



The Claude Agents SDK is open source ( github.com/anthropics/claude-agent-sdk-python) and gives developers programmatic access to the same agent loop that powers Claude Code. Within a session, the SDK tracks everything the agent does.
Across sessions, that state does not carry over to individual users automatically. Understanding this boundary is the starting point for building agents that remember.
What the Claude Agents SDK Is
The SDK (pip install claude-agent-sdk / npm install @anthropic-ai/claude-agent-sdk) exposes Claude's agentic capabilities as programmable Python and TypeScript interfaces. It runs the agent loop inside the developer's own process, giving teams full control over execution environment, tool permissions, and session handling.
The SDK ships with built-in tools the agent can invoke autonomously, grouped by purpose:
File and code:
Read,Write,Edit,Glob,GrepExecution:
BashWeb:
WebSearch,WebFetchInteraction:
Monitor,AskUserQuestion
Developers select which tools are available per invocation via ClaudeAgentOptions(allowed_tools=[...]). The agent loop handles tool execution without any user-side orchestration code.
The SDK supports hooks that fire at agent lifecycle points:
Tool events:
PreToolUse,PostToolUse,PostToolUseFailureAgent lifecycle:
Stop,SubagentStart,SubagentStop,PreCompactSession events:
UserPromptSubmit,Notification,PermissionRequest
Subagents let the main agent spawn specialized agents defined with AgentDefinition(description=..., prompt=..., tools=[...]). MCP servers connect the agent to external systems via the Model Context Protocol.
How Session State Works
The SDK tracks conversation history within a session through a SessionStore interface. Everything that happens during a run (the user's prompt, every tool call, every tool result, every model response) is accumulated as session state. The agent has full context from everything that happened earlier in the same session: files it has read, analysis it has performed, decisions it has reached.
The built-in implementation is InMemorySessionStore. The SDK marks this explicitly as not suitable for production, because all session state is lost when the process exits. For production deployments, developers implement the SessionStore protocol backed by persistent storage; the SDK ships examples for file-based, Redis, PostgreSQL, and S3 stores.
Session continuity works through the resume option. A session ID is returned on the ResultMessage at the end of a run. Passing that ID to the next invocation picks up the conversation exactly where it left off.
Within a session, the agent never re-reads files it already examined, never repeats analysis it already performed, and never loses its chain of reasoning mid-task. Session state handles this well.
What Session State Does Not Cover
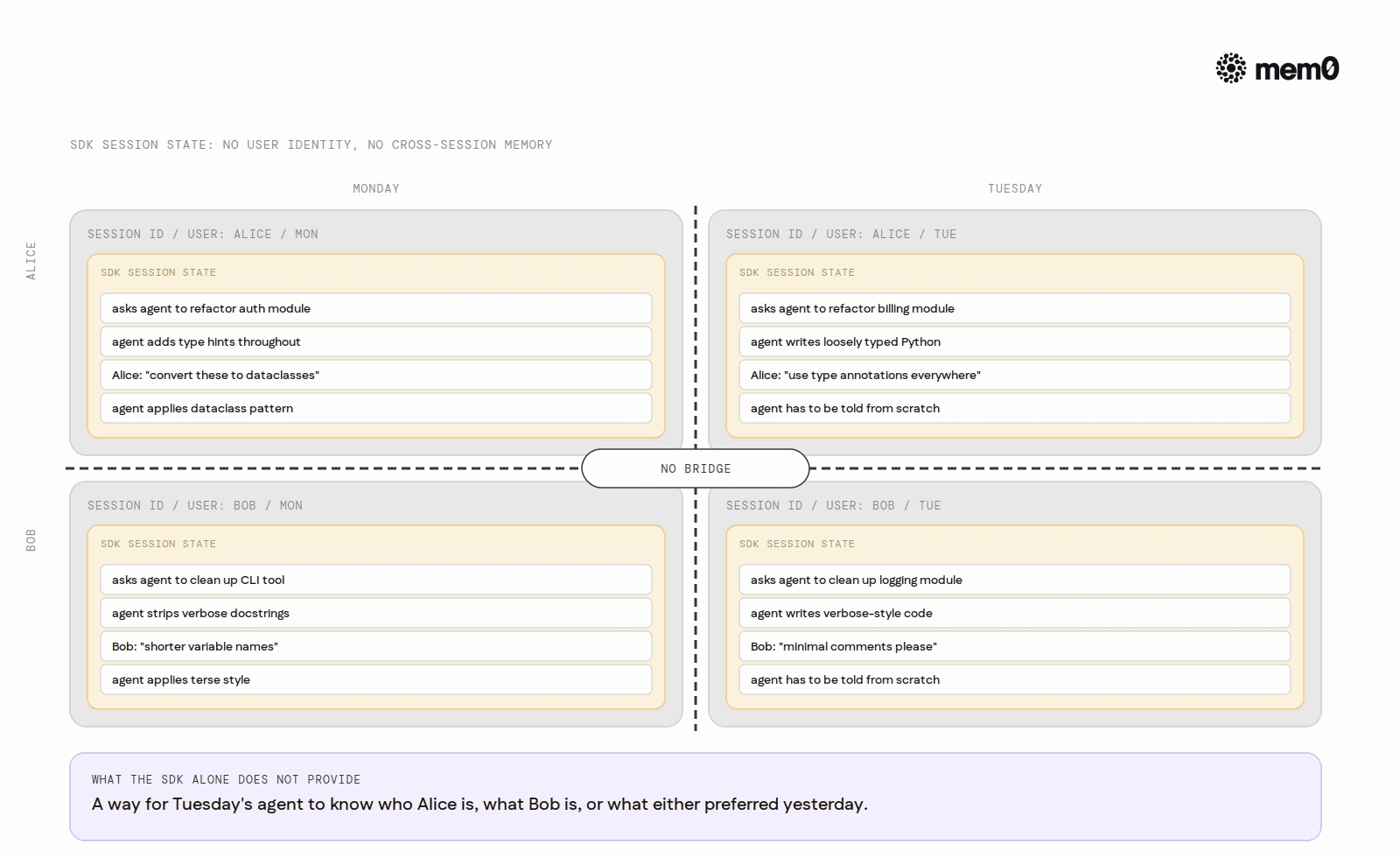
Session state is keyed by session ID, not by the person who triggered it. There is no user-identity layer in the SDK's session model. Two developers using the same agent accumulate state in separate sessions, but neither session carries any knowledge of the other developer's preferences, patterns, or history.
More importantly, session state does not carry over between separate sessions for the same user. A developer tells the agent on Monday that they prefer function-level docstrings and dislike inline comments. The agent applies that throughout the session. On Tuesday they start a new session. That preference is gone; the agent has no record of it.
This is not a flaw in the SDK's design. Session state is designed to capture what happened in a run, not to build a profile of who the user is across runs. Those are different concerns, and the SDK deliberately handles only one of them.
The Gap at Scale
The boundary between session state and persistent user context becomes visible quickly in real deployments.
A coding agent deployed across an engineering team: one developer prefers type annotations and dataclasses, another prefers minimal comments and direct variable names. Neither preference is stored anywhere. Every session starts from scratch. The agent cannot adapt to individual developers even after months of use.
A single developer using the agent daily to review code: by week three, the agent has no accumulated knowledge of that developer's style, the codebase's specific conventions, or the recurring issues they care about. Each session is a first meeting.
What is missing is user-specific context that persists across sessions and is retrieved at the start of each new one.
Session State vs. Persistent User Memory
Dimension | SDK Session State | Persistent User Memory |
|---|---|---|
Scope | One session, one process | Cross-session, cross-process |
User differentiation | None, keyed by session ID | Per-user via identifier |
Built-in persistence | No (InMemorySessionStore by default) | Yes (external store) |
Survives process exit | Only if custom SessionStore is wired | Yes |
Retrieval method | Full session context loaded | Relevance-ranked semantic search |
Best for | Within-run continuity | User-specific context across sessions |
Limitations
The pluggable SessionStore model puts operational burden on the developer. Wiring a Redis or PostgreSQL session store requires infrastructure work beyond the SDK itself. The built-in InMemorySessionStore works for development and testing but becomes a problem in production if the distinction goes unnoticed.
Adding a persistent memory layer introduces latency at session start and end; search and retrieval are network calls. For latency-sensitive applications this cost needs to be measured and budgeted for.
User-specific memory is only as good as the interactions that produce it. Vague or low-signal exchanges produce low-quality stored context. There is no automatic mechanism for resolving contradictions when a user's preferences change across sessions; that requires handling at the application level.
Where Mem0 Fits
Mem0 provides the persistent, user-specific memory layer that sits alongside the SDK's session state. At the end of each agent run, relevant exchanges are stored under the user's identifier. At the start of the next run, the most relevant stored context is retrieved and injected into the prompt before the agent begins work.
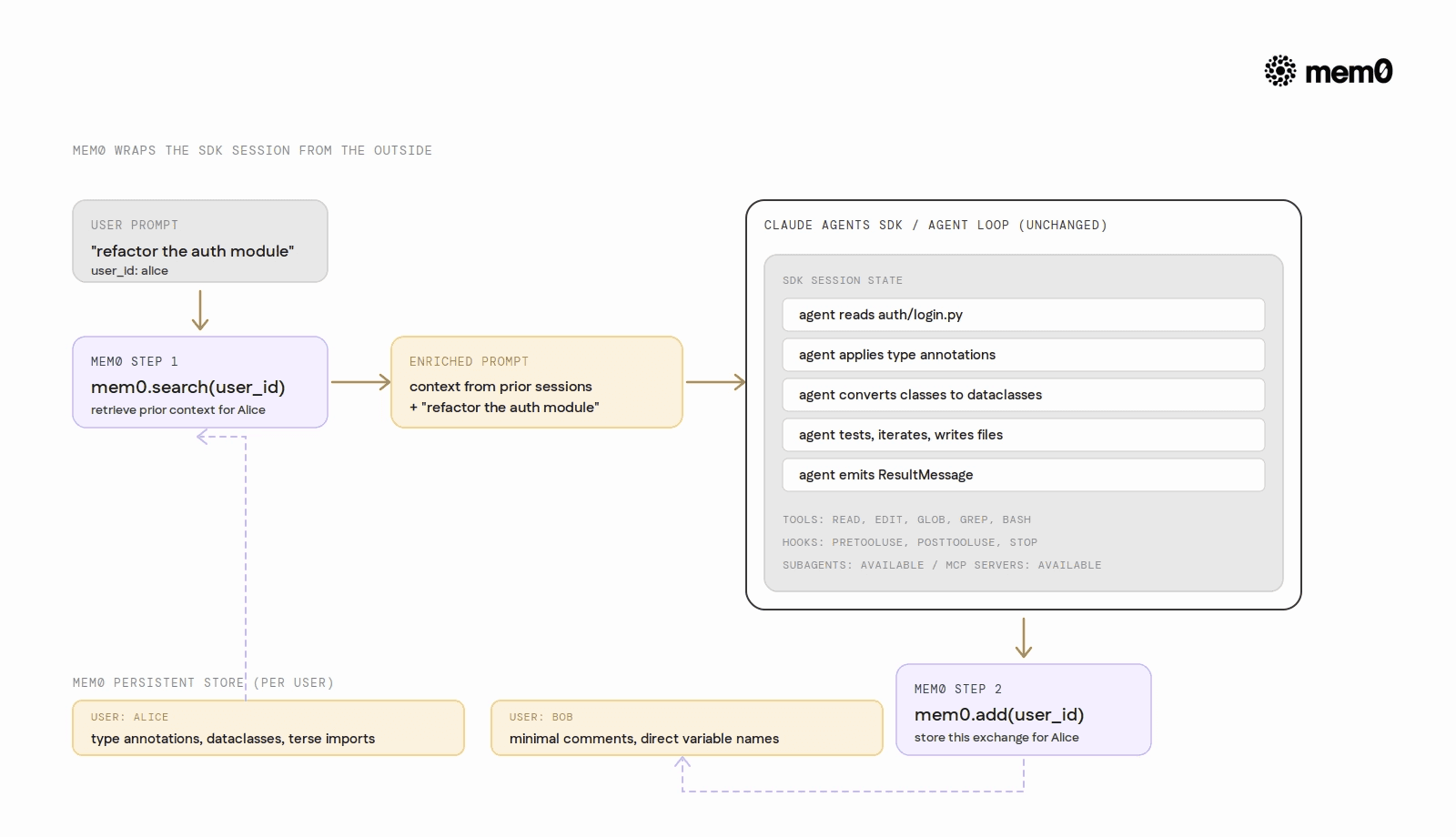
The SDK's session handling is unchanged. Mem0 wraps it from the outside, adding the user-identity and cross-session persistence that session state alone does not provide. Each user's context grows more complete over time without any changes to the underlying agent loop.
Final Notes
The Claude Agents SDK handles session state well: within a run, the agent has full context of everything it has done. What it does not include is a mechanism for building user-specific context that persists and grows across sessions. Mem0 is the layer that fills that gap, turning a stateless-per-session agent into one that genuinely improves the longer it works with a user.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

