



LLM API bills scale directly with tokens sent per request, and the single largest driver is almost never the model response. It is what gets sent in. Most production agents pack full conversation histories or entire document stores into every call, turning a fixed per-call cost into one that grows linearly with usage.
What Drives LLM API Costs
Input tokens dominate the billing curve for most agents. Every request to a hosted model is priced on total tokens consumed in the prompt plus the response. For GPT-4o, OpenAI has charged $2.50 per million input tokens and $10.00 per million output tokens (verify current pricing at openai.com/api/pricing as rates change). Claude Sonnet from Anthropic runs at $3.00 per million input tokens and $15.00 per million output tokens. In both cases, the output is where the rate jumps, but in practice, outputs are short. A typical assistant reply is 200-400 tokens. The prompt carrying history, system instructions, and documents is routinely 10x to 50x that size.
The cost model is straightforward: (input_tokens + output_tokens) times (price_per_token). Output tokens are bounded by what the model needs to say. Input tokens are bounded only by what the developer chooses to send, which is where the lever lives.
Context window size compounds this. GPT-4o supports 128K tokens. Claude Sonnet 4.6 supports 1M tokens. These large windows enable long-context tasks, but they also make it tempting to fill them. Every token in that window is billed, whether it influences the answer or not.
The Naive Pattern and Why It Scales Badly
The naive implementation looks like this: maintain a list of messages, append every user and assistant turn, and send the full list on every API call. It works in development where conversations are short. It fails in production where users return across sessions and conversation histories run thousands of turns.
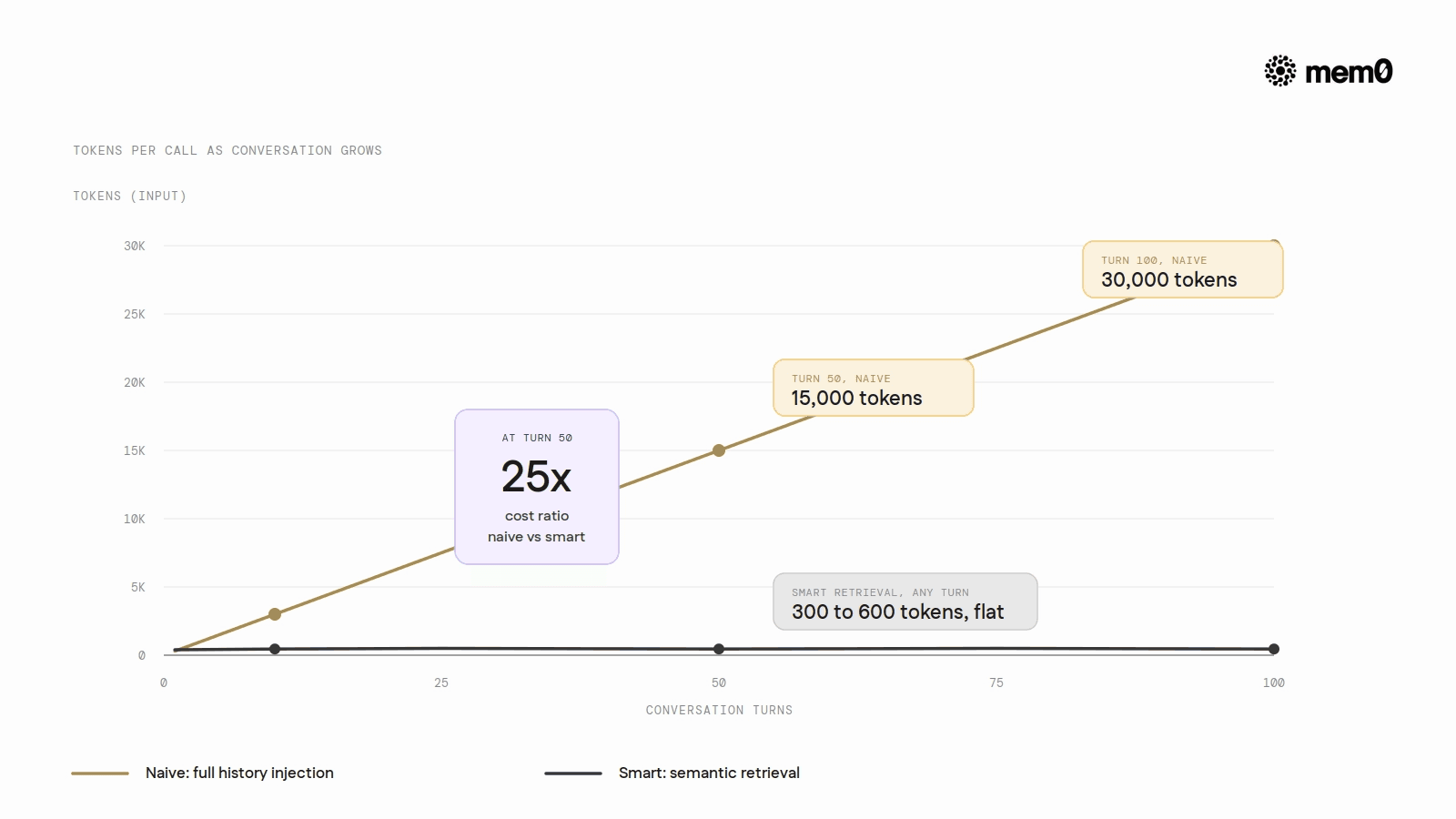
Full history injection means that the tenth message in a conversation costs roughly 10x the tokens of the first. The hundredth message costs 100x. This is linear growth in a system where the cost driver is not the intelligence of the query but the size of the payload.
A concrete example: a user interacts with a support agent 50 times over a month. Each exchange averages 300 tokens of new content. By turn 50, the agent is sending roughly 15,000 tokens of history on every call before writing a single word of its own response. At $3.00 per million input tokens (Claude Sonnet 4.6), that is $0.045 per call spent purely on accumulated history — context that is mostly irrelevant to the current query. The cost is not fixed; it grows with every turn a user has ever had.
The second failure mode is retrieval-augmented generation done naively: stuffing entire documents into the prompt instead of retrieving relevant chunks. A 50-page technical manual embedded in every support query multiplies token counts by orders of magnitude.
How Context Construction Changes the Cost Curve
Smart context construction inverts the assumption: instead of sending everything and letting the model sort it out, it retrieves only what is semantically relevant to the current query and injects that. The rest stays in storage, queryable but not billed.
The cost curve changes from O(n) per call, where n is total conversation length, to effectively O(k), where k is the fixed number of relevant memory chunks retrieved per call. If each call retrieves 3-5 memory entries averaging 50 tokens each, the memory overhead is 150-250 tokens regardless of whether the user has had 10 conversations or 10,000.
Semantic retrieval is the mechanism. A memory store indexes all past interactions as vector embeddings. When a new user message arrives, the system queries the store with that message, retrieves the top-k most relevant memories, and injects only those into the prompt. Irrelevant history from six months ago does not appear in the prompt. Only what is likely to affect the current response is included.
This pattern also improves response quality in many cases. A prompt stuffed with 15,000 tokens of history forces the model to attend across a large, noisy context. A prompt with 300 tokens of precisely relevant memories gives the model a clean signal.
Token Cost Comparison Table
The table below shows how token counts and per-call costs scale across turns under both approaches, assuming 300 tokens of new content per turn. Token counts are derivable math. Pricing rows use confirmed rates from Anthropic's official pricing documentation
Dimension | Naive Full History | Smart Context Construction |
|---|---|---|
Tokens at turn 1 | ~300 | ~300 |
Tokens at turn 10 | ~3,000 | ~300–600 |
Tokens at turn 50 | ~15,000 | ~300–600 |
Tokens at turn 100 | ~30,000 | ~300–600 |
Cost growth pattern | Linear with turns | Flat per call |
Claude Sonnet 4.6 cost at turn 50 ($3/MTok input) | $0.045 per call | $0.0018 per call |
Claude Sonnet 4.6 cost at turn 100 ($3/MTok input) | $0.090 per call | $0.0018 per call |
Context relevance over time | Degrades, grows noisier | Stays high, precise |
Context window overflow risk | High at scale | Rare |
The ratio between naive and smart context construction is approximately 25x at turn 50, growing further at higher turn counts. The cost differential comes entirely from token volume, not model capability- the same Claude Sonnet 4.6 responding to the same query costs 25x less when only relevant context is injected. Pricing source: Anthropic model pricing verify GPT-4o rates at openai.com/api/pricing before adding GPT-4o rows.
Python Code Naive Agent vs Mem0-Powered Agent
The naive pattern grows the message list indefinitely and sends it all on every call.
The Mem0-powered version stores every turn but retrieves only what is relevant to the current query before calling the model.
The key structural difference is in messages. The naive version sends conversation_history which grows with every turn. The Mem0 version sends a fixed-size system prompt plus a capped set of retrieved memories plus the current message. The token budget for history stays constant.
What Gets Retrieved vs What Gets Stored
Everything gets stored. Every user message and assistant response is indexed by Mem0 as a vector embedding, tagged by user_id and timestamp. Nothing is discarded. The user's preferences from six months ago, the edge-case question from last Tuesday, the correction they made in session three, all of it is in the store.
Only the relevant subset gets retrieved. When the user asks "what file format was decided on?", the retrieval query fetches memories about file format decisions. It does not fetch memories about the user's timezone preference or their earlier complaint about response speed.
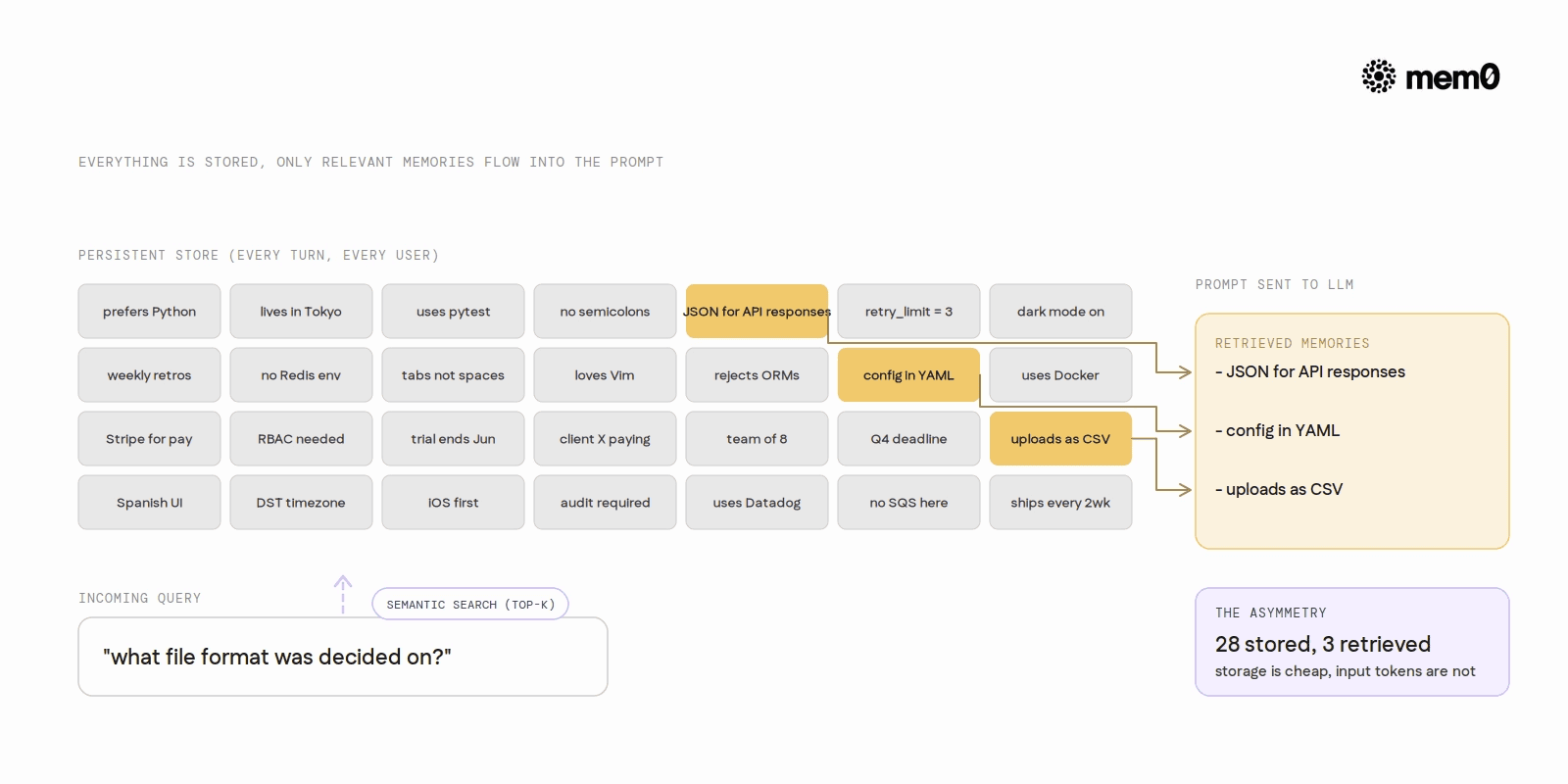
This asymmetry is deliberate. Storage is cheap. Vector database lookups cost fractions of a cent. LLM input tokens at frontier model prices are expensive. The architecture moves cost from the expensive tier to the cheap one.
Mem0 also performs memory distillation: rather than storing raw conversation turns verbatim, it extracts and indexes the semantically meaningful facts. "The user prefers Python over JavaScript for scripting tasks" is stored as a discrete memory rather than the full exchange. This keeps individual memory entries small and retrieval precise.
Caching and Prompt Deduplication
Prompt caching is available on both OpenAI and Anthropic. Static prefix content, like system prompts and shared instructions, can be cached so repeated identical prefixes are not re-billed at full rate. Anthropic charges $0.30 per million tokens for cache reads versus $3.00 for fresh input on Claude Sonnet, a 10x reduction for the static portions.
Smart context construction and prompt caching work together. Because the system prompt is constant and short, it caches reliably. The retrieved memory block changes per query, so it does not cache. But since memory block tokens are already small at 150-250 tokens, the incremental cost is low. The combination of selective retrieval and prefix caching can push effective per-call costs well below naive-injection rates without any change to model selection.
Where Mem0 Fits
Mem0 implements the retrieval pattern described above as a managed service, handling embedding, storage, distillation, and ranked retrieval. A team adopting it does not need to wire together a vector database, an embedding pipeline, and a memory extraction prompt. The API surface is intentionally minimal.
The pattern for a production agent is three operations: search for relevant memories before each LLM call, add the current exchange after each turn, and pass the search results into the prompt. The Mem0 client handles everything in between.
This pattern keeps token counts stable across arbitrarily long user histories. The agent becomes more capable over time as more memories accumulate, while the per-call cost stays bounded by the retrieval budget, not by the length of all past conversations.
Final Notes
LLM API costs are controlled at the prompt, not the model, and the single most impactful change is replacing full history injection with semantic retrieval of only what each query actually needs.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

