



Claude Code is a phenomenal piece of technology. But it is affected by the same problem every LLM is affected by, which is a lack of memory.
Every time you start a Claude Code session, you need to re-explain your project architecture, re-state your coding preferences, and re-describe bugs you have already fixed. This repetition wastes time and tokens. This guide walks you through adding a persistent memory layer to Claude Code using the Mem0 plugin, covering both CLI and desktop versions.
Mem0 offers two paths for adding memory to Claude Code:
Mem0 Platform MCP: hosted cloud memory, zero local setup, managed retrieval. This is what the plugin marketplace installs and what this guide covers.
OpenMemory MCP: local-first, self-hosted memory that runs entirely on your machine with no cloud sync or external storage. All data stays local and under your control.
If you prefer local-first memory with no cloud dependency, see the OpenMemory MCP setup guide. The rest of this article covers the Platform MCP path via the plugin marketplace.
Why Add Memory to Claude Code?
Without memory, Claude Code starts every session with zero context. You spend the first several minutes re-establishing what the project does, what patterns you follow, and what you already tried. With a persistent memory layer, Claude recalls that context automatically from prior sessions.
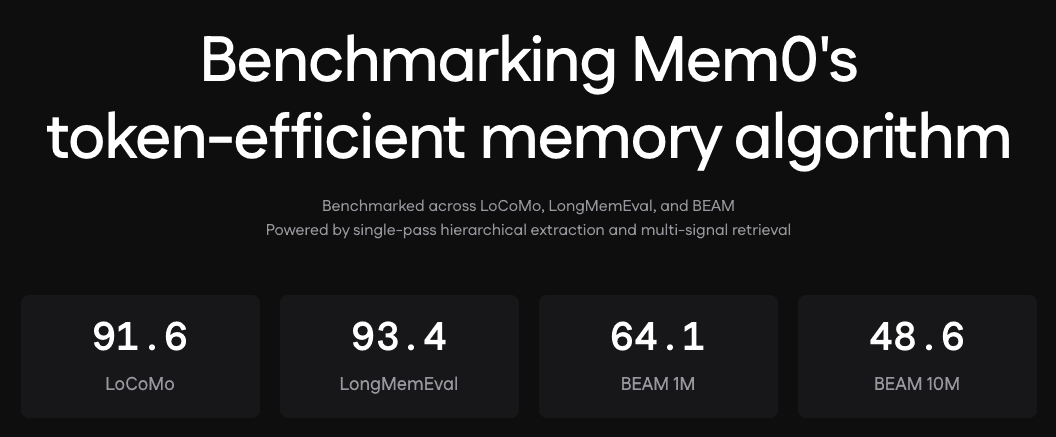
In our internal tests, adding memory reduced context-establishment overhead significantly for complex, multi-session tasks, though results vary by project type and session length. For published benchmark numbers: in April 2026, Mem0 released an updated memory algorithm achieving 91.6% accuracy on the LoCoMo benchmark while using roughly 3–4x fewer tokens than full-context approaches, through single-pass extraction and hybrid retrieval.
We saw similar results with our internal benchmarks.
How To Implement Memory In Claude Code With Mem0
The Mem0 plugin for Claude Code has three components:
MCP Server: Connects Claude Code to Mem0's cloud memory layer via the hosted HTTP MCP endpoint. Provides nine memory tools: add, search, get, update, delete, and more.
Lifecycle Hooks: Automatically captures learnings at key lifecycle points: session start, context compaction, task completion, and session end.
SDK Skill: Teaches the agent how to integrate the Mem0 SDK into your applications.
The plugin uses Mem0's hosted HTTP MCP server, not a locally installed Python package. Your user_id ID is derived deterministically from your API key, meaning the same key gives you the same identity across every machine.
Important behavioral note: The current plugin does not automatically inject memories before every response. Instead, it injects a decision rubric at session start and lets the agent decide when and how to search memories.
You can integrate persistent memory in Claude Code using the official Mem0 MCP server. Here’s a walkthrough.
Prerequisites
Before setting up Mem0 with Claude Code, you need:
A Mem0 Platform account and API key:
Sign up at app.mem0.ai.
Get your API key (starts with
m0-)
Claude Code CLI or the Claude Cowork desktop app is installed.
Your API key is exported in your shell:
The free tier includes 10,000 memories and 1,000 retrieval calls per month.
Installation
Option A: Plugin Marketplace (Recommended)
It installs the full plugin, including the MCP server, lifecycle hooks, and two skills:
mem0: Platform SDK guide that teaches the agent how to use the Mem0 Python SDK in your applicationsmem0-mcp: Agent memory protocol guide covering the MCP v2 filter shape and tool usage patterns
Claude Cowork desktop app: Open the Cowork tab, click Customize in the sidebar, click Browse plugins, and install Mem0.
After installation, restart your Claude Code session. After any future /plugin updaterestart, the MCP server holds a stale connection until the session is restarted.
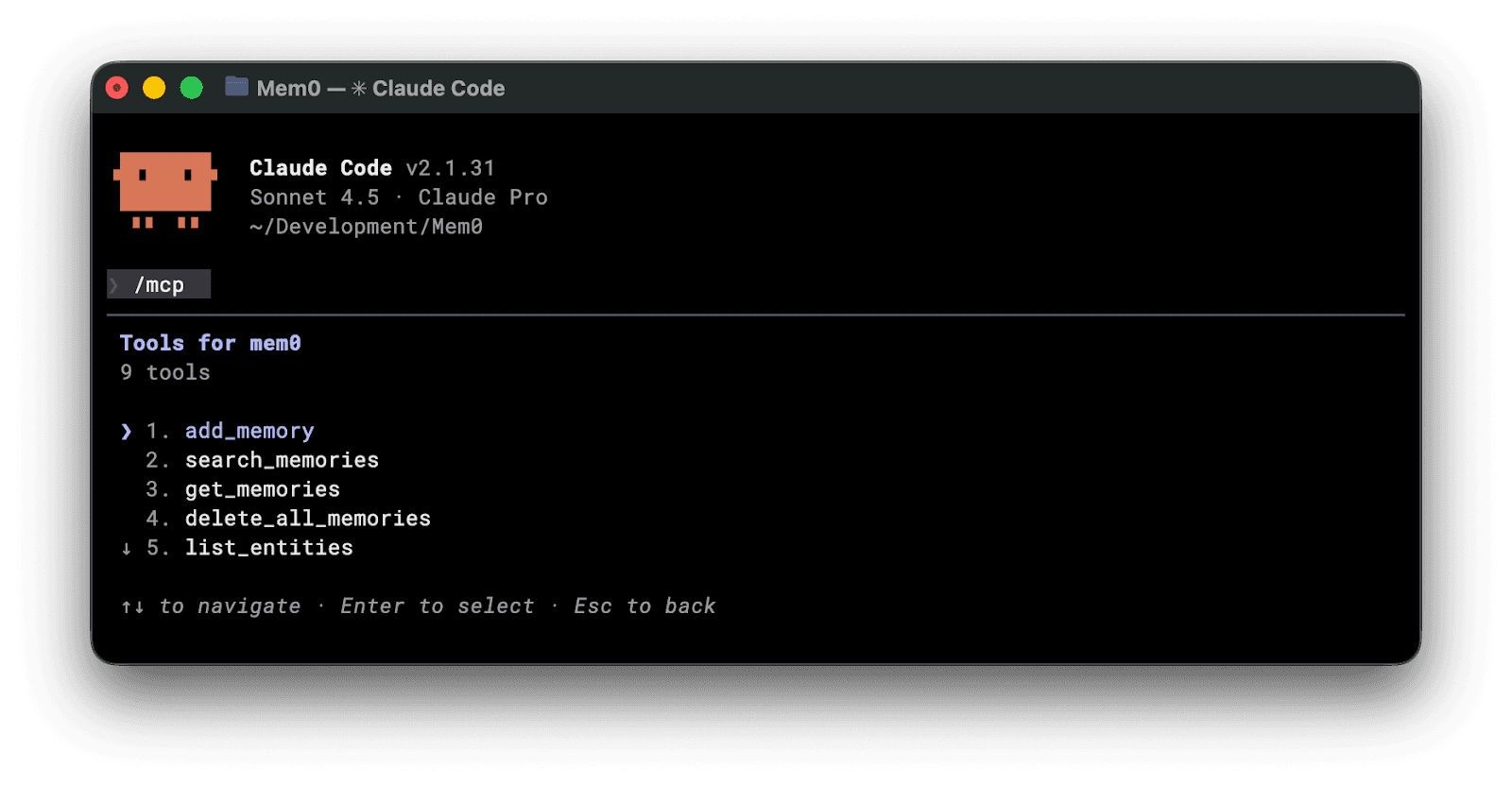
To verify the connection, run /mcp in the CLI or click the plus icon in the desktop app. The mem0 server should appear in the list. You can also ask: "List my mem0 entities". If the tools respond, you are set.
Option B: MCP Only
If you only want the MCP tools without lifecycle hooks or the SDK skill:
Option C: Manual MCP Configuration
If you prefer to configure the MCP server manually without the plugin marketplace, the setup differs slightly between CLI and desktop.
Configure for Claude Code CLI
Add to your .mcp.json in your project root for project-scoped configuration, or to ~/.claude/mcp.json for global configuration across all projects:
Make sure your API key is set in your shell before starting Claude Code:
Run /mcp Inside Claude Code to confirm the mem0 The server is connected.
Configure for Claude Code Desktop (Cowork)
For the Cowork desktop app, edit ~/.claude.json directly and add the mem0 entry under mcpServers:
Once saved, restart the Cowork app and click the plus icon in the session interface to confirm the Mem0 server appears in the list.
For the desktop app, hit the plus icon, and you should see the MCP listed.
Test Mem0 with Claude
Start chatting with Claude code while your Mem0 MCP is connected. It will automatically create new memories that will be inserted as part of the context whenever they’re needed.
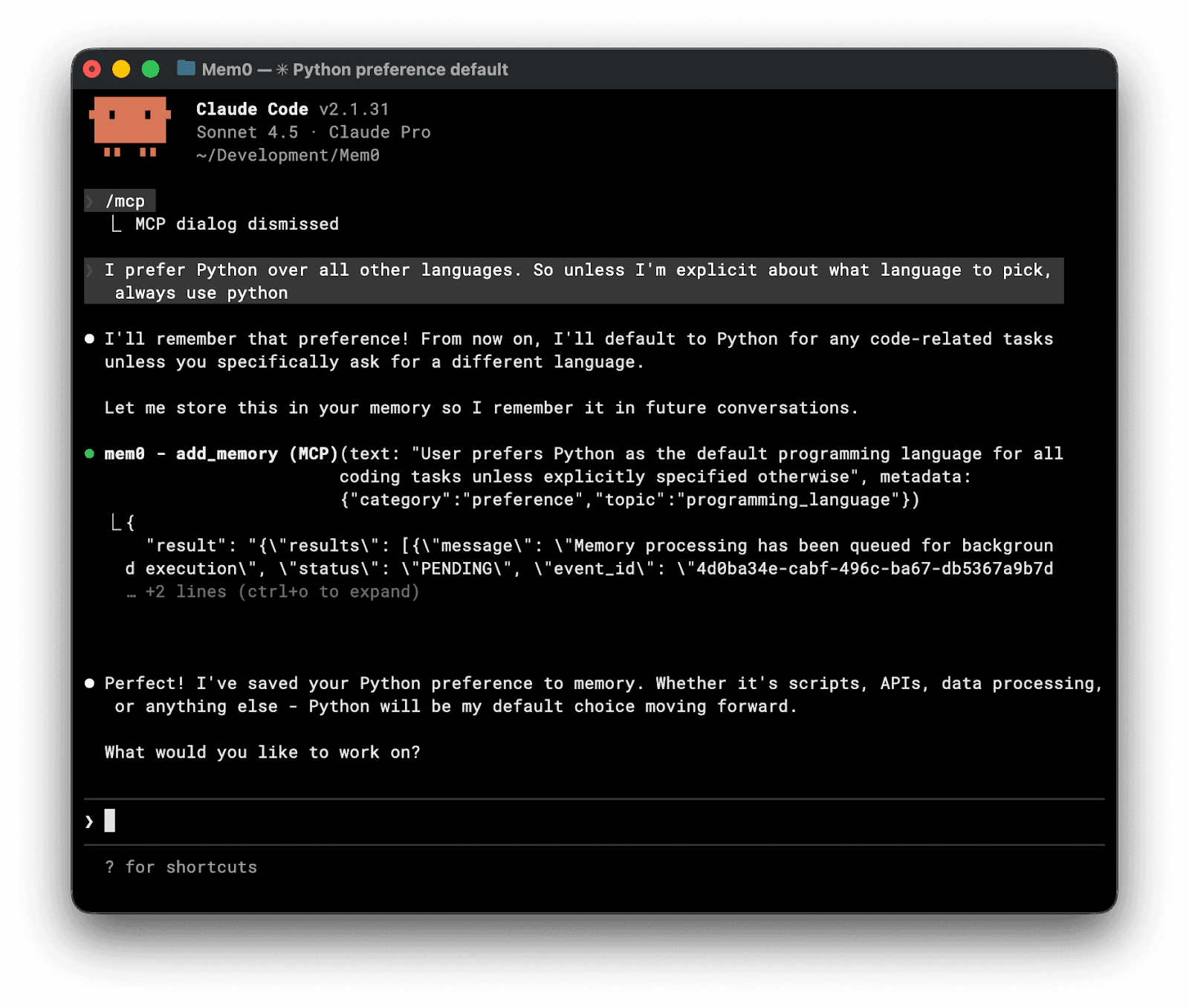
That’s it. Next time you ask Claude to write code, it will fetch your memory and use that information to write code exactly as you prefer.
The best part is, memory turns your Claude Code into an ever-evolving agent, and after a while, it starts to feel so personal, it’s hard to use anything else.
Quick overview
Component | Plugin Install (Option A) | MCP Only (Options B/C) |
|---|---|---|
MCP Server (9 memory tools) | Yes | Yes |
Lifecycle Hooks | Yes | No |
Mem0 SDK Skill | Yes | No |
Zero local dependencies | Yes | Yes |
Mem0 MCP Tools Available After Setup
Once you configure the Mem0 MCP server, here are the tools that are available to Claude
Tool | Description |
|---|---|
| Save text or conversation history for a user/agent |
| Semantic search across memories with filters |
| List memories with filters and pagination |
| Retrieve a specific memory by ID |
| Overwrite a memory's text by ID |
| Delete a single memory by ID |
| Bulk delete all memories in scope |
| Delete a user/agent/app/run entity and all its memories |
| List users/agents/apps/runs stored in Mem0 |
Use natural language to invoke: "Remember that this project uses PostgreSQL with Prisma" or "What do you know about our authentication setup?"
Lifecycle Hooks
When installed via the plugin marketplace, Mem0 hooks into Claude Code's lifecycle at four points:
Session Start: The plugin announces the active
user_idand prompts Claude to callsearch_memoriesto load relevant context from prior sessions. On resumed or post-compaction sessions, it adjusts the search accordingly. Acapture_compact_summary.pyscript reads anyisCompactSummary=truetranscript entry and stores it, taggedmetadata.type=compact_summary. This runs at SessionStart after compaction, since PreCompact fires too early to see the summary.
PreCompact: Before context compression fires, the hook stores a summary of the current session with
infer=False(storing the summary as-is rather than re-extracting facts from it). Session-state and compact-summary memories are automatically tagged withexpiration_date = today + 90 days. Durable memory types like decisions, anti-patterns, and conventions stay unexpired.
Task Completed / Stop: At task completion and session end, the hook reminds Claude to store any new learnings worth preserving across sessions.
PreToolUse: A
block_memory_write.shThe guard prevents accidental writes toMEMORY.mdor.claude/memory/*and redirects those writes toadd_memoryInstead, keep the persistent store as the single source of truth.
Session metadata: Each memory carries the
session_idin its metadata, so post-compaction searches can filter to the current session when needed.
Debugging: Set
MEM0_DEBUG=1to write a hook activity to~/.mem0/hooks.log.
Using the Async SDK in Your Code
If you are building applications that use the Mem0 SDK directly, use AsyncMemoryClient as follows:
AsyncMemoryClient connects to the Mem0 Platform API and provides non-blocking memory operations for high-concurrency applications. In the example above, client.add() stores a new memory tagged to user123, and client.search() retrieves relevant memories using semantic search against that user's store. Memory scoping supports multiple organizational levels: user_id for personal memories, agent_id for bot-specific context, run_id for session isolation, and app_id for application-level defaults.
What Memory Looks Like in Practice
Without Memory: Debugging Authentication
Session 1: You explain that the auth system uses NextAuth with Google and email providers, that tokens expire after 24 hours, and that the refresh logic lives in /lib/auth/refresh.ts. You debug an issue where tokens are not refreshing properly.
Session 2: You re-explain the entire auth setup. Claude suggests checking token expiration, which you already know is 24 hours. You spend the first several minutes re-establishing context before making progress.
With Memory: Debugging Authentication
Session 1: The lifecycle hook prompts Claude to store key findings: Auth uses NextAuth with Google/email. Tokens expire 24h. Refresh logic in /lib/auth/refresh.ts. The refresh fails when the token expires during an active request.
Session 2: When you ask, "Let's continue on the auth logic fix," Claude draws on stored context and asks directly: "Is this related to the token refresh edge case where refresh fails during active requests?"
Cross-Session Project Context
Over time, you can instruct Claude to store repeating patterns as durable memories. Decisions, anti-patterns, and conventions are stored without an expiration date and surface in future sessions when relevant:
This context eliminates the exploration phase, where Claude reads multiple files to understand the project structure before starting work.
Mem0 as the Memory Layer
Mem0 uses a hybrid architecture: vector stores for semantic search, key-value stores for fast retrieval, and optional graph stores for relationship modeling.
For compliance requirements, Mem0 is SOC 2 Type II certified, GDPR compliant, and offers HIPAA compliance on Enterprise plans. Self-hosted installations support 24+ vector databases, including PostgreSQL (pgvector), MongoDB, Pinecone, and Milvus, and 16+ LLM providers, including OpenAI, Anthropic, Ollama, and Groq.
Graph memory (relationship-aware recall across entities) is available on the Pro plan and improves accuracy for multi-hop reasoning tasks.
Frequently Asked Questions
Q: Why does Claude Code need persistent memory?
Claude Code starts every session with zero context. A persistent memory layer eliminates the repetitive context-building phase at the start of each session by storing and retrieving relevant facts automatically.
Q: How do I add memory to Claude Code?
The recommended approach is the plugin marketplace: run /plugin marketplace add mem0ai/mem0 followed by /plugin install mem0@mem0-plugins, then restart your session.
Q: Does this work with both Claude Code CLI and Claude Cowork?
Yes. The plugin marketplace installation works for both. For CLI, verify with /mcp. For Cowork, check the plus icon in the session interface.
Q: Is Mem0 free to use?
The free tier includes 10,000 memories and 1,000 retrieval calls per month, which is sufficient for most individual developers. Graph memory requires the Pro plan.
Q: Can I control what Claude remembers?
Yes. Use natural language ("Forget that I use JavaScript — I've switched to TypeScript") or MCP tools (delete_memory, update_memory) directly. The delete_entities tool removes a user or agent and all their associated memories.
Q: What happens after /plugin update?
Restart your Claude Code session after any plugin update. The MCP server holds a stale connection until the session is restarted, so new tools or hook changes will not take effect until you do.
Q: Is Mem0 the only way to add persistent memory to Claude Code?
No. The MCP ecosystem includes local alternatives such as claude-mem and mempalace that run entirely on your machine. Mem0's advantage is its cloud-hosted server, semantic retrieval, and lifecycle hook integration. If data sovereignty is a concern, the self-hosted Mem0 option uses Qdrant and runs entirely on your infrastructure.
References:
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

