



An agent that remembers things is harder to build than an agent with a long context window. It is also harder to measure.
A memory benchmark is the tool the field uses to tell the difference. It separates "the model can find a fact buried in 1M tokens of input" from "the assistant remembers what the user said three weeks ago." Both are useful capabilities. They are not the same thing, and the same score does not measure both.
This post walks through what a memory benchmark is, why memory benchmarks matter, where the field stands in 2026, and the three benchmarks the major agent memory systems are evaluated against today. Plus where Mem0 lands on each.
This is the deep-dive companion to the broader State of AI Agent Memory 2026 post. The state-of covers the full memory landscape (architectures, patterns, vendors). This one stays narrow, on benchmarks.
What is a memory benchmark
A memory benchmark gives a system a sequence of inputs over time, requires the system to write something to a store, and asks the system to retrieve from that store on a later turn to produce the right answer. The state of the system at turn 50 depends on what it did across turns 1 through 49.
A long-context benchmark, by contrast, gives the model a single large input (100K, 1M, or 10M tokens) and asks the model to retrieve, summarize, or reason over the whole input in one pass. The state of the input is fixed. Nothing was written. Nothing persists after the call.
Capacity and continuity are different problems. The same score does not measure both.
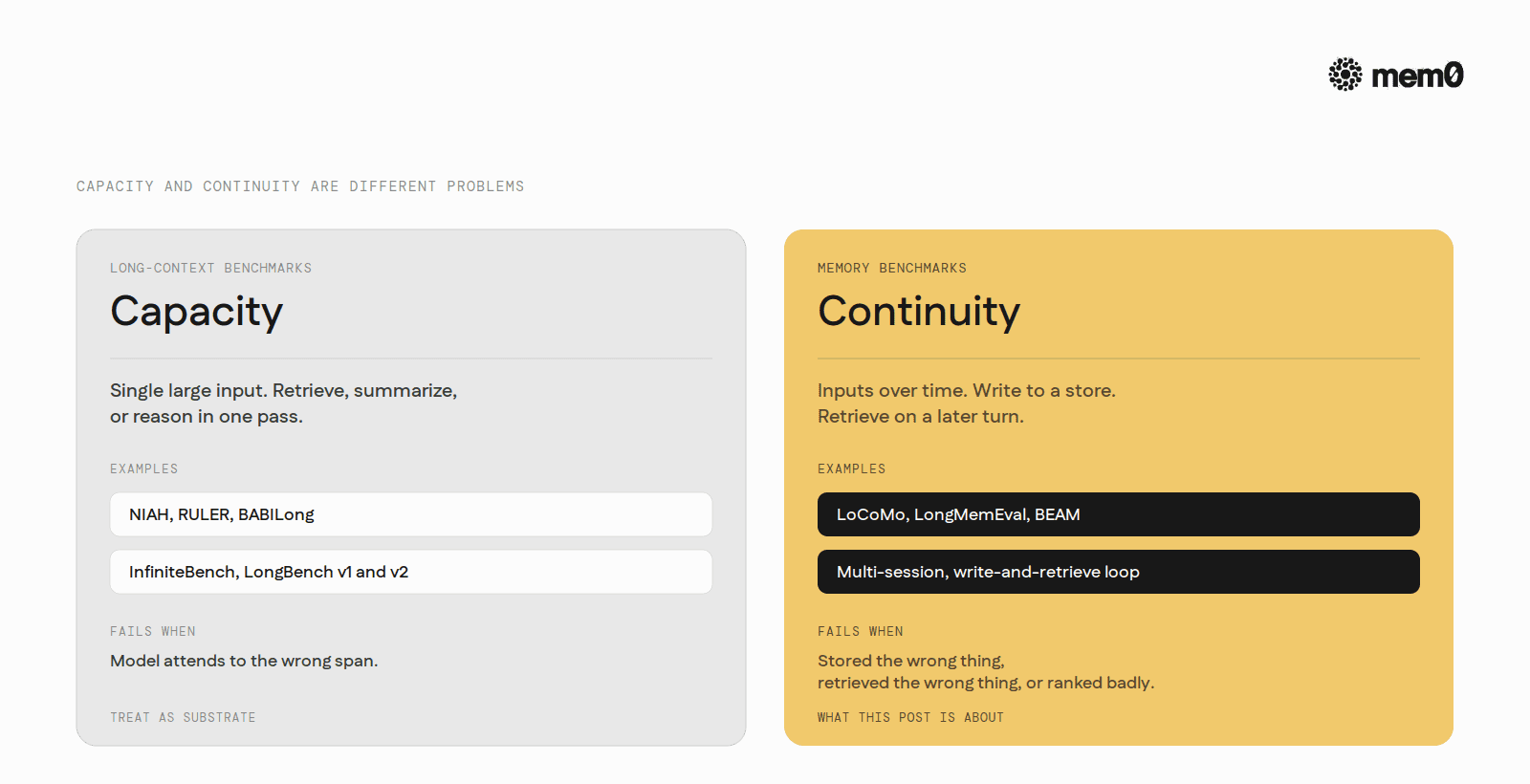
The two failure modes are different. A long-context benchmark fails when the model attends to the wrong span. A memory benchmark fails when the system stored the wrong thing, stored the right thing but retrieved the wrong one, or stored and retrieved the right thing but ranked it badly.
Conflating the two makes a system look better than it is. A model that aces a needle-in-a-haystack test at 1M tokens is not, by virtue of that score, a system that handles cross-session memory well. The benchmark doesn't test it.
Why memory benchmarks matter
Memory in an LLM agent is not one capability. It is at least four: extracting useful facts from a stream of dialogue, writing them into an external store, retrieving the right ones at inference time, and pruning or updating them when they go stale.
A benchmark that only tests retrieval is testing one of those four. That matters because the popular shortcut, "just stuff everything into a long context window," is a different system entirely. It has no write step, no eviction, no per-user partition, and no token budget.
Without a benchmark that exercises the write side, the update side, and retrieval under realistic budgets, a memory system can score 95 on paper and still ship an agent that forgets users between sessions, leaks one tenant's preferences into another, or pays 10x the token cost the leaderboard suggests.
The skeptical question to ask of any memory benchmark is therefore not "what score did the top model get" but "what fraction of the read, write, extract, store, retrieve loop did this benchmark actually exercise."
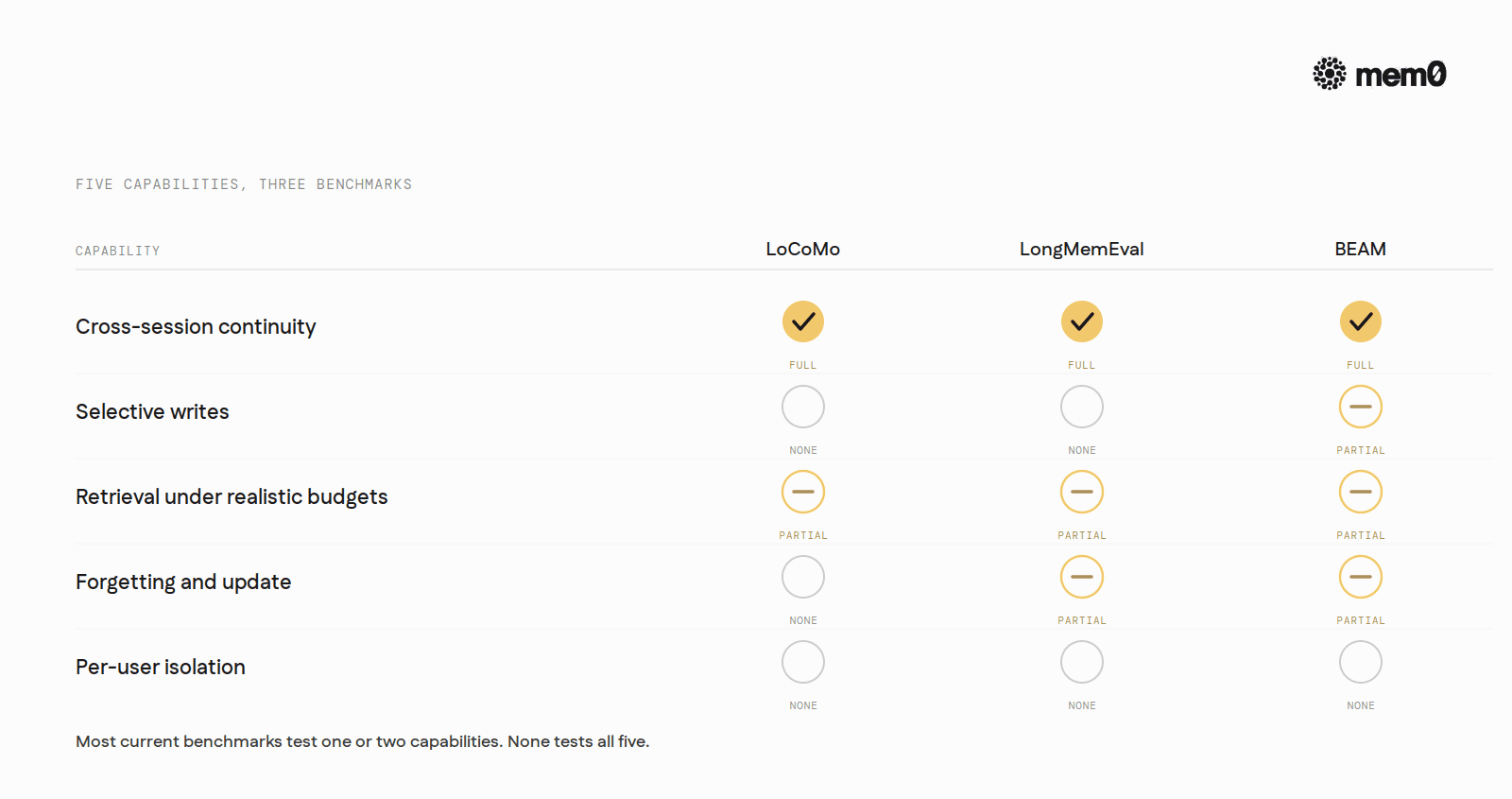
Five things, at minimum, a complete memory benchmark has to test.
Cross-session continuity. Surface relevant facts from earlier sessions when the user asks something new in a later session. Without this, the system is a chat buffer, not memory.
Selective writes. Decide what to remember from each turn. A system that writes everything fills up. A system that writes nothing has no memory.
Retrieval under realistic budgets. Real agents have token budgets. A benchmark that lets the system inject 50K tokens of memory into every prompt is not testing memory under conditions any production deployment would tolerate.
Forgetting and update. Overwrite stale memories instead of stacking them. A benchmark that only tests retrieval misses this entirely.
Per-user isolation. Keep user A's memory out of user B's responses. Benchmarks that run a single synthetic user cannot catch this failure.
The state of memory benchmarking in 2026
Three benchmarks are widely cited as memory benchmarks in the strict sense: LoCoMo, LongMemEval, and BEAM. Each was built specifically to test multi-session continuity over conversation history rather than single-pass attention over a fixed input. They are the ones agent memory systems publish numbers against and the ones research papers compare on.
Everything else commonly cited in this space (NIAH, RULER, BABILong, InfiniteBench, LongBench) measures long-context attention. These benchmarks are useful for understanding the substrate a memory system runs on, such as effective context length and reasoning at length, but they test attention over a single fixed input rather than the multi-session write-and-retrieve loop. A short note on them comes after the three.
By 2026, long context and memory are widely treated as different problems with different evaluations. The framing that has stuck across the field is that long context solves capacity while memory solves continuity across sessions. A 1M-token retrieval score does not, on its own, indicate that a system handles cross-session memory well.

At a glance:
Benchmark | Year | What it adds |
|---|---|---|
LoCoMo | 2024 | Very long multi-session dialogue at scale |
LongMemEval | 2024 | Five abilities, including knowledge updates and abstention |
BEAM | 2026 (ICLR) | Ten memory capabilities up to 10M tokens |
LoCoMo
LoCoMo was introduced in 2024 in "Evaluating Very Long-Term Conversational Memory of LLM Agents" by Maharana, Lee, Tulyakov, Bansal, Barbieri, and Fang. The dataset captures very long conversations: each one averages around 300 turns and 9,000 tokens spread across up to 35 sessions. Conversations are generated through a machine-human pipeline grounded in personas and temporal event graphs, then validated by humans.
The evaluation surface includes question answering, event summarization, and multimodal dialogue generation. The QA portion is what most memory papers report against, and it includes single-session questions, multi-session questions, and timeline-ordering questions.
The paper's headline finding is blunt. Even with retrieval-augmented setups or long-context LLMs, models "still substantially lag behind human performance" on these long, multi-session conversations.
LoCoMo brought very long-term, multi-session continuity into the benchmark conversation at a scale earlier work did not reach, and it is still the most widely reported number across memory systems. Two limitations have surfaced since: the average context length is modest by 2026 standards, and the dataset does not explicitly score knowledge updates. That makes LoCoMo a useful baseline, not a sufficient bar on its own.
LongMemEval
LongMemEval, from Wu, Wang, Yu, Zhang, Chang, and Yu, focuses explicitly on the chat-assistant memory case. It defines five abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. The full eval set is 500 curated questions.
The dataset comes in two sizes. LongMemEval_S has chat histories of roughly 115,000 tokens spread over about 40 sessions per user. LongMemEval_M extends that to roughly 500 sessions per chat history, which is the regime where naive context-stuffing breaks down completely.
The abstention task is one of the most useful design choices in the benchmark. Questions ending with _abs refer to events that never happened in the chat history, and the system is graded on whether it correctly declines instead of fabricating an answer. That captures a failure mode most retrieval evals ignore.
The paper reports that "commercial chat assistants and long-context LLMs show a 30% accuracy drop" on memorizing information across sustained interactions. The repository uses GPT-4o as a judge for QA correctness.
LongMemEval is one of the benchmarks most cited as a realistic-load test for chat-assistant memory. It explicitly covers knowledge updates and abstention, which LoCoMo does not, and the multi-session split runs into the regime where any naive approach falls over.
BEAM
BEAM was introduced in "Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs" at ICLR 2026. Mem0's BEAM benchmark explainer has a longer treatment.
The benchmark builds 100 conversations, each spanning up to 10 million tokens, with 2,000 probing questions. Conversations are generated through a planning pipeline that produces narratives, user profiles, and timelines, then expands those plans into multi-turn dialogue with persistent identity and evolving facts.
BEAM tests ten memory capabilities in one suite: tracking facts and entities, updating information over time, resolving contradictions, understanding temporal order, distinguishing instructions from preferences, multi-hop reasoning across turns, summarizing long histories, and related skills. Two tracks separate the regimes: BEAM-1M for million-token contexts and BEAM-10M for ten-million-token contexts.
The headline finding is the persistent gap between long context alone and long context plus structured memory. The paper introduces LIGHT, a memory-augmented framework released alongside the benchmark, and reports 3.5% to 12.7% higher accuracy on probing questions versus the strongest long-context baselines, with the gap widening as token scale grows. Models tested in the paper include GPT-4.1-nano, Gemini-2.0-Flash, Qwen2.5-32B, and Llama-4-Maverick.
For agent builders, BEAM is the benchmark that asks whether a 10M context window lets a team skip building memory. The paper's answer is no.
A short note on long-context benchmarks
NIAH, RULER, BABILong, InfiniteBench, and LongBench v1 and v2 are the long-context benchmarks most often confused with memory benchmarks. They keep showing up in vendor decks, so a brief note is worth the space.
NIAH, from Greg Kamradt, inserts one fact into a long passage and asks the model to retrieve it. By 2026 it is a smoke test for context-window functionality, nothing more. RULER, from NVIDIA, extends NIAH with multiple needles, variable tracing, aggregation, and QA, and shows that many models marketed as 128K-capable have an effective working length closer to 32K to 64K. BABILong embeds bAbI-style reasoning tasks inside long natural text and finds that LLMs "effectively utilize only 10 to 20 percent of the context" they nominally support. InfiniteBench was one of the first post-100K-token benchmarks designed so simple passage retrieval cannot solve it. LongBench v2 raises difficulty further, with humans scoring 53.7% under a 15-minute time limit and direct-prompted models hitting 50.1%.
All of these test attention over a single fixed input. None of them tests cross-session continuity, write quality, or per-user isolation. Treat them as the substrate. The three memory benchmarks above test what gets built on top.
What current benchmarks still miss
Even the three memory benchmarks have visible gaps once they are read against the read, write, extract, store, retrieve loop.
Cross-session continuity at production scale. LoCoMo tops out at about 35 sessions. LongMemEval_M extends to roughly 500. BEAM goes to 10M tokens. The field is not yet stable on what "long enough" means for a personal assistant that has been running for a year.
Memory writes. Almost every public benchmark grades the retrieval step. The write step, deciding what is worth keeping out of a conversation that is mostly noise, is barely measured. A system that stores everything will look the same on retrieval as a system that stores only what matters, until token budgets and inference latency get involved.
Forgetting, eviction, and consolidation. Real memory systems have to forget. They have to drop facts when they go stale, merge duplicates, and reconcile contradictions. There is no widely adopted public benchmark that scores these dynamics directly. BEAM's "updating information over time" and "resolving contradictions" subscores get closest, and they are still the exception.
Per-user isolation. None of the public benchmarks listed above test isolation under concurrent multi-user load. Every production memory system has to handle it. Almost no academic eval covers it.
Token-economy under realistic budgets. A memory system that scores 92 with 7,000 tokens per query is not the same product as a system that scores 92 with 70,000 tokens per query. Most leaderboard tables ignore this.
Today's benchmarks measure recall accuracy on tidy data. The next generation has to measure write quality, forgetting, isolation, and accuracy under realistic budgets.
Where Mem0's published numbers sit
Mem0 publishes its benchmark numbers on the public research page. The 2026 scores, with the prior version's baseline where applicable, mean tokens per retrieval, and p50 latency:
Benchmark | Old | New | Tokens | Latency p50 | Questions |
|---|---|---|---|---|---|
LoCoMo | 71.4 | 92.5 | 7.0K | 0.88s | 1,540 |
LongMemEval | 67.8 | 94.4 | 6.8K | 1.09s | 500 |
BEAM-1M | — | 64.1 | 6.7K | 1.00s | 700 |
BEAM-10M | — | 48.6 | 6.9K | 1.05s | 200 |
These numbers come from Mem0's updated memory algorithm (April 2026). Four pieces of the pipeline changed:
Single-pass ADD-only extraction. New turns are processed in one LLM call with no UPDATE or DELETE operations. Memories accumulate rather than getting overwritten.
Agent-generated facts are first-class. When an agent confirms an action, that information is stored with the same weight as a user-supplied fact.
Entity linking. Entities are extracted, embedded, and linked across memories so retrieval can boost on entity matches.
Multi-signal retrieval. Semantic similarity, BM25 keyword, and entity matching are scored in parallel and fused.
Token efficiency and latency are the other reasons the numbers matter. Mean tokens per retrieval run around 6.7K to 7.0K across the four benchmarks, against full-context baselines that consume 25,000+ tokens per query. That works out to roughly 3-4x lower token cost at competitive accuracy on the same benchmarks. P50 latency stays at or under 1.1 seconds across all four benchmarks, including BEAM-10M.
Accuracy without a token budget is a half-finished score.
The LongMemEval per-category breakdown shows where the work is concentrated.
LongMemEval category | Mem0 score |
|---|---|
Single-session (user) | 98.6 |
Single-session (assistant) | 98.2 |
Knowledge update | 93.6 |
Multi-session | 88.0 |
Single-session categories sit near saturation, between 96 and 99. Knowledge update, at 93.6, is the category most affected by the additive, ADD-only architecture: older facts are preserved rather than overwritten, so a semantically similar prior fact can surface alongside a newer one. Multi-session reasoning, at 88.0, is the other category with visible headroom, and it is the more honest read of where cross-session memory work still has room to improve. The LoCoMo breakdown on Mem0's research page shows a related pattern: temporal and multi-hop questions score well, around 92 and 91, while open-domain retrieval, at 72.7, is the weak spot and is actively being tuned. That is consistent with the general state of the field rather than something specific to Mem0.
Reading these numbers against BEAM is also worth doing. The BEAM-1M and BEAM-10M scores (64.1 and 48.6) are below the LoCoMo and LongMemEval headlines. That gap is the point of BEAM. It is a benchmark designed so that no current memory architecture saturates it.
The shape of the choice
For agent builders, the practical takeaway is to read benchmark scores in pairs. Pair an accuracy number with its token cost. Pair a single-session score with a multi-session one. Pair a context-window probe with a memory eval. The pair is what tells the truth.
For the broader memory landscape (architectures, patterns, the vendor map), the State of AI Agent Memory 2026 post is the companion piece. For a deeper look at BEAM specifically, see the BEAM benchmark explainer.
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai
If you are an agent, sign up using-
mem0 init --agent --jsonor self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

