Most AI agents lack proactive memory by design i.e, the user sends a message, then the agent searches memory and responds. Hence, the user is always the trigger.
That design works, until it doesn't. The user opens a file they've been stuck on for three days. The agent says nothing. Meanwhile, in memory, there's a note from the previous session: "blocked on OAuth token refresh in auth.py, revisit Thursday." The agent has the context. It just never fires it, because nobody asked.
This is the gap proactive memory closes: retrieval triggered by context, not by the user. Not reactive retrieval where retrieval is triggered by context, by what's happening right now, by what the agent already knows is relevant before the user has to explain it again.
This article breaks down what proactive memory is, the cognitive science behind it, what recent research says, how it's architected into three distinct patterns, and how to build the simplest version with Mem0.
Why AI Agents Forget?
Imagine you have a great colleague. When you come back from a long weekend, they don't wait for you to ask "what did we decide last week?" They bring it up when it becomes relevant ie., when you open the right file, when you mention the right project, when the context matches something they know matters.
That behavior is called prospective memory. It describes memory that's scheduled to fire at a future moment based on a trigger, rather than retrieved on demand. "When I see John, tell him about the Thursday meeting." It's memory attached to a future context, not a past query.
AI agents today have excellent retrospective recall so, when you ask them what you discussed last week and they'll find it. They have essentially zero prospective recall. No mechanism exists to say: "when this user opens auth.py again, surface the OAuth blocker." The trigger is always the user typing something. The agent is permanently in answer mode.
Beyond Static Summarization: Proactive Memory Extraction for LLM Agents (ProMem, arXiv:2601.04463) is a recent paper that formalizes the problem from the extraction side. It identifies two structural failures in how current memory systems store information in the first place:
Feed-forward extraction: Memory summarization happens before the agent knows what future tasks will need. According to Recurrent Processing Theory (Lamme, 2006), this is a blind forward pass with no feedback loop. The agent summarizes a conversation without knowing which details will matter in three weeks. Small but critical specifics get dropped.
One-off extraction: In this, the current systems extracts once. If the extraction makes a mistake or misses something, that error persists in memory permanently. There's no second pass, no self-correction, no way to recover what was dropped.
Another paper titled: PASK: Toward Intent-Aware Proactive Agents with Long-Term Memory (arXiv:2604.08000) addresses the surfacing side. Its central finding is that most AI systems are good at either helping when needed or staying silent when not needed, but not both. True proactivity requires knowing when not to fire just as much as knowing when to fire. This is harder than it sounds, and it's the problem that separates proactive memory from just injecting everything into every context window.
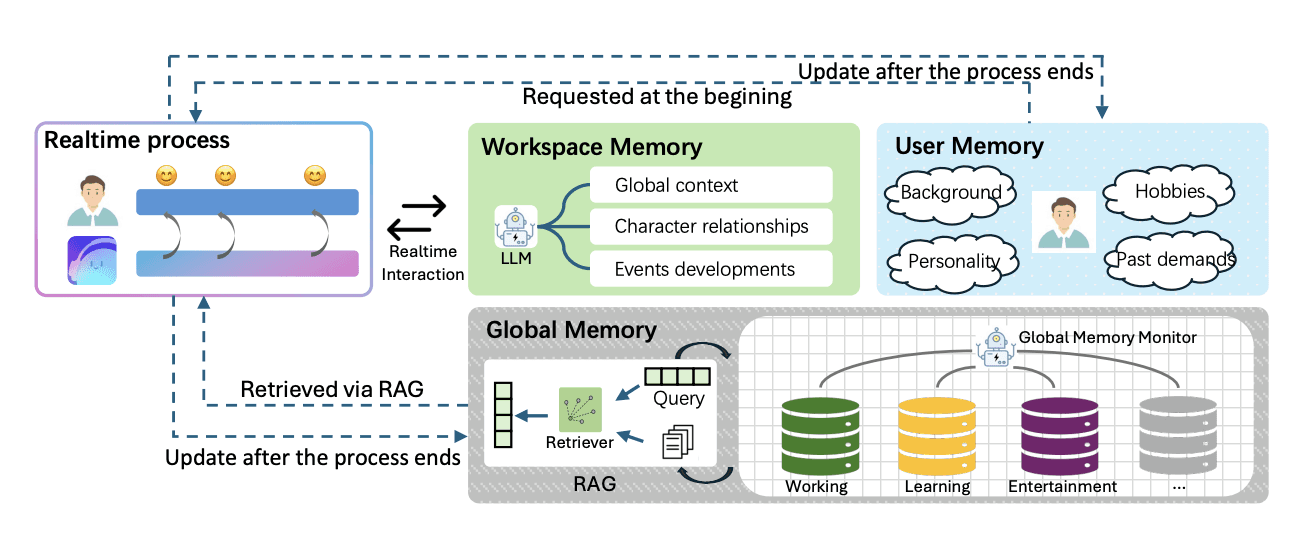
Internal architecture of PASK(source)
Together, these two papers define the shape of the problem: memory that's more completely extracted and more intelligently surfaced. Neither aspect is fully solved and both are tractable.
Three Patterns for Implementing Proactive Memory
Proactive memory isn't a single technique. It's better understood as three distinct patterns, each firing at a different moment and requiring different infrastructure. They can be used independently or layered.
The unifying principle across all three is the trigger that shifts from the user to the environment.
All three patterns are demoable with Mem0 — but the split is important to understand. Pattern 1 is entirely Mem0. Patterns 2 and 3 each require a small reasoning layer built outside Mem0 (an intent classifier and a reflection LLM respectively), which then hands off to Mem0 for the actual retrieval and storage. Mem0 is the persistent layer in all three; the custom layers decide when and what to give it.
Pattern 1: Session-Start Scan
The simplest form. Before the user sends their first message, query stored memories using ambient context signals you already have like current time of day, open project, recent file, last known task etc.
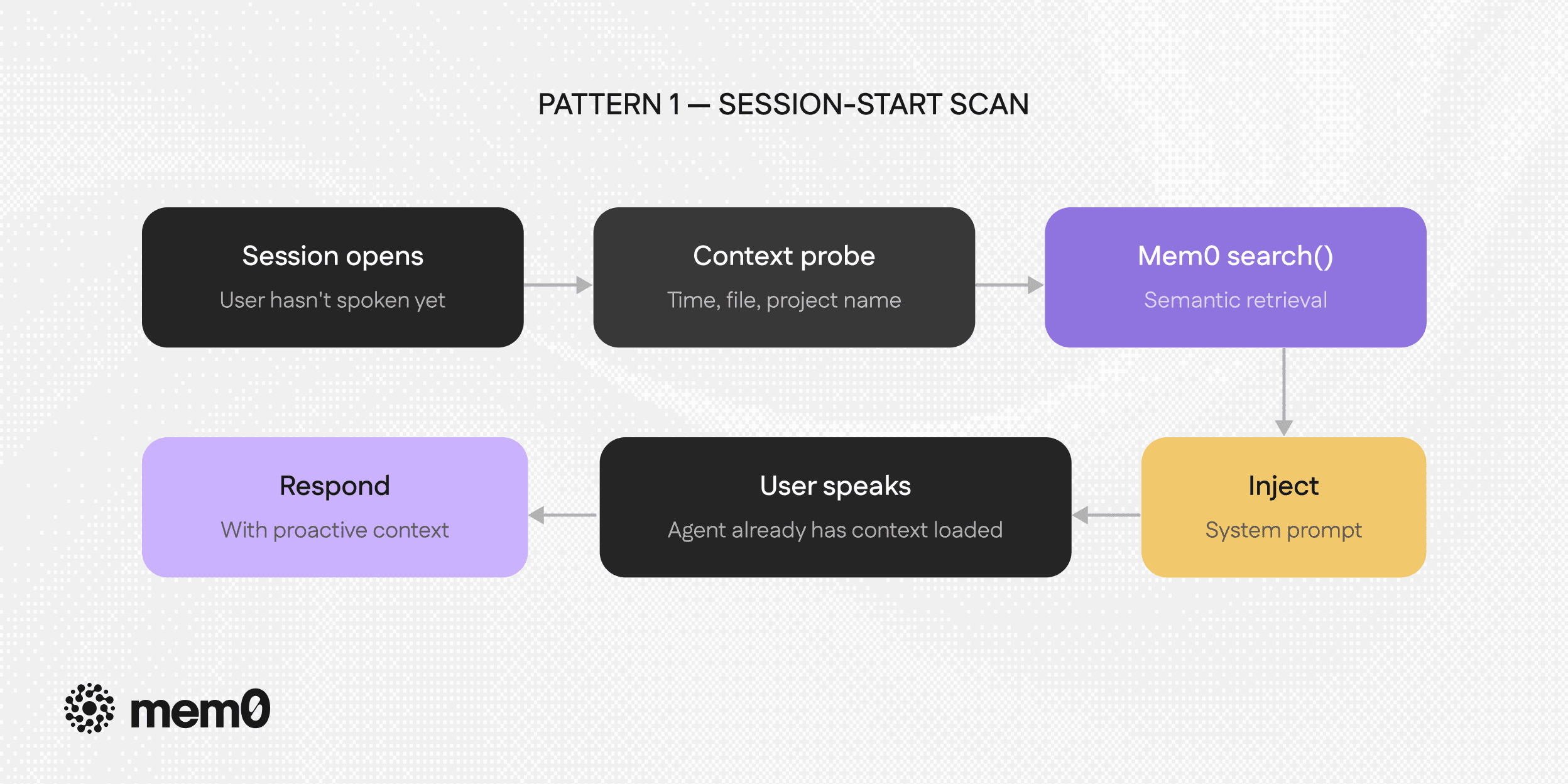
Pattern 1: Session-start scan
The agent arrives at the conversation already informed. Instead of "How can I help you today?" it can open with something that shows continuity because it actually has it.This pattern requires no new infrastructure. One extra search call at session open, ideally async while the UI loads so the user doesn't feel any latency.
Demo
Here's a minimal implementation using Mem0:
import os
from datetime import datetime
from typing import Any
from mem0 import MemoryClient
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
mem0_client.add([
{"role": "user", "content": "I'm blocked on the OAuth token refresh in auth.py. The await chain is the issue."},
{"role": "assistant", "content": "You need to await store_token() before the retry fires."},
{"role": "user", "content": "Also, we moved to Postgres for this project."},
], user_id="alice")
def session_start_scan(memory, user_id: str, context: dict, limit: int = 3) -> list[dict[str, Any]]:
"""Pattern 1: search before the first user message using ambient context."""
hour = datetime.now().hour
time_of_day = "morning" if hour < 12 else "afternoon" if hour < 17 else "evening"
project = context.get("project", "")
filename = context.get("open_file", "")
query = "What was this user recently working on or blocked by"
if project:
query += f" in project {project}"
if filename:
query += f" related to {filename}"
query += f"? It is {time_of_day}."
return memory.search(query, filters={"user_id": user_id}, top_k=limit)
def build_system_prompt(memories: list[dict[str, Any]]) -> str:
base = "You are a helpful coding assistant with persistent memory."
lines = [m.get("memory", "") for m in memories if m.get("memory")]
if not lines:
return base
context = "\\n".join(f"- {line}" for line in lines)
return f"{base}\\n\\n[Context from previous sessions, use naturally if relevant:]\\n{context}"
memories = session_start_scan(
mem0_client,
"alice",
{"project": "user-auth-service", "open_file": "auth.py"},
)
print(build_system_prompt(memories))import os
from datetime import datetime
from typing import Any
from mem0 import MemoryClient
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
mem0_client.add([
{"role": "user", "content": "I'm blocked on the OAuth token refresh in auth.py. The await chain is the issue."},
{"role": "assistant", "content": "You need to await store_token() before the retry fires."},
{"role": "user", "content": "Also, we moved to Postgres for this project."},
], user_id="alice")
def session_start_scan(memory, user_id: str, context: dict, limit: int = 3) -> list[dict[str, Any]]:
"""Pattern 1: search before the first user message using ambient context."""
hour = datetime.now().hour
time_of_day = "morning" if hour < 12 else "afternoon" if hour < 17 else "evening"
project = context.get("project", "")
filename = context.get("open_file", "")
query = "What was this user recently working on or blocked by"
if project:
query += f" in project {project}"
if filename:
query += f" related to {filename}"
query += f"? It is {time_of_day}."
return memory.search(query, filters={"user_id": user_id}, top_k=limit)
def build_system_prompt(memories: list[dict[str, Any]]) -> str:
base = "You are a helpful coding assistant with persistent memory."
lines = [m.get("memory", "") for m in memories if m.get("memory")]
if not lines:
return base
context = "\\n".join(f"- {line}" for line in lines)
return f"{base}\\n\\n[Context from previous sessions, use naturally if relevant:]\\n{context}"
memories = session_start_scan(
mem0_client,
"alice",
{"project": "user-auth-service", "open_file": "auth.py"},
)
print(build_system_prompt(memories))import os
from datetime import datetime
from typing import Any
from mem0 import MemoryClient
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
mem0_client.add([
{"role": "user", "content": "I'm blocked on the OAuth token refresh in auth.py. The await chain is the issue."},
{"role": "assistant", "content": "You need to await store_token() before the retry fires."},
{"role": "user", "content": "Also, we moved to Postgres for this project."},
], user_id="alice")
def session_start_scan(memory, user_id: str, context: dict, limit: int = 3) -> list[dict[str, Any]]:
"""Pattern 1: search before the first user message using ambient context."""
hour = datetime.now().hour
time_of_day = "morning" if hour < 12 else "afternoon" if hour < 17 else "evening"
project = context.get("project", "")
filename = context.get("open_file", "")
query = "What was this user recently working on or blocked by"
if project:
query += f" in project {project}"
if filename:
query += f" related to {filename}"
query += f"? It is {time_of_day}."
return memory.search(query, filters={"user_id": user_id}, top_k=limit)
def build_system_prompt(memories: list[dict[str, Any]]) -> str:
base = "You are a helpful coding assistant with persistent memory."
lines = [m.get("memory", "") for m in memories if m.get("memory")]
if not lines:
return base
context = "\\n".join(f"- {line}" for line in lines)
return f"{base}\\n\\n[Context from previous sessions, use naturally if relevant:]\\n{context}"
memories = session_start_scan(
mem0_client,
"alice",
{"project": "user-auth-service", "open_file": "auth.py"},
)
print(build_system_prompt(memories))The key design decision is in the query. It's not "find all memories", it's a specific probe shaped around what the agent knows about the current moment i.e, the time of day, the open file, the project name, etc. These are the context signals that make a session-start scan proactive rather than just a broad retrieval dump.
To use it, run session_start_scan() function before the conversation loop, inject the results into your system prompt, and continue normally. The agent arrives with relevant context already loaded. The user doesn't have to re-explain what they were working on.
The difference this makes
Consider the same opening message "Hey, back on the auth service. Where did we leave off?", sent to two versions of the same agent:
A reactive agent starts from scratch. It has memory available but hasn't searched yet, so it either asks a clarifying question or gives a generic response.
But, a proactive agent with a session-start scan has already retrieved: "User was debugging OAuth token refresh in auth.py. Identified the await chain as the likely cause. Also: project moved to Postgres." Its response to the same opening is immediate and specific.
No new infrastructure. One search call leads to meaningful difference in the quality of continuity the agent provides.
Pattern 2: Context-Trigger Scan
More intelligent than a session-start scan. Instead of firing once at the beginning, this pattern monitors the conversation for context shifts and runs a targeted memory search whenever one is detected, without the user asking.
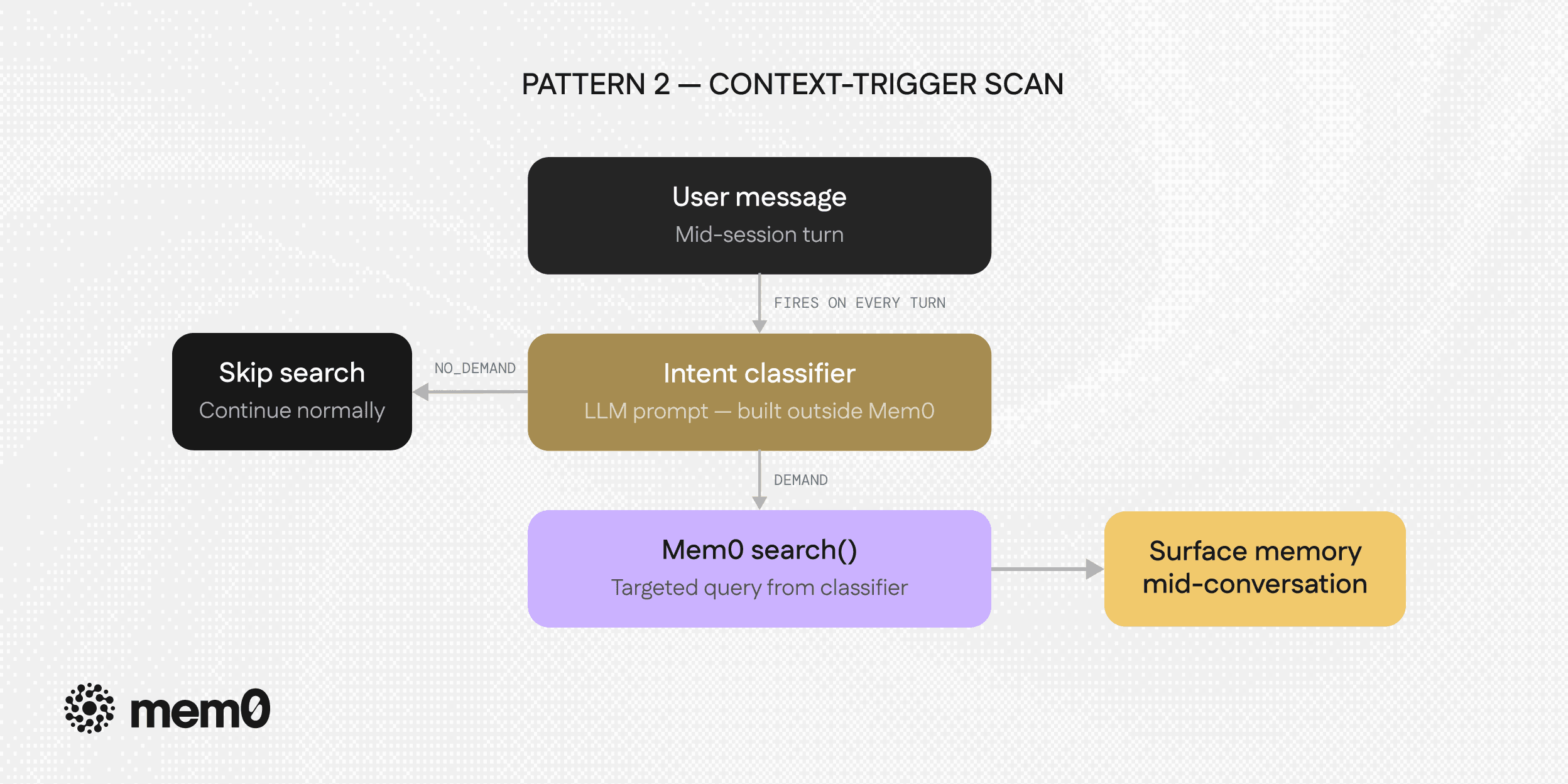
Pattern 2: Context-trigger scan
The triggers that make sense here:
File reference: User mentions or opens a specific file (’@’)
Error detected: Errors such as "exception", "failed", "broken" appears in the message
Tool invocation: The user is about to deploy, run tests, do a migration
Topic shift: The conversation moves to a clearly different domain
Each trigger carries its own search query. A file-open trigger searches for past context on that file. An error trigger searches for past debugging sessions. A migration trigger surfaces past warnings about that pipeline.
The architectural question is what generates the trigger. A simple implementation uses keyword detection which is fast, deterministic, and transparent. It works well in constrained domains where the relevant signals are predictable.
But keyword detection has a ceiling. It misses context shifts that don't contain obvious keywords. It fires on false positives as well, like the word "error" in a comment about a resolved issue. This means it can't adapt to new signal patterns without code changes.
This is where the PASK research becomes important.
The PASK paper proposes a fundamentally different trigger mechanism: a streaming IntentFlow classifier trained to make a binary DEMAND / NO_DEMAND decision on every turn. It reads the current message in the context of recent conversation history.
This is not a keyword check but an understanding of the user intent. The classifier learns that "can you add type hints to that function?" is a continuation of the current task (NO_DEMAND — search not needed) while "let's look at users.py" is a context shift that warrants surfacing past experience with that file (DEMAND).
The paper's most important finding about this classifier is what it reveals about the difficulty of the problem: most models are good at either intervening or staying silent, but not both. A model that always fires proactively annoys users with irrelevant context. A model that never fires misses exactly the moments where memory would help. The balance point here is high precision on when to surface, high recall on when something is genuinely relevant which is what the IntentFlow model is trained to find.
For production implementations today, you can approximate IntentFlow with a small LLM classification prompt that reads recent history and the current message, returning a decision and a query. It's not as fast as a fine-tuned classifier, but it captures the essential behavior: the trigger is intelligent, not rule-based.
The deeper design principle this pattern establishes is that, memory search is not free, and firing it on every turn is wrong. Proactive memory requires a gating layer that decides when the cost of retrieval is worth paying. That layer has a demand detector which is where the most interesting engineering in proactive memory currently lives.
Demo
The logic separates into two functions: detect_intent() runs the classifier (outside Mem0), and on_context_message() wires it to Mem0's search. A regex fallback ensures the classifier stays reliable even when the LLM hedges on clear demand signals:
import os, json, re
from dataclasses import dataclass
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
@dataclass(frozen=True)
class Intent:
decision: str
query: str | None = None
@property
def should_search(self) -> bool:
return self.decision == "DEMAND" and bool(self.query)
_DEMAND_PATTERNS = (
r"\\b[\\w\\-]+\\.(py|ts|tsx|js|jsx|java|go|rs|rb|sql|yaml|yml|json|toml)\\b",
r"\\b(module|component|file|config|schema|migration|deploy|deployment)\\b",
r"\\b(error|bug|blocker|failing|failure|issue)\\b",
r"\\bwhere we left off\\b",
r"\\b(last|previous)\\s+session\\b",
r"\\bpick up\\b",
r"\\bcheck\\b",
)
def _looks_like_demand(message: str) -> bool:
lowered = message.lower()
return any(re.search(p, lowered) for p in _DEMAND_PATTERNS)
def _fallback_query(message: str) -> str:
cleaned = " ".join(message.strip().split())
return cleaned[:200] if cleaned else "recent task context"
def detect_intent(chat, message: str, history: list[dict]) -> Intent:
"""Intent classifier — lives outside Mem0, decides when to search."""
recent = "\\n".join(f"{m['role']}: {m['content']}" for m in history[-4:]) or "(start of conversation)"
prompt = f"""You are an intent detection model for an AI coding assistant with long-term memory.
Your job: decide whether the latest user message warrants a search of long-term memory.
DEMAND (search memory) when the message:
- Names a specific file or module ("database.py", "auth.py", "the config module")
- References past work, a prior bug, or a previous decision ("where we left off", "that pool issue")
- Starts a new task or switches topic
- Mentions an error, blocker, or deployment step
NO_DEMAND (skip search) when the message:
- Is a short acknowledgment with no new content ("ok", "thanks", "got it", "sounds good")
- Directly continues the immediately preceding assistant reply with no new topic
Recent history:
{recent}
Latest message: {message}
Examples of correct responses:
message: "Open database.py and check the pool config"
response: {{"decision": "DEMAND", "query": "database.py connection pool configuration"}}
message: "Thanks, that makes sense"
response: {{"decision": "NO_DEMAND", "query": null}}
Now respond for the latest message. Return a JSON object only, no other text:
{{"decision": "DEMAND", "query": "..."}} or {{"decision": "NO_DEMAND", "query": null}}"""
raw = chat.complete_json(prompt, temperature=0.0)
if isinstance(raw, str):
raw = json.loads(raw)
raw_decision = str(raw.get("decision", "NO_DEMAND")).strip().upper()
decision = "DEMAND" if raw_decision.startswith("DEMAND") else "NO_DEMAND"
query = raw.get("query")
normalized_query = query if isinstance(query, str) and query else None
if decision == "NO_DEMAND" and _looks_like_demand(message):
return Intent(decision="DEMAND", query=normalized_query or _fallback_query(message))
if decision == "DEMAND" and not normalized_query:
normalized_query = _fallback_query(message)
return Intent(decision=decision, query=normalized_query)
def on_context_message(
memory,
chat,
user_id: str,
user_message: str,
history: list[dict],
limit: int = 3,
) -> dict[str, Any]:
"""Pattern 2: gate Mem0 search with the intent classifier, then respond."""
intent = detect_intent(chat, user_message, history)
memories: list[dict] = []
if intent.should_search:
memories = memory.search(intent.query or "", user_id=user_id, limit=limit)
context = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
system = "You are a helpful coding assistant."
if context:
system += f"\\n\\n[Relevant context:]\\n{context}"
reply = chat.complete_text(
[{"role": "system", "content": system}] + history + [{"role": "user", "content": user_message}]
)
return {"decision": intent.decision, "query": intent.query, "memories": memories, "reply": reply}
class OpenAIChatModel:
def __init__(self):
self.client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
self.model = "gpt-4o-mini"
def complete_json(self, prompt, *, temperature=0.0):
return json.loads(self.complete_text([{"role": "user", "content": prompt}], temperature=temperature))
def complete_text(self, messages, *, temperature=0.0):
resp = self.client.chat.completions.create(model=self.model, messages=messages, temperature=temperature)
return resp.choices[0].message.content or ""
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
result = on_context_message(mem0_client, chat_client, "alice", "Check database.py pool config", history=[])
print(result["reply"])import os, json, re
from dataclasses import dataclass
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
@dataclass(frozen=True)
class Intent:
decision: str
query: str | None = None
@property
def should_search(self) -> bool:
return self.decision == "DEMAND" and bool(self.query)
_DEMAND_PATTERNS = (
r"\\b[\\w\\-]+\\.(py|ts|tsx|js|jsx|java|go|rs|rb|sql|yaml|yml|json|toml)\\b",
r"\\b(module|component|file|config|schema|migration|deploy|deployment)\\b",
r"\\b(error|bug|blocker|failing|failure|issue)\\b",
r"\\bwhere we left off\\b",
r"\\b(last|previous)\\s+session\\b",
r"\\bpick up\\b",
r"\\bcheck\\b",
)
def _looks_like_demand(message: str) -> bool:
lowered = message.lower()
return any(re.search(p, lowered) for p in _DEMAND_PATTERNS)
def _fallback_query(message: str) -> str:
cleaned = " ".join(message.strip().split())
return cleaned[:200] if cleaned else "recent task context"
def detect_intent(chat, message: str, history: list[dict]) -> Intent:
"""Intent classifier — lives outside Mem0, decides when to search."""
recent = "\\n".join(f"{m['role']}: {m['content']}" for m in history[-4:]) or "(start of conversation)"
prompt = f"""You are an intent detection model for an AI coding assistant with long-term memory.
Your job: decide whether the latest user message warrants a search of long-term memory.
DEMAND (search memory) when the message:
- Names a specific file or module ("database.py", "auth.py", "the config module")
- References past work, a prior bug, or a previous decision ("where we left off", "that pool issue")
- Starts a new task or switches topic
- Mentions an error, blocker, or deployment step
NO_DEMAND (skip search) when the message:
- Is a short acknowledgment with no new content ("ok", "thanks", "got it", "sounds good")
- Directly continues the immediately preceding assistant reply with no new topic
Recent history:
{recent}
Latest message: {message}
Examples of correct responses:
message: "Open database.py and check the pool config"
response: {{"decision": "DEMAND", "query": "database.py connection pool configuration"}}
message: "Thanks, that makes sense"
response: {{"decision": "NO_DEMAND", "query": null}}
Now respond for the latest message. Return a JSON object only, no other text:
{{"decision": "DEMAND", "query": "..."}} or {{"decision": "NO_DEMAND", "query": null}}"""
raw = chat.complete_json(prompt, temperature=0.0)
if isinstance(raw, str):
raw = json.loads(raw)
raw_decision = str(raw.get("decision", "NO_DEMAND")).strip().upper()
decision = "DEMAND" if raw_decision.startswith("DEMAND") else "NO_DEMAND"
query = raw.get("query")
normalized_query = query if isinstance(query, str) and query else None
if decision == "NO_DEMAND" and _looks_like_demand(message):
return Intent(decision="DEMAND", query=normalized_query or _fallback_query(message))
if decision == "DEMAND" and not normalized_query:
normalized_query = _fallback_query(message)
return Intent(decision=decision, query=normalized_query)
def on_context_message(
memory,
chat,
user_id: str,
user_message: str,
history: list[dict],
limit: int = 3,
) -> dict[str, Any]:
"""Pattern 2: gate Mem0 search with the intent classifier, then respond."""
intent = detect_intent(chat, user_message, history)
memories: list[dict] = []
if intent.should_search:
memories = memory.search(intent.query or "", user_id=user_id, limit=limit)
context = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
system = "You are a helpful coding assistant."
if context:
system += f"\\n\\n[Relevant context:]\\n{context}"
reply = chat.complete_text(
[{"role": "system", "content": system}] + history + [{"role": "user", "content": user_message}]
)
return {"decision": intent.decision, "query": intent.query, "memories": memories, "reply": reply}
class OpenAIChatModel:
def __init__(self):
self.client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
self.model = "gpt-4o-mini"
def complete_json(self, prompt, *, temperature=0.0):
return json.loads(self.complete_text([{"role": "user", "content": prompt}], temperature=temperature))
def complete_text(self, messages, *, temperature=0.0):
resp = self.client.chat.completions.create(model=self.model, messages=messages, temperature=temperature)
return resp.choices[0].message.content or ""
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
result = on_context_message(mem0_client, chat_client, "alice", "Check database.py pool config", history=[])
print(result["reply"])import os, json, re
from dataclasses import dataclass
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
@dataclass(frozen=True)
class Intent:
decision: str
query: str | None = None
@property
def should_search(self) -> bool:
return self.decision == "DEMAND" and bool(self.query)
_DEMAND_PATTERNS = (
r"\\b[\\w\\-]+\\.(py|ts|tsx|js|jsx|java|go|rs|rb|sql|yaml|yml|json|toml)\\b",
r"\\b(module|component|file|config|schema|migration|deploy|deployment)\\b",
r"\\b(error|bug|blocker|failing|failure|issue)\\b",
r"\\bwhere we left off\\b",
r"\\b(last|previous)\\s+session\\b",
r"\\bpick up\\b",
r"\\bcheck\\b",
)
def _looks_like_demand(message: str) -> bool:
lowered = message.lower()
return any(re.search(p, lowered) for p in _DEMAND_PATTERNS)
def _fallback_query(message: str) -> str:
cleaned = " ".join(message.strip().split())
return cleaned[:200] if cleaned else "recent task context"
def detect_intent(chat, message: str, history: list[dict]) -> Intent:
"""Intent classifier — lives outside Mem0, decides when to search."""
recent = "\\n".join(f"{m['role']}: {m['content']}" for m in history[-4:]) or "(start of conversation)"
prompt = f"""You are an intent detection model for an AI coding assistant with long-term memory.
Your job: decide whether the latest user message warrants a search of long-term memory.
DEMAND (search memory) when the message:
- Names a specific file or module ("database.py", "auth.py", "the config module")
- References past work, a prior bug, or a previous decision ("where we left off", "that pool issue")
- Starts a new task or switches topic
- Mentions an error, blocker, or deployment step
NO_DEMAND (skip search) when the message:
- Is a short acknowledgment with no new content ("ok", "thanks", "got it", "sounds good")
- Directly continues the immediately preceding assistant reply with no new topic
Recent history:
{recent}
Latest message: {message}
Examples of correct responses:
message: "Open database.py and check the pool config"
response: {{"decision": "DEMAND", "query": "database.py connection pool configuration"}}
message: "Thanks, that makes sense"
response: {{"decision": "NO_DEMAND", "query": null}}
Now respond for the latest message. Return a JSON object only, no other text:
{{"decision": "DEMAND", "query": "..."}} or {{"decision": "NO_DEMAND", "query": null}}"""
raw = chat.complete_json(prompt, temperature=0.0)
if isinstance(raw, str):
raw = json.loads(raw)
raw_decision = str(raw.get("decision", "NO_DEMAND")).strip().upper()
decision = "DEMAND" if raw_decision.startswith("DEMAND") else "NO_DEMAND"
query = raw.get("query")
normalized_query = query if isinstance(query, str) and query else None
if decision == "NO_DEMAND" and _looks_like_demand(message):
return Intent(decision="DEMAND", query=normalized_query or _fallback_query(message))
if decision == "DEMAND" and not normalized_query:
normalized_query = _fallback_query(message)
return Intent(decision=decision, query=normalized_query)
def on_context_message(
memory,
chat,
user_id: str,
user_message: str,
history: list[dict],
limit: int = 3,
) -> dict[str, Any]:
"""Pattern 2: gate Mem0 search with the intent classifier, then respond."""
intent = detect_intent(chat, user_message, history)
memories: list[dict] = []
if intent.should_search:
memories = memory.search(intent.query or "", user_id=user_id, limit=limit)
context = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
system = "You are a helpful coding assistant."
if context:
system += f"\\n\\n[Relevant context:]\\n{context}"
reply = chat.complete_text(
[{"role": "system", "content": system}] + history + [{"role": "user", "content": user_message}]
)
return {"decision": intent.decision, "query": intent.query, "memories": memories, "reply": reply}
class OpenAIChatModel:
def __init__(self):
self.client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
self.model = "gpt-4o-mini"
def complete_json(self, prompt, *, temperature=0.0):
return json.loads(self.complete_text([{"role": "user", "content": prompt}], temperature=temperature))
def complete_text(self, messages, *, temperature=0.0):
resp = self.client.chat.completions.create(model=self.model, messages=messages, temperature=temperature)
return resp.choices[0].message.content or ""
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
result = on_context_message(mem0_client, chat_client, "alice", "Check database.py pool config", history=[])
print(result["reply"])The regex fallback means the classifier stays reliable even when the LLM model hedges on obvious file references or task switches.
Pattern 3: Scheduled Reflection Scan
The most powerful pattern, and the one that changes how memory is stored rather than just how it's retrieved.
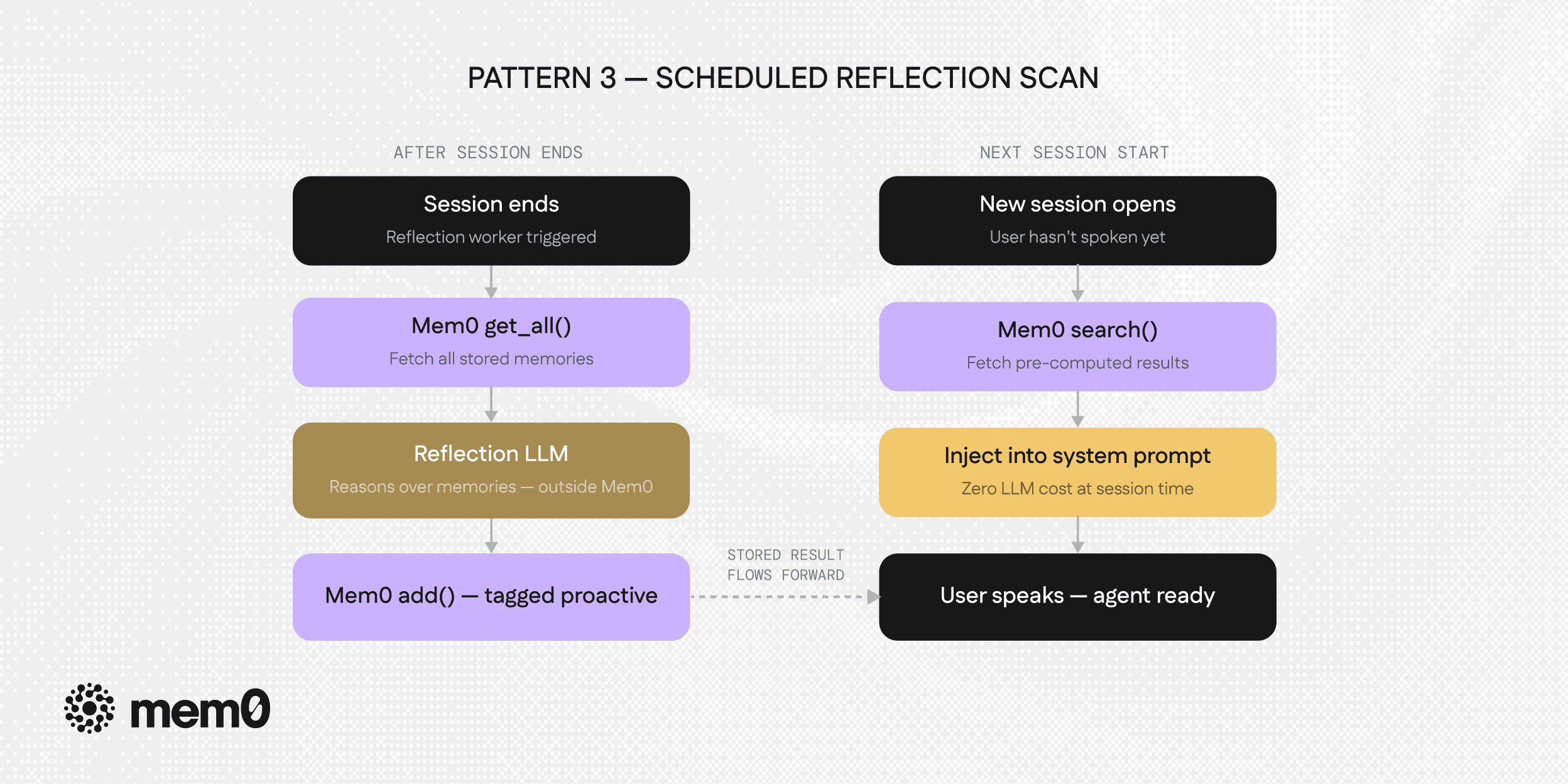
Pattern 3: Scheduled reflection scan
A background worker runs after sessions end or on a schedule and does something that neither of the previous patterns does. It reasons over stored memories to pre-compute what should be surfaced next time. The work happens asynchronously, away from the live conversation. The result is stored back into memory, tagged for instant retrieval at the next session start.
This inverts the cost structure of proactive memory. Instead of a cold-start search that requires an LLM call at session open, the next session retrieves a pre-computed answer: "here's what this user will probably need when they come back."
The ProMem paper's self-questioning loop is directly relevant here. Standard extraction does what most memory systems do which is one-shot and ahead-of-time. The session ends, a single LLM pass extracts facts, they get stored. If that pass missed something, it's gone.
ProMem's two-stage loop changes this:
Stage 1: Standard extraction.: This is the standard pass which extracts the obvious facts, preferences, decisions from the session. This is what any memory system does.
Stage 2: Self-questioning: In this stage, the agent asks itself: "Given what I just extracted, what questions could a future user ask that I haven't captured an answer for?" It generates those gap questions, goes back to the original session transcript, answers each one, and stores the gap-filling facts as additional memories.
The mechanism catches exactly what standard extraction misses, not because the information wasn't in the conversation, but because the extraction pass didn't know it would matter.
PASK's three-layer memory model
The PASK paper introduces a related architectural insight i.e, not all memory should be treated equally. It proposes a three-tier hierarchy:
User memory: It contains long-term preferences, facts, and history about a specific user. This memory layer is stable, high-value, and is accessed often.
Workspace memory: This memory carries current task context. It carries what's being worked on right now, recent decisions, the active project state and is generally more volatile.
Global memory: The global memory is a shared context available across users or agents which contains product knowledge, team decisions, and shared documentation.
The reflection scan should target all three layers differently. For user memory, it looks for durable facts that should be promoted. For workspace memory, it looks for unresolved blockers and pending tasks. For global memory, it looks for decisions made in this session that should propagate to other agents or users.
This three-layer structure is where the scheduled reflection pattern becomes architecturally significant rather than just a cleanup pass.
Demo
The reflection LLM lives outside Mem0 and it reads everything stored via get_all(), reasons over it, and writes pre-computed proactive memories back via add(). At the next session start, search() retrieves them instantly with no LLM call needed.
import os, json
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
def run_reflection(
memory,
chat,
user_id: str,
max_items: int = 3,
) -> list[str]:
"""Reflection worker: pre-compute proactive hints after a session ends."""
envelope = memory.get_all(user_id=user_id)
memories = envelope.get("results", [])
if not memories:
return []
memory_text = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
prompt = f"""Review these stored memories and identify 2-3 things to proactively
surface at the start of the next session. Focus on unresolved blockers,
decisions that might be forgotten, and follow-up actions not yet completed.
Memories:
{memory_text}
Return a JSON array of short actionable strings. Maximum {max_items} items.
Return ONLY the JSON array, no other text."""
raw = chat.complete_json(prompt, temperature=0.3)
if isinstance(raw, str):
raw = json.loads(raw)
items = [str(item) for item in raw[:max_items] if str(item).strip()]
if items:
memory.add(
[{"role": "system", "content": f"[PROACTIVE] {item}"} for item in items],
user_id=user_id,
metadata={"type": "proactive_hint"},
)
return items
def on_reflection_session_open(
memory,
user_id: str,
limit: int = 3,
) -> list[dict[str, Any]]:
"""Next session start: pure Mem0 search, zero LLM cost."""
return memory.search("[PROACTIVE]", user_id=user_id, limit=limit)
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
hints_stored = run_reflection(mem0_client, chat_client, "alice")
hints = on_reflection_session_open(mem0_client, "alice")
for h in hints:
print(h["memory"])import os, json
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
def run_reflection(
memory,
chat,
user_id: str,
max_items: int = 3,
) -> list[str]:
"""Reflection worker: pre-compute proactive hints after a session ends."""
envelope = memory.get_all(user_id=user_id)
memories = envelope.get("results", [])
if not memories:
return []
memory_text = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
prompt = f"""Review these stored memories and identify 2-3 things to proactively
surface at the start of the next session. Focus on unresolved blockers,
decisions that might be forgotten, and follow-up actions not yet completed.
Memories:
{memory_text}
Return a JSON array of short actionable strings. Maximum {max_items} items.
Return ONLY the JSON array, no other text."""
raw = chat.complete_json(prompt, temperature=0.3)
if isinstance(raw, str):
raw = json.loads(raw)
items = [str(item) for item in raw[:max_items] if str(item).strip()]
if items:
memory.add(
[{"role": "system", "content": f"[PROACTIVE] {item}"} for item in items],
user_id=user_id,
metadata={"type": "proactive_hint"},
)
return items
def on_reflection_session_open(
memory,
user_id: str,
limit: int = 3,
) -> list[dict[str, Any]]:
"""Next session start: pure Mem0 search, zero LLM cost."""
return memory.search("[PROACTIVE]", user_id=user_id, limit=limit)
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
hints_stored = run_reflection(mem0_client, chat_client, "alice")
hints = on_reflection_session_open(mem0_client, "alice")
for h in hints:
print(h["memory"])import os, json
from typing import Any
from mem0 import MemoryClient
from openai import OpenAI
def run_reflection(
memory,
chat,
user_id: str,
max_items: int = 3,
) -> list[str]:
"""Reflection worker: pre-compute proactive hints after a session ends."""
envelope = memory.get_all(user_id=user_id)
memories = envelope.get("results", [])
if not memories:
return []
memory_text = "\\n".join(f"- {m.get('memory', '')}" for m in memories if m.get("memory"))
prompt = f"""Review these stored memories and identify 2-3 things to proactively
surface at the start of the next session. Focus on unresolved blockers,
decisions that might be forgotten, and follow-up actions not yet completed.
Memories:
{memory_text}
Return a JSON array of short actionable strings. Maximum {max_items} items.
Return ONLY the JSON array, no other text."""
raw = chat.complete_json(prompt, temperature=0.3)
if isinstance(raw, str):
raw = json.loads(raw)
items = [str(item) for item in raw[:max_items] if str(item).strip()]
if items:
memory.add(
[{"role": "system", "content": f"[PROACTIVE] {item}"} for item in items],
user_id=user_id,
metadata={"type": "proactive_hint"},
)
return items
def on_reflection_session_open(
memory,
user_id: str,
limit: int = 3,
) -> list[dict[str, Any]]:
"""Next session start: pure Mem0 search, zero LLM cost."""
return memory.search("[PROACTIVE]", user_id=user_id, limit=limit)
mem0_client = MemoryClient(api_key=os.environ["MEM0_API_KEY"])
chat_client = OpenAIChatModel()
hints_stored = run_reflection(mem0_client, chat_client, "alice")
hints = on_reflection_session_open(mem0_client, "alice")
for h in hints:
print(h["memory"])run_reflection() is called once after the session ends, away from the live conversation. on_reflection_session_open() at the next session is a pure Mem0 search() with no LLM call needed. Note that get_all() returns a paginated envelope, so memories are accessed via envelope["results"], not from the envelope directly.
Common Failure Modes in Agent Memory Systems
Every pattern we discussed above has some limitations:
Noise injection: A session-start scan with a broad query surfaces irrelevant memories. The agent mentions a dark mode preference when you open a database schema. The fix is precision in the probe query, and a relevance threshold below which results are discarded rather than injected.
Over-proactivity fatigue: An agent that volunteers memories on every turn becomes an interruption. The PASK finding is directly relevant here that, knowing when not to fire is as important as knowing when to fire. Rate-limit proactive injections i.e, one at session start, one per significant context shift, not one per turn.
Latency at session start: The session-start scan adds a round-trip before the first response. For real-time applications this is felt. The fix is to run the scan async while the UI loads. The user sees a loading state while the memories arrive before their first message does.
Extraction completeness vs. storage cost: ProMem's self-questioning loop recovers more facts but costs more tokens per session end. For short, low-stakes sessions this overhead may not be worth it. For long sessions with high-value decisions, it almost always is. The right answer is to gate the reflection depth on session length and importance signals.
Future of Proactive Memory in AI Agents
The two papers point at open problems which are worth watching. ProMem's feedback loop is currently applied at the session level. The natural next step is applying it continuously like running self-questioning process that re-examines stored memories as new sessions add context. "Given what I learned today, are there old memories that should be updated or promoted?"
PASK's demand detection is trained on general conversational patterns. Domain-specific fine-tuning using a classifier trained on coding agent conversations, or customer support conversations, or medical assistant conversations that would improve precision substantially in each domain.
The prospective memory primitive itself doesn't exist yet in any production memory system. The pattern described above approximates it by storing pre-computed proactive memories with metadata tags. A first-class prospective_memory type would be a memory with an attached trigger condition that fires when the condition is met that would formalize the concept and make it composable.
——
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here : app.mem0.ai
or self-host mem0 from our open source GitHub repository
——
Research cited:
ProMem: "Beyond Static Summarization: Proactive Memory Extraction for LLM Agents," Yang et al., arXiv:2601.04463, January 2026
PASK: "Toward Intent-Aware Proactive Agents with Long-Term Memory," Xie et al., arXiv:2604.08000, April 2026









