



LlamaIndex is an open-source framework focused on connecting LLMs to private data.
The original pitch in late 2022 was a thin layer over vector indexes that turned a folder of PDFs into a queryable backend. Five years later it spans data connectors, indexing strategies, query engines, agents, workflows, and an evaluation suite.
The core import path is llama_index.core, with model and memory providers split into their own packages.
Most production LlamaIndex code runs through one of three orchestration shapes. A QueryEngine for one-shot retrieval. A ChatEngine for conversational interaction. An Agent (FunctionCallingAgent or ReActAgent) for tool use. Each of these can read from indexed data effortlessly. None of them remembers the user across a process restart unless an external memory layer is wired in.
How LlamaIndex handles memory natively
The default memory abstraction in LlamaIndex is ChatMemoryBuffer. It holds messages in process, capped by a token limit, flushed when the limit is hit. A second class, ChatSummaryMemoryBuffer, summarizes older turns once the buffer fills. A third, SimpleComposableMemory, lets developers stack multiple memory sources together: one for short-term, one for long-term.
The ChatEngine and agent classes both accept a memory argument that conforms to a BaseMemory interface. The interface exposes put, get, and reset. By default, every chat call writes to the buffer and every prompt assembly reads from it.
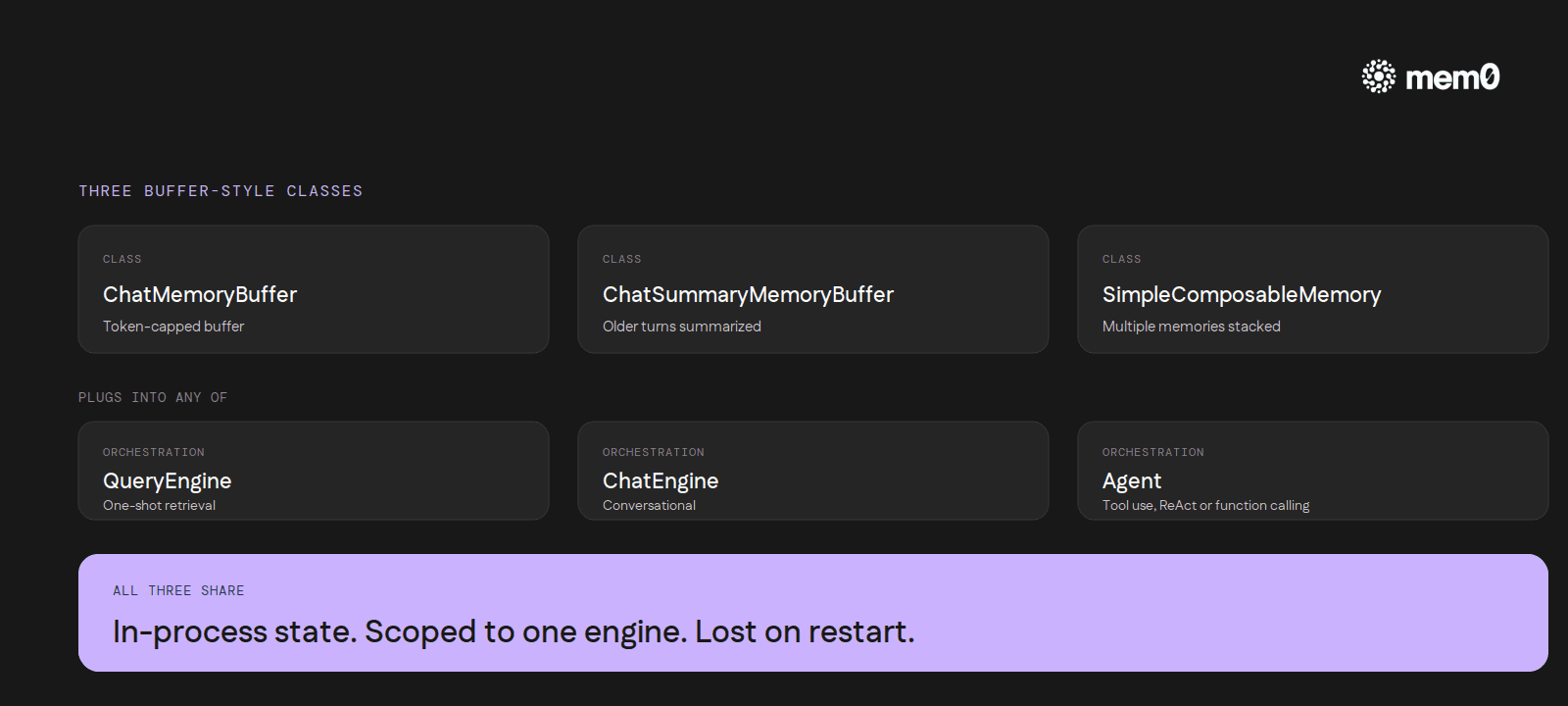
The design pattern is familiar to anyone who has worked in a web framework: in-memory state, scoped to a single object's lifetime, gone when the process ends. A handful of community projects back the buffer with Redis or DynamoDB, but they store messages, not facts. The agent still has to re-derive everything it knows about the user on every cold start.
Where the built-in memory stops
The buffer-style classes are well-shaped for a specific scenario: one user, one session, contained inside a single Python process, lasting the length of a chat window. Outside that shape the limits surface fast.
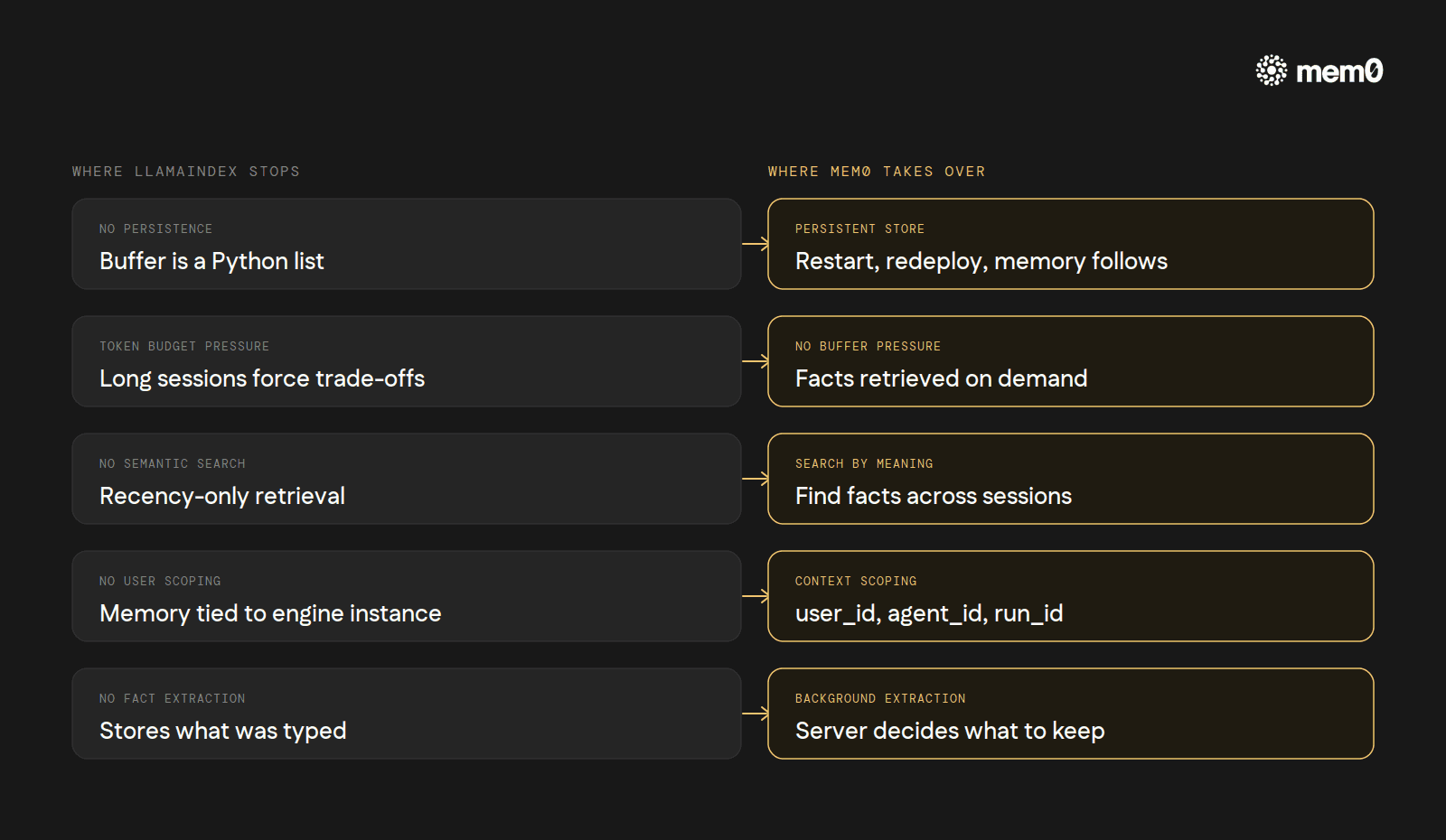
No persistence across restarts. The buffer is a Python list. The summary is a Python string. Both reset with the process.
Token-budget pressure. Every retained message takes context window space. Long sessions force a hard choice between losing detail and losing budget for the actual task.
No semantic search over history.
ChatMemoryBufferretrieves by recency, not relevance. The agent cannot ask, "what does this user prefer for testing?" and get back a stored fact from a conversation three weeks ago.No user scoping. Memory belongs to the engine instance, not to the user. A multi-tenant app needs to instantiate a fresh engine per user or risk crosstalk.
No fact extraction. What the agent stores is what the user typed. There is no compression model deciding "this is worth keeping."
Mem0 is the integration LlamaIndex documents as the path through these limits. The wiring is shorter than the list of limits.
How to add Mem0 to LlamaIndex
The full setup is documented at docs.mem0.ai/integrations/llama-index.
The install pulls the integration package alongside the core:
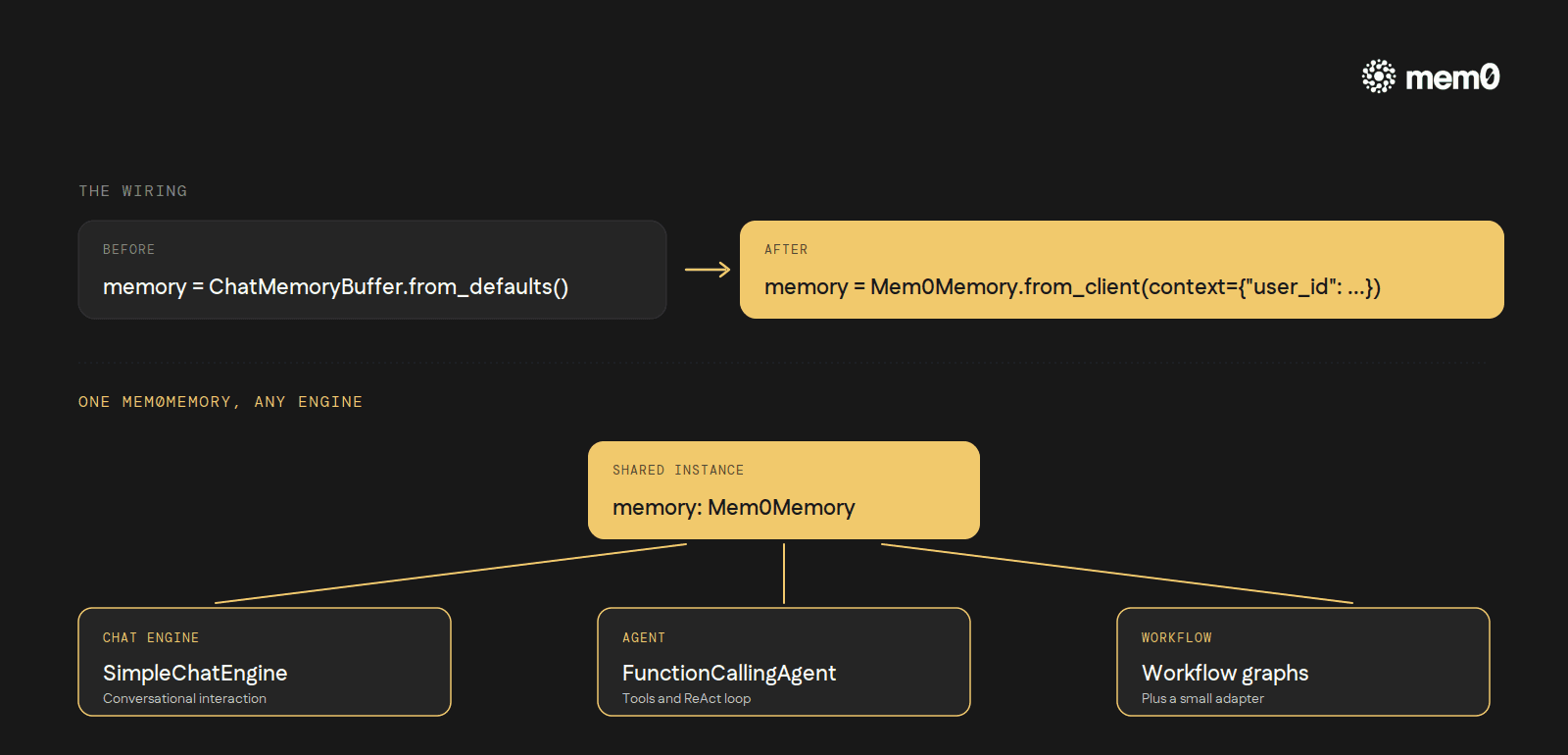
The integration plugs into the same memory slot the engine and agent classes already accept. Replace ChatMemoryBuffer with Mem0Memory:
The context dictionary is the scoping mechanism. Three valid keys: user_id, agent_id, run_id. Pass any combination. Memory written under one scope is invisible to another. search_msg_limit controls how many recent messages are folded into the retrieval query (default 5).
The same Mem0Memory instance plugs into agent runners without modification:
Two patterns the integration supports out of the box. Hosted Mem0 via Mem0Memory.from_client() uses a platform API key. Self-hosted via Mem0Memory.from_config() takes an OSS config dictionary specifying vector_store, llm, and embedder providers. The same agent code works against either backend.
What changes underneath:
Persistence is the default. The store is Mem0's database, not the engine's instance state. Restart, redeploy, or migrate, the memory follows.
Server-side fact extraction. Each turn pushes the user/assistant exchange to Mem0 in the background. The extraction model decides what to keep. The agent's prompt grows with the user's relevant history, not with the raw transcript.
Semantic retrieval across sessions. Search runs by meaning. "What does this user prefer for testing?" returns the pytest fact from session one, even if session forty-two never used the word testing.
Per-user isolation. The
user_idflowing throughcontextkeeps tenants separated without an extra layer.One backend for chat engines, agents, and workflows. The same
Mem0Memoryworks inSimpleChatEngine,FunctionCallingAgent,ReActAgent, and (with a small adapter) inWorkflowgraphs.
Three buffer-style classes, each scoped to a single in-process session. One Mem0 integration, three lines of glue, persistence and semantic recall and per-user isolation added to every engine, agent, and workflow the framework already runs.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

