



GPT 5.6 announced the Sol, Terra, and Luna families, which target different balances of intelligence, latency, and cost. Sol is the flagship model with the strongest reasoning and cyber capabilities, Terra targets everyday work at a lower price, and Luna focuses on speed and affordability.
For AI engineers, these models significantly improve long-horizon reasoning and multi-step workflows. They also introduce new controls such as max reasoning effort, ultra mode with subagents, and more predictable prompt caching.
GPT 5.6 is positioned as a core reasoning engine for agents that coordinate tools, maintain plans, and handle complex domains like cybersecurity and biology. In that setting, memory management moves from “nice to have” to a central architectural concern.
What is new in GPT 5.6 for agent builders
GPT 5.6 Sol focuses on agentic workloads. On Terminal‑Bench 2.1, it shows improved performance for command-line workflows that require planning, iteration, and tool orchestration. This type of workload aligns closely with agent frameworks that chain tools and maintain evolving goals.
Two features matter directly for agent design:
Max reasoning effort: GPT 5.6 allows configuration of how much effort the model should invest in reasoning. Higher effort means longer chains of thought, deeper planning, and more corrections. This shifts work from the application layer into the model, but it also increases token consumption and context-length pressure.
Ultra mode with subagents: Ultra mode uses subagents internally to accelerate complex work. From the outside, the API call looks like one model request, but inside it can spawn multiple reasoning threads. This is powerful for multi-step tasks, but it means more intermediate state that never leaves the model and can be lost when the call ends.
Sol also improves performance on long-horizon technical tasks such as genomics (GeneBench v1) and cybersecurity (ExploitBench and ExploitGym). These tasks involve persistent hypotheses, partial results, and evolving artifacts, which makes external memory a requirement for stable behavior across sessions.
How GPT 5.6 works in an agent architecture
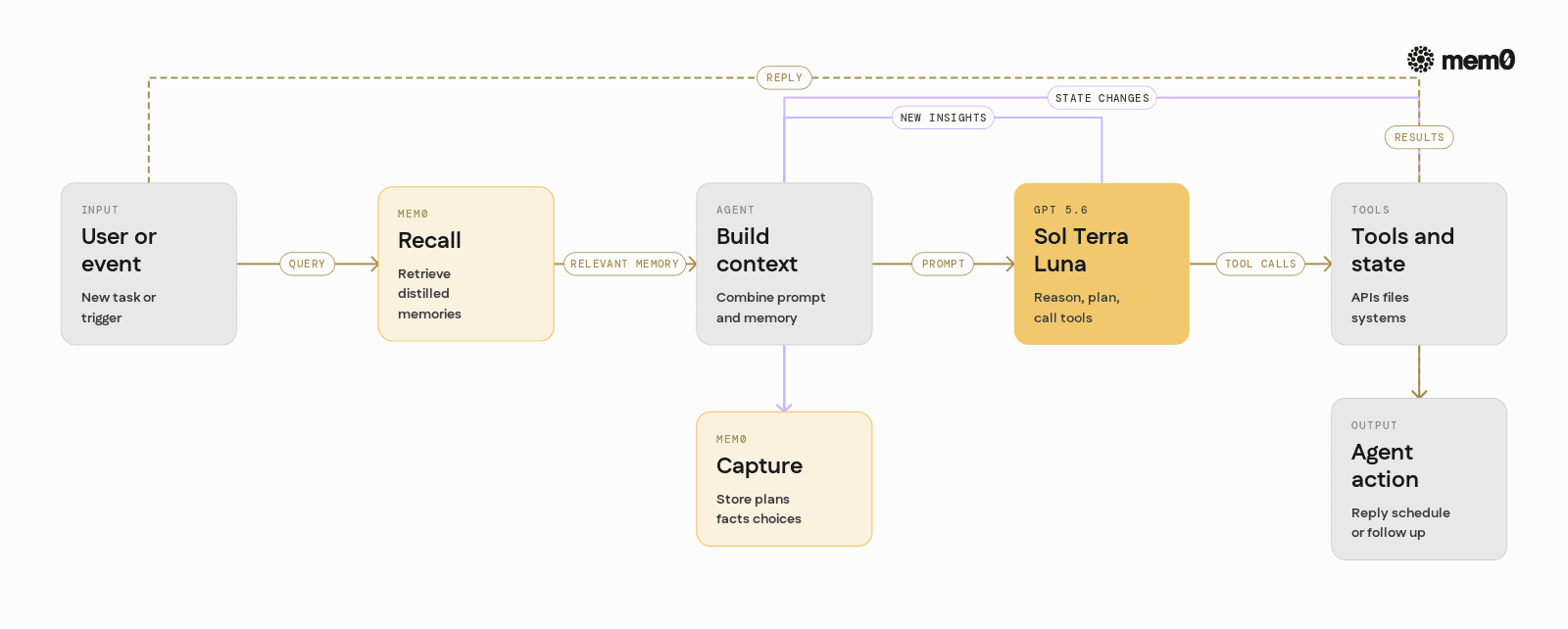
In a typical production agent stack using GPT 5.6, GPT is one component in a larger loop:
Receive user input or an event.
Load relevant past context and state.
Call GPT 5.6 Sol, Terra, or Luna with tools and instructions.
Interpret tool calls and results.
Update external memory and state.
Decide whether to respond, act again, or schedule follow-up work.
GPT 5.6 improves step 3, sometimes dramatically, but leaves steps 2 and 5 mostly unchanged. It still expects the application to provide the right context and to persist the right outputs.
Prompt caching helps with repeated long prompts across calls, but it is transient and scoped to a 30‑minute window. It reduces cost and latency for repeated system and project contexts, but it does not function as a durable memory of a specific user or agent over days or months.
For long-lived agents, the main unsolved problems are:
What to remember from each interaction.
How to retrieve the right slice of memory at the right time.
How to keep memory size manageable as it grows.
How to share memory across different GPT 5.6 tiers (Sol, Terra, Luna) and tools.
These are precisely the gaps that a dedicated memory layer like Mem0 is designed to address.
The core memory problem with GPT 5.6
GPT 5.6 upgrades the reasoning and tool-using parts of an agent, but it does not change some basic model properties:
It is stateless across API calls.
It forgets everything not included in the current prompt.
It cannot autonomously index long-term experience across sessions.
It treats each call as a fresh problem, aside from transient prompt caching.
The new features increase the memory pressure rather than reducing it.
Reasoning effort, and memory
Higher max reasoning effort and ultra mode allow GPT 5.6 to create richer intermediate structures such as subplans, code sketches, hypotheses, and multi-path explorations. If these details are not persisted, they disappear at the end of the call. The agent then needs to “rediscover” them later, which wastes tokens and can lead to inconsistent behavior.
For example, a security agent using Sol to audit a service may iteratively discover potential vulnerabilities, rule out false positives, and derive a prioritized patch plan. If the plan is not written to long-term memory as structured data, the next audit must re-create the same reasoning, and cross-session continuity disappears.
Multi-tier usage and memory
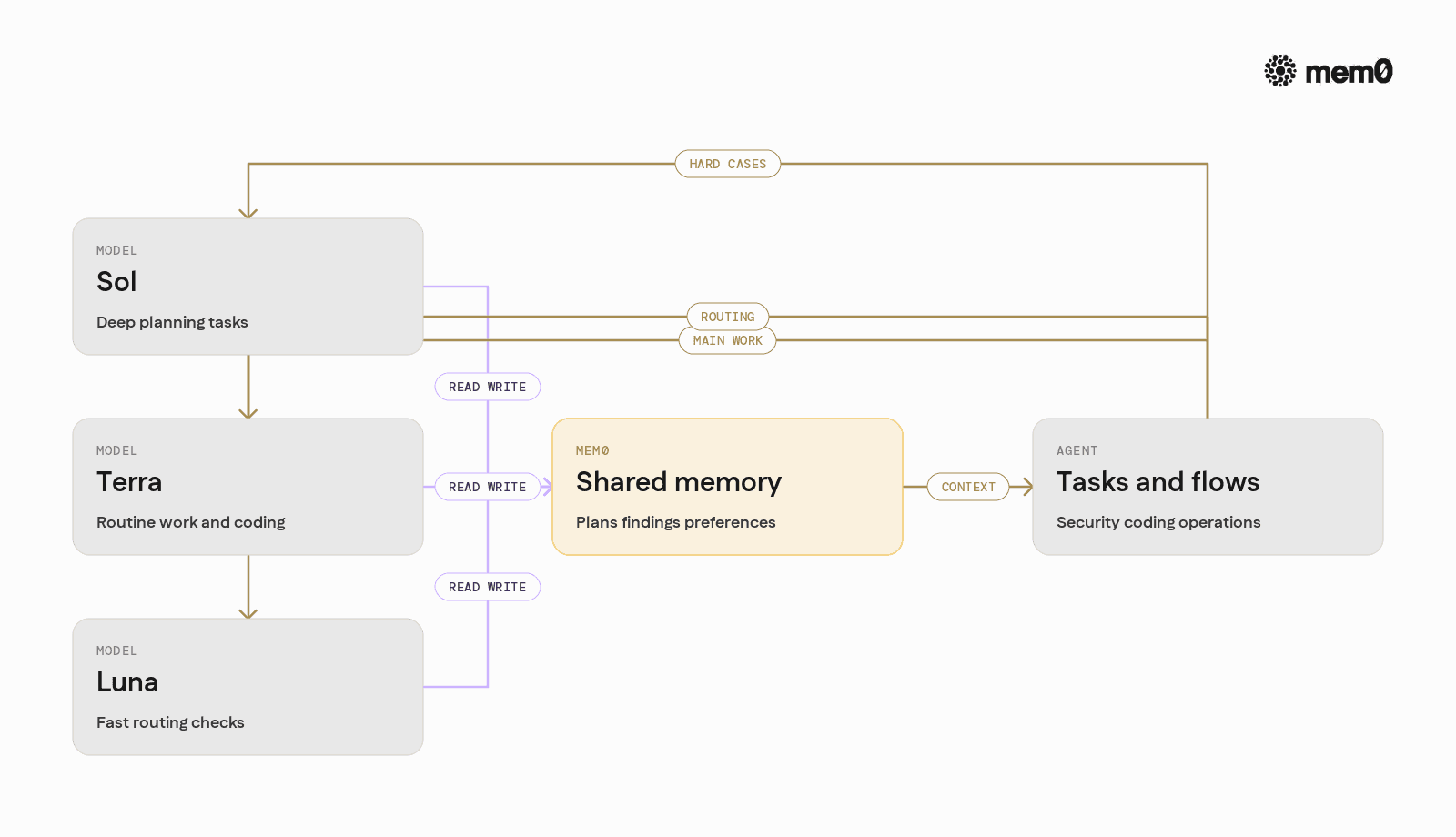
It is common to mix GPT 5.6 tiers:
Sol for complex reasoning or high-risk tasks.
Terra for routine workflows and coding.
Luna for fast classification or routing.
Without a shared memory layer, each tier effectively works in isolation. The Sol call might generate insights that Terra never sees, or Luna might make routing decisions without awareness of what Sol already tried.
The memory problem, in short, is not solved by a more capable model. The more capable the model, the greater the cost of letting its outputs evaporate at the end of each call.
How Mem0 fits with GPT 5.6
Mem0 is an open-source memory layer that sits between agents and models like GPT 5.6. It focuses on three tasks:
Capture: Extract and store relevant information from interactions, outputs, and tool calls. This includes user preferences, task state, discovered facts, plans, and mistakes.
Organize: Index memories by entity, topic, time, and custom tags. This supports scalable retrieval as memory grows, with vector similarity, metadata filters, and per-tenant scoping.
Recall: Retrieve and summarize the most relevant memories for a given query or task, then feed them into GPT 5.6 as structured context rather than raw logs.
With GPT 5.6 specifically, Mem0 provides:
Durable memory across sessions, beyond prompt caching windows.
A shared state for Sol, Terra, and Luna agents to read and write.
A way to persist the results of ultra mode subagents in a structured, queryable form.
Reduced prompt size, because only distilled memory is passed rather than raw history.
The agent uses GPT 5.6 to reason about “what to do now,” and uses Mem0 to maintain “what has happened so far and what matters.”
Integrating GPT 5.6 with Mem0 in Python
The following example shows a minimal production-style loop for a coding assistant that uses GPT 5.6 Sol for deep reasoning and Mem0 for memory. It uses the openai Python client and the Mem0 Python SDK.
Assumptions:
GPT 5.6 Sol is exposed as
gpt-5.6-solin the API.Mem0 is available via
pip install mem0ai.Each user has a unique
user_id.
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
This pattern treats GPT 5.6 as the reasoning engine and Mem0 as the long-term memory. GPT 5.6 is even used to decide which memories to persist, turning the model into a memory curator instead of a static context consumer.
Comparison: GPT 5.6 features vs dedicated memory layer
The relationship between GPT 5.6 features and Mem0 can be summarized as follows:
Concern | GPT 5.6 feature(s) | What it solves | What remains unsolved | Mem0 role |
|---|---|---|---|---|
Long-horizon reasoning | Max reasoning effort, ultra mode | Better planning and internal subagents | No persistence across calls | Persist plans, state, and outcomes |
Cost and latency for long prompts | Prompt caching | Cheaper repeated static prefixes | No durable user-specific memory | Store distilled user and task memories |
Multi-tier agent setups | Sol, Terra, Luna tiers | Different cost / capability tradeoffs | No shared state between tiers | Shared memory accessible from all tiers |
Cyber and biology workflows | Improved domain capabilities | Better domain reasoning | No cross-session knowledge of a system | Maintain per-system findings and hypotheses |
Misuse safeguards | Layered safety stack | Safer responses in high-risk domains | No policy-aware memory of user behavior | Track relevant patterns, support safety logic |
Long-term personalization | None intrinsic | Per-call adaptation only | Cannot remember preferences across sessions | Persist preferences and habits |
GPT 5.6 pushes the frontier on reasoning and safety, Mem0 handles persistent context, personalization, and cross-session state.
Designing memory-aware agents with GPT 5.6
For production agents, integrating GPT 5.6 with Mem0 is less about glue code and more about memory design.
Some practical guidance:
Define memory schemas per agent type: For a coding agent, store codebases, design decisions, and style preferences. For a security agent, store systems, vulnerabilities, and patches. Use Mem0 metadata to distinguish these categories.
Use GPT 5.6 to author memory entries: Instead of dumping full transcripts, ask GPT 5.6 to summarize interactions into short, structured memories. This reduces memory size and improves retrieval quality.
Scope memory to entities, not only users: Many agents interact with multiple entities, such as projects, repositories, or servers. Use Mem0 namespaces or metadata to separate memories for each entity, and then combine them per request.
Keep prompts lean, not exhaustive: Do not feed all retrieved memories into GPT 5.6. Let Mem0 retrieve a larger set, then optionally run a secondary selection step using GPT 5.6 or custom scoring to select the top N that fit in your prompt budget.
Align memory policies with safety policies: In sensitive domains, align what gets remembered with internal policies and regulatory requirements. Mem0 can store metadata flags that describe data classification, retention schedules, and access controls.
Mem0 becomes part of the agent’s “brain architecture,” while GPT 5.6 is the reasoning cortex that works on the current problem with the right subset of historical context.
Limitations
The GPT 5.6 plus Mem0 pattern also has boundaries that engineers should understand.
Memory is only as good as extraction: If the extraction prompts are poorly designed, the system may store irrelevant or redundant memories. This can lead to noise in retrieval and larger storage costs. Human evaluation and iteration on extraction prompts are required.
Concept drift over time: As projects, systems, and preferences change, older memories may become misleading. Agents can start insisting on outdated patterns. Periodic pruning, re-summarization, or time-aware retrieval is necessary to prevent stale context from dominating.
Latency impact of memory retrieval: Each agent's turn now involves additional Mem0 calls. In low-latency environments, this overhead must be managed through batching, caching, or asynchronous memory updates.
Safety and privacy tradeoffs: Long-term memory raises questions about what should be remembered. While GPT 5.6 has strong safeguards for generation, memory layers must also respect privacy, consent, and deletion requests. This is an application-level responsibility.
Non-deterministic reasoning and memory: GPT 5.6 remains non-deterministic, even with low temperature. If memory extraction itself uses GPT 5.6, memories may vary across similar interactions. This can be mitigated with careful prompt design, validation checks, and, where needed, human oversight.
Complexity of multi-agent memory sharing: When multiple agents (for example, Sol for planning, Terra for execution, Luna for classification) share the same memory, concurrency and conflict resolution become non-trivial. Designs must specify which agents can write to which memory segments and how conflicts are handled.
These limitations do not negate the benefits of combining GPT 5.6 with Mem0, but they shape the engineering work required for production robustness.
Frequently Asked Questions
Q. What is GPT 5.6, and how is it different from GPT 5.5 for agents?
GPT 5.6 is a next-generation model family with Sol, Terra, and Luna tiers, focused on stronger reasoning and improved cyber and biology capabilities. For agents, the key differences are max reasoning effort, ultra mode with subagents, and improved performance on long-horizon tool-driven tasks.
Q. Why is an external memory layer needed if GPT 5.6 has better reasoning and prompt caching?
Prompt caching only optimizes repeated static context within a short window; it does not remember user-specific information across days or sessions. An external memory layer like Mem0 provides durable, queryable memory for users, projects, and systems that persists beyond any single API call.
Q.How does Mem0 integrate with GPT 5.6 in a typical production setup?
Mem0 sits alongside GPT 5.6 in the agent loop, retrieving relevant memories before each model call and persisting new memories after each response. GPT 5.6 focuses on reasoning about the current task, while Mem0 manages what should be remembered and how it should be structured over time.
Q. When should GPT 5.6 Sol be used versus Terra or Luna with Mem0?
Sol is best for complex planning, deep debugging, and high-stakes reasoning where correctness matters more than cost. Terra fits everyday workflows and bulk coding tasks, while Luna suits routing, classification, and fast checks. All three can read and write to Mem0 so that insights discovered at any tier remain available to the others.
Q. How does Mem0 handle memory growth as GPT 5.6 agents run for months?
Mem0 indexes memories with vectors and metadata, and it supports filtered retrieval by user, entity, time, and tags. Applications can periodically prune, merge, or re-summarize old memories using GPT 5.6 to keep the memory base concise while preserving important information.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

