



An agent that remembers everything is an agent that recalls badly.
The intuition runs against most engineering instincts. Storage is cheap, the thinking goes; just keep it all. Eviction is something to figure out later, after the system is in production. By then, the system that "remembers everything" is the system that produces stale answers, contradictory facts, and irrelevant retrievals.
Forgetting is its own design problem, not a side-effect of storage limits. The systems that handle it deliberately are the ones that scale.
Forgetting is not a side effect of storage
Most teams hit the forgetting question accidentally. Disk fills up, the vector index gets slow, retrieval latency creeps from 80ms to 300ms, and someone proposes a TTL job to drop old rows. Forgetting then arrives as an infrastructure concern rather than a memory-quality concern.
That framing misses the real problem. A memory system gets worse at recall as it grows even when storage is unlimited and retrieval is fast. The reason is interference. Every additional fact in the index is another candidate to surface during a top-k search, and most of those candidates are noise relative to the current turn.
An agent's recall quality is bounded not by what it can store but by how well it can suppress everything irrelevant.
Treat forgetting as a recall-quality intervention, not a storage one. The right question is not "which entries can we afford to drop," it is "which entries are crowding the active surface so much that the right answer cannot rise to the top."
What cognitive science already knew
Hermann Ebbinghaus ran the first systematic forgetting experiments between 1880 and 1885. He memorized lists of nonsense syllables, then re-tested himself at varied intervals to map how much had survived. The resulting forgetting curve dropped sharply in the first hours and flattened into a long tail.
The takeaway most often quoted is that humans halve their memory of newly learned material within days unless they review it. The more interesting finding is that each repetition lengthens the optimum interval before the next review is needed. Reinforcement does not just refresh a memory; it changes the schedule.
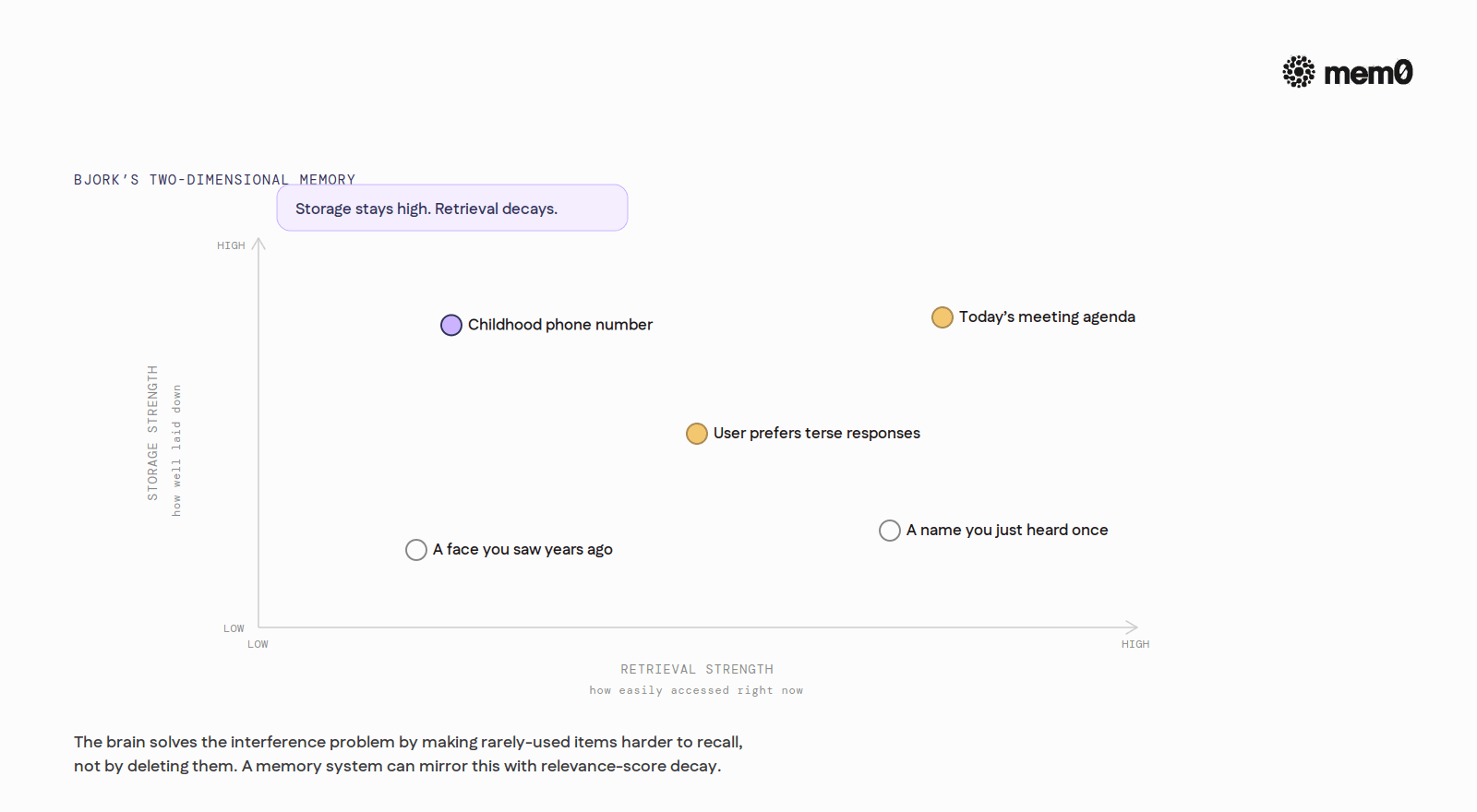
A century later, Robert Bjork sharpened the theory. In what he and Elizabeth Bjork called the New Theory of Disuse, they distinguished two indices of a memory: storage strength, which is how well a memory is laid down, and retrieval strength, which is how easily it can be accessed right now. Storage strength does not decay. Retrieval strength does, and that decay is adaptive rather than accidental.
If every stored item were equally and permanently accessible, the memory system would be paralyzed by interference. Lowering retrieval strength of infrequently used items is the way the brain stays usable.
That sentence reads like an architecture review for a vector store. The brain solves the interference problem by making rarely-used items harder to recall, not by deleting them. Production memory systems can mirror that behavior using relevance-score decay, where access resets the score and disuse lowers it.
Memory consolidation adds the other half of the picture. Newly encoded experiences live, in cognitive-science terms, in the hippocampus. Over hours, days, and years, they reorganize across cortical networks. The richness of the original episode is often lost. What remains is a semantic version of the event, depersonalized and compressed.
For an agent builder, consolidation is essentially summarization plus deduplication. Raw turn-level history is the equivalent of fresh hippocampal traces. The user-level memory store is the cortical version. Moving a fact from the first store to the second is not just a copy operation. It is an editorial decision about what to keep and in what shape.
The four eviction strategies
Age-based / TTL
The simplest. Drop entries older than N days regardless of how often they have been accessed. The cognitive analogue of trace decay.
TTL still earns its place in production. It is the right tool for legally constrained data, where retention windows are imposed by policy rather than recall quality. A user's prior support ticket from three years ago might still be useful, but if the privacy policy promises eighteen-month retention, TTL is the mechanism that enforces it.
The failure mode is obvious. A pure TTL policy will eventually drop a fact that was both old and still true. A user's allergy, a child's name, a workspace's billing structure. None of these should age out on a fixed schedule.
LRU / recency
Drop entries unused for N days. Each access resets the clock. This is the closest analogue to Bjork's retrieval-strength decay.
LRU works well for high-churn assistants where the relevant context shifts quickly. A coding agent does not need last quarter's project notes once the project is done. An assistant for ephemeral planning tasks (trip itineraries, one-off research) is mostly composed of facts that age out cleanly.
The failure mode is the rare-but-critical fact. If the agent has not had occasion to surface a user's penicillin allergy in six months, an LRU policy will quietly prune it. The next time it matters, it is not there. LRU treats access frequency as a proxy for importance, and that proxy breaks for low-frequency, high-stakes data.
Salience scoring
Attach an importance score at extraction time, set either by the LLM that pulled the fact out of conversation or by explicit user signals (thumbs up, "remember this," explicit pinning). Drop entries whose score falls below a threshold.
Salience is the cognitive analogue of emotional and flashbulb-memory effects. The brain encodes traumatic, surprising, or emotionally charged events more durably than ordinary ones.
Salience scoring shifts the eviction question from "when was this used" to "how much does this matter," which is usually the question the product actually wants answered.
The failure mode is rater drift. If the model that scores salience changes (a new release, a new prompt, a new evaluator), the threshold that worked last quarter no longer works this quarter. Some teams pin the scorer to a specific model version. Others recalibrate periodically.
Semantic supersession / update
When a new fact contradicts an old one, replace or mark the old as superseded. Most useful for preference and profile data, where what changes is not the topic but the value.
Without supersession, an agent that hears "I prefer terse answers" today and "give me lots of detail" three months from now will store both, retrieve both, and have no way to decide which is current. Supersession solves this at write time. The new fact is compared against semantically similar existing memories. If they conflict, the old one is replaced or the new one wins.
The failure mode is false-positive supersession. "I'm in Berlin this week" sounds like it contradicts "user lives in Lisbon," but it does not. Distinguishing temporary state from durable profile data is exactly the judgment LLMs are good at, which is why most modern systems use an LLM (not a similarity threshold) to decide whether a candidate fact is a contradiction or merely an addition.
Active forgetting versus passive aging
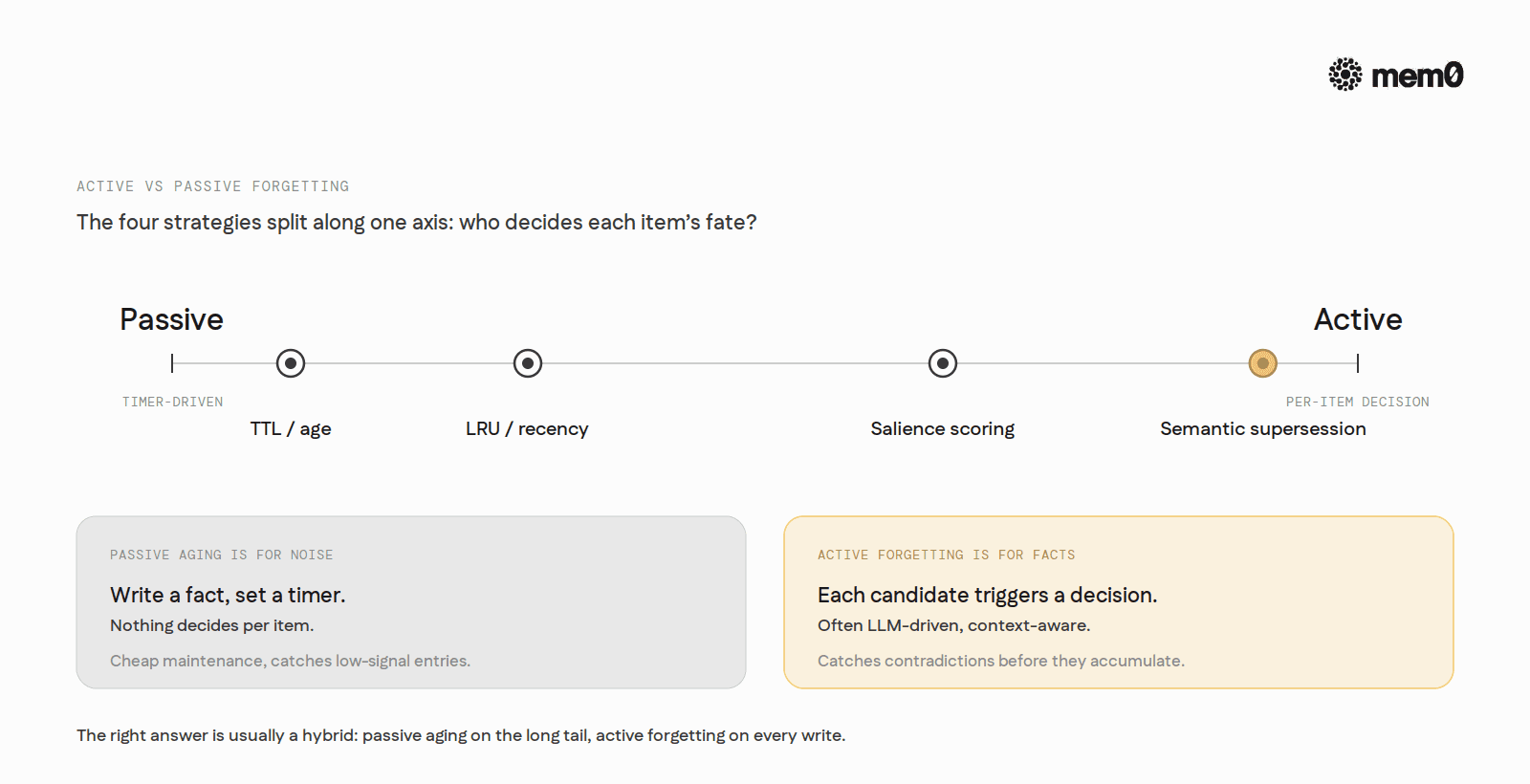
The four strategies above split along another axis. Some are passive. The system writes a fact, sets a timer, and lets the timer expire. Nothing decides per item.
Active forgetting is different. The system runs a deliberate pass, often LLM-driven, and decides what to keep, drop, merge, or supersede based on context. Each candidate fact triggers a decision rather than a timer.
The right answer is usually a hybrid. Passive aging keeps maintenance cheap. Active forgetting catches the cases passive aging gets wrong. A reasonable production policy is something like: TTL on long-tail entries to bound storage, LRU-style decay on retrieval scores to bound interference, and active supersession on every write so contradictions never accumulate.
Passive aging is for noise. Active forgetting is for facts.
Comparison at a glance
Strategy | What triggers eviction | Cognitive analogue | Best for | Worst for |
|---|---|---|---|---|
TTL / age | Wall-clock age exceeds N | Trace decay | Compliance, PII retention | Long-lived true facts |
LRU / recency | Time since last access > N | Bjork retrieval-strength decay | High-churn assistants | Rare-but-critical facts |
Salience scoring | Score below threshold | Emotional, flashbulb effects | High-signal extraction pipelines | Drift in rater calibration |
Semantic supersession | New fact contradicts old | Belief revision, interference resolution | Preference and profile data | Cases needing audit history |
Where systems fail
Three failure patterns show up repeatedly. They are useful as a checklist when designing or auditing an agent's memory layer.
Over-eager forgetting. The user says "I told you yesterday," and the agent has no record. Almost always this is a TTL set too short relative to the user's natural recall interval, or an LRU window that does not account for the cadence of the actual use case. Mitigation: combine TTL or LRU with a salience floor, so high-importance facts cannot be pruned on time alone.
Stale facts surviving. The user moved cities last month. The agent still recommends restaurants in the old city. This is the failure mode of pure semantic-supersession systems that wait for a contradicting fact to arrive. If the user never explicitly says "I moved," the old fact lingers. Mitigation: add a time-based decay on top of supersession so old facts gradually lose retrieval weight even without contradiction.
Stacked contradictions. The store has both "user prefers verbose" and "user prefers terse" because the user said one in May and the other in November, and no write-time reconciliation ever happened. Top-k retrieval surfaces both, the model has no signal about which is current, and behavior becomes inconsistent. Mitigation: at write time, compare the candidate fact against the top similar memories and run an update or delete if the new fact contradicts the old. Sort by recency at read time as a backstop.
How Mem0 handles forgetting
Mem0 treats memory operations as first-class. Every time a new fact arrives, an extraction pass identifies what is worth remembering, and an update pass evaluates that candidate against existing memories. The decision is not a similarity threshold but an LLM-selected operation, drawn from four options.
ADD creates a new memory when no semantically equivalent one exists. UPDATE augments an existing memory with complementary information. DELETE removes a memory that the new fact contradicts. NOOP takes no action when the candidate adds nothing meaningful.
That four-operation design directly addresses the stacked-contradictions failure. The candidate fact is compared against the top semantically similar existing memories before it is written. If a contradiction exists, the resolution happens at write time, not at the next retrieval.
For explicit lifecycle control, the platform exposes deletion at three levels:
A single memory can be removed by ID. Batches can be removed in one call. Filter-based deletion drops everything matching a user, agent, run, or metadata filter, with a safety check that refuses to wipe everything if no filter is provided.
Updates are equally explicit. A PUT against a memory record corrects outdated content immediately and stamps a fresh updated_at timestamp. Used together with the automated update pipeline, this gives an agent both autonomous reconciliation (the model decides) and deterministic correction (the application decides), in the same store.
The memory layer also separates lifetimes by tier. Conversation memory is single-response. Session memory persists for minutes to hours and is cleared explicitly. User and organizational memory are long-lived. That tiering matches the cognitive model: short-term, episodic working context flows into longer-term, semantic memory through promotion rather than indefinite accumulation.
A different mechanism: Memory Decay
Mem0 ships one more forgetting-adjacent layer worth treating separately. Memory Decay is not an eviction strategy. Nothing gets removed.
Memory Decay is a search-time re-ranking layer. Recently accessed memories carry up to a 1.5x score boost. Unused ones dampen toward 0.3x. The dampened memory still surfaces when it is genuinely the best match. The fact stays in the store; its accessibility falls when it goes unused.
This mirrors Bjork's storage-strength versus retrieval-strength distinction almost literally. The fact never gets deleted; it just gets harder to recall when nothing reinforces it. That is the philosophical opposite of TTL.
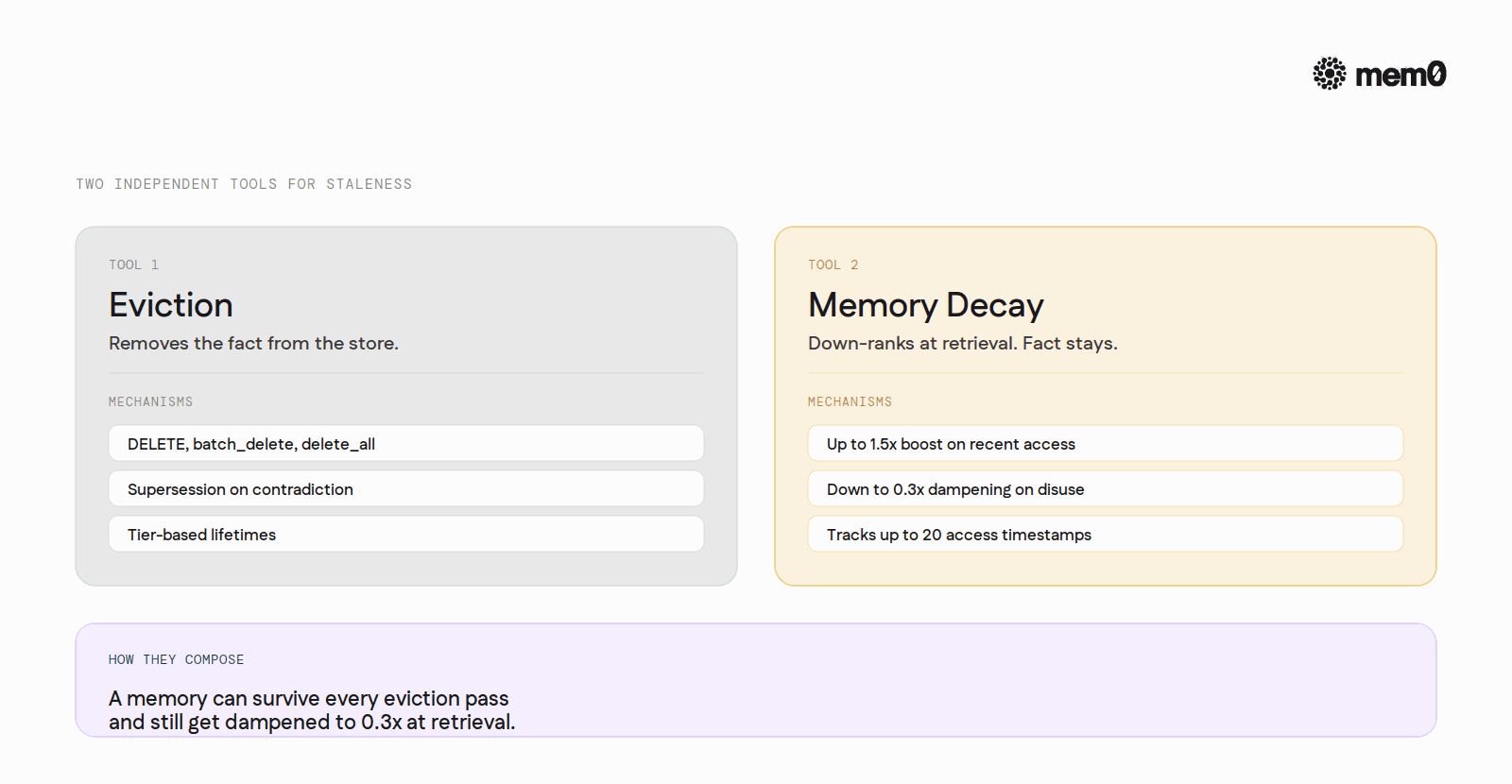
For an agent builder, this means Mem0 offers two independent tools for the same staleness problem. Eviction (DELETE, batch_delete, delete_all, supersession-on-contradiction, tier-based lifetimes) actually removes facts. Memory Decay leaves them in place but down-ranks them at retrieval. They compose: a memory might survive every eviction pass and still get dampened to a 0.3x retrieval score because it has gone untouched.
Memory Decay is opt-in at the project level, enabled with client.project.update(decay=True), and tracks up to 20 access timestamps per memory.
The shape of the choice
Memory systems get judged on what they recall, not on what they store. A clean index of fewer facts beats a noisy index of many.
The teams that handle forgetting deliberately build the index that recalls cleanly. The teams that defer it ship the system that "remembers everything" and recalls poorly.
The four strategies (age, recency, salience, supersession) are not interchangeable. Each one fits a class of memory. Age and recency handle noise; salience and supersession handle facts. Most production systems need at least one of each.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

