



TL;DR for Hermes / LangGraph / OpenClaw builders:
Naive file-memory injection scales linearly with every entry you add; 24 entries already costs 594 tokens per call
A retrieval-based memory architecture cuts that to 166 tokens with identical answer quality, thereby 72% savings (based on 24 entries), verified against real model
usage.prompt_tokens
If you are building a local or self-hosted agent on Hermes, LangGraph, OpenClaw, or your own stack, there is a cost problem that will not show up in your first week of testing. It shows up in week three, on your inference invoice.
The issue is that naive agent memory approaches scale linearly with usage:
7 entries requires ~146 prompt tokens per call
24 entries requires 594 tokens
200 entries requires ~3,200 tokens
500 entries requires ~8,000 tokens
Every one of those tokens is injected on every single inference call regardless of what the user asked. That growth is continuous, invisible at small scale, and unaddressed by most default agent frameworks.
Here is a quick look into results from the experiment we ran in this blog on same query, same model, and same 24-entry memory store:
Naive Hermes | Retrieval-Based Memory | |
|---|---|---|
Prompt tokens (top-5) | 594 | 166 |
Prompt tokens (top-10) | 600 | 293 |
Token savings | — | 51–72% |
Answer quality | Correct | Correct |
Entries injected per call | All 24 | 5–10 (relevant only) |
Both answers were correct, and the savings came entirely from not injecting the 14 to 19 irrelevant entries including the deployment notes, sprinkler schedules, and MQTT broker rules, that the naive approach dumps into every call regardless of the query.
Why Context Bloat Is Worse Than It Looks
The problem is not just that naive file injection is wasteful. It is that it is invisible until you go looking for it.
Developers notice high token counts, assume the issue is conversation history, trim the history, see mild improvement, and move on. What they miss is that the memory file overhead is structural and persistent. Every call, regardless of the query, receives the full dump. A single irrelevant entry today is a persistent tax on every future inference call for as long as that entry lives in your memory file.
The math compounds once you factor in everything else already competing for context space. A conservative in-home agent with a few dozen memory entries, a system prompt, and some tool definitions is already sitting at tens of thousands of tokens per call. Production traces from continuously running agents often show 80,000 to 120,000 token contexts within two to three weeks of operation. Memory file bloat is a consistent, compounding contributor to that number, and it is the easiest one to fix.
Why Adding a Vector Store Does Not Fully Solve It?
The natural instinct is to add retrieval-augmented generation that store memories in a vector database, retrieve the top-K relevant ones at inference time, and leave the rest out. This helps, but naive RAG has its own failure modes that limit how far it takes you:
Semantic drift: Top-K cosine similarity doesn't always match what's contextually relevant. "Do the usual thing" retrieves memories about the literal word "usual" rather than the temporal and behavioral pattern the phrase implies.
Chunk boundary problems: Memories stored as raw conversation chunks pull in large blocks with irrelevant surrounding context. You retrieve 3,000 tokens to surface one relevant sentence.
No graph awareness: Naive RAG treats every memory as an isolated vector. It can't understand that "the kitchen light" and "the Philips Hue strip" are the same device, or that "Tuesday gym session" and "post-workout protein" are causally linked. In-home agent memory optimization requires this kind of relationship modeling.
Recall degradation over time: Retrieval precision drops as the store grows. Top-5 recall that was 94% at 100 memories may fall to 71% at 10,000 memories without architectural changes to compensate.
Production systems using naive full-context or naive RAG typically run 3 to 5 times higher token costs than necessary, with recall that degrades measurably over weeks of continuous operation, which is the kind of problem most agent builders discover in month two rather than day one.
Modern Memory Architecture
The core insight behind the new generation of agent memory architectures is that most systems are doing too much at retrieval time and not enough at storage time. The work of organizing, relating, and compressing memories should happen once at creation time rather than being repeated on every inference call.
Here's the architecture showing the best results in 2026 for in-home and self-hosted agents. A production-ready open-source implementation is available via the Mem0 SDK, released mid-2025 and actively maintained as of 2026.
Principle 1: Single-Pass ADD-Only Extraction
Traditional memory pipelines run three sequential LLM calls per new memory: extract the raw fact, check for conflicts, then update or merge. This is expensive and adds latency on every write.
Single-pass ADD-only extraction runs one LLM call to extract a structured fact and add it to the store. Conflict resolution is deferred to retrieval time or handled asynchronously. This cuts write-time LLM calls by 60 to 70 percent without meaningfully degrading memory quality. The key is tight extraction prompts that produce normalized, atomic facts ("User prefers lights at 40% brightness after 9pm") rather than raw conversational chunks.
Principle 2: Entity Linking and Lightweight Graph Relationships
Pure vector stores treat every memory as an isolated embedding. A more powerful approach adds a lightweight graph layer that tracks entity relationships alongside the vectors.
When a memory is extracted, entities are identified and linked: people, devices, locations, preferences, schedules. At retrieval time, a graph traversal surfaces related memories that wouldn't appear in a pure semantic search. For in-home agent memory optimization, this is particularly valuable because a query about "the living room" can traverse to linked devices, routines, historical issues, and preferred settings through graph relationships rather than relying on semantic proximity.
Principle 3: Agent-Generated Facts as First-Class Memories
Most memory systems only store user utterances. A more powerful approach lets the agent generate its own memory writes like observations, inferences, summaries etc, as explicit memory entries.
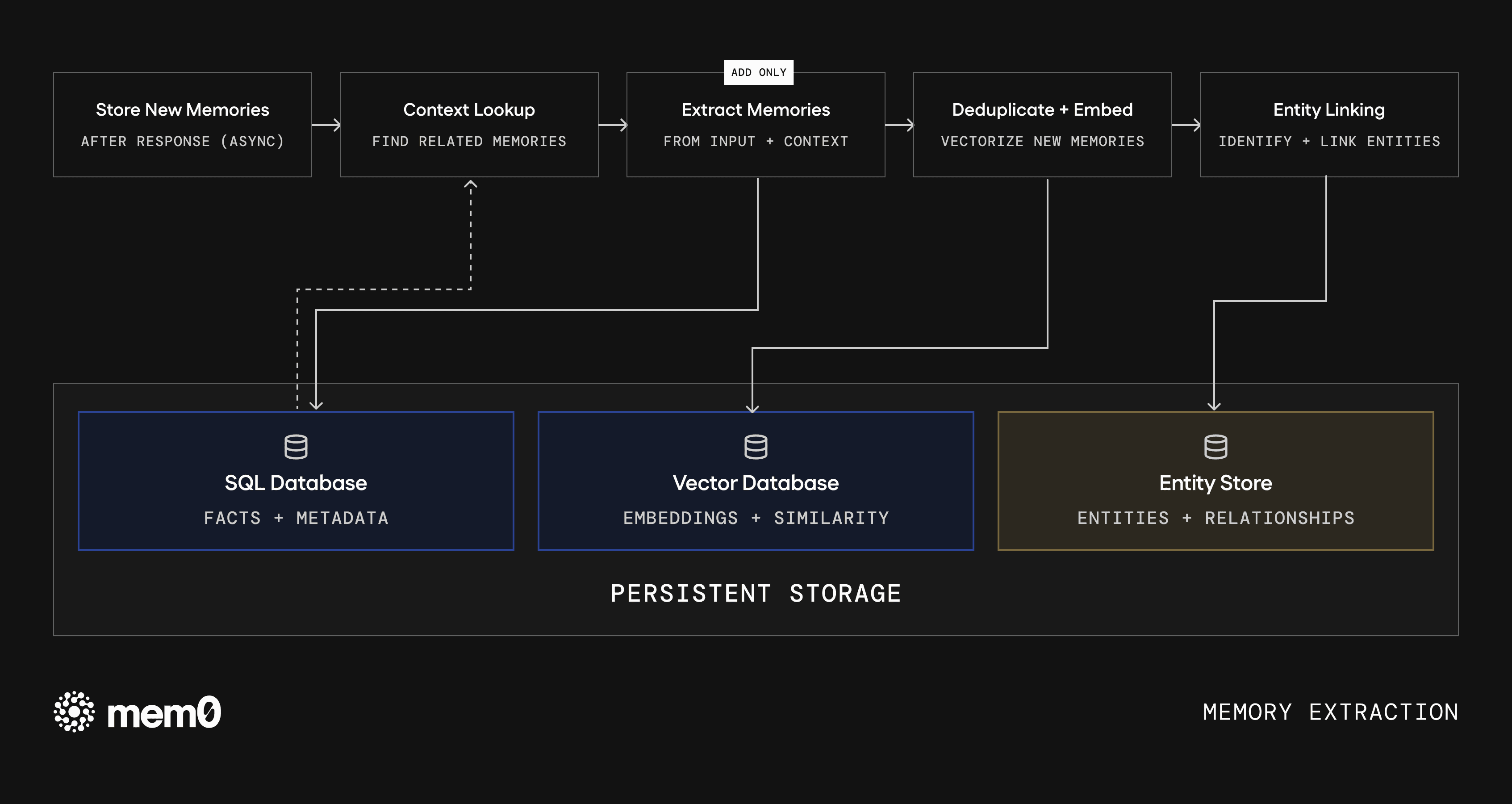
Fig: Memory extraction. Input flows through context lookup, single-pass extraction, deduplication, and entity linking before being written to persistent storage.
After a week of observing that the user always turns down the thermostat before bed, the agent writes: user_preference: lower thermostat to 68°F at bedtime. This becomes a retrievable fact at query time, derived from behavioral observation. The agent doesn't need to re-observe and re-infer patterns it has already learned.
Principle 4: Multi-Signal Retrieval
Rather than a single semantic similarity lookup, effective memory retrieval combines multiple signals:
Vector similarity: Semantic relevance to the current query
Graph traversal: Entity-linked memories that may not be semantically close
Temporal recency: Recent memories weighted higher for context-dependent queries
Metadata filters: User ID, device, location, category that fast pre-filtering before vector search
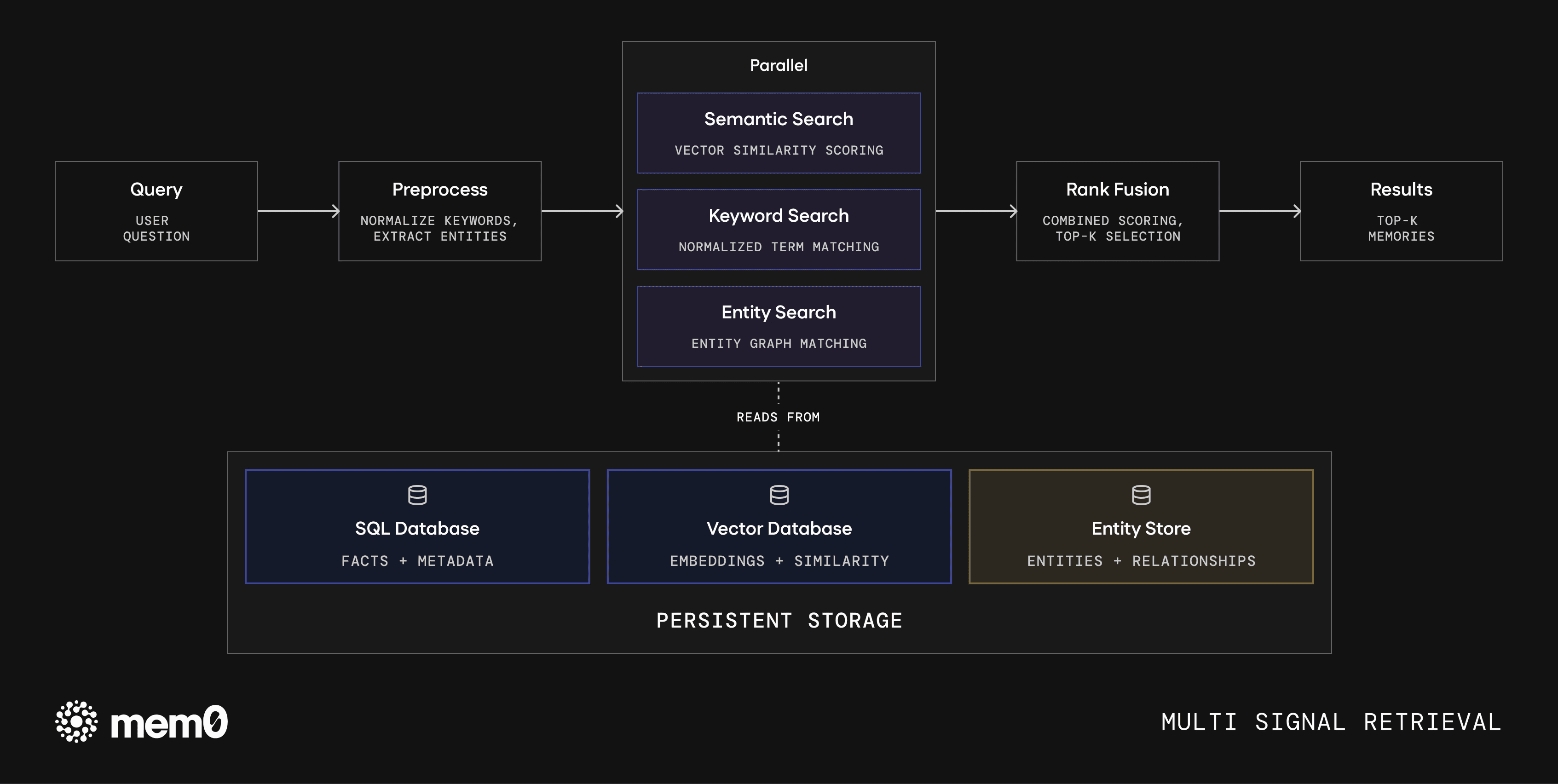
Fig: Multi-signal retrieval stack. Queries are preprocessed and scored in parallel across semantic, keyword, and entity signals, then fused via rank scoring.
This multi-signal approach allows tight retrieval budgets while maintaining precision. On typical in-home agent workloads the result is roughly 7,000 tokens per retrieval, compared to 25,000 to 100,000 or more for full-context approaches, with recall rates above 91 percent on LoCoMo-style long-horizon benchmarks.
Open-source implementations of this architecture show benchmark improvements of 26% on LoCoMo and 20 to 30% on LongMemEval-style tasks compared to full-context or naive RAG baselines, while reducing active context size by 70 to 85%.
To see what that looks like against a real Hermes memory store with actual API token counts, here is the comparator.
Token Comparison on Hermes Agent
The script reads your existing MEMORY.md and USER.md files, runs the same query two ways in parallel (naive file dump versus retrieval-based), sends both to the same model, and prints real token counts side by side using usage.prompt_tokens from the OpenRouter API. You need:
A free OpenRouter account for inference (or an OpenAI API key)
A free Mem0 account for the retrieval side
Python 3.10+ which works on Raspberry Pi 4/5, consumer GPU homelabs, and standard VPS setups
Hermes agent set up
After setup, Hermes writes its memory files to ~/.hermes/memories/ by default. Run your agent for a few sessions so the memory files have real entries, so the comparison is most meaningful with 10+ entries.
Once you have the repo cloned and your .env set up with both keys, run it against your own memory directory:
Run against your own Hermes memory directory:
Under the hood, the comparator does exactly this — reads your memory files, seeds Mem0, retrieves only what is relevant, builds both prompts, sends them to the same model, and prints the token difference:
The full implementation of each helper function is in the repo. The logic above is the entire comparison in one readable flow.
Here's the output from running this against a 24-entry Hermes memory store, which represents a realistic one to two month accumulation for an active personal assistant. The query was: "It is 10:30pm and no guests are coming. What should I do with outside lights?"
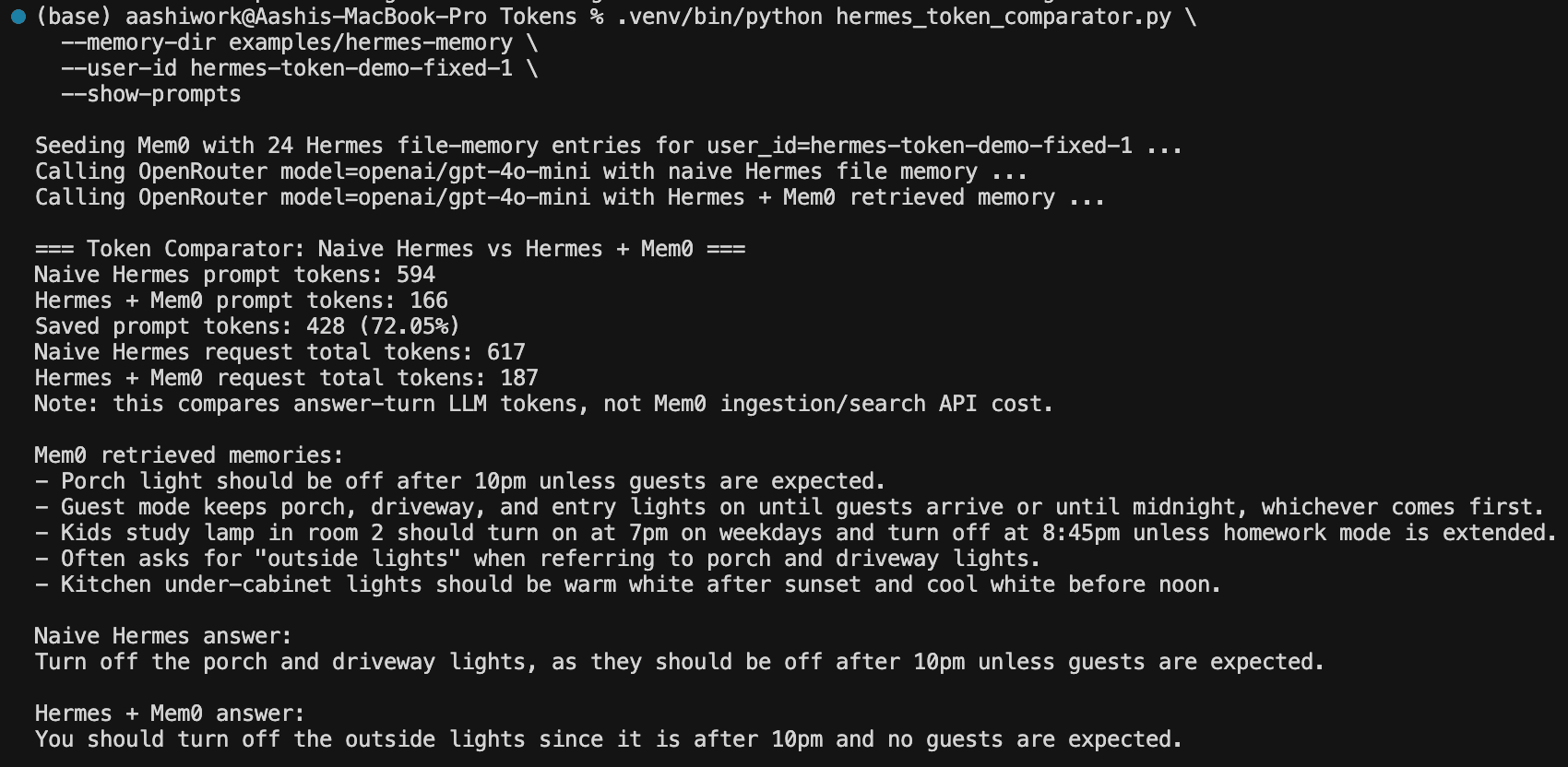
Here are a couple of observations from the results:
The 72 percent token reduction stands out most immediately. Naive Hermes injected all 24 raw entries into the call, including Docker deployment notes, MQTT broker restart rules, robot vacuum schedules, and OpenRouter model preferences. The retrieval-based approach sent 5 semantically relevant entries and nothing else.
The second thing worth noting is that both answers are correct and equivalent. You are not trading recall quality for token savings. You are trading irrelevant context for none, which means the agent answers just as well with 428 fewer prompt tokens consumed.
The third observation is harder to see until you look at the actual prompts side by side. The naive prompt contained entries about Docker Compose, MQTT broker downtime approval, and preferred model routing for evaluation demos. None of that information is relevant to a question about lights at 10:30pm, but the naive approach injected it anyway. The retrieval-based approach did not send any of it.
Here is a quick number summary:
Naive Hermes | Hermes + Mem0 | |
|---|---|---|
Prompt tokens | 594 | 166 |
Total tokens | 617 | 187 |
Memories injected | 24 (all of them) | 5 (relevant only) |
Token savings | — | 428 tokens (72%) |
The gap scales with your store size. On a 200-entry store the naive approach injects roughly 4,600 tokens of memory content while retrieval-based still injects around 130 tokens for top-5. The longer your agent has been running, the bigger the difference. Every entry in the retrieval-based prompt is directly relevant to the question being asked. Every entry the naive approach added on top of those five is overhead that the model has to process, attend over, and potentially confuse with relevant context on every single call.
Production Guardrails Worth Adding
The architecture shift handles the token cost problem. These three additions protect the system once it is running in production:
Prevent memory poisoning: Any system that lets an agent write its own memories is vulnerable to prompt injection. Validate extracted facts before writing them to the store and reject entries that contain instructions, URLs, or code-like patterns.
Set cost alerts: Instrument token counts per call and alert at 150 and 200 percent of your baseline. A sudden spike usually indicates a retrieval bug, a rogue tool result, or a context management regression rather than a genuine change in usage pattern.
Log retrieval misses: When your agent says "I don't have information about that" for something it should know, log the query, what was retrieved, and what the expected memory was. This is your most valuable dataset for tuning retrieval precision over time.
Your Next Step
Run --show-prompts on a query from your own agent and count how many of the injected entries are actually relevant to that specific question. For most agents that have been running longer than a month, the answer is fewer than a quarter of them. That ratio is your token waste number, and it gets worse with every new entry your agent writes.
Clone the repo, point it at your --memory-dir, and run the comparator. The savings number you get back is the per-call overhead you are currently paying on every inference call your agent makes.
FAQ
Q: Does this work with agents other than Hermes?
The script reads standard MEMORY.md and USER.md files, but the underlying principle of naive file injection versus retrieval-based memory applies to any agent framework that manages a persistent memory store. LangGraph, OpenClaw, and custom LangChain agents with file-based memory all exhibit the same bloat pattern and benefit from the same architectural shift.
Q: Do I need Mem0 specifically, or can I use another vector store?
The script uses Mem0 for the retrieval side because it handles extraction, indexing, and retrieval in one API call. That said, the token savings come from the retrieval pattern(which is quite effective in Mem0) rather than from any specific library.
Q: Is the 72% token saving realistic for larger memory stores?
The 72 percent result is from a real 24-entry store. The savings grow as the store grows, because naive injection scales linearly while retrieval holds flat at top-K. On a 200-entry store the naive approach injects roughly 4,600 tokens of memory content while retrieval-based still injects around 130 tokens for top-5. We do not extrapolate results beyond what we have measured, so run it on your own store and get your actual number.
Q: What are the tradeoffs of retrieval-based memory versus file injection?
Retrieval-based memory adds read-path latency because it runs a vector search before each inference call, and it requires a seeding step when you first migrate. It also introduces a cold-start window where newly added memories may not yet be fully indexed, which is why the comparator script handles this with --mem0-wait-seconds. For most production in-home agent deployments the latency tradeoff is well worth the token savings.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

