



AI agents become genuinely useful when they remember things across sessions. A personal assistant should know that a user prefers vegetarian restaurants, recognize when that preference changes to vegan, and never surface the older preference as if it were still current. That sounds straightforward, but the path from "memory write" to "correct retrieval weeks later" involves more failure modes than most developers anticipate and almost none of them are visible to conventional testing.
Unit tests verify that individual functions behave correctly. Integration tests verify that memory writes and searches work end to end. Neither test captures how memory behaves across many sessions where preferences evolve, contradict each other, and compete for retrieval. You can write assert memory.search("diet") == "vegan" in a test and have it pass cleanly, and still ship an assistant that recommends a cheese plate to a user who switched from vegetarian to vegan six weeks ago. The function worked. The pipeline worked. The failure lives in the accumulated state that no individual test ever generated.
This is what makes long-term memory testing genuinely hard. The bugs are emergent, but they only appear after enough history has accumulated to create ambiguity at retrieval time. A memory system that looks perfect in a five-turn test conversation can look very different after eighty turns across a dozen sessions, especially when the user's preferences are evolving.
Note: This article documents what we found when we built a memory simulator and ran it against Mem0's hosted platform using Python SDK mem0ai==2.0.1. The results showed that Mem0 is a reliable foundation for long-term agent memory with the right integration pattern, it handles most real-world memory scenarios well and that the simulator itself is a useful instrument for any team that wants to validate their memory layer before it meets production users.
What We Built
Memsim (Memory-Simulator) is a small open-source framework that generates synthetic user trajectories, replays them through a memory backend, and scores the results against known ground truth. The design is deliberately minimal where trajectories are sequences of turns, each turn has a type, and ground truth is tracked deterministically so that probes can score memory accuracy against what the system should know at any given point.
Here is what our set up looked like:
80 turns per trajectory
3 seeds per contradiction rate
4 contradiction rates: 0%, 5%, 15%, and 30%
12 total trajectories per run
Mem0 as the memory backend
Semantic scoring in the final run
The simulator tracks ground truth at every turn, which means that at any point in a trajectory, you can ask "what is the canonical current value of the user's diet preference?" and get a precise answer. That ground truth is what the probes score against.
The Four Memory Behaviors We Measured
Before getting to the results, it's worth being precise about what each probe is actually measuring.
Stale facts: This measures whether an older preference surfaces after a newer update exists. This is the vegetarian/vegan problem: the user updated their preference, but the assistant is still retrieving and acting on the old value. In isolation, a stale retrieval looks like a helpful response. It only looks wrong when you know the trajectory that produced it, which is exactly why it's invisible to one-off testing.
Unresolved contradictions: In this we measure whether old and new values appear together in the top-k results without a clear signal about which is current. This is worth distinguishing carefully from stale facts. Mem0's latest algorithm is ADD-only, so it preserves every transition as a separate timestamped row rather than overwriting previous values.
Scope leakage: This measures whether one user's memories appear in another user's namespace. In multi-tenant memory systems, this is a correctness bug with direct privacy implications, and it's the kind of bug that only appears under concurrent load rather than in single-user test scenarios.
Retrieval drift: Finally, retrieval drift measures whether a stable fact remains consistently retrievable as the trajectory grows longer. A memory system that correctly returns a preference early in a trajectory but loses track of it by turn sixty, not because the preference changed, but because accumulated history has pushed it down in the rankings is exhibiting retrieval drift. This probe only measures genuinely stable durable facts, not fields that were intentionally updated.
Experiments
The most important thing about these experiments is that they were designed as a progression rather than a single measurement. Each run changed exactly one thing like the evaluation method, the integration pattern, or the probe design, so that we could isolate what each change contributed to the results.
TL;DR
The experiments were intentionally incremental. Each run changed one part of the setup so we could separate Mem0 behavior from evaluator behavior, timing artifacts, and downstream resolution logic.
All experiments use the Mem0 Python SDK. Get your free API key
Run | What changed | Stale facts | Unresolved contradictions | Scope leakage | Retrieval drift | Outcome |
|---|---|---|---|---|---|---|
Default baseline | Mem0 default behavior with exact scoring | 0.948 | 0.377 | 1.000 | 0.421 | Mem0 retrieved many current facts, but exact scoring and unresolved historical memories made contradictions look worse. |
Custom instructions | Added latest-wins-style extraction guidance | 0.398 | 0.346 | 1.000 | 0.799 | Prompt-level guidance alone was not enough to reliably create a current-state view. |
Timestamp-aware V1 | Added downstream timestamp-aware resolution | 0.839 | 0.834 | 1.000 | 0.354 | Treating the newest timestamped memory as current substantially improved stale and contradiction behavior. |
Timestamp-aware V2 | Added semantic scoring and improved drift tracking | 0.917 | 0.917 | 1.000 | 0.750 | Best raw stale/contradiction scores; semantic scoring gave Mem0 credit for correct paraphrases. |
Timestamp-aware V3 | Removed fallback drift checkpoints and kept only stable durable facts | 0.853 | 0.850 | 1.000 | 0.917 | Cleanest final measurement; Mem0 stayed isolated, retained stable facts, and handled most contradictions with timestamp-aware resolution. |
Let’s explore each run in detail:
Run 1: Default baseline with exact scoring
The first run used Mem0's default configuration with exact-match scoring and no special integration logic. It represents the experience of a developer with the standard SDK integration and evaluates the results by checking whether retrieved text contains the expected value verbatim.
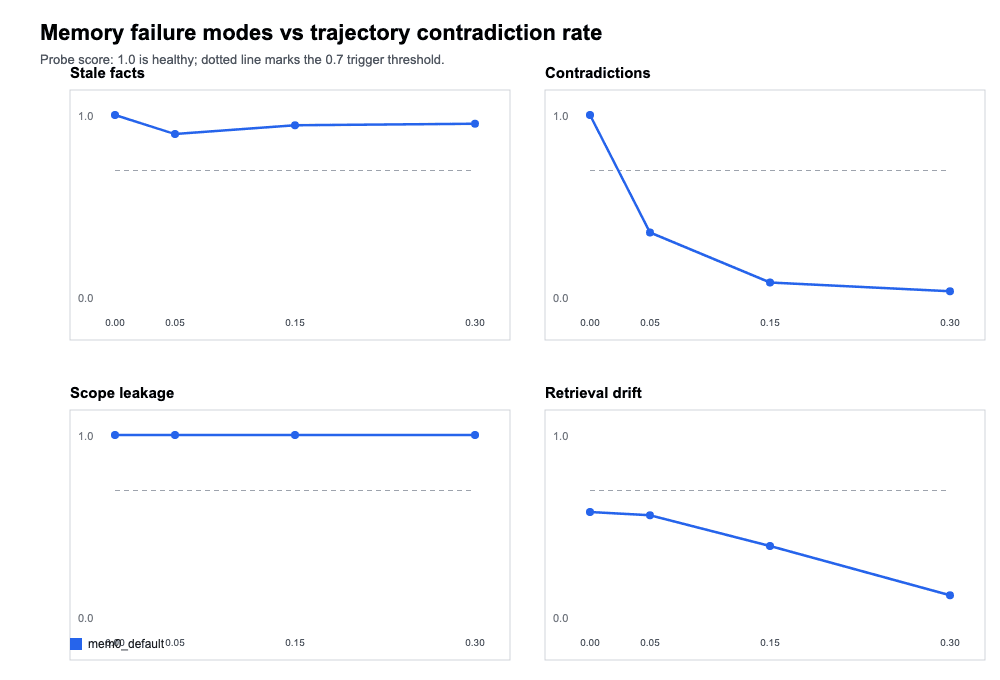
Run 1: Default baseline with exact scoring
Outcomes:
Scope leakage was perfect at 1.0 across every contradiction rate, which was the most important result from this run. Mem0's user-level namespace isolation held completely under sustained contradiction injection. That invariant never moved for the rest of the experiment.
Stale facts came in at 0.948 averaged across all contradiction rates, which is largely healthy but shows some degradation at higher contradiction rates.
The unresolved contradictions score of 0.377 looked alarming at first, but the next run revealed that this was substantially a measurement artifact rather than a true memory failure.
Retrieval drift’s performance turned out to reflect a combination of the ADD-only architecture surfacing historical entries and the exact scorer's inability to credit semantically correct paraphrases.
Key finding: Scope isolation is robust by default. The numbers on the other probes with exact scoring are measuring a mix of real behavior and scorer limitations.
Run 2: Custom instructions with latest-wins guidance
The second run added project-level custom instructions to Mem0 telling it to treat newer explicit updates as the current truth for durable profile fields. The hypothesis was that prompt-level guidance could nudge extraction and retrieval behavior toward better contradiction resolution.
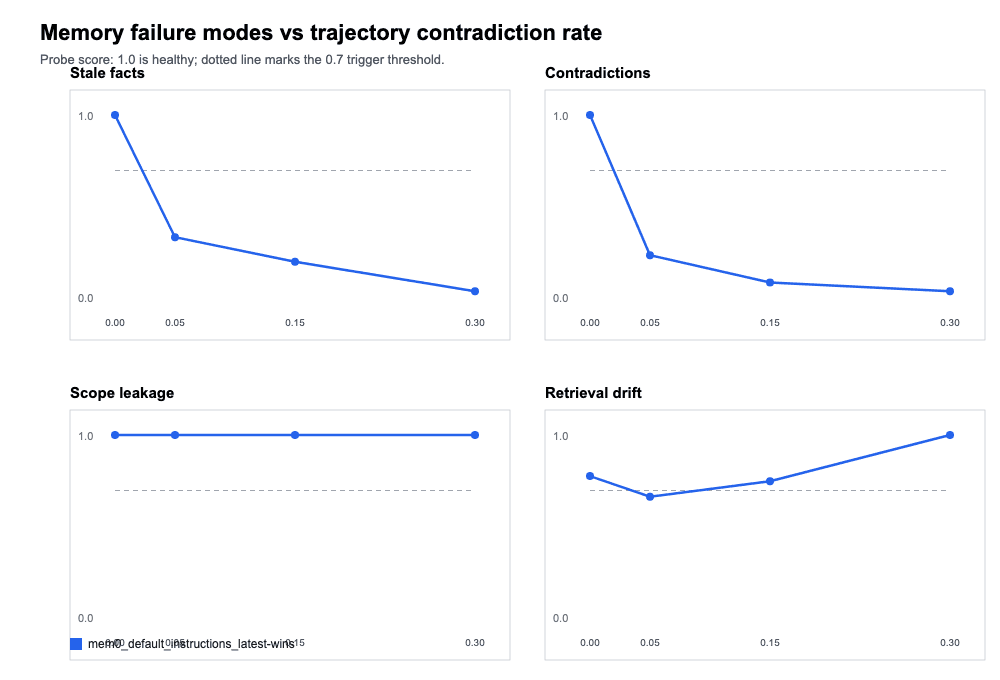
Run 2: Custom instructions with latest-wins guidance
Outcomes:
Stale facts dropped to 0.398, which was worse rather than better, indicating that the custom instructions were changing extraction behavior in ways that created new fragility.
Unresolved contradictions improved slightly to 0.346 averaged, and retrieval drift dipped initially but improved at later stages.
The overall picture was that custom extraction instructions alone are not a reliable path to clean current-state resolution. They change behavior, but not predictably enough to be the primary mechanism.
Key finding: Custom instructions are useful for defining extraction behaviour, but require parallel current-state resolution at the application layer.
Run 3: Timestamp-aware resolution
The Mem0’s new ADD-only algorithm documents that created_at timestamps are returned on every memory row in the V3 search response, and that the intended integration pattern is for downstream applications to use those timestamps to identify the most current value. Rather than expecting Mem0 to destroy historical context, the architecture expects the application to interpret history intelligently.
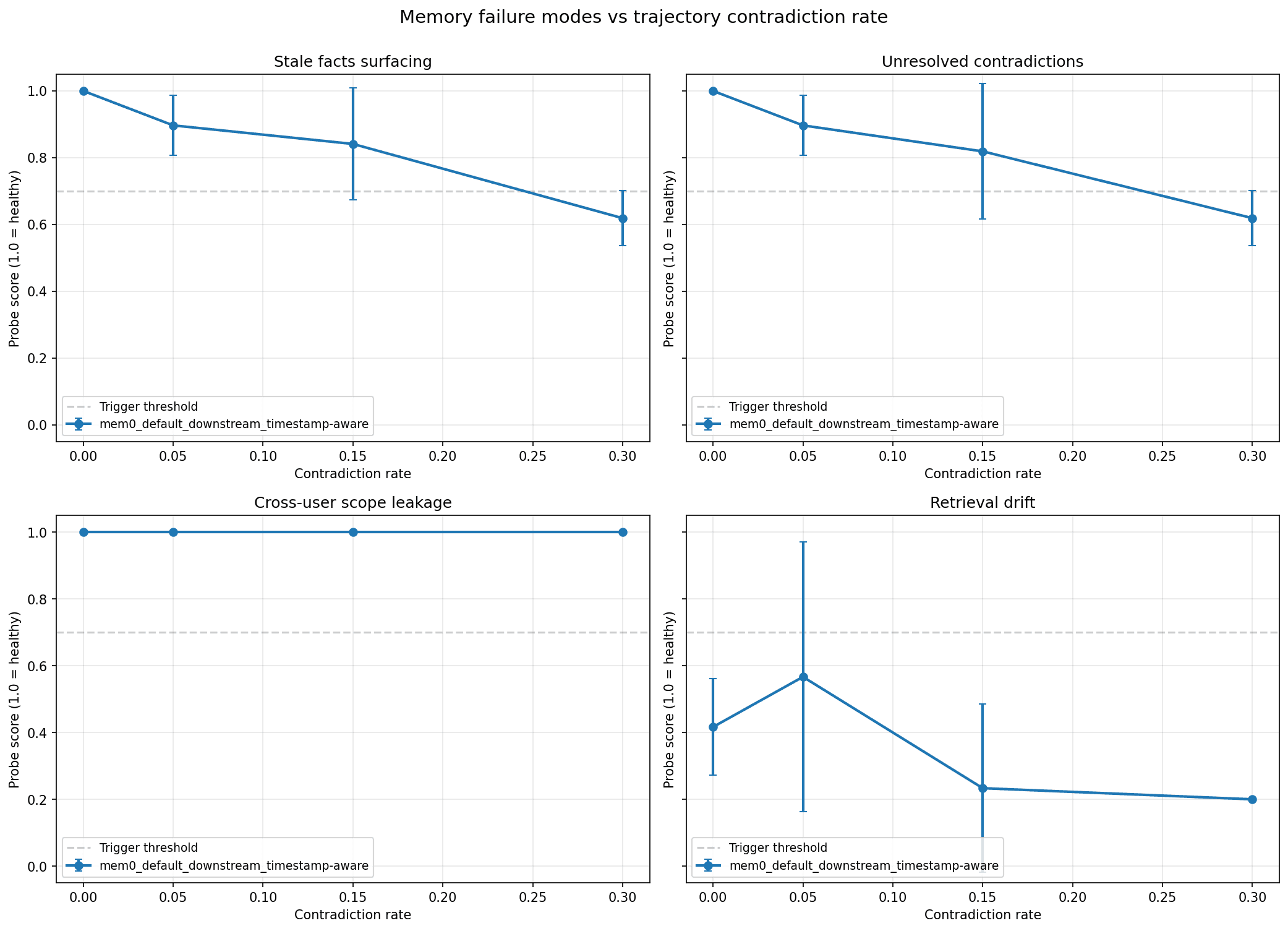
Run 3: Timestamp-aware resolution
Outcomes:
Run 3 implemented the following pattern: after calling
mem0.search(), the results were sorted bycreated_atdescending, and the most recent matching memory was treated as the canonical current value.This single change transformed the unresolved contradictions score from 0.346 to 0.834 and stale facts from 0.398 to 0.839. Scope leakage remained at 1.0.
Retrieval drift dropped to 0.354, which turned out to be a probe design issue rather than a true memory problem, so the probe was falling back to unstable facts when stable ones weren't available, creating noisy checkpoints that contributed false failures. That was fixed in the next run.
Key finding: Timestamp-aware resolution at the application layer is the correct integration pattern for Mem0's ADD-only architecture. Treating the newest timestamped memory as the current value resolves the vast majority of apparent contradiction failures.
Run 4: Semantic scoring
Run 4 kept timestamp-aware resolution and added semantic scoring to replace exact string matching. The change addressed a systematic problem with exact scoring: memory systems like Mem0 often return semantically correct but lexically varied paraphrases. A system that stores "User follows a vegan diet" and retrieves "plant-based eating only" when asked about diet preferences is working correctly i.e, exact scoring was penalizing this as a failure, but semantic scoring credits it.
Run 4: Semantic scoring
Outcomes:
Stale facts improved to 0.917 and unresolved contradictions to 0.917.
Retrieval drift improved to 0.750. These numbers give credit to the memory for semantically correct retrievals rather than penalizing surface-form variation.
Key finding: Semantic scoring is more representative of real retrieval quality than exact matching. A significant fraction of apparent failures in exact-scored runs were retrievals that were semantically correct but phrased differently.
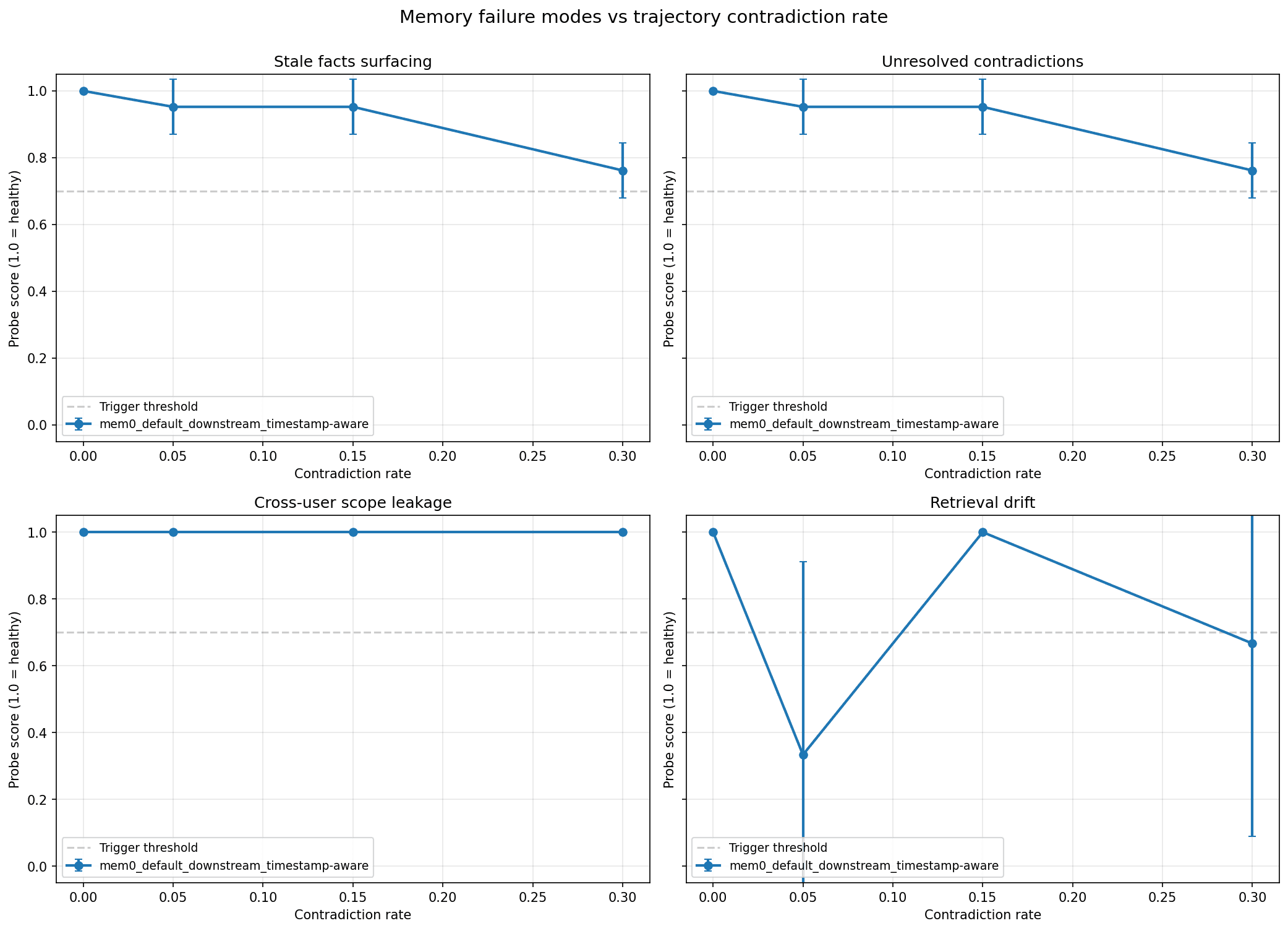
Run 5: Final Run with Drift Probe Fix
The final run kept all the improvements from Run 4 and fixed the retrieval drift probe to only evaluate against genuinely stable durable facts that were the fields that were set early in the trajectory and never updated. Previous runs included fallback checkpoints using facts that were subsequently contradicted, which created noise in the drift measurement. Restricting the probe to truly stable facts made the drift metric more honest.
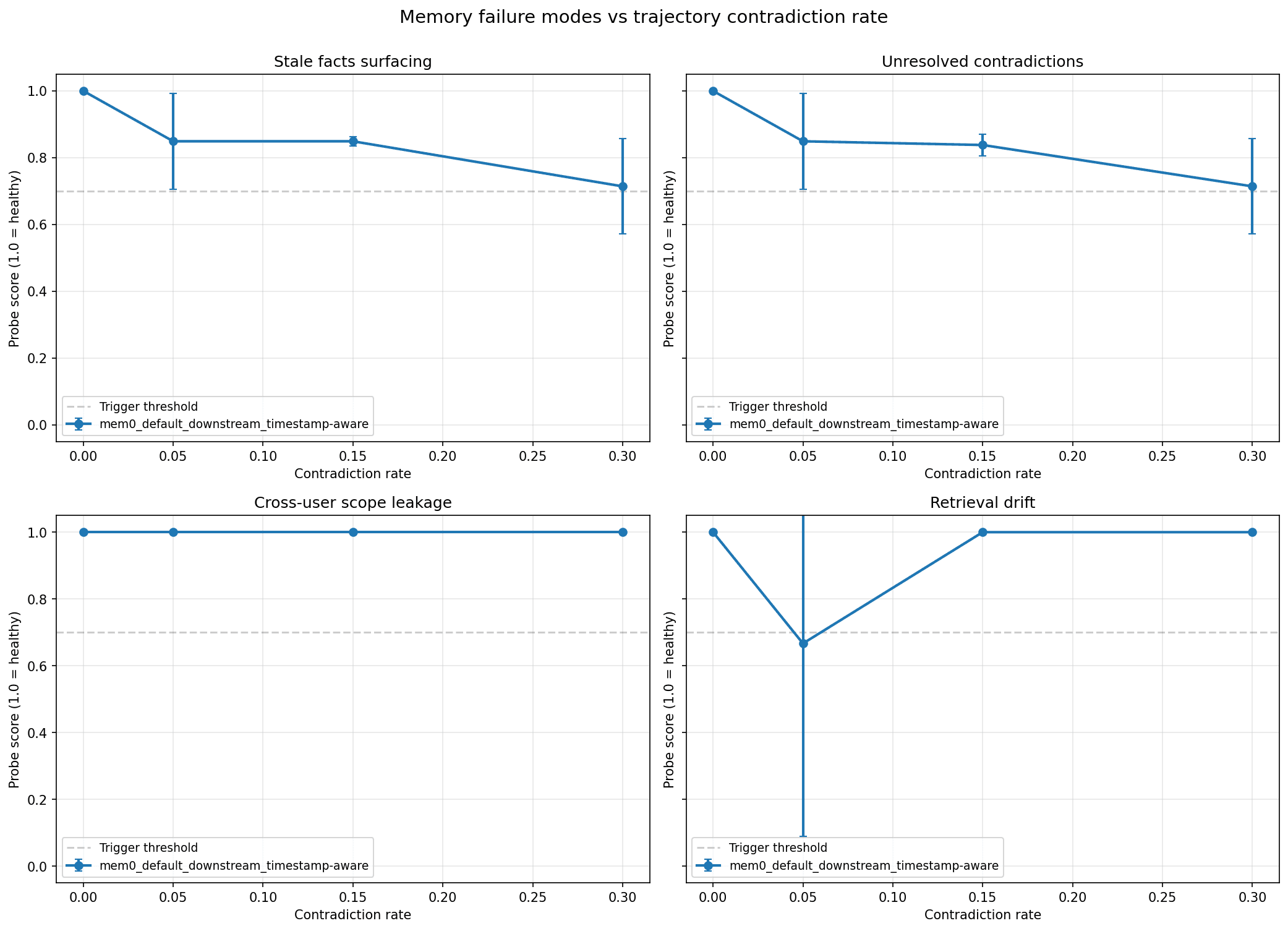
Run 5: Final Run with Drift Probe Fix
Outcomes:
The final results: stale facts at 0.853, unresolved contradictions at 0.850, scope leakage at 1.0, and retrieval drift at 0.917. All four probes are above the 0.7 healthy threshold on average, and the trajectory shapes tell the real story.
At 0% contradiction, a user whose preferences are entirely stable across 80 turns and on all four probes score 1.0. This is the expected baseline and it holds cleanly.
At 5% and 15% contradiction rates, stale facts and unresolved contradictions hold around 0.85. The error bars widen, reflecting variance across the three seeds, but the averages stay comfortably above threshold. This is the contradiction density that corresponds to a real user who changes preferences occasionally like a workout routine that evolves, a dietary change, a relocation and Mem0 with timestamp-aware resolution handles it well.
At 30% contradiction, both stale facts and unresolved contradictions drop to approximately 0.71, which is just above the 0.7 threshold. This contradiction density is nearly a third of all turns updating a previously stated preference and is on the extreme end of realistic user behavior, and the fact that scores stay above threshold even here reflects how much work the timestamp-aware resolver is doing.
Retrieval drift at 0.917 overall, with a visible dip at the 5% contradiction rate, reflects one seed where the early checkpoint fact was missing from the initial retrieval. The V shape in the chart is a sampling artifact from small seed counts at that rate rather than a systematic drift pattern. At 15% and 30% contradiction, drift recovers to 1.0 because the stable facts being probed are genuinely stable and remain retrievable throughout the trajectory.
Scope leakage at 1.0 across every point on the chart is the result worth highlighting most prominently.
Why Timestamp-Aware Resolution Worked?
Mem0's latest algorithm was redesigned from the ground up to preserve memory history rather than overwrite it. Instead of two LLM passes that decided whether to ADD, UPDATE, or DELETE existing memories, the new pipeline uses a single-pass ADD-only extraction with hybrid retrieval that combines semantic, keyword, and entity signals. The result is a system that accumulates the full sequence of a user's preference changes rather than consolidating them into a single current value and the benchmark numbers reflect how much this matters in practice:
91.6 on LoCoMo: A (+)20.2 point improvement over the previous algorithm
93.4 on LongMemEval: This is a (+)25.6 point improvement, with the biggest gains in temporal reasoning (+29.6) and multi-hop queries (+23.1)
Read the complete methodology and results at mem0.ai/research.
This architecture is genuinely more powerful for applications that care about longitudinal context like coaching, health tracking, audit trails, anything where the history of how a preference evolved is as valuable as the current value. The trade-off is that the application now needs to interpret a history rather than receive a pre-resolved answer.
Here is a quick code snippet from the project:
The created_at timestamp returned on every memory row is exactly the mechanism Mem0 provides for this. Sort retrieved memories by created_at descending, treat the top result as the canonical current value, and you have implemented the interpretation layer the architecture was designed to support, with the full historical sequence still accessible for any workflow that needs it.
The simulator's final run validates that this pattern holds across 0% through 30% contradiction rates with above-threshold scores on all four probes.
Recipe for Teams Building Memory-Augmented Agents
The progression from Run 1 to Run 5 maps the decisions a production team faces when building on Mem0. Each one has a concrete practice attached.
Semantic Scoring: Exact matching undercounts correct retrievals because memory systems return semantically correct paraphrases. A significant fraction of apparent failures in Run 1 were retrievals that were correct in meaning but phrased differently than the expected value.
ADD-Only Architecture: The new algorithm preserves the full sequence of preference changes rather than overwriting them. Forcing UPDATE/DELETE via custom prompts doesn’t work best here, since the architecture is designed to preserve history and let the application interpret it.
Timestamp-Aware Resolution: When your application needs the latest value for a field, sort retrieved memories by
created_atdescending and treat the most recent match as canonical. This single change took the unresolved contradictions score from 0.346 to 0.850 across the experiment.Async Extraction: Mem0's
add()returns{"status": "PENDING"}by default. PollGET /v1/event/{event_id}/forSUCCEEDEDbefore running any retrieval that depends on the added memory, or use a 6-second (best fix) fixed sleep in test environments.Scope Isolation: Scope leakage held at 1.0 across every run and contradiction rate, but that invariant is worth verifying against your own user ID scheme and workload before scaling to production load.
Mem0 handles the storage, retrieval, and conflict resolution: your team writes the test logic.
Running the Experiment Yourself
The final run can be reproduced with the following command. You will need mem0ai==2.0.1 version.
💡Before you run this You'll need a Mem0 API key. It's free: get yours at app.mem0.ai
You can find the complete code here
Each run produces a failure_modes.png chart, a summary.md, a results.csv, and a results.json in the output directory. The chart gives the high-level behavioral picture. The results.json contains the diagnostic detail for every probe check with matched memories, timestamps, expected values, and whether a failure was triggered, which is where the most useful signal lives when you're investigating a specific failure pattern.
Note: Allow approximately two hours of wall-clock time for the full run. Mem0's add() is asynchronous, and the simulator waits 6 seconds after each add before proceeding, which is the correct behavior for ensuring extraction is complete before probing.
Final Thoughts
Mem0 provides the durable memory foundation, while the simulator provides the instrument for validating that the application is using that foundation correctly. The combination gives teams a way to answer a question that no unit test or integration test can answer: does my agent remember the right things, for the right users, over the time scales that matter?
The five runs documented in this blog are a starting point, not a ceiling.
To get started, grab your free Mem0 API key at app.mem0.ai or
self-host from the GitHub repository and run the experiment yourself.
If you build on top of this, run it against a different memory backend, or have a failure mode you think the probe suite should cover, feel free to open an issue, because the most useful extensions come from teams using it against real workloads.
Looking for more mem0-demo quickstarters? Check out our companion playbooks
Frequently Asked Questions
Q. What is long-term memory testing for AI agents?
Long-term memory testing validates how a memory system behaves across many sessions as user preferences evolve and contradict each other. Unlike unit tests, it catches emergent bugs that only appear after enough history has accumulated to create ambiguity at retrieval time.
Q. How does Mem0 handle contradicting user preferences over time?
Mem0 uses an ADD-only architecture that preserves the full history of preference changes with timestamps rather than overwriting old values. Your application sorts retrieved memories by created_at descending and treats the most recent match as the current value.
Q. Does Mem0 leak one user's memories into another user's results?
No. Scope leakage scored 1.0 across every run and contradiction rate in the experiment, meaning Mem0's user-level namespace isolation held completely even under sustained concurrent load and high contradiction injection.
Q. Why does exact string matching undercount correct memory retrievals?
Memory systems like Mem0 often return semantically correct paraphrases rather than verbatim matches. A system storing "User follows a vegan diet" may retrieve "plant-based eating only," which is correct in meaning but fails exact scoring. Semantic scoring gives accurate results.
Q. How long does it take to run the Mem0 memory simulator experiment?
The full run takes approximately two hours of wall-clock time. Mem0's add() is asynchronous, and the simulator waits 6 seconds after each add to ensure extraction is complete before probing, which accounts for most of the runtime.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

