



LangChain is the most widely used open-source framework for building LLM applications.
It started in late 2022 as a thin wrapper around prompt templates and chains. Today it is a sprawling ecosystem covering retrieval, agents, tools, and an expression language (LCEL) that turns chains into composable pipelines.
Most production LangChain code runs through langchain-core for primitives and a provider package like langchain-openai or langchain-anthropic for the model layer.
The framework's reach is the reason memory matters here. A LangChain app rarely lives in isolation. It is piped into a Slack bot, a customer support agent, a coding assistant, or a long-running research workflow. Each of those needs memory the framework's defaults were never built to provide.
How LangChain handles memory natively
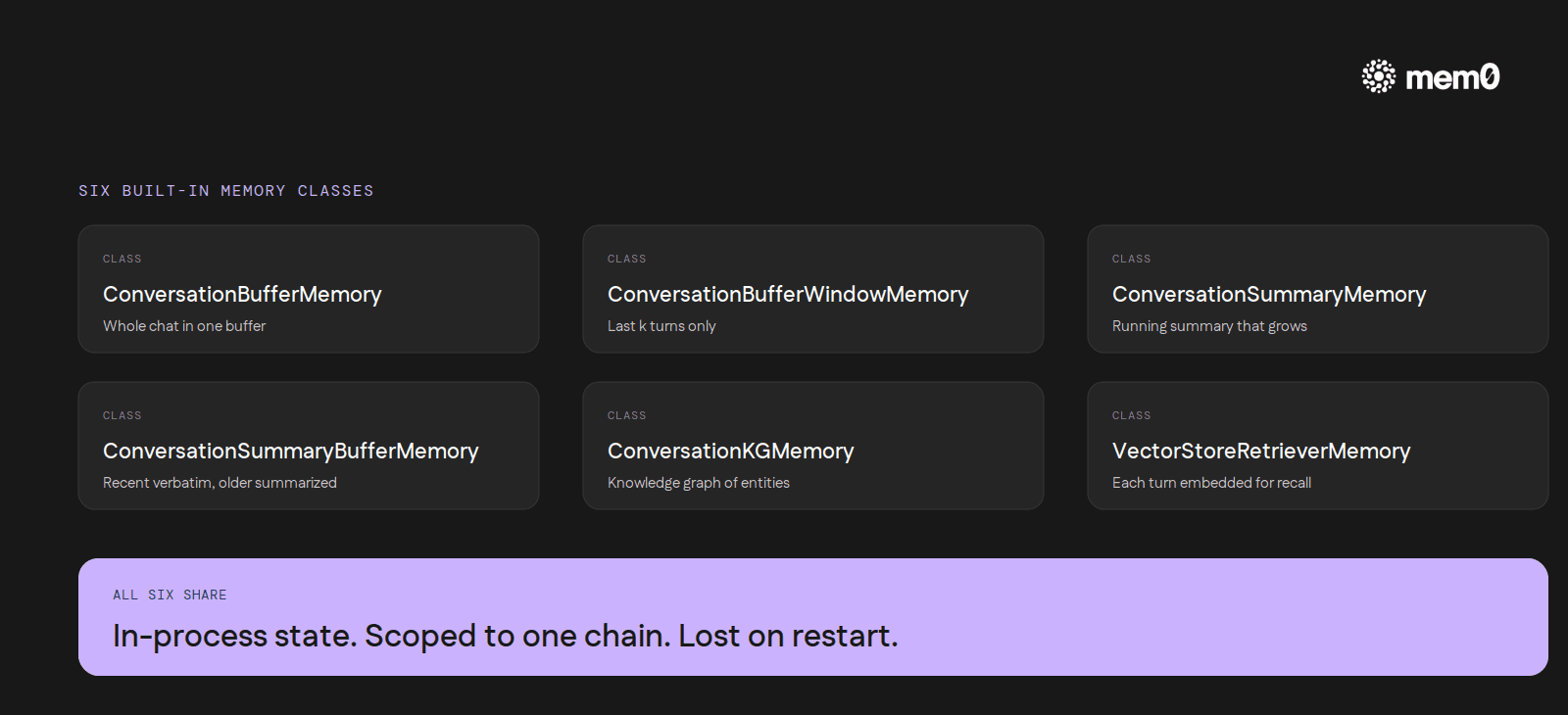
The classic LangChain memory abstraction is the Memory class, exposed in six flavors:
ConversationBufferMemorykeeps the entire chat in a single buffer and pastes it into the prompt every turn.ConversationBufferWindowMemorydoes the same, capped to the lastkturns.ConversationSummaryMemoryreplaces the buffer with a running summary that grows as the chat grows.ConversationSummaryBufferMemoryis a hybrid. Recent turns sit in the buffer verbatim, older turns get summarized.ConversationKGMemorybuilds a NetworkX knowledge graph of mentioned entities and surfaces only the relevant nodes back into the prompt.VectorStoreRetrieverMemorystores every interaction as an embedding and retrieves the closest matches each turn.
Each one exposes a save_context method that captures the current input/output pair and a load_memory_variables method the chain calls to assemble the next prompt. Modern LCEL code increasingly uses RunnableWithMessageHistory and a BaseChatMessageHistory backend (Redis, Postgres, DynamoDB) instead of the legacy classes, but the underlying shape is the same.
The design choice across all of them is shared. Memory is in-process state, scoped to a single chain instance, lost the moment that instance is garbage collected. The contrib packages that back history with Redis or Postgres store messages, not facts. Replaying every prior message is not the same as remembering what matters.
Where LangChain's built-in memory stops
The built-in classes are well-shaped for one specific case: a single short-lived conversation that fits in one buffer, on one process, on one machine. Step outside that shape and the cracks show.
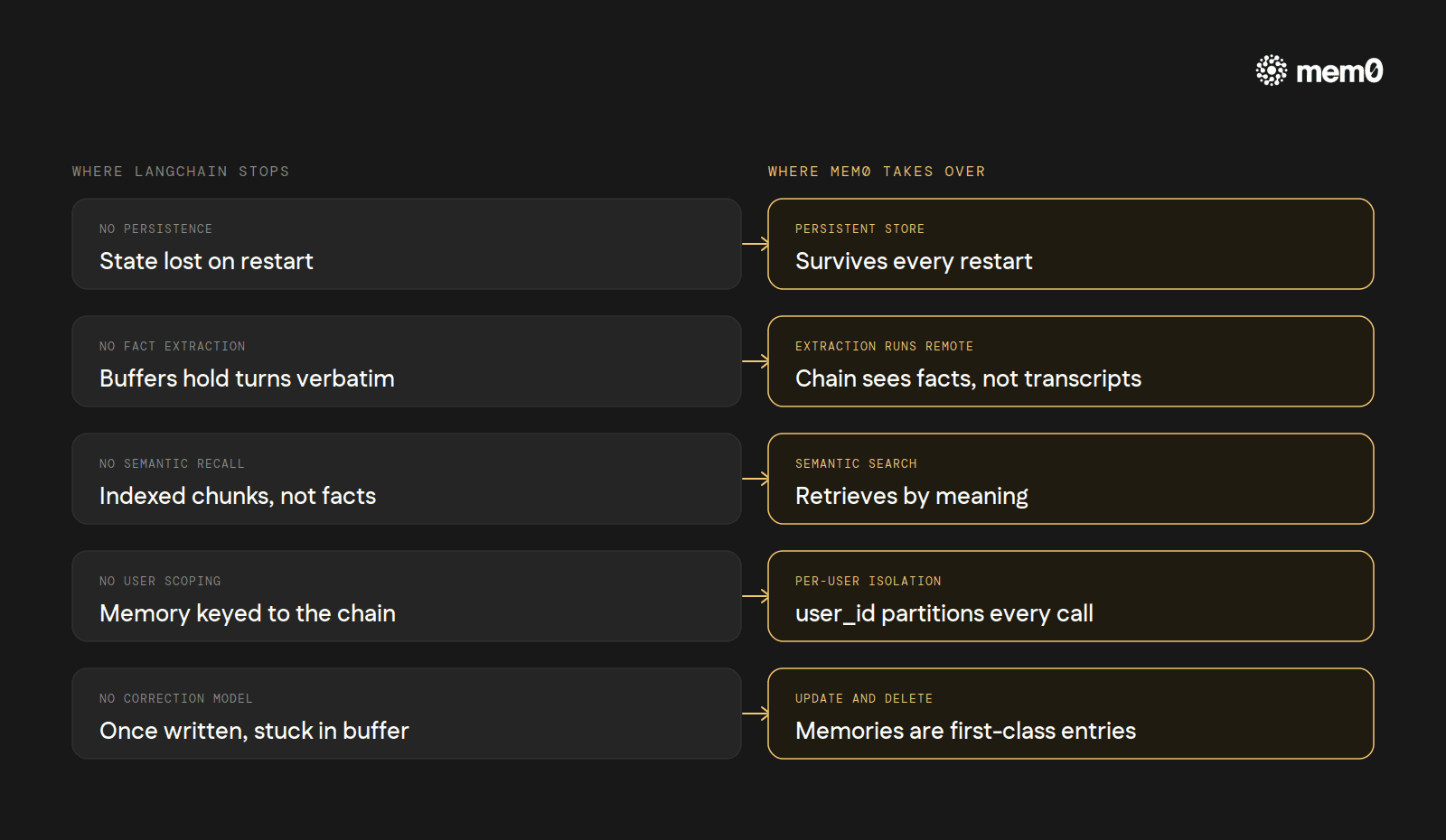
No persistence by default. Restart the worker and every memory class above resets. The chat-history backends only persist raw messages.
No fact extraction. The buffer classes hold turns verbatim. The summary classes compress, but compression is lossy and the summary is opaque to the application.
No semantic recall across sessions.
VectorStoreRetrieverMemoryis the closest thing, but it indexes message chunks, not extracted facts. It has no notion of who said something or when it was said.No per-user isolation. Memory is keyed to the chain, not the user. Three Slack users hitting the same bot means three conversations bleeding into one buffer unless the application threads
session_idthrough manually.No update or correction model. Once a turn is in the buffer, it is there. If the user says, "actually, ignore what I said earlier," the agent has to learn to ignore it inside the prompt every turn for the rest of the session.
These are exactly the cases external memory providers address. Mem0 is the integration LangChain points to in its own docs as the long-term solution. The surface area is small enough to wire in inside an afternoon.
How to add Mem0 to LangChain
The full setup is documented at docs.mem0.ai/integrations/langchain.
The install is one line:
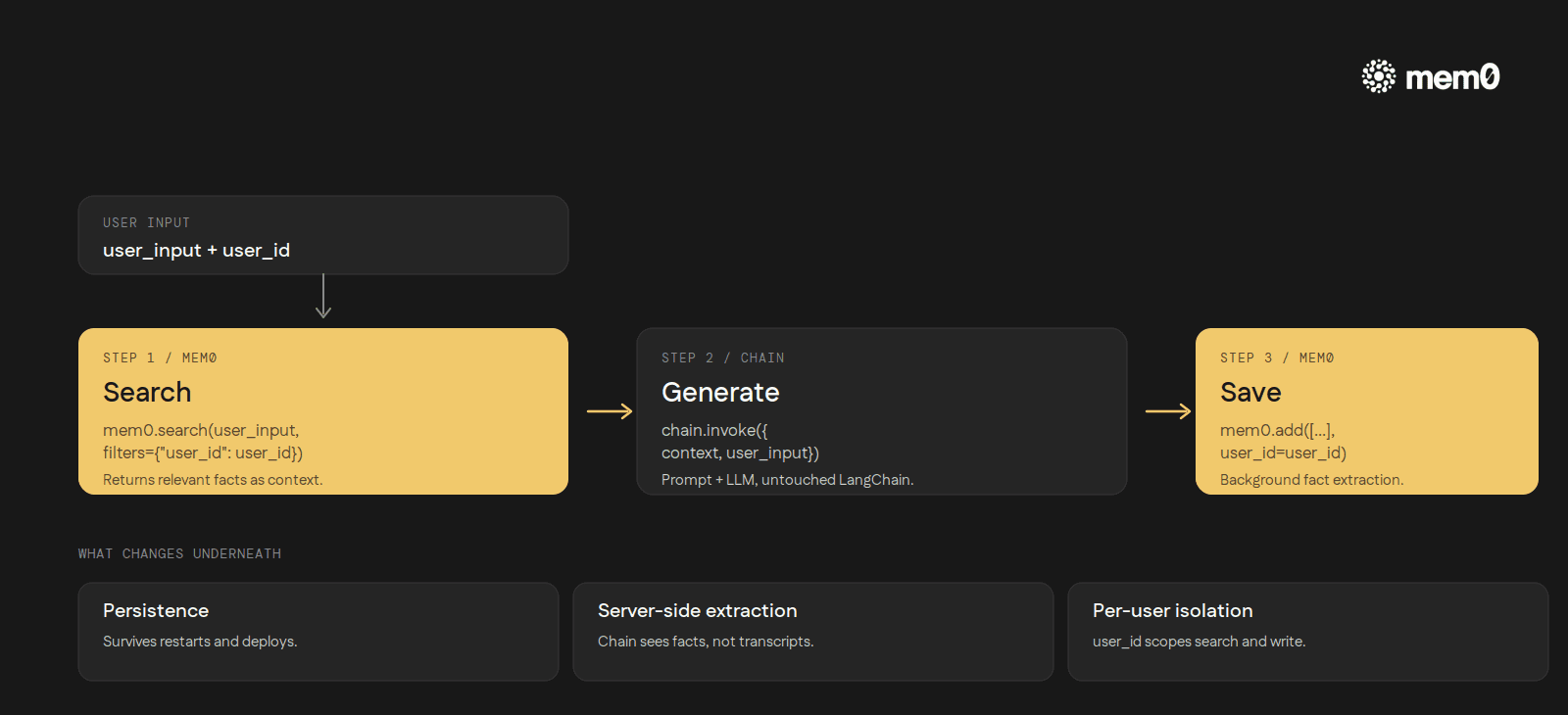
The integration leans on two MemoryClient methods: search to retrieve relevant memories before generation, and add to store the user/assistant exchange after it. Wiring is intentionally minimal:
A turn becomes three steps: retrieve, generate, save.
Three things change underneath the chain:
Persistence is automatic. Memory survives process restarts, deploys, redeploys, and machine swaps. The store is Mem0's, not the chain's.
Fact extraction runs server-side. The
addcall ships the exchange to Mem0. An extraction model decides what is worth remembering. The chain does not see prompt-stuffed transcripts. It sees a short list of facts.Per-user isolation is built in. The
user_idparameter scopes every search and write. Three Slack users mean three independent stores, no manual partitioning.
The same pattern composes cleanly with LCEL. RunnablePassthrough.assign(context=...) can pull memories before the prompt step, and RunnableLambda can write them back after. Every production-shaped LangChain stack the integration was tested against (customer support bots, sales agents, RAG with personalization, long-running research workflows) maps onto the same three-step rhythm: search before generation, generate, save after.
Six built-in classes, each suited to a single in-process conversation. One Mem0 integration, a few lines of glue, persistence and per-user isolation and semantic recall added to whatever the chain already does.
The framework keeps doing what it is good at. Memory becomes the layer it was never trying to be.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

