



Most agent memory failures don't happen at write time. They happen at retrieval. A store can hold the answer to the user's question and the agent still asks the question again, because the retrieval step looked in the wrong place.
The storage problem is largely solved. Vector databases, graph databases, full-text indexes, and managed memory APIs are commodity. The retrieval problem is not.
It is a design choice with at least five distinct shapes. Each one has different failure modes, different latencies, and different use-case fit.
What retrieval actually has to do
Storage decides what the agent could know. Retrieval decides what the agent does know in the moment of a turn. The two are different jobs.
A retrieval call has milliseconds to do four things. Take the user's current input. Decide what kind of recall the situation calls for. Search the memory store. Surface the result in a form the model can attend to.
If any one of those four steps mismatches the situation, the rest of the agent's reasoning sits on top of the wrong context.
Storage answers "did the agent remember this?" Retrieval answers "did the agent use it at the right moment?"
The mismatch shows up as a specific kind of bug. The agent forgets a preference the user stated last week. The agent misattributes a fact from a different session. The agent keeps asking for the same context the user already provided. None of these are storage failures. They are retrieval failures.
The five strategies in production
Most current agent stacks use one of five retrieval shapes, sometimes combined.
Recency
The simplest. Pull the last N entries by timestamp. Used by ChatMemoryBuffer in LlamaIndex, ConversationBufferMemory in LangChain, and the inner loop of most chat-based agents.
Recency is fast, deterministic, and zero-config. It is also wrong for any query that wants the relevant memory rather than the latest one. A user asking, "what did we decide about the database?" gets last Tuesday's chat about lunch, because lunch was more recent.
Semantic similarity
Embed every memory entry. Embed the query. Return the top K nearest neighbors by cosine similarity. The default move in any vector-database-backed memory system, including most production deployments of Pinecone, Weaviate, Chroma, and Mem0's own default mode.
Semantic similarity surfaces meaning regardless of phrasing. "What does the user prefer for testing?" returns "they prefer pytest over unittest" even though the words don't match.
The cost is that nearest-neighbor is brittle for rare entities. A query like ACME-7720 will not match a memory that says "the new Acme model" unless the embedding model happens to know the link. The embedding model's biases become the retrieval's biases.
Keyword and full-text
BM25 over a full-text index. SQLite FTS5. PostgreSQL tsvector. Used by Hermes Agent's session_search, OpenClaw's hybrid search, and most enterprise agent stacks that need to surface specific names, IDs, or code symbols.
Keyword retrieval excels at the rare-entity case where semantic similarity drowns out the exact match. It struggles with paraphrased queries. A user asking "deploy command" gets nothing useful when the memory says "ship to production."
That is why pure keyword retrieval almost never ships alone in modern stacks.
Hybrid with reranking
Run vector search and keyword search in parallel. Fuse the scores (reciprocal rank fusion is the cheap default; learned fusion is the expensive upgrade). Apply a cross-encoder reranker that scores query-document pairs jointly.
This is the configuration most production teams converge on after the first year of running an agent. A hybrid retriever recovers the misses of each individual signal, and a reranker on top of a 20-candidate list typically reorders the top three in a useful way.
The cost is two index lookups and one reranker call per turn, which can move latency from 50ms to 300-500ms depending on the reranker.
Graph traversal and entity-aware retrieval
Some memory layers store entities and edges instead of opaque text chunks. Retrieval becomes a small walk. Find the user, follow edges to their preferences, follow edges to recent topics, return the subgraph.
Graph retrieval surfaces structural recall that vector search cannot. "Who introduced this person to the project" is a graph query, not a similarity query. "What did the team decide about authentication, sorted by recency?" maps to a clean traversal.
The cost is operational. An extra store to run, an extra schema to evolve, a write path that has to extract entities reliably. Some systems answer this cost by running entity-linking in-process instead of standing up a separate graph database; the retrieval ranking still reflects entity structure, with a smaller operational footprint.
A vector index tells the agent what is similar. A graph tells the agent how things are connected. The right answer often lives in the structure, not the similarity.
A side-by-side view
Strategy | Strong at | Weak at | Typical latency | When to reach for it |
|---|---|---|---|---|
Recency | Short sessions, latest state | Anything older than the buffer | <10ms | MVP chatbots, working memory |
Semantic | Paraphrase, fuzzy match | Exact codes, rare names | 20-80ms | Default for unstructured text |
Keyword (BM25/FTS5) | Exact tokens, proper nouns | Synonym, paraphrase | <20ms | Logs, technical IDs |
Hybrid + rerank | Mixed-content corpora | Adds 100-300ms total | 100-400ms | Long-lived agent memory |
Graph / entity-aware | Relationship questions | Plain semantic queries | varies | Entity-heavy domains |
Numbers are order-of-magnitude. The right benchmark is the one run on the actual data.
The retrieval tradeoffs
Each strategy is a specific bet. The bets compose into four axes worth being explicit about.

Precision versus recall
A retriever can return five highly relevant memories and miss one important fact, or it can return twenty memories that include the fact but bury it. Precision-first systems feel sharp. Recall-first systems feel thorough but verbose.
Most agent stacks bias toward precision because the model pays a token cost for every recalled item. The fix is not "retrieve more." The fix is "retrieve smarter and rerank."
Recency versus relevance
A high-similarity match from six months ago can outrank a slightly less similar but very recent fact. That is wrong for a personal assistant who needs to know the user moved cities last week.
Recency decay solves this. Multiply the similarity score by an exponential decay over time, or filter the candidate set by a recency window before scoring. Either approach pushes stale-but-similar facts down the list.
Latency versus quality
A cross-encoder reranker typically adds 100-300ms. Mem0's documented managed reranker adds 150-200ms. That is a real budget hit on a turn that already includes embedding, retrieval, prompt assembly, and generation.
A 200ms reranker is worth it on the turns that matter and a luxury on the turns that don't.
The pragmatic answer is to rerank conditionally. Cheap chitchat does not need a rerank pass. A high-stakes question that triggers a tool call probably does.
Local versus distributed
A local in-process index is faster but bound to one machine. A managed remote store survives restarts and machine swaps but adds a network hop per turn. Most production retrieval is a hybrid because no single point on this axis wins all the time.
Failure modes worth knowing
Five failure modes show up across all strategies.
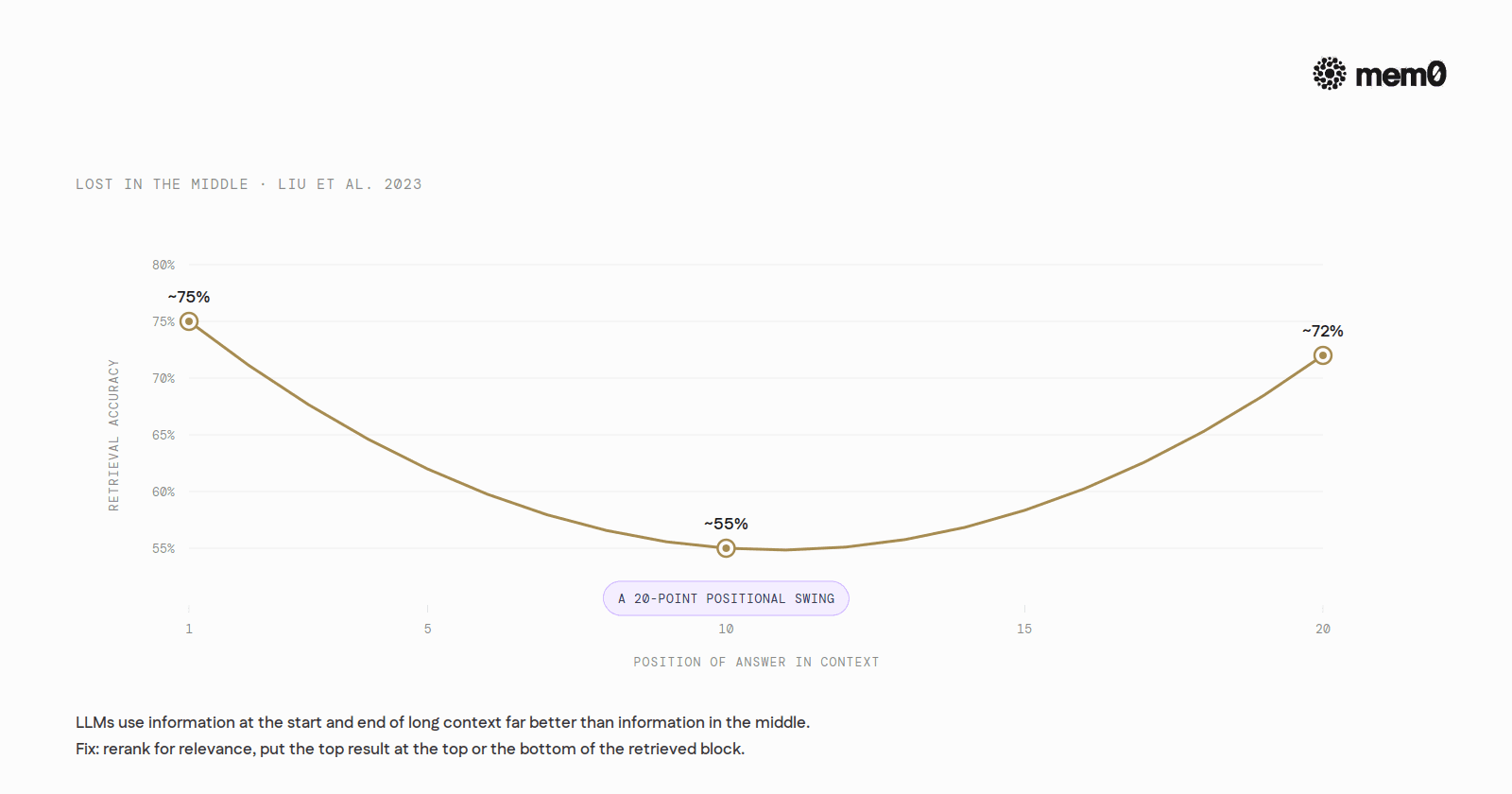
Lost in the middle. Liu et al. 2023 ("Lost in the Middle: How Language Models Use Long Contexts") showed that LLMs use information at the start and end of a long context far better than information in the middle. On a 20-document multi-document QA task, accuracy is around 75% when the answer sits in document 1, around 72% when it sits in document 20, and drops to roughly 55% when the answer lands in document 10. A 20-point swing driven only by position. The fix is to rerank for relevance and put the top-ranked result either at the very top or the very bottom of the retrieved block.
Recency bias. A retrieval that always returns the most recent memory works for chat-flow continuity and fails for any query that wants the right answer instead of the latest one. A user who once stated a dietary restriction will see it overridden by a more recent casual mention of pizza. The fix is a hybrid scoring function that blends recency with semantic relevance, weighted by query intent.
Missing-link recall. A purely semantic retriever cannot answer "what did Maya recommend last spring" if the stored memory phrases it as "Maya suggested a few options in March." The link between "recommend" and "suggest" is fine. The link between "last spring" and "March" needs a temporal index or an entity-linked store.
Context dilution. Retrieval pulls 20 memories when 3 are relevant. The agent's working buffer fills with marginal facts. The model attention spreads thin and the response degrades. The fix is harder pruning at retrieval time, scoring thresholds rather than fixed K, and reranking that aggressively cuts the long tail.
Diminishing returns on bigger context. A 50-experiment study by Zep on the LoCoMo benchmark with gpt-4o-mini found accuracy moved from 69.62% at a minimal retrieval budget (5 edges, 2 nodes, 347 tokens) to 80.32% at a maximum budget (30 edges, 30 nodes, 1,997 tokens). The slope flattens fast. Past the 20/20 setting, the next jump cost roughly 1.5x the tokens for 0.26 percentage points of accuracy.
More context is not free. Past a saturation point, every extra token is paid in latency, dollars, and lost-in-the-middle risk.
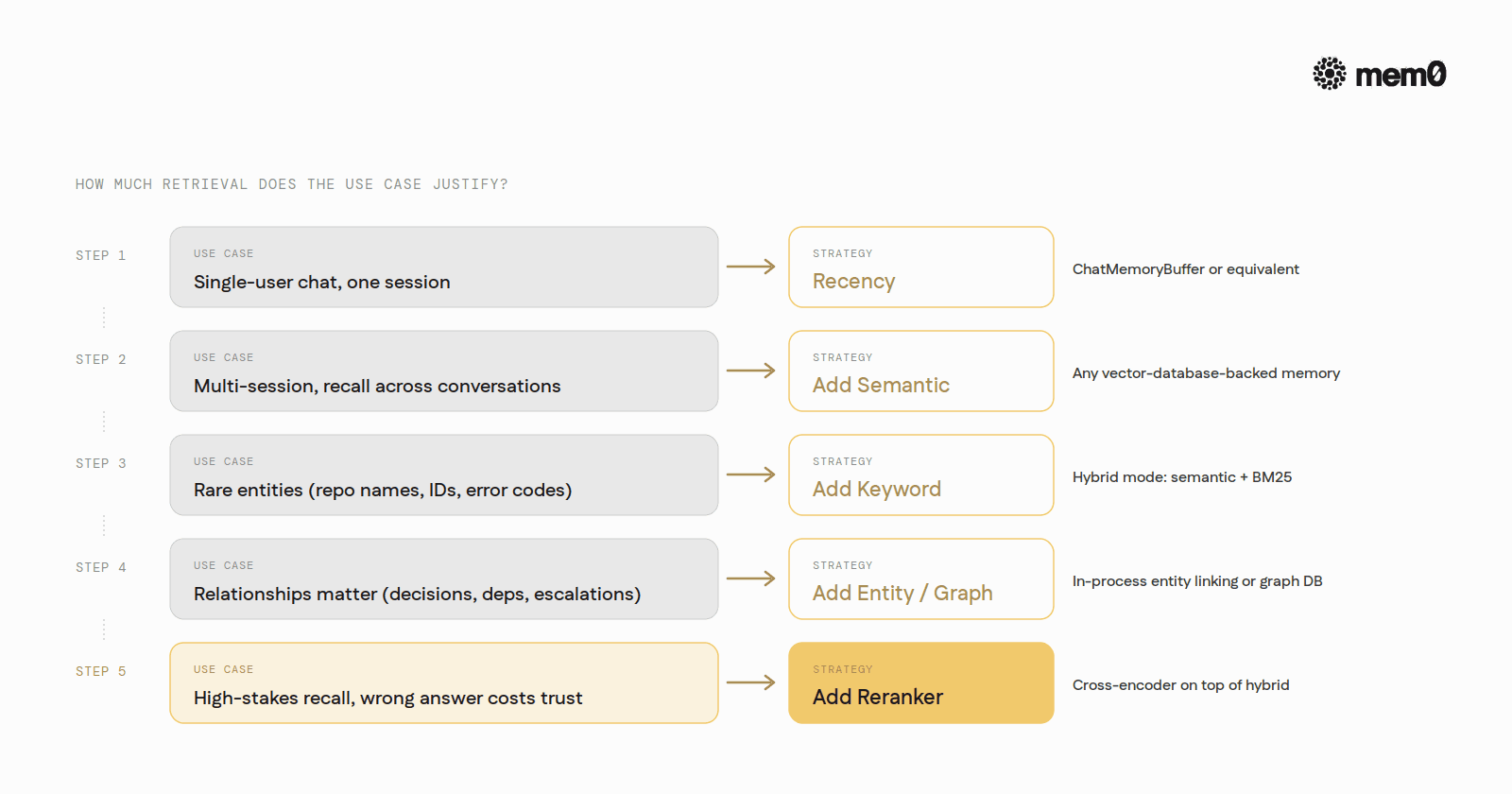
How to pick a strategy
A practical hierarchy, ordered by how much retrieval engineering the use case justifies.
For a single-user chat agent in a single session, recency is enough. Use ChatMemoryBuffer or its equivalent. Do not build a retrieval stack for a chatbot that lives for ten minutes.
For a multi-session agent that needs to recall facts across conversations, start with semantic similarity. Use any vector-database-backed memory layer.
For an agent that handles rare entities (specific repo names, account IDs, error codes), add keyword retrieval alongside semantic. Hybrid mode on Mem0, LlamaIndex, or LangChain.
For an agent whose queries depend on relationships between entities (decisions, dependencies, escalation paths), add an entity-aware or graph layer. Mem0's in-process entity linking, or a dedicated graph DB.
For an agent serving high-stakes queries where wrong recall costs the user trust, add reranking on top of hybrid. The latency cost is real. So is the precision lift.
The mistake most teams make is assuming the answer is always semantic similarity. Semantic is the right default for most queries. It is the wrong default for queries with specific entities, structural relationships, or strong recency intent.
Where Mem0 fits
Mem0 is built around the assumption that the agent should not retrieve over raw transcripts. The write path runs server-side fact extraction first, so the index is over distilled, atomic facts rather than message blobs. A 50-turn conversation collapses to a handful of facts, and similarity search runs over signal instead of noise.
The platform exposes retrieval through a single search call (client.search(query, filters={...})) with a few load-bearing parameters. top_k controls breadth. threshold filters out weak hits. rerank enables a managed cross-encoder pass at a documented cost of 150-200ms additional latency.
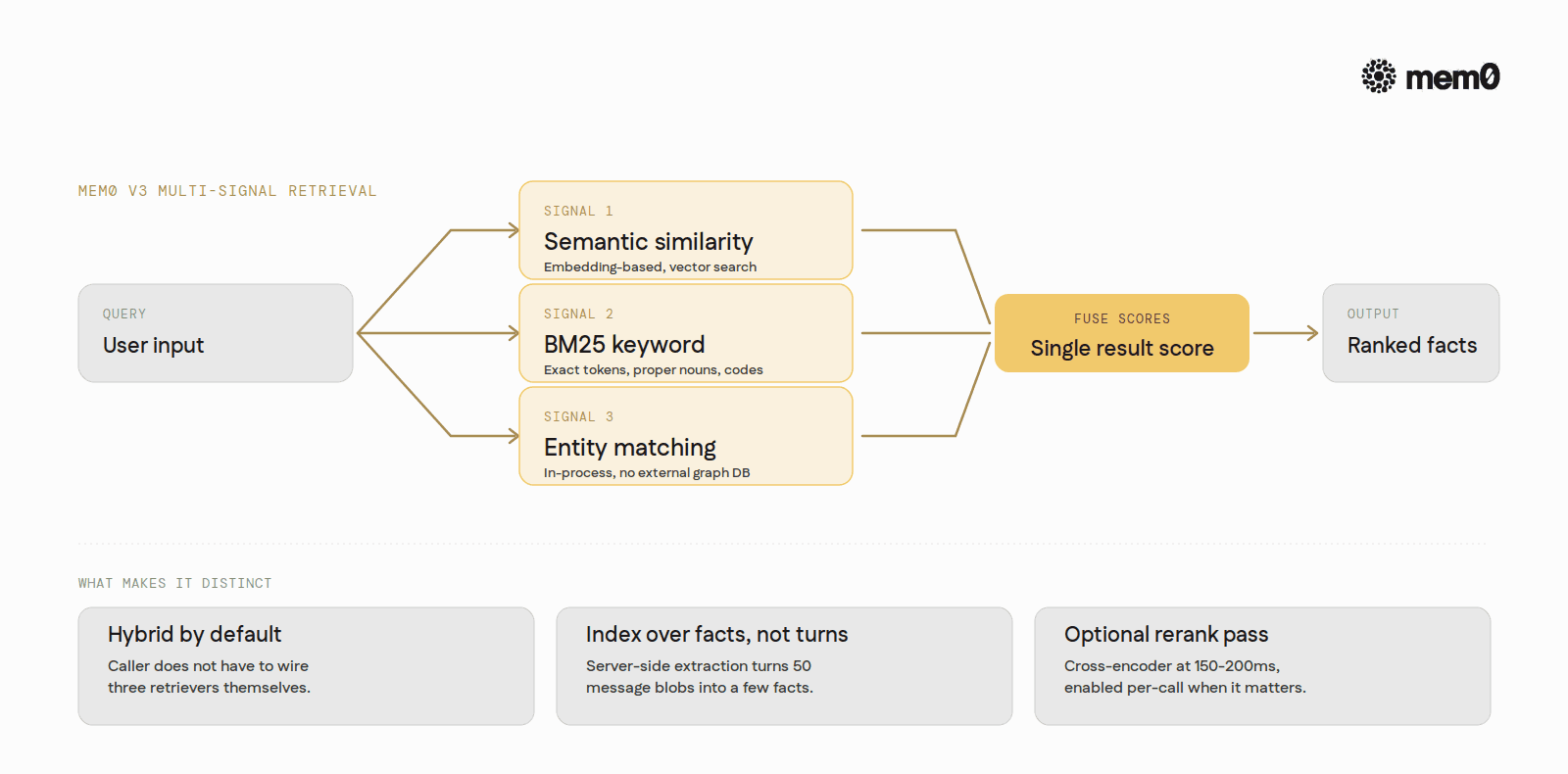
Under the hood, Mem0 V3 runs multi-signal retrieval.
Semantic,
BM25 keyword,
and entity matching are scored in parallel and fused into a single result score.
Hybrid retrieval delivered without the caller wiring three retrievers themselves.
Memory is scoped along four independent dimensions: user (user_id), agent (agent_id), app (app_id), and session/run (run_id). These are tagging dimensions, not nested layers. Every search must include at least one of them inside the filters argument, which keeps cross-user contamination out of results by construction. Writes that include both user_id and agent_id are persisted as separate records per entity to enforce privacy boundaries.
For workloads where relationships matter, Mem0 ships built-in entity linking that runs natively without an external graph store. Entities are extracted at write time and influence retrieval ranking.
Retrieval quality is bounded by what the index sees. A clean index of a few facts beats a noisy index of many turns.
The shape of the choice
Storage is commodity. Retrieval is the design surface.
The five strategies (recency, semantic, keyword, hybrid, graph) are not interchangeable. Each one fits a specific class of query and fails on a different one. The right pick is rarely "all of them at once" and never "whichever is easiest to set up."
Pick the strategy that matches what the agent's users actually ask. Add a second strategy when the first one's failure modes start showing up in real conversations. Add reranking when precision matters more than latency. Skip everything else.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

