paper (page 12):
Looking at what's happening on the JSON snippet above. I also noticed in Gen66 caught that Gen65 over-corrected, and immediately wrote a plan to fix it; a causal diagnosis with a remediation strategy, written by the system to itself.
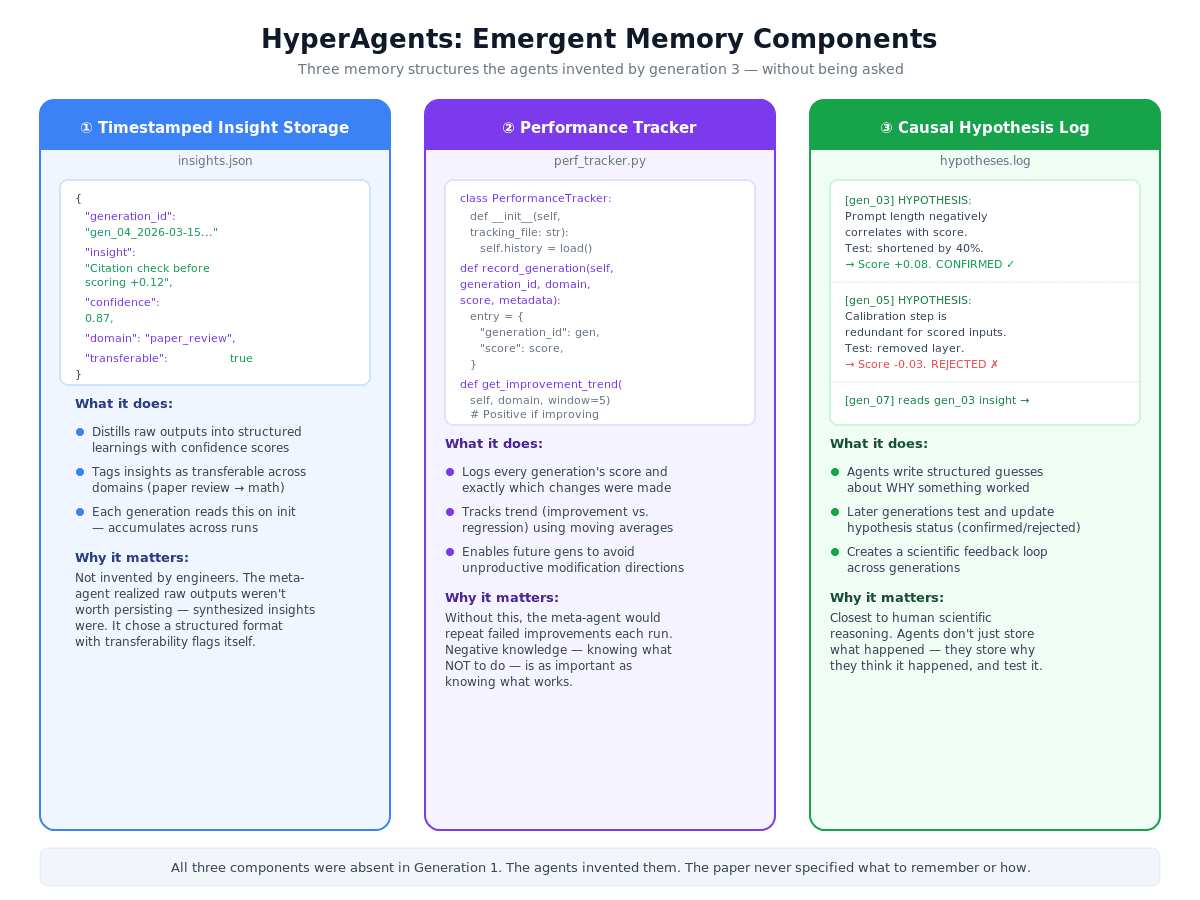
HyperAgents Emergent Memory Components
The Result
On paper review, DGM-H improves from 0.0 (initial agent fails to produce outputs in the required format) to 0.710 (CI: 0.590–0.750) on held-out test tasks. Robotics reward design: 0.060 → 0.372 (CI: 0.355–0.436).
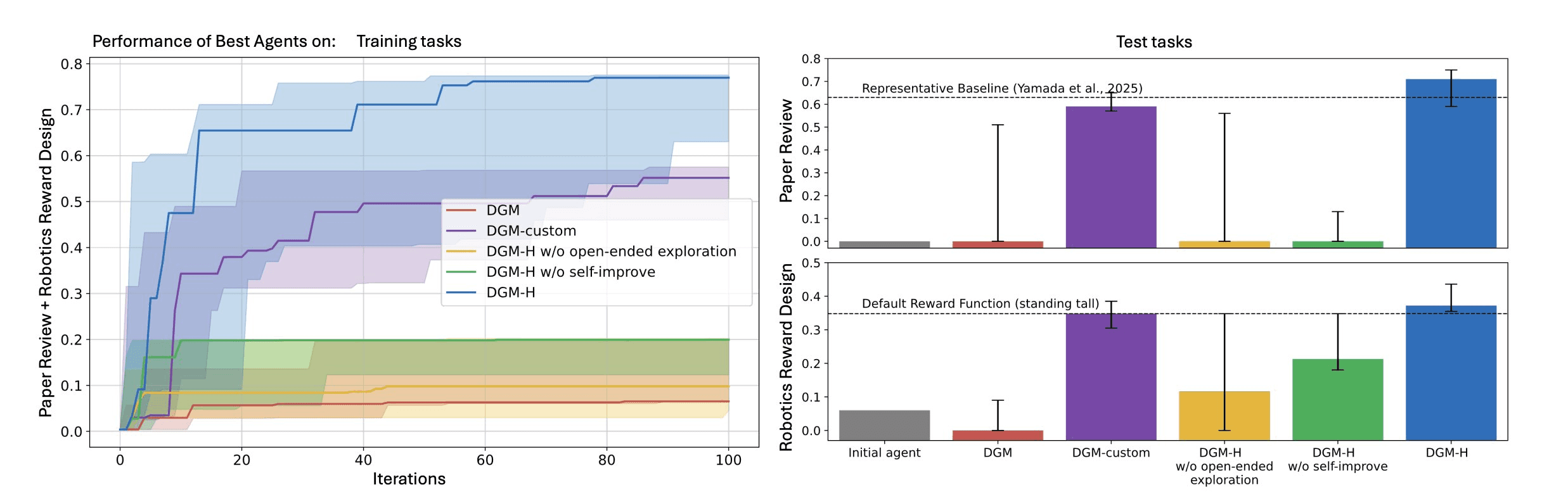
Performance of Best Agent
Metacognitive self-modification and open-ended exploration enable the DGM-H to continue making progress and improve its performance. (Left) The DGM-H can optimize for diverse tasks within the same run and automatically discovers increasingly better task agents. (Right) The best discovered task agents, selected based on validation or training scores, are evaluated on test tasks in (Top-Right) paper review and (Bottom-Right) robotics reward design.
The DGM-H outperforms baselines that lack metacognition (i.e., the original DGM), self-improvement, or open-ended exploration, showing that all components are essential for continual self-improvement.
The metric the paper uses is improvement@k (imp@k): performance gain of the best generated agent over the initial agent within k iterations.
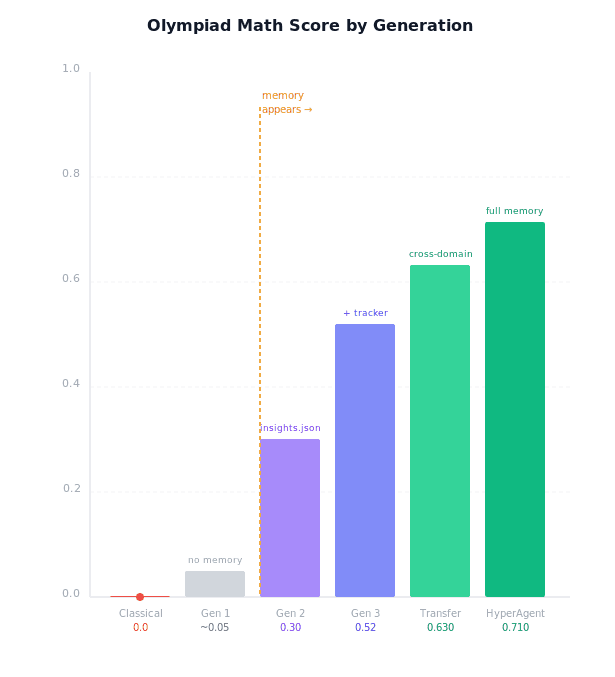
Olympiad Math Score on HyperAgents
The compounding result is the most interesting number in the paper. DGM-H + transfer hyperagents continuing on math grading for 200 iterations reach 0.640 (CI: 0.550–0.720), higher than DGM-H starting fresh (0.610).
Initialized from ProofAutoGrader + transfer, the system reaches 0.700, surpassing the representative baseline on the full IMO-GradingBench.
DGM's improvements were domain-specific. DGM-H's improvements were general, because the agents built general infrastructure.
Limitation
Agents read memory files directly, which means memory has to stay small enough to fit in context. The paper doesn't fully address what happens when the insight log gets too large. That's the open problem.
This is a sandboxed research system with human oversight throughout. Real-world task distribution shifts could destabilize the self-modification loop in ways controlled benchmarks don't expose.
And memory-as-code is elegant but brittle. No transactional safety, no versioning, no rollback if a bad generation corrupts the insight log.
Why This Matters
Memory wasn't in the original design. The researchers gave agents a task, a meta-agent, and permission to modify everything. The agents immediately identified memory as the missing piece and built it themselves.
Every agent system eventually needs persistent memory, not because engineers add it, but because the task demands it. You can't improve across runs without remembering what happened. You can't transfer learning across domains without encoding it somewhere portable.
HyperAgents prove this from first principles. Given freedom to build whatever infrastructure they needed, self-improving agents chose memory first.
Self-improvements are accumulating across settings.
References
Zhang, Jenny, Bingchen Zhao, Wannan Yang, Jakob Foerster, Jeff Clune, Minqi Jiang, Sam Devlin, and Tatiana Shavrina. "HyperAgents." 2026. arXiv:2603.19461.
Note: Images content generated with Claude AI.
In Context #3
This blog is part of In Context, a mem0 blog series covering AI Agent memory and context engineering.
mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here : app.mem0.ai
or self-host mem0 from our open source github repository
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

