



Working memory is what an agent is actively thinking about. Episodic memory is what happened to a specific user at a specific time. Semantic memory is what is true in general.
Most agents have semantic memory partially baked in. The model's training data is a giant semantic memory of the world. What's missing is personal semantic memory: facts about this specific user, this team, this codebase that the model never saw during training.
That gap is what a personal-semantic memory layer fills. The gap is bigger than it looks.
What semantic memory is
The cleanest definition comes from Endel Tulving's 1972 chapter "Episodic and Semantic Memory," published in Organization of Memory. Tulving proposed splitting long-term memory into two systems with different jobs.
Semantic memory holds the facts and meanings a person knows. In Tulving's framing, it functions like "a mental thesaurus": the structured knowledge of words, verbal symbols, their meanings and references, and the rules for manipulating them.
Episodic memory, by contrast, holds personal experience tied to a specific time and place. Tulving described it as storing "temporally dated episodes or events, and the temporal-spatial relations" among them.
Knowing what a cat is sits in semantic memory. Remembering the cat that jumped on the keyboard last Tuesday sits in episodic memory.
Tulving was careful to call the distinction "an orienting attitude or a pretheoretical position." Even in 1972 he argued the two systems were interdependent. That qualifier matters for agent design, because the line between "the user prefers Python" (semantic) and "the user said they prefer Python on March 4" (episodic) blurs the moment a system has to decide what to store.
Semantic vs working memory
A second distinction worth being precise about. Semantic memory is durable. Working memory is active.
Working memory is the small, volatile state the agent is currently reasoning over. The current task, the recent turns, the scratchpad. It dies when the session ends.
Semantic memory is what survives across sessions. The user's preferred language. The project's deploy command. The team's code review conventions. None of this changes turn-by-turn. All of it has to be available next session.
The CoALA framework (Sumers et al., 2024) makes the same split for language agents. CoALA models a language agent as working memory plus long-term memory, where long-term memory is itself divided into semantic, episodic, and procedural components. Working memory is the scratchpad. Semantic memory is where the durable facts live.
What the model already knows, and what it does not
Frontier LLMs already encode an enormous amount of semantic knowledge in their parameters. Capitals, language rules, library APIs, common-sense relationships, historical dates. CoALA explicitly notes that semantic memory in a language agent can include "factual knowledge about the world," and that much of this knowledge is "embedded in the agent's code or the LLM's parameters."
That covers world knowledge. It does not cover personal knowledge.
Personal semantic memory is the set of facts that exist only because of this particular user, this particular team, this particular project. A frontier model trained six months ago has no way to know:
The user's name, role, time zone, and preferred language.
The team's primary cloud, framework, and deploy target.
The project's database, schema, and naming conventions.
The customer's renewal date, plan tier, and last support ticket.
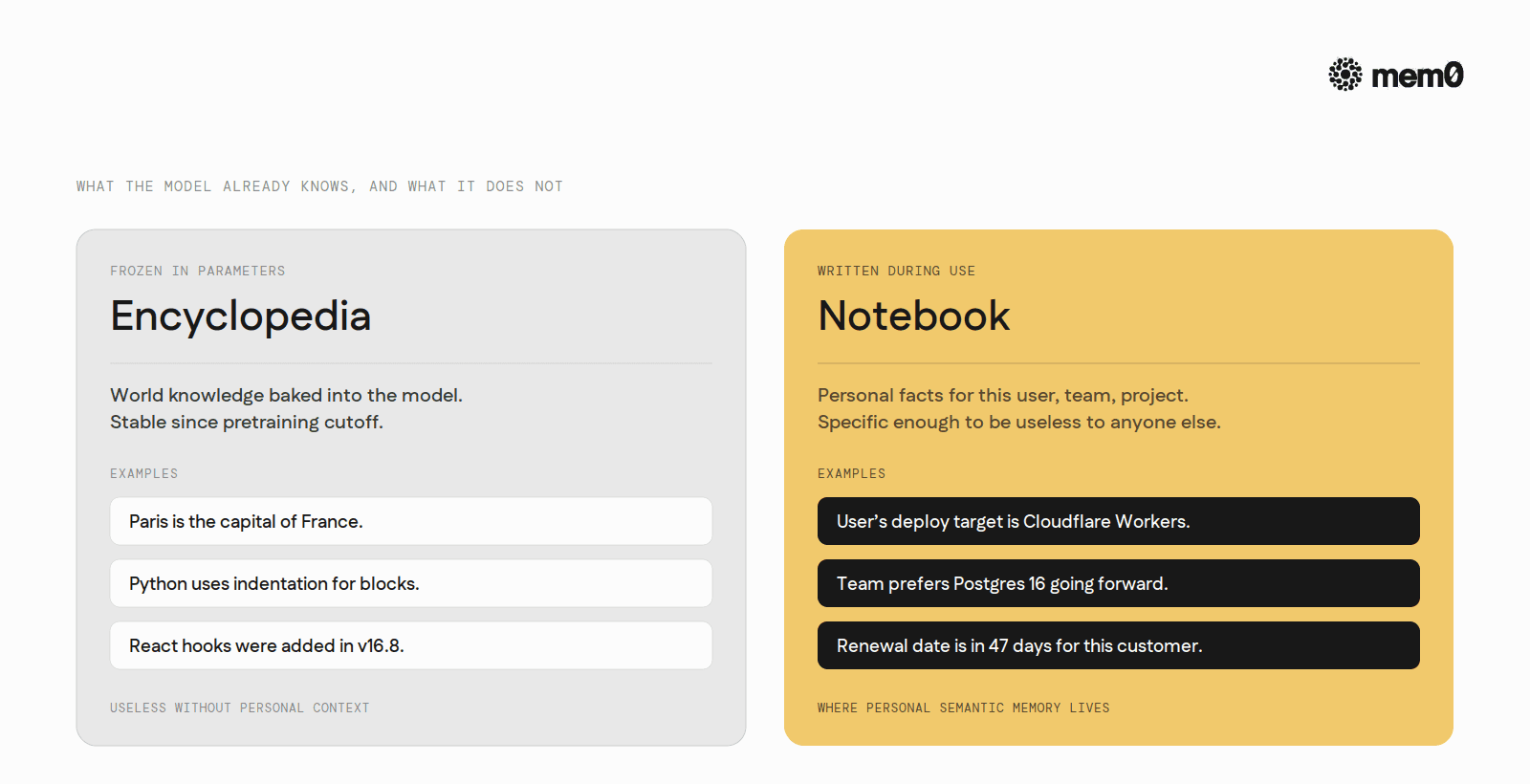
These facts are stable enough to be semantic and specific enough to be useless to anyone else. They are exactly the layer most agents are missing.
Foundation models gave agents an encyclopedia. They did not give agents a notebook with the user's name on it.
The rest of this post is about that notebook.
How agents implement semantic memory today
Pattern 1. Instruction files and Skills
The simplest implementation writes facts directly into the system prompt. Anthropic formalized a richer version with Agent Skills.
A skill is a directory containing a SKILL.md file with YAML frontmatter (name and description) plus optional bundled resources. Skills load in three stages. The frontmatter is always loaded (about 100 tokens per skill). The body of SKILL.md loads when the skill is triggered (under 5K tokens). Bundled files load only when referenced.
The community-convention equivalents are AGENTS.md and CLAUDE.md for project-level facts, and .cursorrules for Cursor. They share a common pattern: a markdown file the agent reads at session start and treats as durable instructions.
This works well for facts the team is willing to write down once. It breaks down for facts that change frequently or facts specific to one user out of many.
Pattern 2. RAG over docs
Retrieval-augmented generation handles bulk text knowledge. Chunk a documentation corpus, embed the chunks, search at inference time. RAG is the right tool when the agent needs to cite a paragraph from a handbook.
It is the wrong tool for short, durable, user-scoped facts. Embedding a sentence like "the user does not use Vercel" into a million-document store and trying to retrieve it later by similarity search is brittle. Negation and short factual statements are exactly what dense retrieval struggles with.
Pattern 3. Knowledge graphs
Entity-relation stores fit semantic facts naturally. A graph node for the user, edges to preferences, projects, and team members. Graphs handle multi-hop questions ("what database does Alex's main project use?") better than flat vector stores.
The cost is operational complexity. Schema design, ingestion, and updates all become engineering surface area.
Pattern 4. Memory layers
A managed service whose job is exactly this: extract facts from conversation, store them durably, retrieve them at the right moment, reconcile them when they change. Mem0 and similar systems live here.
The memory-layer pattern treats facts as first-class entries with identifiers, scopes, metadata, and an update path. That last point is the one most other patterns fail at.
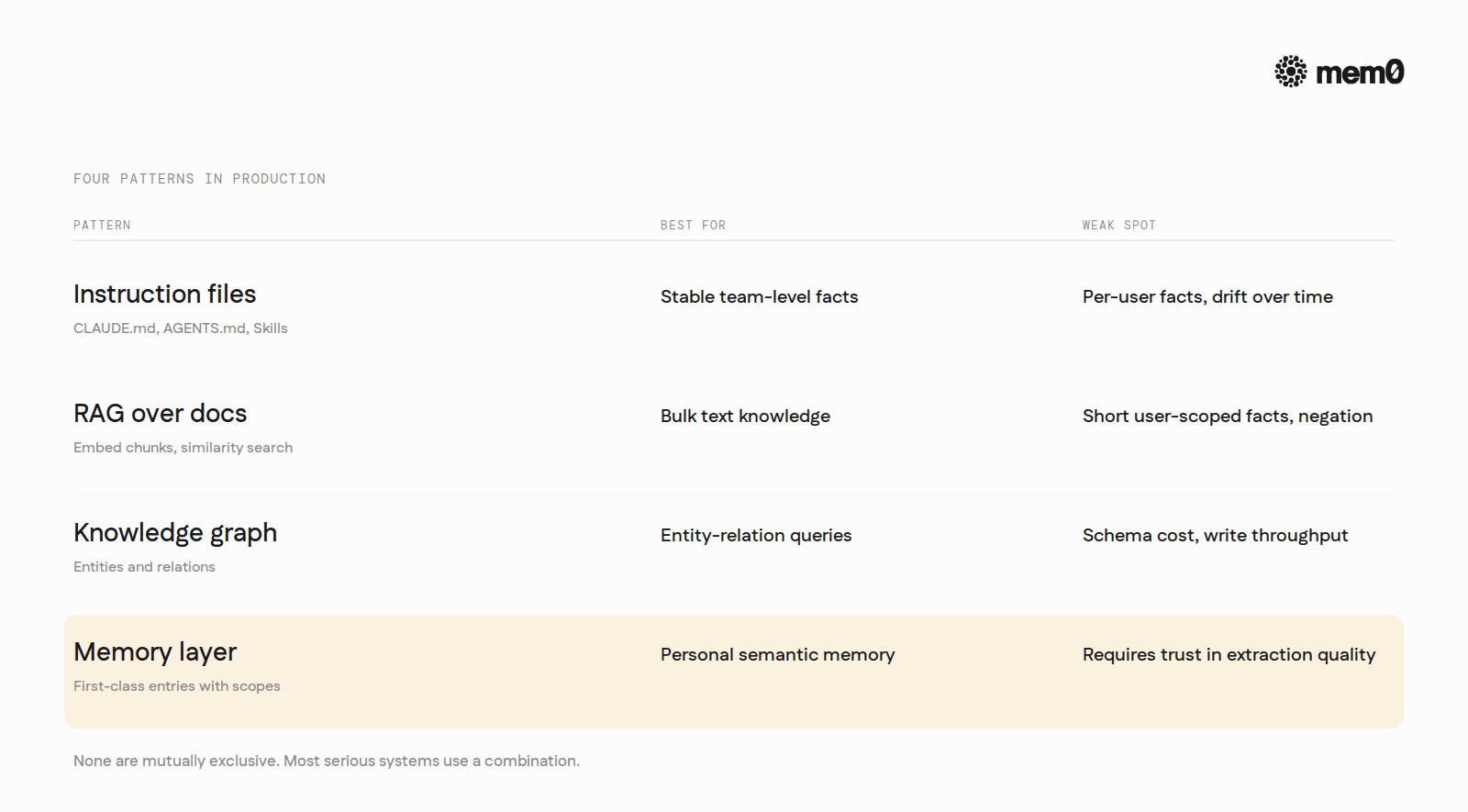
Comparison at a glance
Pattern | Best for | Weak spot |
|---|---|---|
Instruction files (CLAUDE.md, AGENTS.md, Skills) | Stable team-level facts | Per-user facts, drift over time |
RAG over docs | Bulk text knowledge | Short user-scoped facts, negation |
Knowledge graph | Entity-relation queries | Schema cost, write throughput |
Memory layer | Personal semantic memory | Requires trust in extraction quality |
Failure modes worth flagging
Five failure modes show up consistently in agent semantic memory.
Stale facts. The user changes jobs, switches stacks, or updates a preference. The old fact lingers because nothing told the system to retire it. The agent then suggests an outdated framework with full confidence.
Confusion with episodic recall. A semantic fact is "the user prefers Postgres." An episodic fact is "the user mentioned Postgres on March 4." Storing them with the same shape and the same retrieval path turns durable preferences into noisy timestamped history.
Overwrite vs update tension. Hard delete on contradiction loses the audit trail. Soft writes on every utterance create duplicates. Most teams oscillate between these two failure modes for a quarter or two before settling on a hybrid policy.
Fact contamination across users. Without strict scope keys on every read, a fact stored under one tenant can leak into another tenant's prompt. This is one of the rare memory bugs that is both subtle and a security incident at the same time.
System prompt drift. Hand-edited instruction files (CLAUDE.md, AGENTS.md, .cursorrules) accumulate facts the way any shared doc does. After a few months they are bloated, contradictory, and read on every turn whether the current task needs them or not.
The common thread is that semantic memory is not a write-once problem. It is a continuous extract, scope, update, and retrieve loop, and the systems that ship best are the ones that make every step explicit.
Where Mem0 fits
Mem0 treats personal semantic memory as a first-class layer in its own data model. The docs call it user memory: long-lived knowledge tied to a person, account, or workspace, separated from short-lived session state and from in-flight conversation turns. The other patterns retrofit this separation. Mem0 starts there.
The mechanism is extraction-based, not summarization-based. When a turn is added to Mem0, an extraction model pulls candidate facts out as atomic items, compares each against existing memories, and picks one of four operations: ADD when no equivalent fact exists, UPDATE when an existing fact needs new detail, DELETE when a fact contradicts the new one, and NOOP when nothing has changed. The index holds distilled facts, not message blobs.
The five failure modes named earlier map back to specific pieces of this design.
Stale facts are what reconciliation is for. The latest-truth-wins behavior of UPDATE and DELETE retires the old fact in the same write that introduces the new one. No application-side sweep, no scheduled job.
Confusion with episodic recall is handled by keeping the two as separate stores with a defined path between them. Mem0's own hierarchy splits episodic memory (summaries of past interactions) from semantic memory (durable facts, relationships, preferences, learned knowledge), and the update phase promotes the durable details into semantic memory while the rest stay episodic or are discarded. The same preference does not end up stored twenty times as twenty timestamped entries.
Overwrite vs update tension is exactly what the four-operation reconciliation resolves. UPDATE preserves the audit trail by modifying an existing entry instead of appending a duplicate. DELETE fires only on contradiction, not on every utterance. The hybrid policy most teams eventually write by hand ships as the default.
Cross-user contamination is handled by mandatory scope keys. Every read filters on user_id, agent_id, or run_id. A fact stored under one tenant cannot surface in another tenant's prompt unless the call explicitly asks for it.
System prompt drift stops being a problem when facts live in a queryable store. Instead of every session reading a growing markdown file at startup, the agent calls memory.search with the current query and pulls back the few facts that matter. The instruction file stays small. The knowledge layer scales.

How this pairs with other memory types
Semantic memory is one layer in a four-part cognitive map for agents. The other three are working memory, episodic memory, and procedural memory.
A complete agent memory architecture has all four:
Working memory holds the active state of the current turn.
Episodic memory holds time-stamped events: what the user did last Tuesday, what the agent decided last week.
Semantic memory holds the durable personal facts: preferences, conventions, project state (this post).
Procedural memory holds the workflows: how to deploy, how to triage, how to compose a release.
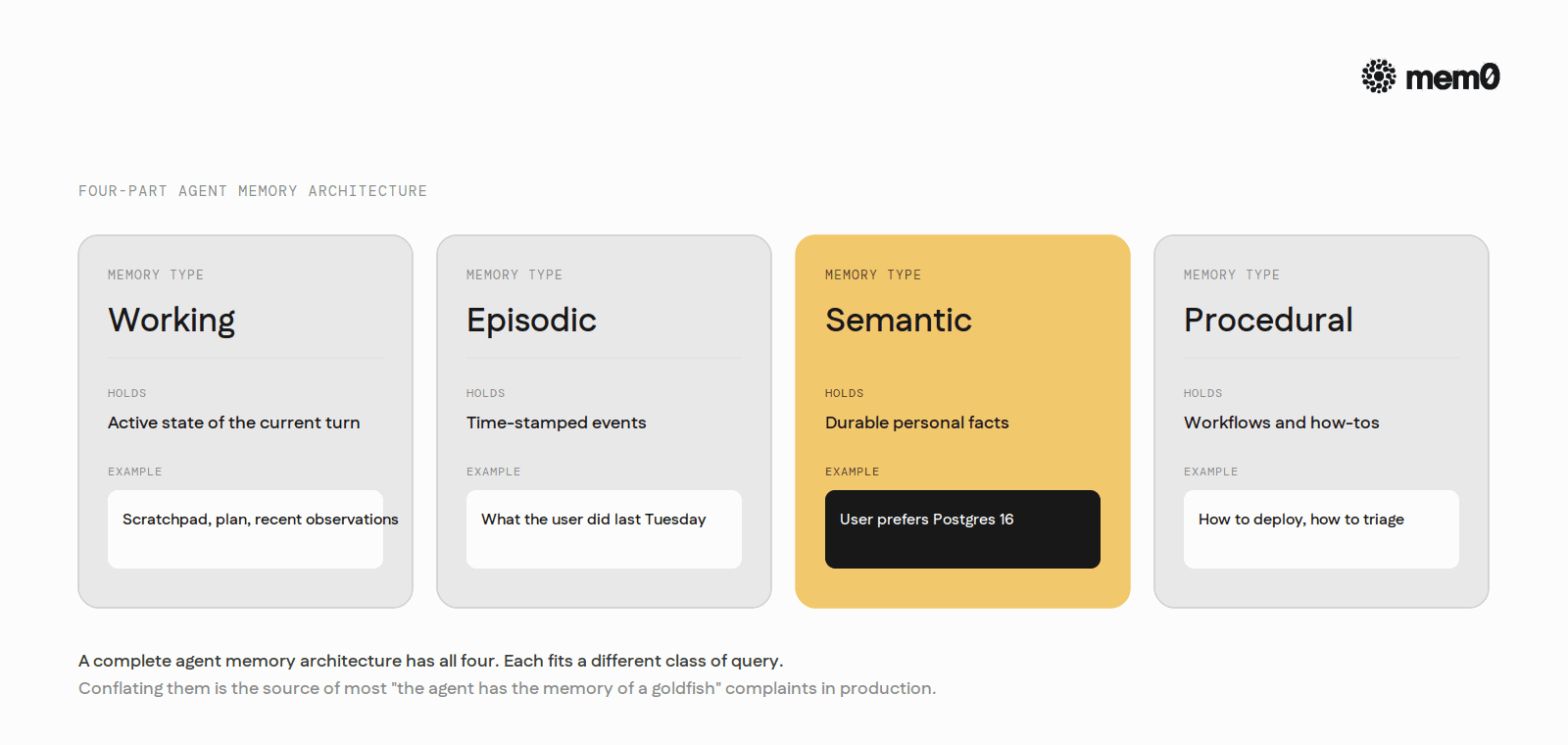
Each fits a different class of query. Conflating them is the source of most "the agent has the memory of a goldfish" complaints in production.
The shape of the choice
Foundation models give every agent a built-in semantic memory of the world. That's most of what's needed for general questions.
What every production agent has to add is personal semantic memory: the facts about this user, this team, this project that the training data couldn't possibly contain. Without it, the agent re-asks the same questions every session and never gets better.
The pattern that scales is a dedicated memory layer with semantic-search retrieval, scoped by user, with update and delete primitives for fact correction. The implementation is shorter than the list of failure modes it solves.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

