



Production AI agents do not fail on model quality first. They fail on memory.
Stateless prompts work for chatbots and demos. Agents that book travel, triage support tickets, run workflows, or operate in user accounts must remember past interactions, preferences, and system context across calls and sessions. Most open-source agent frameworks expose tools and planners, yet leave memory as a vague vector-store abstraction or an in-context hack.
This post describes how open-source AI agents with built-in memory actually work, why memory becomes the bottleneck at scale, and how Mem0 fills that gap as a dedicated, open-source memory layer. The focus is practical, for engineers building production agents that need persistence, personalization, and auditing.
What open source AI agents with memory really are
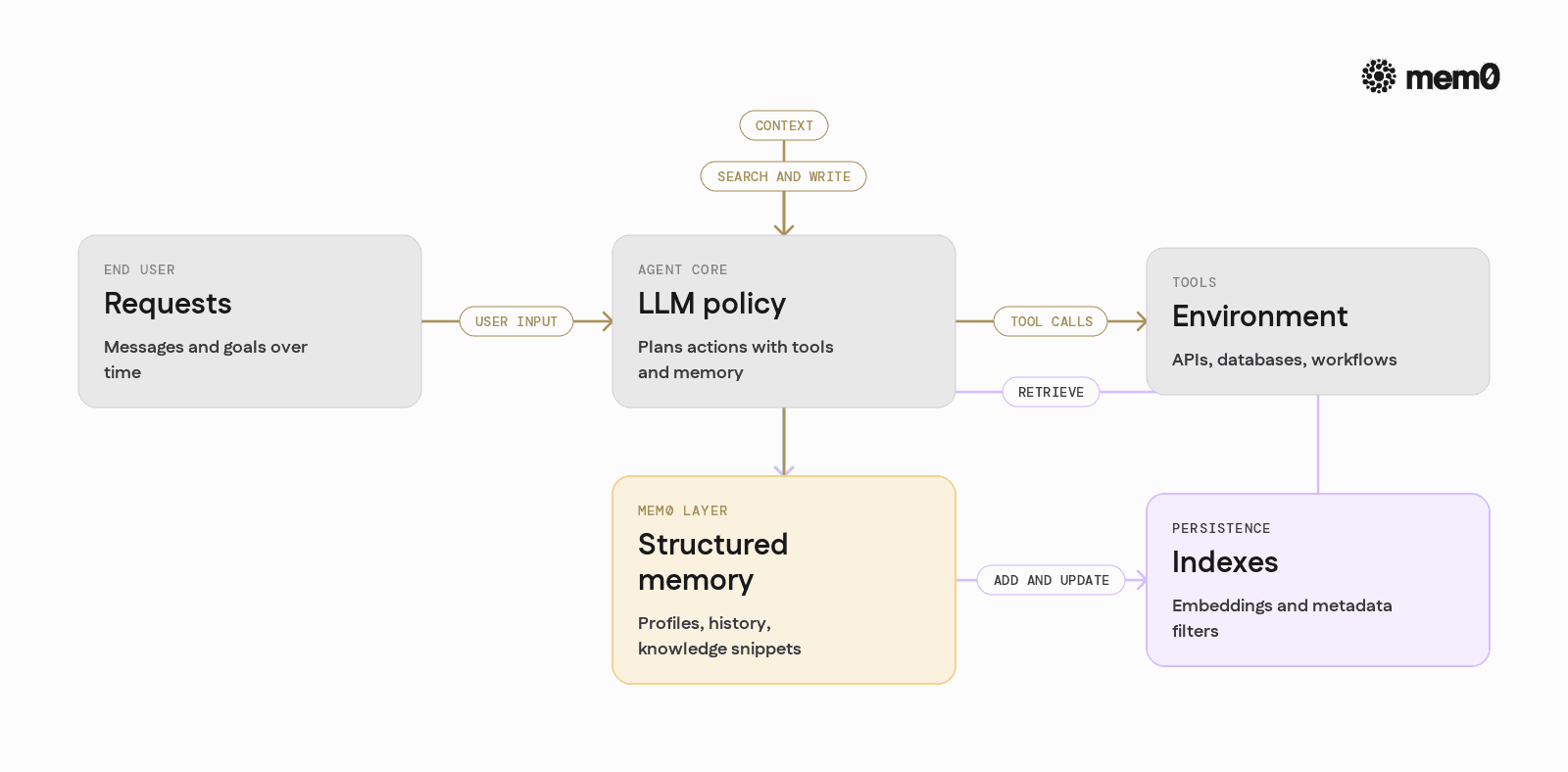
An "AI agent with memory" is just an LLM that can:
Observe events and states over time
Write a subset of those into persistent storage
Retrieve and compress relevant pieces when planning the next action
Open source agents typically expose three layers:
LLM policy: The model that decides what to do next, usually via a ReAct or tool-calling loop.
Tooling and environment: HTTP clients, databases, file systems, workflow engines, calendars, etc.
Memory and context management: Stores user preferences, goals, past tool calls, and environmental facts.
The first two layers rely on standard frameworks and APIs. The third is where systems diverge. Some projects:
Stuff the last N messages into the prompt
Store everything in a generic vector database
Hand-roll JSON files or SQL tables
These strategies can work in prototypes. They break when agents must run for weeks, serve many users, or pass audits.
An "agent with built-in memory" really means that memory is treated as a first-class part of the agent API. The agent can say "save this," "recall that," or "update the profile" using structured calls, not manual indexing.
Why naive memory approaches fail in production agents
Most issues appear only once the agent operates in a real environment with real users. Common patterns:
Full history in the prompt
Cheap and simple, but context length is limited.
Costs increase quadratically as tokens grow.
The model starts ignoring early messages.
Raw transcript embeddings
Every message becomes a vector.
Retrieval returns near-duplicates and irrelevant noise.
The model must re-interpret low-level events with every query.
Ad-hoc key-value stores
Developers manually decide which pieces to store.
No consistent schema or cross-agent reuse.
Hard to migrate, audit, or share across applications.
In production, these choices cause concrete issues:
User preferences are dropped randomly when context resets.
Agents re-ask for data already given, which frustrates users.
Personalized behavior works in one environment but not across channels.
Memory leakage across users or tenants due to poor isolation.
Difficulty explaining why the agent did something.
The underlying problem is not the lack of a vector database. It is the lack of a well-defined memory model and lifecycle.
What a memory layer must do for open source agents?
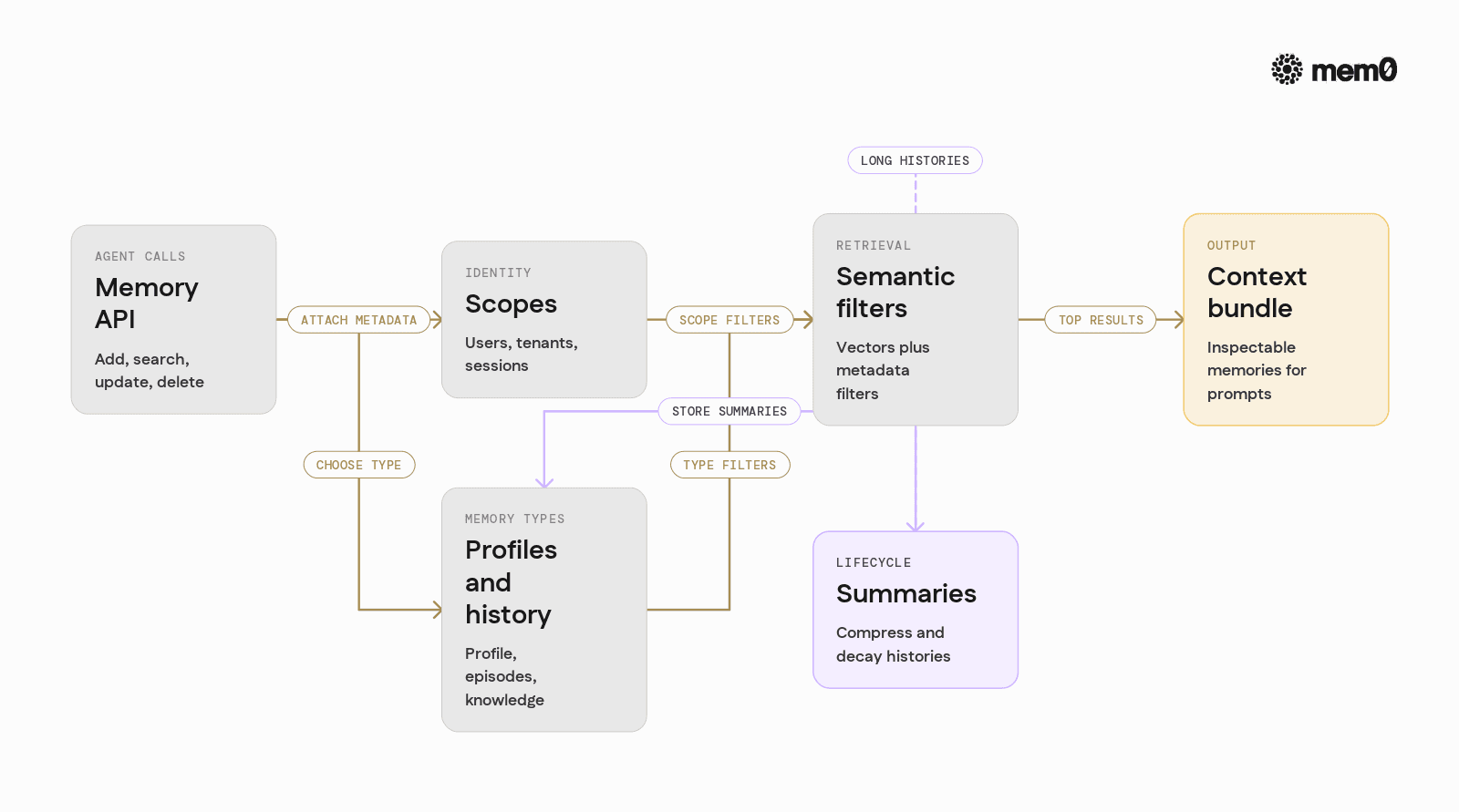
A practical memory layer for production agents must provide:
Identity and multi-tenant isolation
Each agent run should map to a user, organization, or session identity. Memory operations must be scoped to that identity.Structured memory types
Distinguish between:Long-term profile (preferences, constraints, stable facts)
Episodic history (sessions, tool calls, events)
Knowledge snippets (derived facts, summaries, decisions)
Semantic and symbolic retrieval
Retrieval should mix:Vector similarity
Filters on attributes such as user, object type, time
Optional tags such as "billing", "support", "devops"
Automatic summarization and decay
Long histories must be compressed into higher-level memories. Old or low-value items need decay or archival.Explainability hooks
It should be possible to inspect what was retrieved and why, for debugging and audits.Framework-agnostic integration
The same memory layer should serve multiple agent frameworks and runtimes, not be tied to one orchestrator.
Mem0 was built to satisfy this layer, not to create a new agent framework. It treats memory as its own system with clear APIs and behavior.
How Mem0 models memory for agents
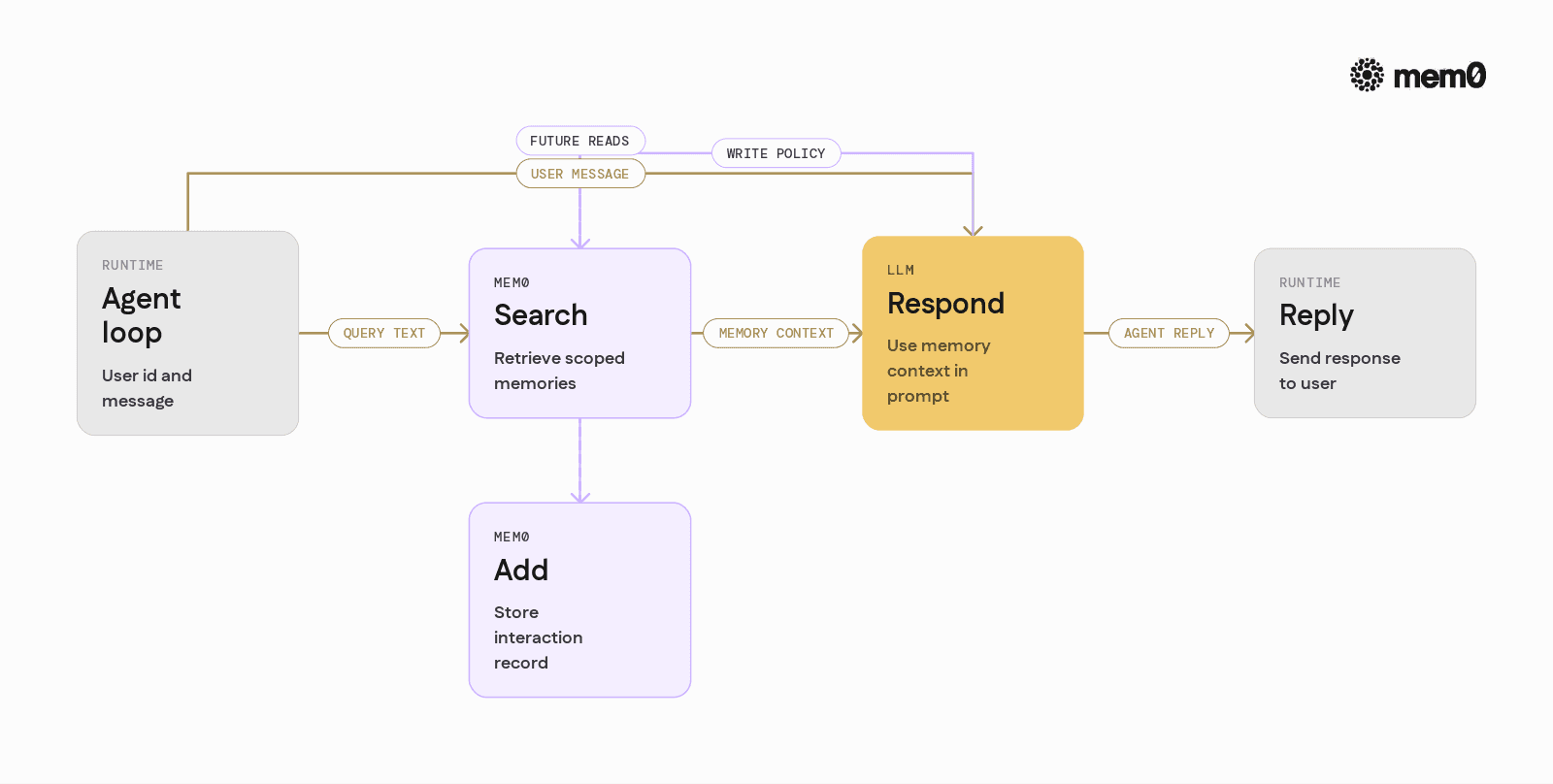
Mem0 is an open-source memory layer that wraps retrieval, summarization, and persistence in a model-driven yet framework-agnostic API. From the agent's perspective, there are three core operations:
add: persist new memoriessearch: retrieve relevant memoriesupdateanddelete: maintain and refine existing entries
Each memory item has:
A
contentfield with natural language textA
metadataobject with identity, type, tags, and arbitrary keysInternally, embeddings and indexes optimized for retrieval
Mem0 separates the agent reasoning from the memory plumbing:
The LLM decides that something is worth remembering.
The agent calls Mem0 with
addand suitable metadata.Later, the agent calls
searchwith a query and identity information.Mem0 returns concise, filtered context suitable for the prompt.
This pattern works whether the agent is a single ReAct loop, a tool-using planner, or a hierarchical multi-agent system.
Basic Mem0 Python integration
The snippet below shows how to add Mem0 to an existing Python-based agent loop:
💡Get the Mem0 API key and OpenAI API Key to follow along
This example is intentionally minimal. In practice, the memory schema and write policy are critical, and Mem0 provides the primitives to implement them.
Memory patterns for production agents
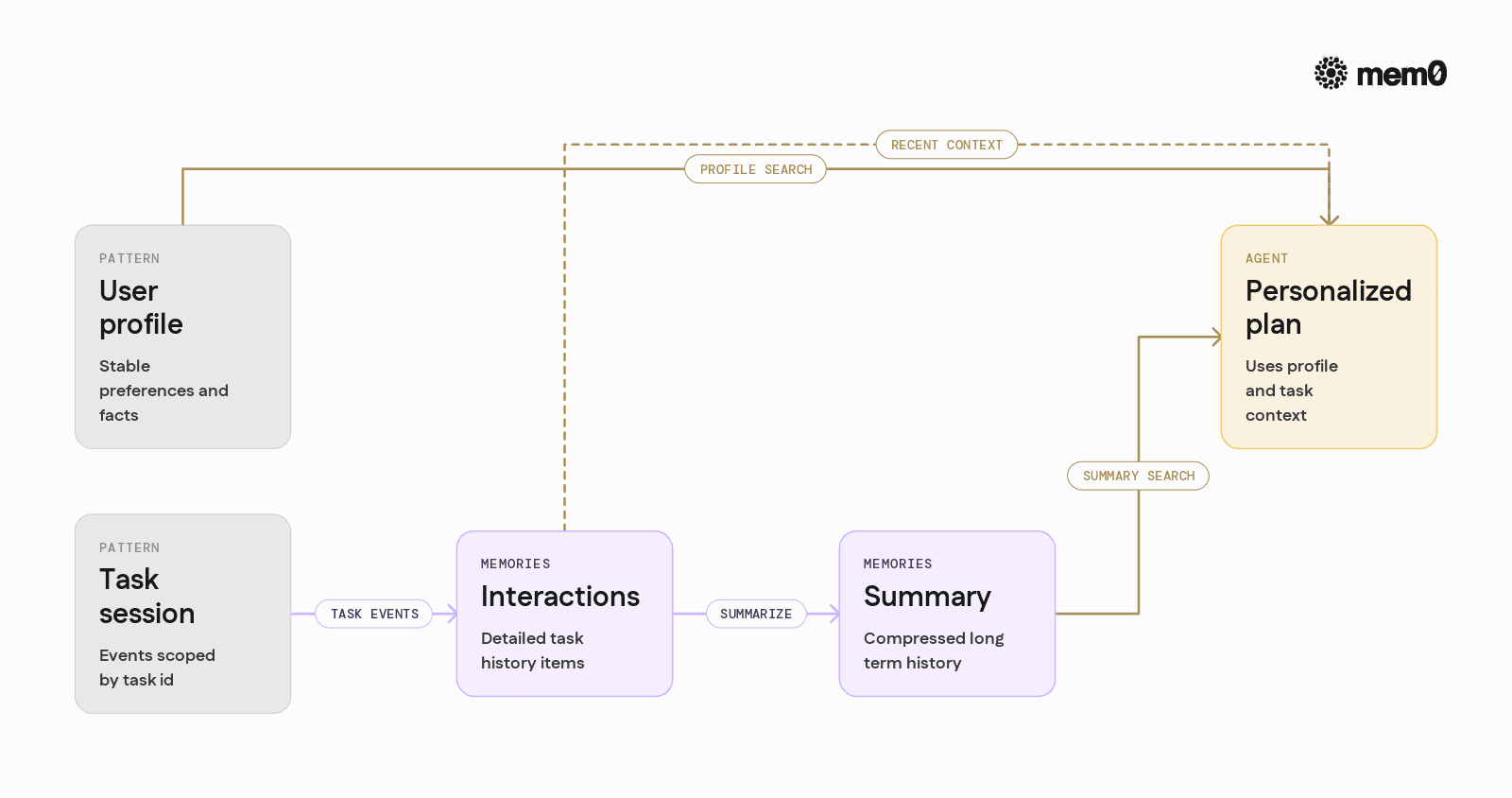
Different agent types call for different memory patterns. Mem0 can support several with the same API.
1. User profile memory
Store durable preferences and static facts about each user.
Example entries:
"User prefers flights with at least one checked bag included."
"User is located in Berlin and works in CET."
"User uses Terraform for infrastructure."
These entries change rarely and should be retrieved whenever the agent plans high-level actions for that user.
2. Task and session memory
Tasks like incident triage, fraud investigation, or multi-step automation need session-scoped memory.
Example entries:
"Incident #4271 was escalated to on-call engineer at 09:32 UTC."
"For support ticket 8912, user confirmed the bug is reproducible."
These can use a task_id or session_id in metadata to isolate histories.
3. Derived knowledge and summaries
For long-running users or tasks, raw events become too large. In that case the agent can periodically summarize histories and store the summary as a higher-level memory, then mark older events as archived or lower priority.
Mem0 does not dictate when or how to summarize, which allows fine-grained control per application.
Comparison of memory strategies in open source agents
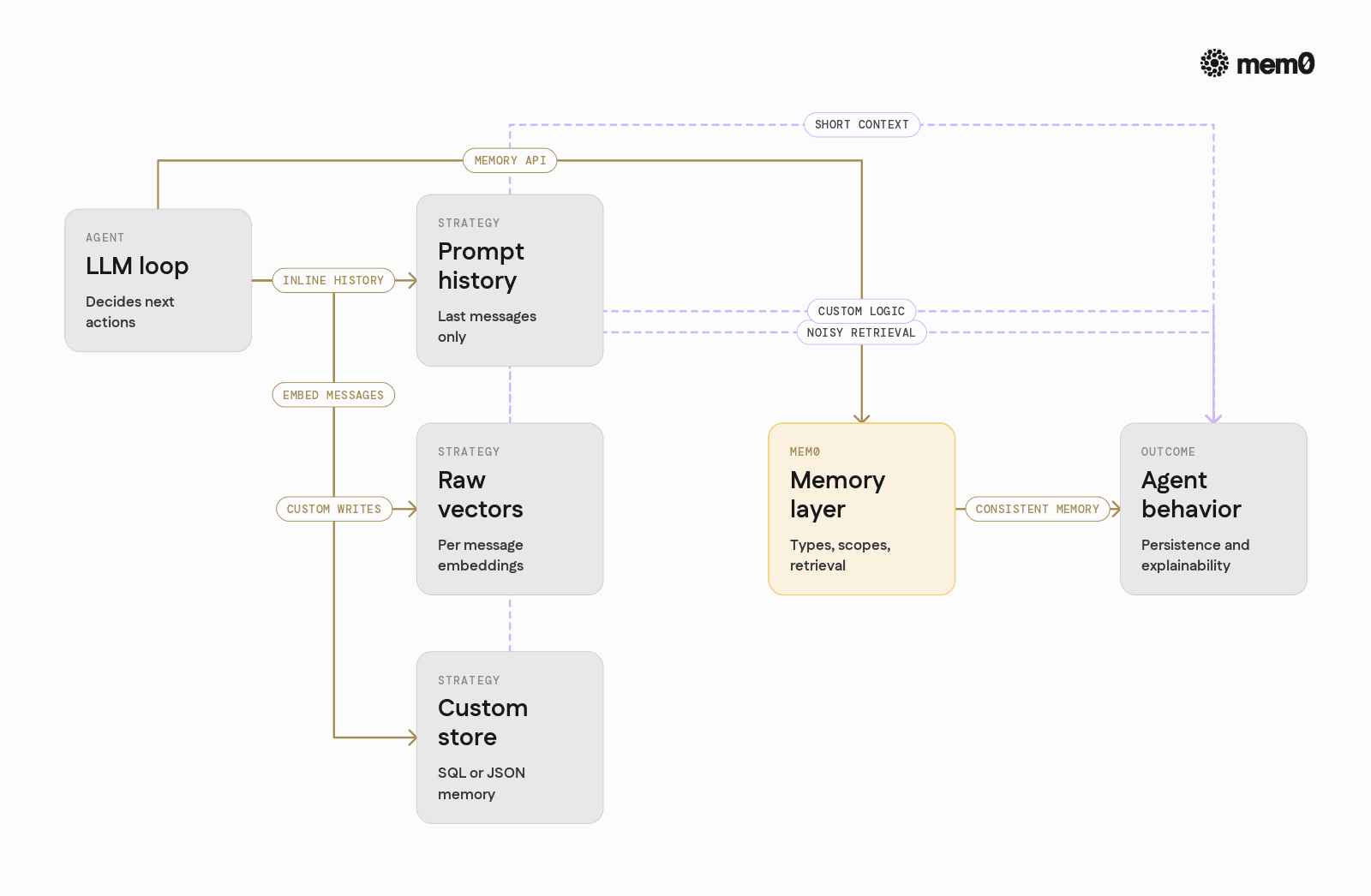
The table below contrasts common memory approaches for open source agents with a dedicated memory layer such as Mem0.
Aspect | No memory, only prompt history | Raw vector DB per message | Custom SQL/JSON memory | Mem0-style memory layer |
|---|---|---|---|---|
Cross-session persistence | No | Yes | Yes | Yes |
Control over memory types | None | Minimal (all entries similar) | High but manual | Built-in via metadata and schemas |
Retrieval quality | Limited to last N turns | Semantic, but noisy and redundant | Depends on custom queries | Semantic plus structured filters |
Long-term summarization | Manual via ad-hoc prompts | Rarely implemented in a consistent way | Custom logic per project | Encouraged pattern with shared primitives |
Multi-tenant isolation | N/A | Possible but fragile | Possible, requires discipline | First-class via metadata scopes |
Ecosystem and composability | Framework-specific | DB/vendor-specific | Application-specific | Framework-agnostic memory API |
Auditability of decisions | Hard as history is partial | Hard as retrieval is opaque | Possible with extra work | Easier via inspectable memory records |
Dev effort for new agents | Low for prototypes, high for production | Medium plus tuning | High, repeated per project | Medium, reusable across agents |
The key distinction is that Mem0 treats memory as a reusable component with clear semantics, not just a storage primitive.
Incorporating Mem0 into existing open source agent frameworks
Mem0 does not replace existing agent frameworks. Instead, it fills the gap where frameworks tend to offer only basic memory or tie memory deeply into their internals.
A typical integration involves three steps:
Define identity and metadata strategy: Decide how to map user IDs, tenants, projects, and tasks. Keep metadata consistent across all Mem0 calls.
Wrap Mem0 in your agent abstraction: Create a small adapter that manages
add,search, and optionalupdateanddeleteoperations in the context of the agent lifecycle.Adjust prompts to use memory context explicitly: Add a dedicated memory section in system prompts, and instruct the LLM to rely on that context for personalization and continuity.
Example adapter layer:
This wrapper can then be injected into any agent class or function, independent of the agent framework.
Operational and security considerations
Production agents require more than API ergonomics. Memory introduces data, access, and lifecycle concerns.
Key points when using Mem0 in a real deployment:
Data residency and self-hosting: Mem0 is open source and can be self-hosted, which allows data to remain within a VPC or specific region.
Access control and tenancy: The combination of infrastructure isolation and Mem0 metadata (for
user_id,tenant_id, etc.) should enforce both physical and logical separation of memories.PII and retention policies: Projects that handle PII should implement retention and deletion workflows. Mem0's
deleteAPI and metadata filters support targeted cleanup.Observability and debugging: Inspecting what memories are retrieved for a given query can explain agent actions and help tune memory filters or schemas.
Schema evolution: Over time, metadata schemas evolve. Using versioned keys (for example,
"schema_version": 1) can help distinguish older entries from newer ones.
Mem0 aims to provide the building blocks, while operational discipline remains the responsibility of the engineering team.
Limitations of built-in memory for open source agents
Even with a dedicated memory layer, several limitations remain:
Model interpretation errors: The LLM might misinterpret retrieved memories or ignore them entirely. Memory only increases the chance of consistent behavior; it does not guarantee it.
Selection and write policy quality: If the agent saves too much, retrieval becomes noisy. If it saves too little, important context is lost. Designing good write policies often requires iteration, domain knowledge, and evaluation.
Long-horizon reasoning: Complex processes that span months, with changing goals and participants, remain challenging. Summaries can lose nuance, and the model might fail to connect distant events even when memories exist.
Latency and cost: Every memory search and write is an extra operation. On high-traffic systems, the cumulative cost and latency matter, and optimization or caching strategies may be required.
Schema drift and versioning: As applications evolve, memory schemas and usage patterns change. Keeping backward compatibility and avoiding inconsistent metadata requires explicit design.
Mem0 can help manage these challenges, but cannot remove them entirely. Memory remains an architectural and product concern as much as an infrastructure one.
Frequently Asked Questions
Q. What is the main advantage of using a dedicated memory layer for open source agents?
A dedicated memory layer separates reasoning from persistence and retrieval. This leads to more consistent personalization, easier debugging, and reuse of memory across multiple agents and applications.
Q. How does Mem0 differ from just using a vector database directly?
A vector database stores embeddings, while Mem0 provides a higher-level abstraction around identities, memory types, retrieval strategies, and integration patterns. It focuses on the semantics of memory for agents rather than on raw vector operations.
Q. When should an AI engineer introduce Mem0 into an agent architecture?
Mem0 becomes useful once agents need cross-session persistence, multi-user support, or consistent personalization rules. For quick prototypes with short interactions, in-context history might suffice, but Mem0 helps significantly once behavior must be stable and auditable.
Q. How does Mem0 handle multi-tenant or multi-user isolation?
Mem0 relies on metadata such as user_id or tenant_id to scope memories and retrievals. Combined with infrastructure isolation or self-hosting, this supports clear separation of data between users and tenants.
Q. What types of memory are most important for production agents?
Long-term user profile memory and task or session memory are usually most critical. Derived summaries and knowledge snippets add value as histories grow and raw transcripts become too large to retrieve directly.
Q. Why can agents with built-in memory still behave unpredictably?
Memory increases the information available to the model but does not control the model's internal reasoning. Prompt design, tool configuration, and model choice still influence behavior, and memory cannot fully prevent occasional mistakes or inconsistencies.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

