



What both harnesses are
Hermes Agent is the open-source AI coding agent Nous Research released in early 2026, with first tagged release v0.2.0 on March 12, 2026 (github.com/NousResearch/hermes-agent). It runs as a CLI with a TUI and is built for extended tasks: sessions that run for hours or span multiple days.
OpenClaw is the open-source AI coding agent at github.com/openclaw/openclaw, with documentation at docs.openclaw.ai. It also runs as a CLI and also targets extended development work.
Both harnesses solve roughly the same problem: a coding agent that survives across sessions, accumulates context, and gets more useful over time. Both lean on markdown files for memory. Both have a Mem0 plugin. The interesting thing is how differently they got there.
Where memory lives
Hermes stores memory in two files inside ~/.hermes/memories/:
MEMORY.md: the agent's notes about the world. Hard char cap of 2,200.USER.md: the agent's notes about the user. Hard cap of 1,375.
Roughly 3,575 characters total. Entries are separated by § (the section sign, U+00A7). About 1,300 tokens that travel into every system prompt.
OpenClaw stores memory in ~/.openclaw/workspace/:
MEMORY.md: the primary long-term file. Around a 20,000-char soft target; behaviour past that point is not formally specified in the docs.memory/YYYY-MM-DD.md: daily notes. Today's and yesterday's auto-load at session start; older ones stay on disk and are searchable, but not automatically in context.DREAMS.md(optional): consolidation summaries.~/.openclaw/memory/<agentId>.sqlite: a per-agent FTS5 + vector index over everything above.
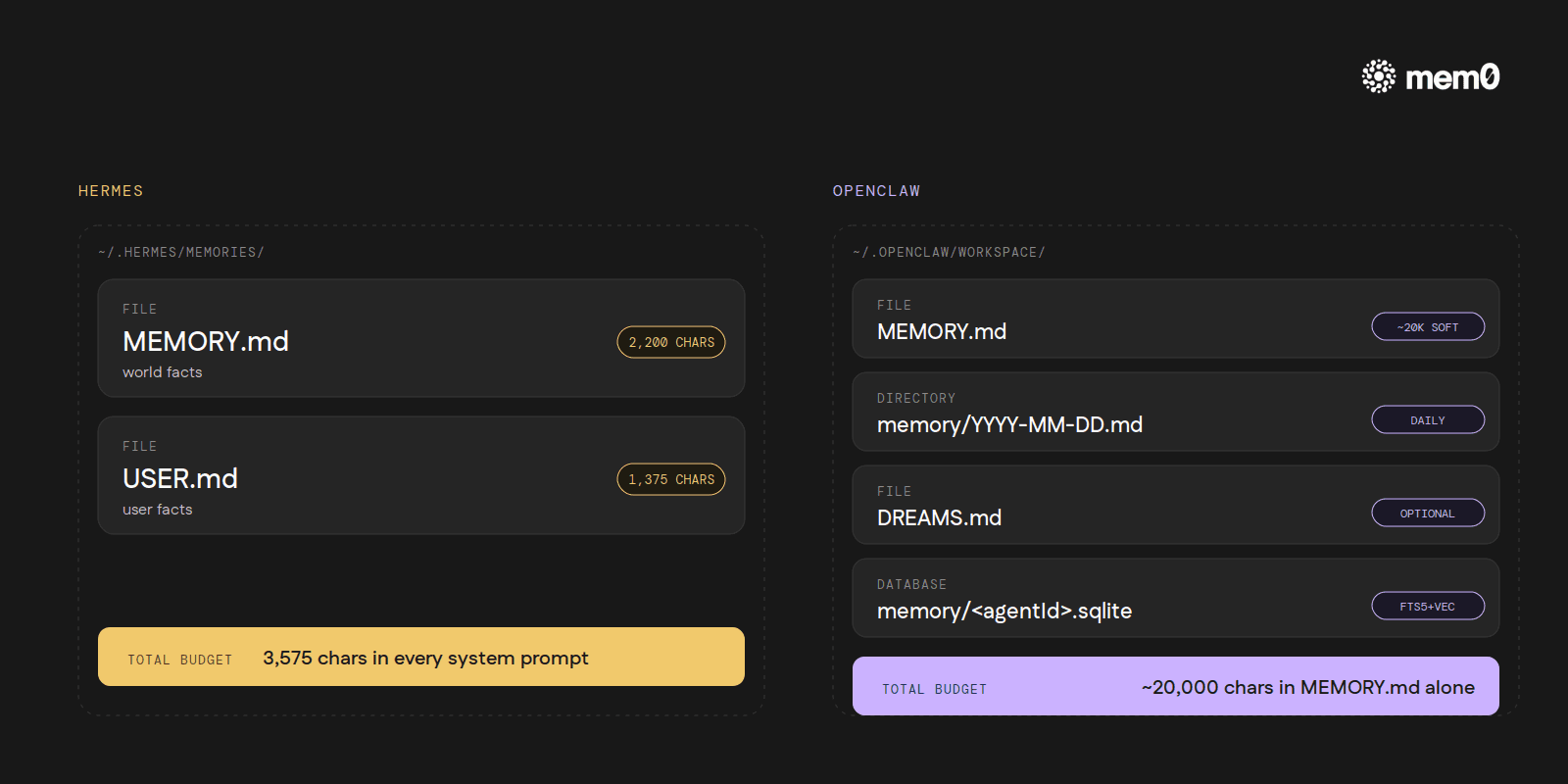
Plain markdown, no delimiter. About six times the storage budget Hermes runs with, though some of that gets paid back in token cost on every turn.
Frozen versus live system prompts
This is the deepest architectural difference, and it changes how the rest of each system feels in practice.
Hermes captures memory once, when the session starts, and pins it as a frozen block in the system prompt. When the agent calls the memory tool to add or remove entries, those changes go to disk immediately. The system prompt for the rest of the session does not move. New entries only show up at the next session start.
The reason is prefix caching. Every major LLM provider caches the start of every prompt so subsequent turns can reuse those tokens at a fraction of the cost. As long as the system prompt doesn't change, the cache holds.
Hermes makes the trade explicitly: stable, cached system-prompt input across an entire long session in exchange for a slightly worse memory experience inside a single session. The agent can't recall something it just wrote until the next conversation.
OpenClaw goes the other way. MEMORY.md is re-injected fresh every turn as part of the system prompt's "Project Context → Workspace Files" block. Mid-session writes are visible immediately on the next turn. Freshness is built in. The cost is token overhead: maintainers report 20-30% of every turn's input is bootstrap files re-shipped each time, and the underlying redundancy (large MEMORY.md files getting fully injected even when memory_search and memory_get are available) is tracked.
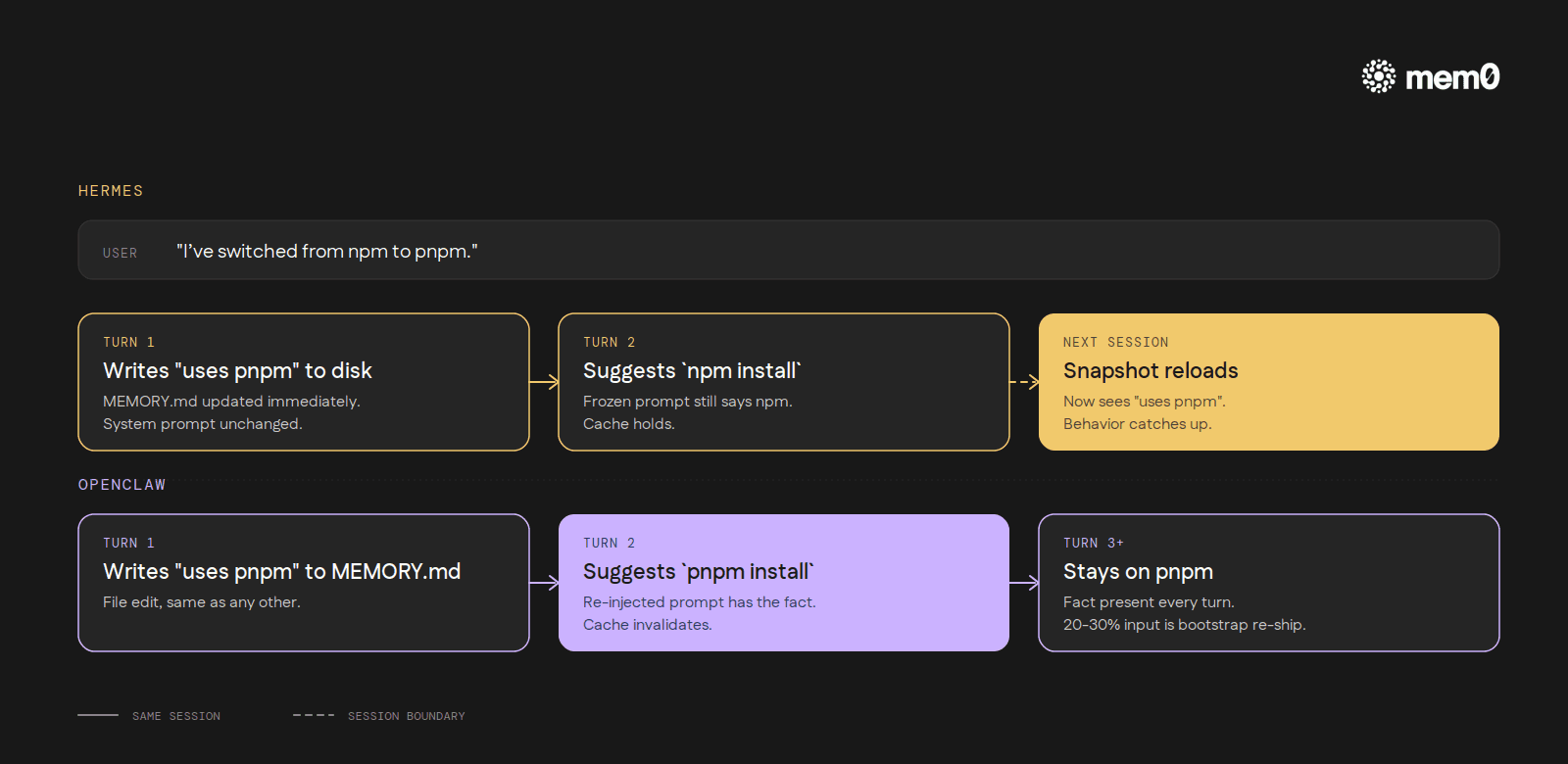
What this looks like in practice: say a user mentions mid-session that they've switched their preferred package manager from npm to pnpm. Hermes writes that fact to MEMORY.md immediately and the agent acknowledges it, but the system prompt it's reading from for the rest of the session still reflects the old state.
The fix is on disk. It won't be visible until the next session start. OpenClaw's agent, reading from the live-injected MEMORY.md, picks up the change on the very next turn and starts using pnpm without being reminded.
Two coherent answers to the same trade-off. Hermes optimizes for cache-stable long sessions. OpenClaw optimizes for immediate visibility. Neither is wrong. They're different bets about what a developer using the tool actually does for hours at a time.
How the agent reads and writes memory
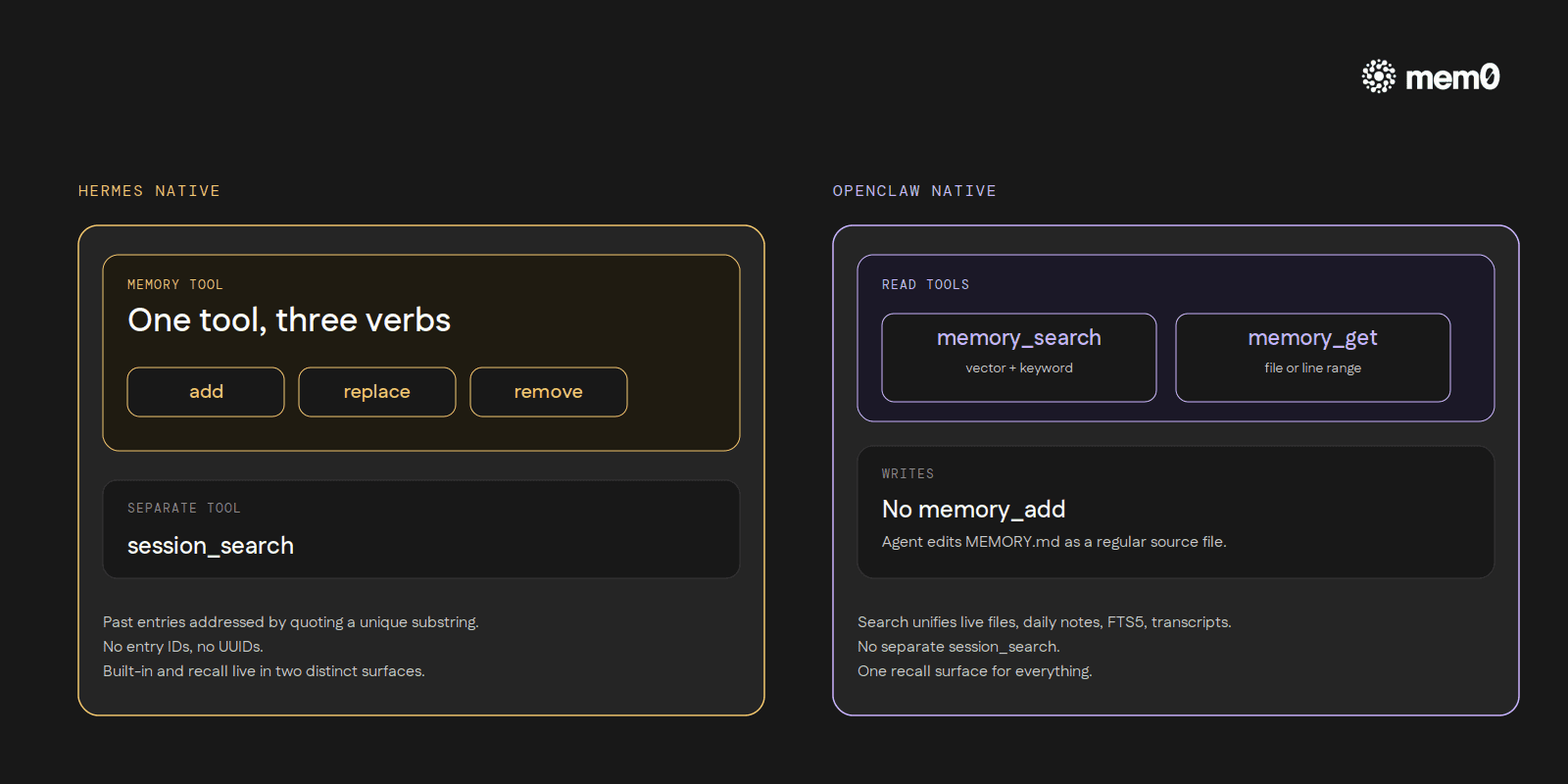
Hermes exposes a single memory tool with three actions: add, replace, and remove. Add appends a new entry to either the world-facts file or the user-facts file, and rejects exact duplicates.
Replace finds an existing entry by a substring match of its text and swaps it for new content. Remove uses the same substring-match pattern to delete an entry. There are no entry IDs, no UUIDs. The model addresses past entries by quoting a unique substring of them.
OpenClaw natively exposes two read tools (per docs.openclaw.ai/concepts/memory). memory_search runs hybrid retrieval that combines vector similarity (semantic meaning) with keyword matching (exact terms like IDs and code symbols). memory_get reads a specific memory file or line range.
Writing happens via direct file editing. The agent edits MEMORY.md the same way it would edit any other source file. There is no native memory_add. Installing the Mem0 plugin replaces the native two-tool surface with an eight-tool one (memory_search, memory_add, memory_list, memory_get, memory_update, memory_delete, plus two event-monitoring tools in Platform mode).
Two design philosophies. Hermes treats memory as a constrained API surface: three verbs, one tool, designed to make the model think carefully about what it's writing. OpenClaw treats memory as a file the agent already knows how to edit, plus a search tool over everything.
Cross-session recall
Both harnesses index past conversations with FTS5 over SQLite. The split is in how that surface is exposed.
Hermes runs an FTS5 index inside ~/.hermes/state.db and exposes it through a separate session_search tool. When a user references something from a past conversation, the agent calls session_search, gets back relevant turns, summarizes them, and proceeds. Built-in memory and session search are two distinct surfaces with two distinct tools.
OpenClaw unifies the two. memory_search searches across the live MEMORY.md, daily notes, the FTS5 index, and exported session transcripts in one call. There is no separate session_search tool. The trade-off is that the agent doesn't have to choose between recall surfaces, but it also gets a less explicit signal about what kind of recall it's doing.
OpenClaw also supports multiple search backends (the builtin SQLite, QMD, Honcho, LanceDB) configurable via agents.defaults.memorySearch. Hermes is single-backend (FTS5 only) for the built-in path.
OpenClaw also ships an optional active memory mode. When enabled, a blocking sub-agent fires before the model generates each reply. It searches stored memory against the current message and injects relevant facts into the context before the main turn begins.
The mode only activates for interactive persistent sessions, not headless tasks or one-shots, and recent mode (current message plus a short conversation tail) is the recommended default. Hermes has no equivalent. Its session_search is always agent-initiated: recall happens when the model decides to ask, not before every response.
What OpenClaw adds that Hermes doesn't
Hermes has no auto-compaction primitive. When MEMORY.md hits 2,200 characters, the next write fails with an error and the agent has to consolidate by hand. No silent garbage collection, no LRU, no sliding window.
OpenClaw has both compaction and consolidation, and they're worth describing because they don't exist in Hermes at all.
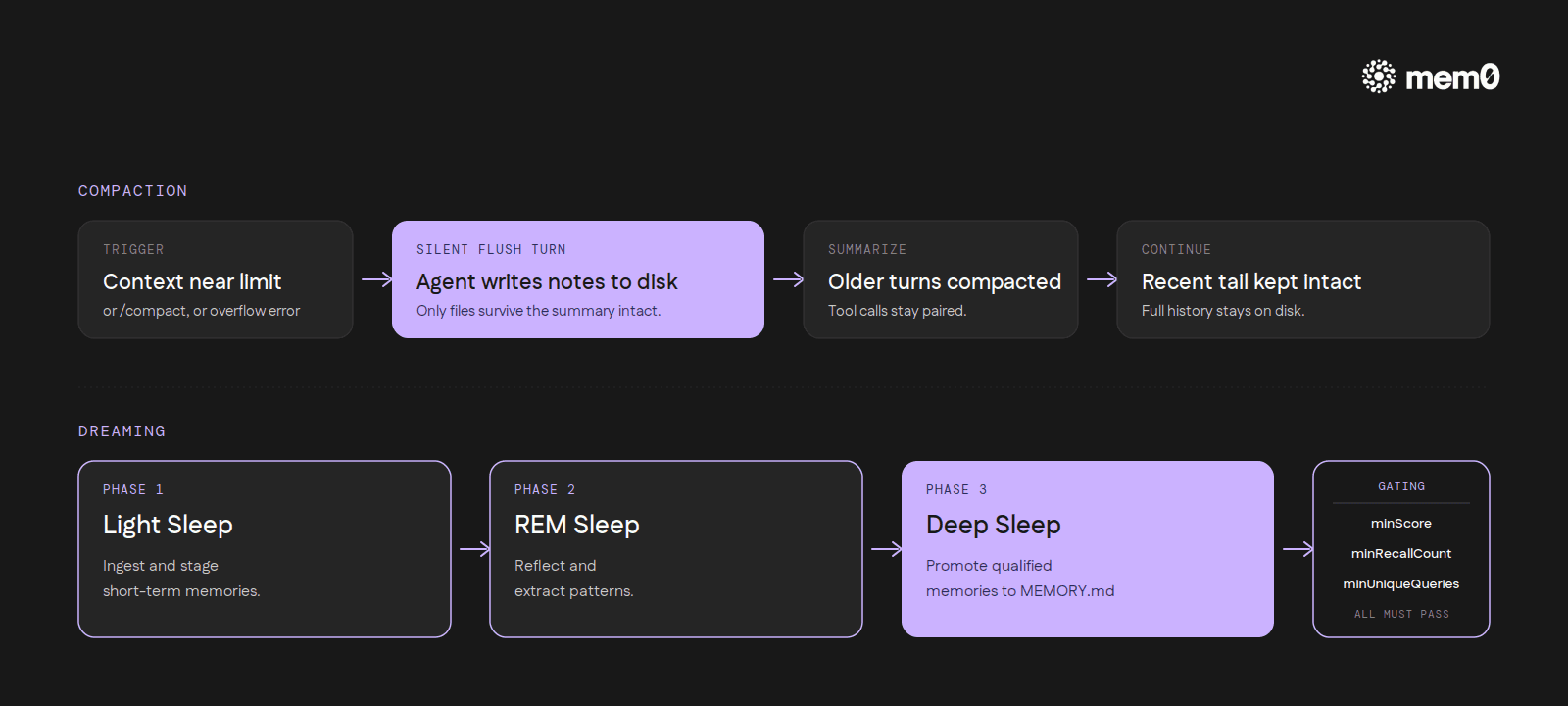
Auto-compaction is enabled by default. When a session nears the context limit, or the model returns a context-overflow error, OpenClaw summarizes older turns into a compact entry, keeps the recent messages intact, and continues. The split logic is careful about pairing: assistant tool calls stay grouped with their toolResult entries even if a chunk boundary would otherwise fall inside the pair. Manual trigger is /compact.
The full conversation history stays on disk; compaction only changes what the model sees on the next turn (docs.openclaw.ai/concepts/compaction). Configuration lives under agents.defaults.compaction, with knobs for the summarization model, a keepRecentTokens tail size, a maxActiveTranscriptBytes byte threshold, and truncateAfterCompaction to control whether successor transcripts get created.
The most distinctive piece is the pre-compaction memory flush.
Before summarization actually runs, OpenClaw can fire a silent memory-flush turn that nudges the agent to write durable notes to disk. The docs put it this way: "Before compaction, OpenClaw automatically reminds the agent to save important notes to memory files. This prevents context loss." The principle is simple: compaction summarizes the in-context conversation, so only what got committed to files survives that summary intact.
Dreaming is OpenClaw's optional consolidation mechanism, three phases run in the background (docs.openclaw.ai/concepts/memory):
Light Sleep: ingest and stage short-term memories.
REM Sleep: reflect and extract patterns.
Deep Sleep: promote qualified memories to
MEMORY.md.
Promotion is gated by three thresholds, all of which must pass: minScore, minRecallCount (the memory has been recalled at least N times), and minUniqueQueries (triggered by at least N distinct search queries). A weighted scoring rule combines relevance, frequency, query diversity, recency, consolidation, and conceptual richness; the exact thresholds and weights are configured under agents.defaults.memory.dreaming in the OpenClaw memory config. Only memories that prove themselves useful across multiple recalls get promoted.
The Hermes design assumes the model can be trusted to manage 3,575 characters of memory directly. OpenClaw assumes a larger memory will accumulate noise, and builds machinery to filter and consolidate it.
How Mem0 fits in both
Both harnesses ship with a Mem0 plugin. Whichever harness you run, Mem0 is the cross-tool persistence layer.
For Hermes, Mem0 is one of eight external providers, with the integration documented at docs.mem0.ai/integrations/hermes. Activation is a single command:
Picking mem0 as the provider writes memory.provider: mem0 into ~/.hermes/config.yaml and stores the API key in ~/.hermes/.env as MEM0_API_KEY. Three Mem0 tools land on the agent's tool surface: mem0_profile, mem0_search, mem0_conclude. After each turn, Hermes ships the user/assistant exchange to Mem0 in a background thread for server-side fact extraction, so a slow or failed Mem0 call never blocks the conversation. A circuit breaker pauses calls for 2 minutes after 5 consecutive failures.
For OpenClaw, Mem0 is the npm package @mem0/openclaw-mem0, documented at docs.mem0.ai/integrations/openclaw.
The CLI install is two commands:
(A chat-based path also exists at mem0.ai/claw-setup for users who prefer it.)
The plugin adds eight memory tools: memory_search, memory_add, memory_list, memory_get, memory_update, memory_delete, plus memory_event_list and memory_event_status for monitoring background events.
It runs in two modes: Platform (conversations sent to api.mem0.ai for extraction and storage, requires MEM0_API_KEY) or Open-Source (no Mem0 API key needed; uses OpenAI gpt-5-mini for fact extraction and text-embedding-3-small for embeddings by default, with configurable backends).
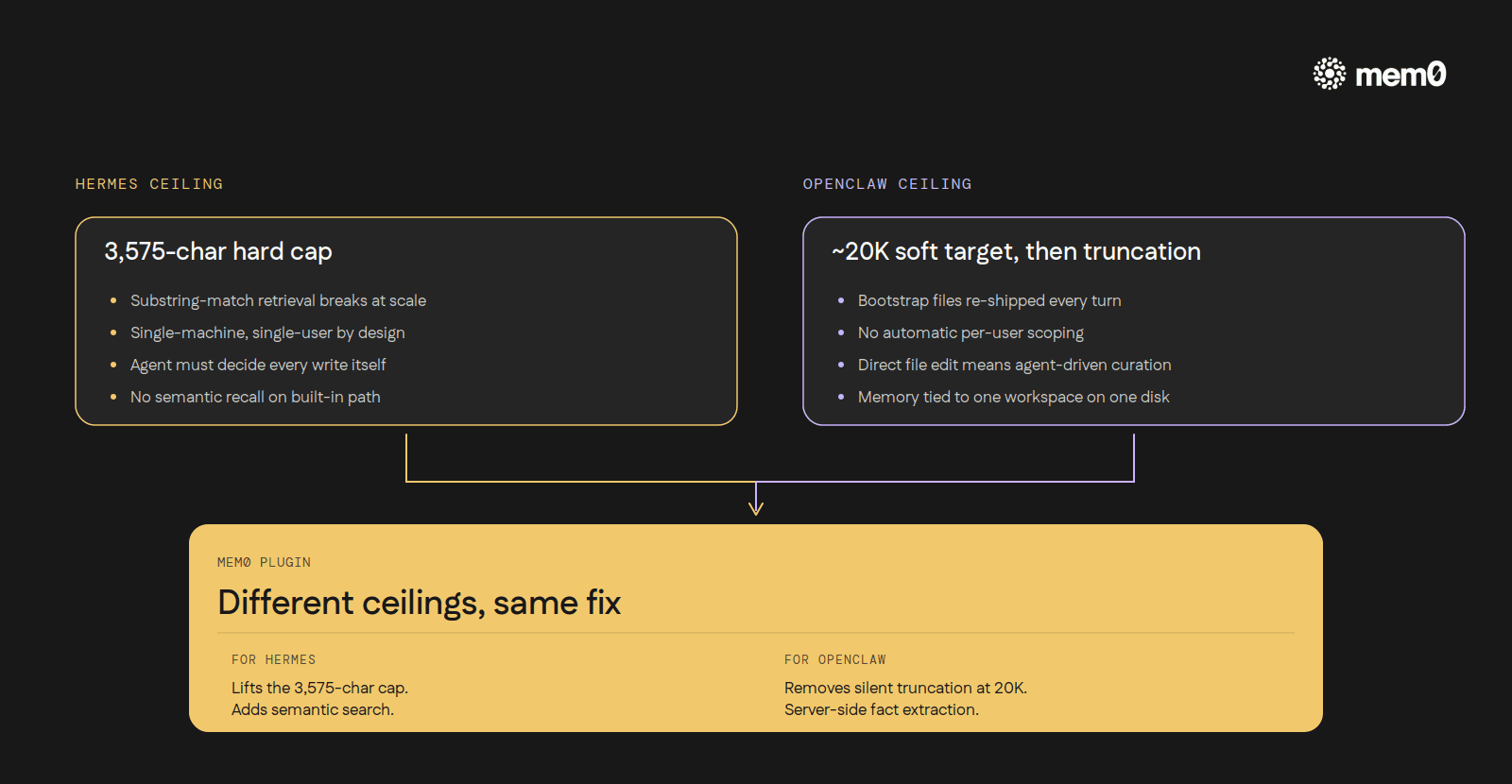
In Hermes, Mem0 fixes the 3,575-char ceiling and the substring-match retrieval. In OpenClaw, it fixes the silent-truncation-at-20k problem and adds server-side extraction so the agent doesn't have to remember to write things down. Different ceilings, same fix
In OpenClaw the integration runs in skills mode by default, which uses a triage / recall / dream protocol the plugin ships with: triage extracts facts from the conversation, recall pulls relevant stored memories before the next reply, and dream consolidates entries on a longer cadence.
The plugin also exposes autoRecall and autoCapture flags for setups that prefer a flag-driven approach, but in skills mode they're ignored in favor of the protocol. Either way, per-user scoping lands automatically: each user's userId (which defaults to the OS username if unset) scopes their memory, so facts about one developer's project stay separate from another's environment without anyone managing that separation by hand.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

