



Agentic AI refers to systems in which LLMs behave less like autocomplete engines and more like autonomous actors that pursue goals. Instead of responding to single prompts, they plan, take actions, call tools, react to feedback, and iterate until a task is complete.
For production use, this pattern now shows up in support copilots, sales assistants, workflow orchestrators, research bots, and more. In each case, the system must remember context over time, reason about it, and then adapt behavior.
At a small scale, it can be built around a simple chain of prompts and tools. At the production scale, it becomes obvious that something is missing. That missing piece is durable, structured memory tuned for agents, not for humans.
Core properties of agentic AI systems
Agentic AI is not just "LLM and tools". It combines several key capabilities that reinforce each other:
Goal-oriented behavior: Agents interpret a high-level objective, then break it into smaller steps. They may call APIs, search, read documents, and ask clarification questions until the goal is satisfied.
Tool use and environment interaction: Agents call external tools, databases, or APIs. They mutate state in applications, send emails, update CRMs, deploy infrastructure, and more. The environment is not static.
Planning and re-planning: Agents generate plans, follow them, and adjust when new information appears. Failure handling, retries, and recovery become core concerns.
Long-running and multi-session context: Real-world agents run across multiple user sessions and workflows. A support agent may talk to the same user for weeks. A research agent may gather findings for days.
Personalization and adaptive behavior: The best agents adapt to user preferences, organization norms, and task history. They should improve over time, not restart from zero every call.
All of these properties rely on a shared foundation: memory. Without memory, agents repeatedly rediscover the same facts, ignore past failures, and behave statelessly.
Why is memory central to agentic behavior?
Most LLM agent frameworks solve the "thinking" part with prompts and tools. They defer the "remembering" part to ad hoc hacks such as stuffing more into the context window, caching chunks in a vector store, or storing raw transcripts.
For agentic systems, memory is not optional. It provides at least four crucial capabilities:
User personalization: Agents need to recall user preferences, constraints, and styles. For example: "Prefer concise answers", "Customer is on a legacy plan", or "Avoid sending Slack messages after 6 pm local time".
Task and project continuity: Agents work on multi-step tasks. When a user returns, the agent should recall what was done, what remains, and why certain choices were made.
Organizational knowledge accumulation: Agents should accumulate knowledge about error patterns, mitigation steps, customer-specific edge cases, and team decisions, and reuse this knowledge across similar situations.
Safety and oversight: Auditable memory makes it possible to understand why an agent made a decision, what context it used, and when incorrect or sensitive memories should be edited or removed.
Building these features with naive context stuffing or raw database logging creates brittle and expensive systems. A more disciplined memory layer is needed.
The standard context window pattern and its limits
Most agent pipelines start with one simple pattern: pass everything as context to the LLM. The system concatenates the latest messages, relevant docs, and tool outputs into a single prompt.
This pattern is effective for short-lived tasks, but it stops working when:
Conversations or workflows span many turns or sessions
The agent interacts with multiple users and entities
Past details are sparse but crucial
Context windows hit token limits or become too expensive
Adding a naive vector store for "long-term memory" partially helps. Embeddings can surface similar past chunks, but this creates new problems:
Memory is stored as unstructured text without clear entities or types
Retrieval is fuzzy and hard to control
Duplicate and noisy memories accumulate
Manual curation becomes difficult at scale
Agentic AI needs something more structured, controllable, and intent-aware than raw text retrieval.
What agentic memory really needs?
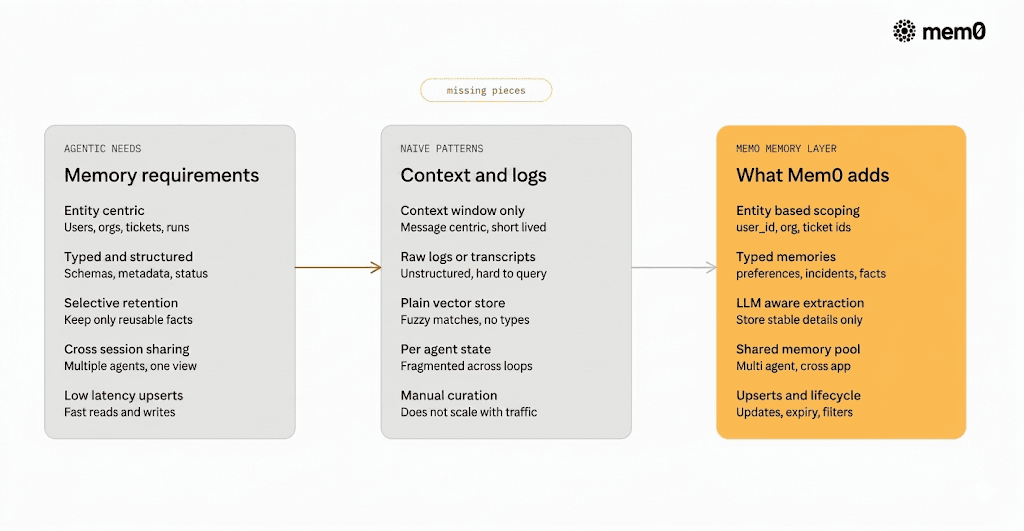
Fig: Key requirements of agentic memory
A production-ready memory layer for agents should behave more like a specialized database than a log file. It must support how agents think and act, not just how humans write.
Key requirements include:
Entity-centric: Memories should be attached to entities such as users, organizations, tickets, projects, or resources. The system needs to answer queries like "What does this user prefer?" or "What did we already try on this ticket?"
Typed memories with schemas: Raw text is not enough. A useful memory can be "user_pref: {format: 'markdown', tone: 'formal'}" or "incident: {id: 123, status: 'mitigated'}". Typed memories are easier to query, override, and audit.
Selective retention: Not every token deserves to be stored. Agents must store only meaningful, reusable facts. This requires extraction logic, filters, or LLM-backed summarization.
Cross-session and multi-agent sharing: Different agents must share relevant memories while respecting boundaries. A sales agent and a support agent may both need core account context, but not everything.
Low-latency retrieval and write paths: Memory access cannot dominate latency budgets. Both writes and reads need to be optimized for agent loops.
Upserts and evolution: A user's role, plan, or preferences can be updated. Memory should support merging, updating, and expiring entries.
Mem0 is designed as a memory layer that gives agent builders these capabilities with simple APIs and flexible deployment.
How Mem0 addresses the agent memory problem?
Mem0 treats memory as a first-class system component, not a side effect of logging. It provides an open-source, LLM-aware memory layer with:
Entity-based memory: Each memory is scoped to one or more entities such as
user_id,conversation_id, or custom identifiers. This makes it simple to ask "what do I know about X?" instead of scanning messages.Semantic and structured storage: Mem0 supports raw text memories and structured data. Under the hood, it uses embeddings and metadata, so agents can retrieve relevant memories using natural language or filters.
Automatic extraction from interactions: Mem0 can ingest chat messages, tool outputs, or event payloads. Developers can define what should be stored, and Mem0 uses LLMs to extract and normalize facts.
Cross-session continuity: Memory persists across sessions, applications, and models. An agent can recall facts from yesterday's call when responding today, without manual stitching.
Simple APIs and framework-agnostic integration: Mem0 works with any Python-based agent loop, whether custom or framework-based. All capabilities come through a small set of read, write, and search primitives.
This gives AI engineers a controlled way to attach durable memory to agents without hand-rolled vector stores and brittle retrieval prompts.
Integrating Mem0 into an agent loop
The following example shows a minimal Python pattern for integrating Mem0 with an LLM-powered agent. The agent:
Reads relevant memory for a user
Builds a prompt including personal context
Calls an LLM to generate a response
Writes new memories extracted from the interaction
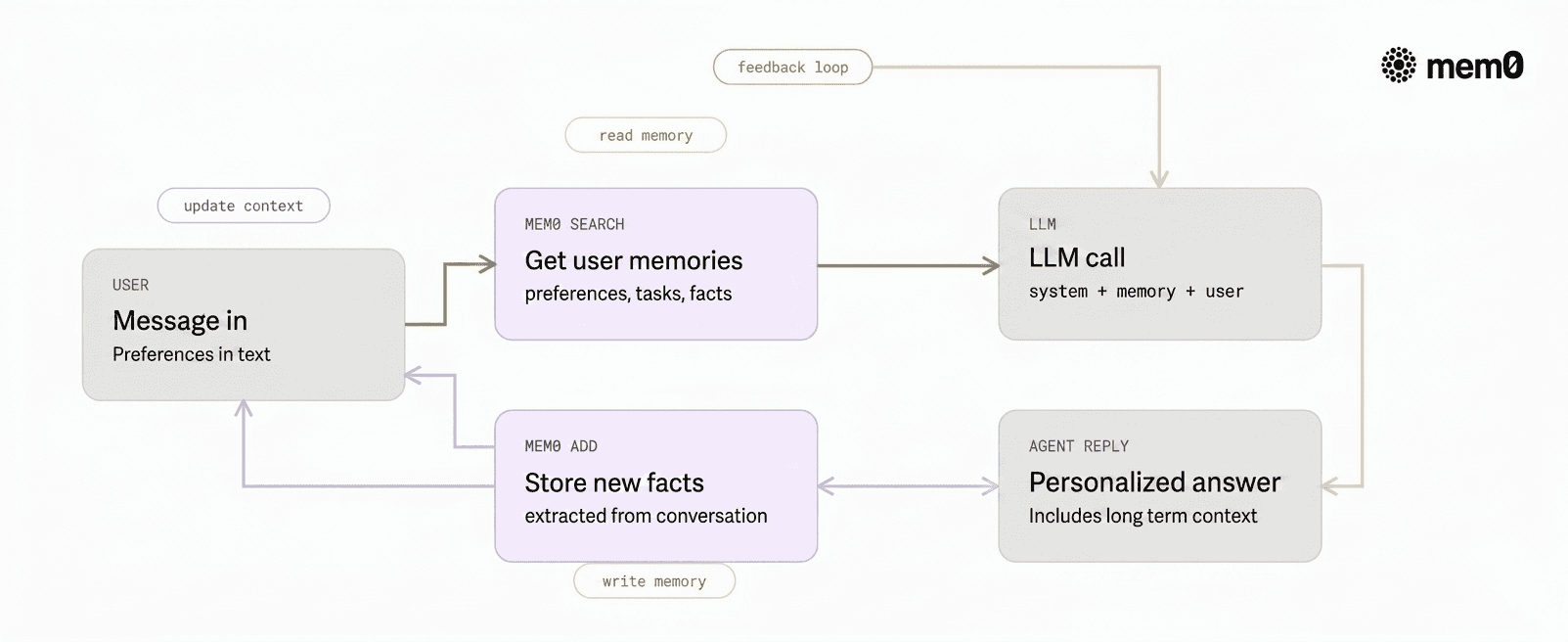
Fig: Read, reason, write loop with Mem0 inside an agent
This example uses minimal logic. In real systems, developers can add more precise extraction rules, custom schemas, and task-specific queries.
Context windows vs external memory vs Mem0
Several approaches exist for storing and reusing information in agentic systems. The table below summarizes how a dedicated memory layer compares with common alternatives.
Approach | Strengths | Weaknesses | Best used for |
|---|---|---|---|
Inline context window only | Simple to implement. Zero extra infra. | Loses history quickly. Expensive for long prompts. | Short, single-session tasks |
Raw logs in the database | Good for auditing and debugging. | Hard to query semantically. No structure for agents. | Compliance logs, offline analysis |
Plain vector store | Semantic search over text. Reusable building block. | No entity semantics. No memory types or versioning. | Document retrieval, RAG-style search |
Custom in-app key-value store | Fast and controlled. App-tailored structure. | Manual schema design. Hard to generalize and scale. | Small, domain-specific state |
Mem0 memory layer | Entity-based, semantic, and structured. LLM-aware. | Requires initial integration and modeling of entities. | Agentic AI with long-term personalization |
Mem0 does not replace every pattern. It fills the gap between unstructured logs and rigid application databases, with a design tuned specifically for LLM agents.
Using Mem0 in multi-agent workflows
Complex systems often orchestrate multiple agents that collaborate on a task. For example, a triage agent, a research agent, and an action agent might handle different parts of an incident.
Mem0 supports this style by letting each agent:
Read a shared pool of memories scoped by entities
Write new memories with source metadata
Filter by agent type, topic, or task ID
A typical pattern:
The triage agent writes a structured "incident" memory with fields
id,severity, andsuspected_cause.The research agent queries memories filtered by
incident_idandtype='incident'.The action agent retrieves both prior attempts and user-specific constraints before modifying systems.
This avoids prompt-spaghetti where every agent must have full history stuffed in context, and it encourages clear division of responsibility.
Designing memory schemas with Mem0
Effective use of Mem0 starts with modeling which entities the system cares about and what should be remembered. A practical approach is:
Identify entities: Typical entities include
user,organization,ticket,document,project, andrun_id. Each memory can attach to one or more of these.Define memory categories: Some examples of memory categories include,
preference,fact,decision,incident,task_state. These categories can live in metadata and prompt templates.Write extraction prompts: The user needs to provide Mem0 with instructions such as "extract stable user preferences and important account facts, ignore ephemeral details".
Plan lifecycle policies: The user needs to decide when memories should be updated, merged, or expired. For instance, a plan-type memory may always be overwritten by the latest value.
Although Mem0 handles embeddings and indexing internally, schema design remains a core design task for engineers. This mirrors how any production data system requires a thoughtful model.
Limitations of agentic memory patterns
Memory is essential for agentic AI, but it is not a magic cure. Several inherent limitations remain:
Incorrect or outdated memories: Agents can infer wrong facts or store transient information as if it were permanent. Without explicit update or deletion logic, these errors may propagate.
Privacy and data governance: Long-term memory increases the risk of storing sensitive data. Production systems must enforce consent, retention policies, redaction, and access controls.
Prompt and retrieval mismatch: Poorly designed prompts may ignore retrieved memories or use them incorrectly. Retrieval quality and LLM alignment both matter for correct behavior.
Cost and latency tradeoffs: Storing and retrieving memory is not free. Engineers must decide what to remember and how aggressively to query, in line with latency and cost budgets.
Behavioral brittleness: Over-reliance on memory can cause agents to stick to outdated assumptions. Balanced designs combine fresh context, long-term memory, and live tool calls.
Mem0 provides primitives that help manage these issues, but system design, evaluation, and governance are still necessary.
Frequently Asked Questions
What is agentic AI in practical terms?
Agentic AI refers to systems where LLMs act as goal-driven agents that plan, call tools, and iterate on tasks rather than simply answering a single prompt. They maintain state across steps and make decisions based on both current inputs and prior context.
Why is memory the missing piece for most agents today?
Most agents reset their understanding at every request, relying only on the current prompt and a limited context window. Without durable memory, they cannot personalize, continue long-running tasks, or learn from past interactions, which limits their usefulness in production settings.
When should an engineer move from simple context windows to a dedicated memory layer?
A dedicated memory layer becomes important when conversations span multiple sessions, when agents interact with many users, or when personalization and long-term task tracking are required. If prompts are growing unwieldy and still missing important prior details, it is time to introduce structured memory.
How does Mem0 differ from using a plain vector store for memory?
A plain vector store is mainly a semantic search engine over text chunks. Mem0 adds entity semantics, structured metadata, and LLM-aware extraction, so agents can store and retrieve meaningful facts about users, tasks, and decisions instead of arbitrary text fragments.
How can Mem0 be integrated into an existing agent framework?
Mem0 integrates through simple Python APIs for adding, searching, and managing memories. Engineers can insert Mem0 calls at the start of each agent loop for retrieval and after each interaction for storage, without rewriting planning or tool-calling logic.
Why use Mem0 for multi-agent systems instead of separate per-agent stores?
A shared memory layer allows different agents to collaborate around common entities such as users, tickets, or incidents while still scoping access via metadata. This reduces duplication, keeps a consistent view of the world, and simplifies debugging and auditing across agent boundaries.
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

