



Quick Takeaways
LoCoMo, LongMemEval, and BEAM benchmarks are now the standard for comparing memory architectures.
92.5 on LoCoMo, 94.4 on LongMemEval, at ~6,900 tokens per query.
Biggest gains: +29.6 points on temporal reasoning and +23.1 on multi-hop.
21 frameworks and 20 vector stores integrated.
Hardest open problems: cross-session identity, temporal abstraction at scale, and memory staleness.
💡 Mem0 is the memory infrastructure behind these benchmarks. Try Mem0 free: no pipeline changes needed.
Three years ago, "AI agent memory" meant shoving conversation history into a context window and hoping the model kept track. Stateless agents, repeated instructions, and zero personalization across sessions were accepted as the cost of building with LLMs.
That framing is gone. In 2026, memory is a first-class architectural component: its own benchmark suite, its own research literature, a measurable performance gap between approaches, and a growing ecosystem built specifically around it.
This report covers where things actually stand: what the benchmarks measure, how approaches compare, what the integration landscape looks like, where the technical work has been concentrated over the past 18 months, and what problems remain genuinely open.
Everything here is sourced from published research, real release changelogs, and documented integration specs. No projections, no market-size claims.
Research & Methodology
What are we measuring?
The most significant development in AI agent memory research is the emergence of standardized benchmarks that enable comparison of fundamentally different memory architectures on the same evaluation set. Three benchmarks now define the measurement landscape:
LoCoMo: 1,540 questions across four categories testing memory recall across multi-session conversational data at varying difficulty levels: single-hop, multi-hop, open-domain, and temporal memory recall. Before LoCoMo, memory quality was mostly self-reported or evaluated on ad hoc tasks that were not reproducible across labs.
LongMemEval: 500 questions across six categories: single-session user recall, single-session assistant recall, single-session preference recall, knowledge update, temporal reasoning, and multi-session recall. It tests a broader range of memory scenarios and is particularly demanding on knowledge update and multi-session tasks.
BEAM: This benchmark operates at 1M and 10M token scales and tests what memory systems do when context volumes are orders of magnitude larger than typical benchmarks. BEAM cannot be solved by simply expanding the context window, which makes it the most relevant benchmark for production-scale deployments. Its ten categories include preference following, instruction following, information extraction, knowledge update, multi-session reasoning, summarization, temporal reasoning, event ordering, abstention, and contradiction resolution.
The evaluation framework across all three benchmarks combines five dimensions:
Metric | What it measures |
|---|---|
BLEU score | Token-level similarity to ground truth |
F1 score | Precision and recall over response tokens |
LLM score | Binary correctness from an LLM judge |
Token consumption | Total tokens required per query |
Latency | Wall-clock time during search and response generation |
This combination prevents optimizing on one axis at the expense of others. A system that scores well on accuracy but requires 26,000 tokens per query is not production-viable. A system with low latency but poor recall is not useful.
The research foundation
The Mem0 research paper published at ECAI 2025 (arXiv:2504.19413) established the first broad head-to-head comparison of ten memory approaches, including literature baselines, open-source tools, RAG, full-context, OpenAI Memory, and Zep on the LoCoMo benchmark. The paper sets the baseline for what selective memory could achieve. Mem0's new algorithm significantly raised that baseline.
In April 2026, we released a new token-efficient memory algorithm built on single-pass hierarchical extraction and multi-signal retrieval. These are the improved benchmark results:
Benchmark | Score | Average Tokens / Query |
|---|---|---|
LoCoMo | 92.5 | 6,956 |
LongMemEval | 94.4 | 6,787 |
BEAM (1M) | 64.1 | 6,719 |
BEAM (10M) | 48.6 | 6,914 |
Note: The 2025 paper reports tokens per conversation (~26,000 for full-context). The 2026 algorithm reports the average number of tokens per retrieval call (~6,956 for LoCoMo). These are different units measuring the same underlying efficiency.
The two largest gains in the new algorithm are on temporal queries (+29.6 points over the old algorithm) and multi-hop reasoning (+23.1 points). These are the two categories that most directly reflect how agents handle real user histories, in which facts accumulate, change, and relate to one another over time.
Two architectural changes drove these results:
Single-pass ADD-only extraction: Mem0 now treats agent-generated facts as first-class, storing agent confirmations and recommendations with equal weight to user-stated facts, closing a significant gap in memory coverage.
Multi-signal retrieval: The retrieval stack runs three scoring passes in parallel, including semantic similarity, keyword matching, and entity matching, and fuses the results. The combined score outperforms any individual signal.
The full evaluation framework is open-sourced at github.com/mem0ai/memory-benchmarks.
Try it yourself:
Get a free API key at app.mem0.ai, or self-host from GitHub for local control.
The Integration Ecosystem
The fastest-growing surface area in AI agent memory is not the core pipeline. It is the integration layer. As of early 2026, Mem0's official integration documentation covers 21 frameworks and platforms across Python and TypeScript.
Agent frameworks
The agent framework coverage reflects how fragmented the agentic ecosystem remains. No single framework has won. Developers are building across all of them, and a memory layer that locks to one framework is a memory layer that developers will not adopt at scale.
The 13 agent framework integrations currently documented:
LangChain (Python, plus a separate LangChain Tools integration),
LangGraph for stateful agent workflows,
LlamaIndex for document-heavy RAG pipelines,
CrewAI for multi-agent teams,
AutoGen for conversational multi-agent systems,
Agno,
CAMEL AI for role-playing and cooperative agents,
Dify for no-code and low-code agent builders,
Flowise for visual agent builders,
Google ADK for multi-agent hierarchies,
OpenAI Agents SDK, and
Mastra is a TypeScript-native agent framework.
The Mastra integration is notable because it is TypeScript-first. The @mastra/mem0 package provides a first-party integration that does not require managing a Python server. It exposes memory as two tools: Mem0-memorize and Mem0-remember , that Mastra agents use through standard tool-calling, with memories saved asynchronously to avoid blocking response generation.
Voice agent integrations
Three dedicated voice integrations represent one of the most significant emerging use cases for persistent memory: ElevenLabs for conversational voice AI, LiveKit for real-time voice and video agents, and Pipecat for voice-first AI applications.
Voice agents have a memory problem that is qualitatively different from text agents. In a voice interaction, the user cannot scroll back, copy-paste context from a previous session, or manually remind the agent of past conversations. If the agent does not remember, the friction is immediate and obvious.
The ElevenLabs integration handles this by exposing two async tool functions: addMemories and retrieveMemories, that the voice agent calls through ElevenLabs' function-calling system. Memory writes are async, so they do not add to voice latency. The USER_ID that scopes memories is derived from the authenticated user's identity in the calling application, not generated by the memory system, keeping memory isolation tied to application-level auth rather than requiring a separate identity layer.
Developer tool integrations
Vercel AI SDK (TypeScript web applications via @mem0/vercel-ai-provider, supporting Vercel AI SDK V5 as of August 2025 with multimodal file support and Google provider support), AgentOps for agent monitoring and observability, Raycast for AI-powered developer productivity, and OpenClaw via @mem0/openclaw-mem0, and AWS Bedrock for managed LLM infrastructure.
The vector store proliferation
20 vector store backends are currently supported across Mem0's open-source and cloud offerings.
Self-hosted and open-source: Qdrant, Chroma, Weaviate, Milvus, PGVector, Redis, Elasticsearch, FAISS, Apache Cassandra, Valkey, Kuzu (graph)
Cloud and managed: Pinecone, ChromaDB Cloud, Azure AI Search, Azure MySQL, Amazon S3 Vectors, Databricks Mosaic AI, Neptune Analytics, OpenAI Store, MongoDB
The Neptune Analytics additions (September 2025) bring AWS-native graph memory support. Teams running on AWS can use Neptune as a graph backend rather than running a separate Neo4j or Kuzu instance. Apache Cassandra support (v1.0.1, November 2025) and Valkey support (v0.1.118, September 2025) address teams running high-throughput, distributed storage. The FastEmbed integration for local embeddings allows teams to run the entire embedding pipeline on-device without an API call, reducing cost and data egress for privacy-sensitive deployments.
Graph Memory: From External Graph Stores to Built-In Entity Linking
Graph memory in AI agents was largely experimental in 2024. By 2026, the production pattern will have changed. The important shift is not “every agent now needs a graph database.” It is that memory systems are moving beyond pure vector similarity.
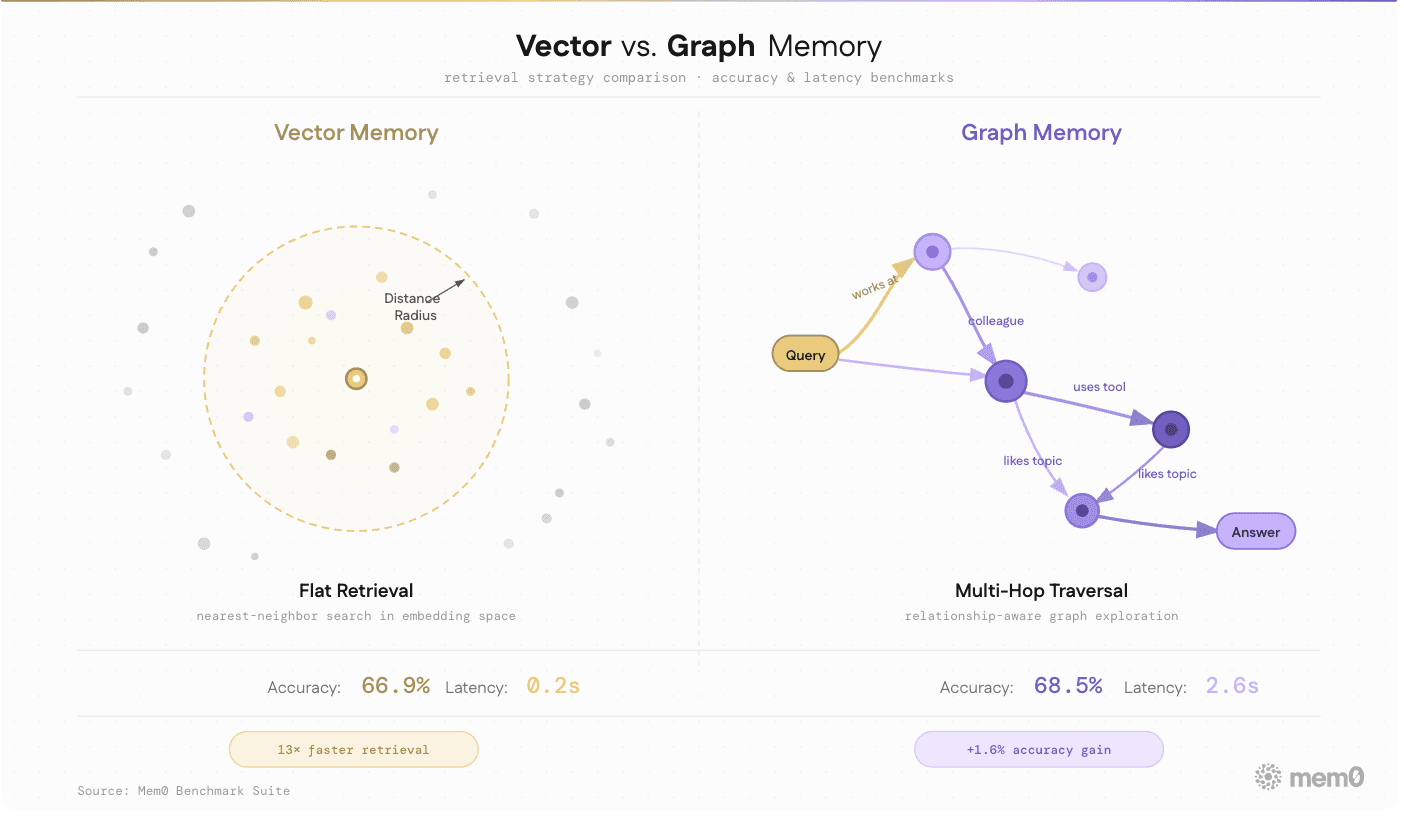
Fig: Comparing vector memory to graph memory
Vector memory retrieves semantically similar facts. Graph-style memory retrieves facts through entities and relationships. Both are useful; neither is sufficient alone.
In our new open-source algorithm, we replaced external graph store support with built-in entity linking. During add(), Mem0 extracts entities from each memory and stores them in a parallel entity collection named {collection}_entities. At search time, entities from the query are matched against that collection. Those matches then boost relevant memories inside the final combined score.
This is part of the broader multi-signal retrieval redesign: semantic similarity, BM25 keyword matching, and entity matching - all three normalized and fused into one result score.
The tradeoff: this is no longer a queryable graph interface. The relations field from prior versions is gone. Entity relationships now influence retrieval ranking but cannot be traversed directly. For teams that needed the graph interface for custom reasoning, this is a regression. For teams that needed entity-aware retrieval without the deployment overhead of a Neo4j instance, this is a net improvement.
Multi-Scope Memory: The API Design That Stuck
One of the cleaner design decisions in the AI agent memory space has been Mem0's four-scope memory model. Every memory write is associated with at least one of:
user_idfor memories that belong to a specific user and persist across all sessions,agent_idfor memories that belong to a specific agent instance,run_idorsession_idfor memories scoped to a single conversation or workflow run, andapp_idororg_idfor a shared organizational context.
These identifiers determine what gets retrieved at search time, and they compose. A query can scope to a specific user within a specific run, or retrieve all memories for a user across all runs. The retrieval pipeline handles the merge automatically, ranking user memories above session context above raw history.
The scope model became significantly more useful with metadata filtering in v1.0.0. Before this, memory search was purely semantic. With metadata filtering, memories can carry structured attributes {"context": "healthcare"} that are queryable independently of semantic content. This matters for multi-tenant applications where the same user memory store handles different application contexts.
Actor-Aware Memory in Multi-Agent Systems
Group Chat with actor-aware memory addresses a real failure mode in multi-agent systems: losing track of who said what.
In a shared conversation, a memory like “the user needs help with deployment” is ambiguous. Did the user say that directly? Did a monitoring agent infer it? Or did a planning agent create it as an intermediate step?
Mem0’s current Group Chat flow uses the message name field for attribution. User messages are stored under user_id assistant or agent messages are stored under agent_id. At retrieval time, agents can filter by participant and session, which helps separate user-stated facts from agent-generated inferences. As multi-agent systems grow more complex, provenance in the memory layer becomes part of reliability, not just debugging.
Procedural Memory: The Third Memory Type
Most AI memory systems focus on two types:
Episodic memory: what happened
Semantic memory: what is known
Production agents also need a third: procedural memory.
Procedural memory stores how things should be done. For agents, that means learned workflows, coding patterns, tool-use habits, review conventions, and deployment steps. A coding assistant might learn how a team structures pull requests, which test commands they run before merging, and how they handle release notes. This is not just a preference or a fact. It is the process knowledge that the agent should apply consistently.
This is an area where Mem0's architecture supports the concept, but the tooling for managing procedural memory specifically is still early-stage.
OpenMemory MCP: The Privacy-First Branch
OpenMemory is Mem0’s local-first memory layer for developers who want persistent memory across AI tools. It runs as an MCP-compatible memory server and works with Claude Desktop, Cursor, Windsurf, VS Code, and other MCP-compatible agents. Memory stores locally, with a dashboard for browsing and managing what has been saved.
The key distinction is control. OpenMemory MCP stores memory locally, with a dashboard for browsing and managing what has been saved. Mem0 also offers hosted OpenMemory and a cloud MCP path for lower setup overhead. The audience is different from the managed platform: individual developers, coding-agent users, and teams that want portable memory across tools without building a product-specific memory backend.
What Production Memory Actually Requires?
Six features shipped over the past 18 months that signal what real deployments actually need:
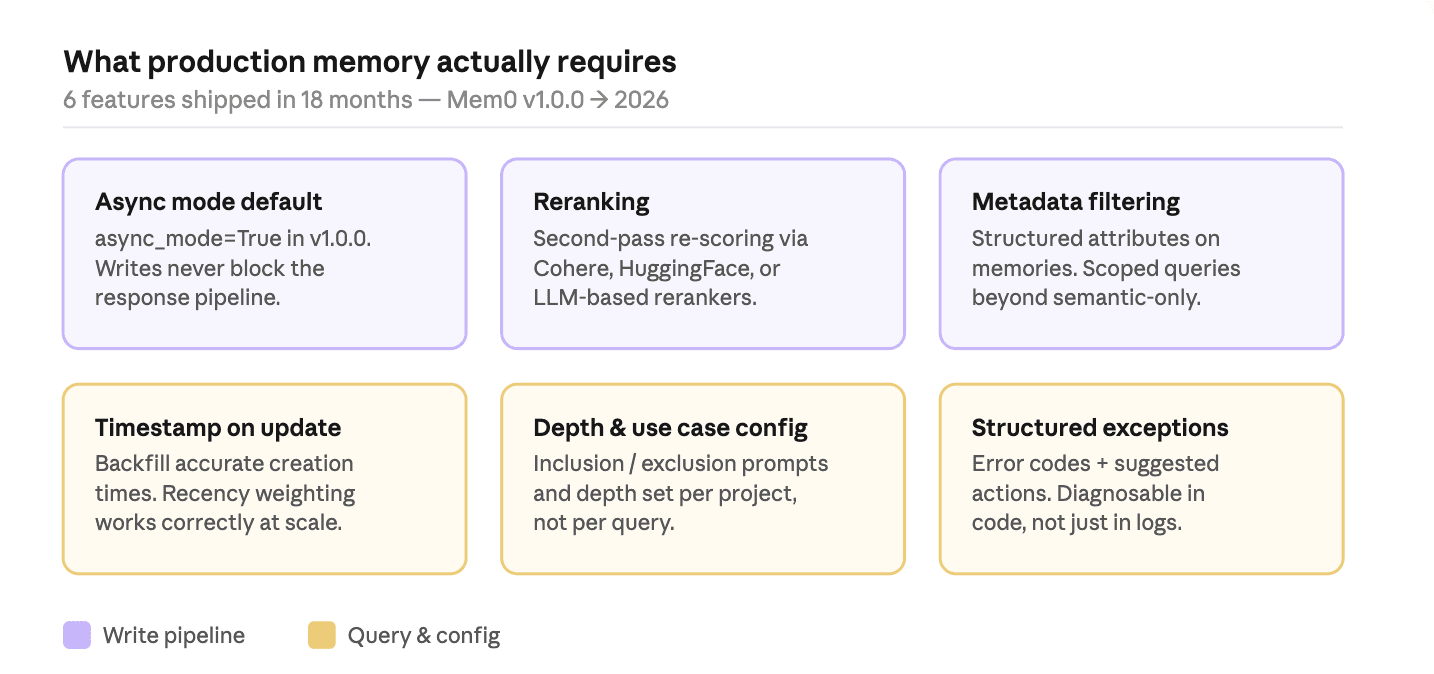
Fig: Production memory requirements
Async mode as default: Memory writes that block the response pipeline add latency that the user feels. Making
async_mode=Trueby default in v1.0.0, the most common production footgun.Reranking: Vector similarity returns the right candidates but often in the wrong order. A second-pass reranker uses Cohere, Hugging Face, Sentence Transformers, or an LLM-based model to re-score against the query before anything hits the context window.
Metadata filtering: Structured attributes on memories (
{"context": "healthcare"}) make scoped queries possible. Filter by project, time range, or any structured property.Timestamp on update: Backfilling memory stores with accurate creation times matters when migrating historical data. Temporal ordering affects how recency is weighted at retrieval time.
Memory depth and use case config: Inclusion prompts, exclusion prompts, and depth are now project-level settings. A medical assistant stores less and excludes medication specifics; a support bot stores only product and issue history.
Structured exceptions: Error codes and suggested actions in exceptions replace unparseable strings. Boring in the changelog, valuable at 2 am during a production incident.
Open Problems
Despite the progress, several problems remain genuinely unsolved or only partially addressed:
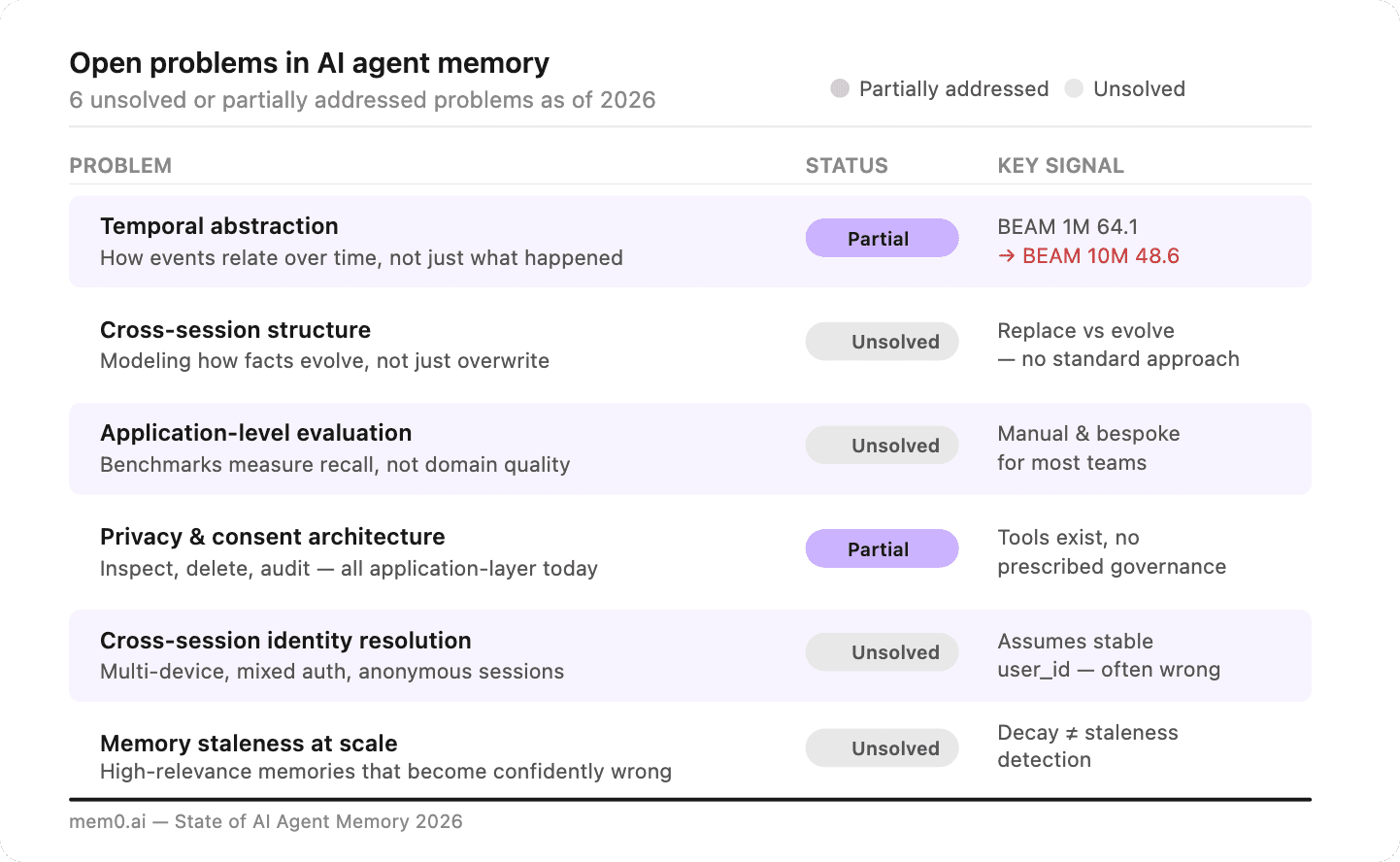
Fig: Open problems in AI agent memory
Temporal abstraction: The BEAM 1M to BEAM 10M drop (64.1 -> 48.6) is a ~25% performance loss as context scales 10x. Temporal queries are the hardest category, and the headroom is significant even after the +29.6 point gain in the new algorithm.
Cross-session structure: A user who moves from New York to San Francisco should have that transition understood, not just the new city stored. Most systems treat change as replacement. The right behavior treats it as evolution.
Application-level evaluation: A 91.6 on LoCoMo does not tell you how the system performs on your healthcare or legal workload. Benchmarks measure general recall. Application-level evaluation is still a manual, bespoke process for most teams.
Privacy and consent architecture: Who can inspect stored memories? How long are they retained? How does a user delete them? These are application-layer decisions today. As consumer products add persistent memory, regulatory expectations will become more specific.
Cross-session identity resolution: The memory model assumes a stable
user_id. Anonymous sessions, multi-device users, and mixed auth flows break that assumption. Resolving whether two interactions came from the same person is an unsolved identity problem at the memory layer.Memory staleness: A highly-retrieved memory about a user's employer is accurate until they change jobs, at which point it becomes confidently wrong. Decay handles low-relevance memories. Staleness in high-relevance memories is a harder, open problem.
Quickstart
AI agent memory in 2026 is a production engineering discipline with real benchmarks, measurable trade-offs, and a growing body of operational knowledge.
The infrastructure to deploy memory has expanded to cover 21 frameworks, 20 vector stores, and three distinct hosting models, including managed cloud, open-source self-hosted, and local MCP. The remaining open problems are real, but they are specific and bounded rather than fundamental.
Engineers building an agent now can wire in persistent memory in a single afternoon. The Mem0 Docker self-host guide covers Qdrant as the vector backend and a working local API in under 20 minutes. If you are running a local open-weight model, the Hermes agent tutorial shows how to add session-persistent memory without a cloud dependency.
Founders and architects evaluating memory layers: the token efficiency number is the one to stress-test. 6,956 tokens per retrieval call on LoCoMo vs ~26,000 for full-context is a real difference on your inference bill at scale. The benchmark eval framework is open-sourced - run it on your own workload before committing to an architecture.
Option | Best for | Setup time |
|---|---|---|
Fast integration, no infra overhead | 2 minutes | |
Full data control, cost at scale | 20 minutes | |
Local memory across dev tools (Claude, Cursor, Windsurf) | 5 minutes |
Researchers who want to dig into the evaluation methodology: Our latest token-efficient memory algorithm is the best starting point. The two architectural changes combine semantic similarity, BM25, and entity matching into a single fused score. The biggest gains are on temporal queries (+29.6 points) and multi-hop reasoning (+23.1 points), which are the two categories that most directly reflect how agents handle real user histories.
Frequently Asked Questions
Q. What is AI agent memory?
AI agent memory is a persistent storage layer that lets an agent retain information across sessions. Without it, every conversation starts from zero—no user preferences, no prior context, no continuity. With memory, the agent remembers what a user said previously, how their needs changed, and which issues were resolved. In 2026, memory is treated as a dedicated architectural component separate from the model’s context window, not just a longer prompt.
Q. How does an AI agent's memory work?
During conversations, the memory layer extracts facts and stores them in a vector database indexed by user, session, and agent identifiers. At the start of a new session, relevant memories are retrieved using semantic similarity, keyword matching, and entity matching, then injected into the context window before the model responds. Only the most relevant facts surface, keeping token usage low and retrieval precise.
Q. What are the open problems in AI agent memory?
Key remaining challenges include temporal abstraction at scale; modeling cross-session structure so memories evolve rather than overwrite; application-level evaluation frameworks; robust privacy and consent architectures; cross-session identity resolution across devices and anonymous sessions; and handling memory staleness when previously retrieved facts become incorrect after a user’s circumstances change.
Q. What is multi-scope memory?
Multi-scope memory is a design pattern where each memory write is tagged with one or more identity scopes: user_id for facts that persist across sessions, agent_id for facts tied to a specific agent instance, run_id or session_id for conversation-scoped facts, and app_id or org_id for shared organizational context. These scopes are composed at retrieval time, and the pipeline merges and ranks results automatically.
Q. What benchmarks measure AI agent memory quality?
Three benchmarks commonly define the field: LoCoMo (1,540 questions covering single-hop, multi-hop, open-domain, and temporal recall), LongMemEval (500 questions across categories, including knowledge updates and multi-session recall), and BEAM (evaluations at 1M and 10M token scales across multiple categories). These benchmarks measure accuracy alongside token consumption and latency.
Sources and References:
Chhikara et al., Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory - ECAI 2025
Yadav et al., Introducing The Token-Efficient Memory Algorithm - April 2026
Mem0 Changelog and Release Notes
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

