



Gemma 4 represents a new generation of open models that run efficiently on local hardware and edge devices. For AI engineers building production agents, it offers a compelling mix of quality, controllability, and deployability across on-prem and hybrid stacks.
In practice, most Gemma 4 deployments fall into one of three patterns. First, as a primary reasoning model for agent loops and tool orchestration. Second, as a local inference engine that pairs with a cloud model for sensitive or latency-critical tasks. Third, as a fully offline assistant for privacy-first environments, such as internal enterprise tools.
All three share one core constraint. Gemma 4, like every transformer-based model, has a finite context window. Even with long context variants, agents forget cross-session details, user preferences, and multi-step workflows. This is where an external memory layer becomes essential rather than optional.
How memory works in Gemma 4?
Gemma 4 uses the standard transformer attention mechanism with positional encodings and a bounded context length. The model only attends to tokens within that window. Anything older must be either summarized, truncated, or omitted entirely from the prompt.
There is no internal notion of persistent memory across calls. Each invocation is stateless from the model’s perspective. Any sense of continuity comes from the application layer, which decides what history to re-inject into prompts and how to compress older context when the window fills up.
Some implementations add system prompts or instruction templates that carry global behavior rules. That still does not qualify as memory in the sense of personalized, per-user, long-term state. The model treats each call as a fresh sequence of tokens, without inherent recall of previous interactions.
Why local Gemma 4 models expose the memory gap
When Gemma 4 runs locally, many of the traditional tricks used in cloud deployments become less practical or less desirable. Engineers often avoid constantly shipping large histories over the network, especially in edge or partially offline settings. Local models shift the cost and risk profile.
Local deployments also tend to serve more specialized use cases. Examples include internal knowledge assistants that must remember project-level facts, personal productivity agents that track habits and tasks, or support agents that learn from previous tickets. In all these cases, memory is not just nice to have, it is central to the product value.
Without a dedicated memory layer, teams often end up with ad hoc solutions. They concatenate chat logs into prompts until the context breaks. They manually store JSON blobs tied to users, then handcraft retrieval logic. These approaches quickly become brittle, hard to maintain, and inconsistent across agents.
Core memory requirements for Gemma 4 agents
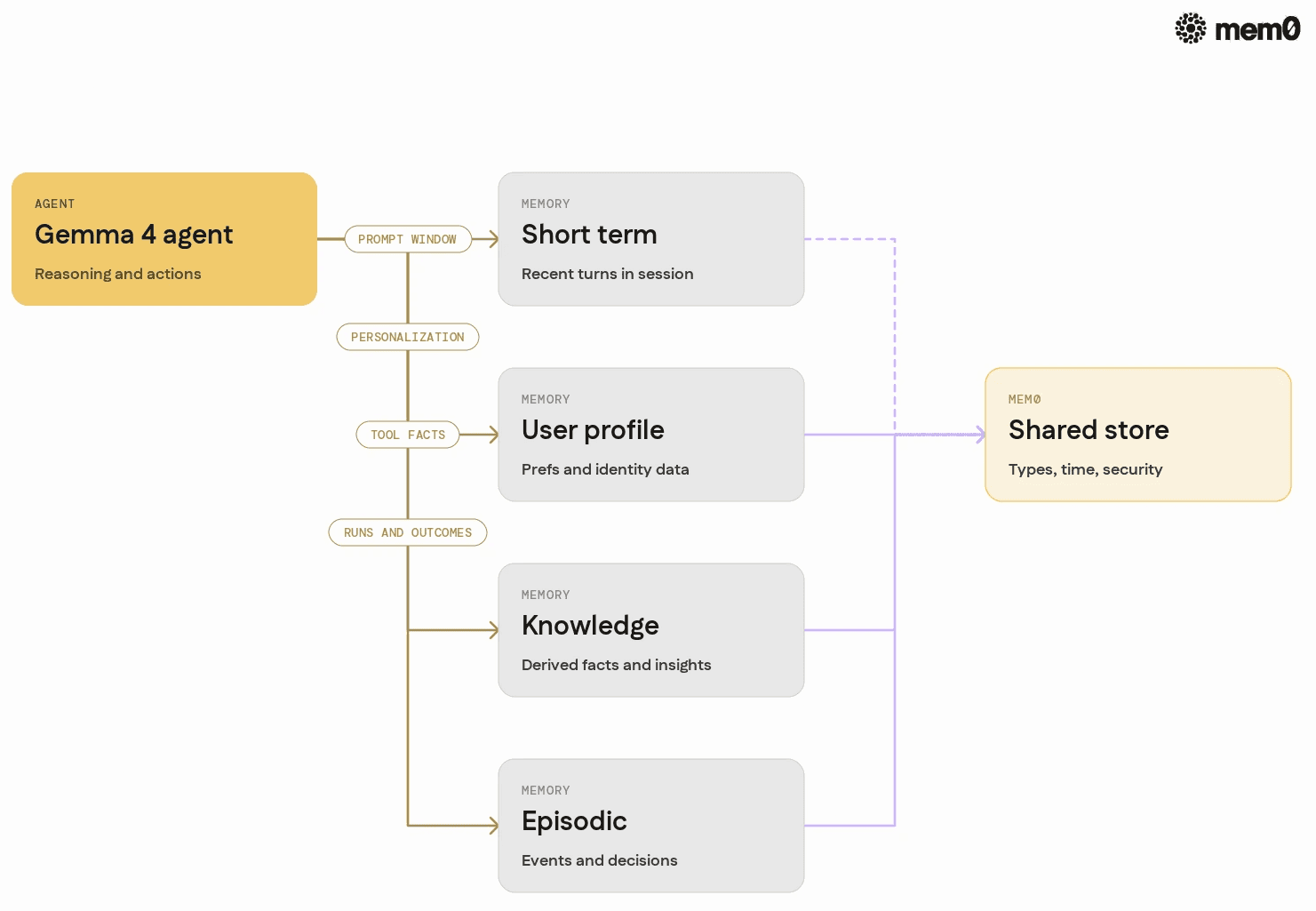
Production agents using Gemma 4 typically need four categories of memory.
First, short-term conversational memory, which captures recent turns in a session to keep dialogue coherent. This lives naturally in the prompt, but needs pruning and summarization over time.
Second, long-term user memory, such as preferences, bio details, constraints, and recurring goals. This needs to outlive individual sessions and be scoped per identity, not per thread.
Third, knowledge memory, which stores derived facts that the agent has inferred or imported from tools, such as project status, document insights, or workflow metadata. These are candidates for retrieval during reasoning.
Fourth, episodic memory, which records key events, successes, failures, and decisions made by the agent. This type of memory lets the system improve behavior across repeated runs and explain past choices.
Implementing all four categories in a consistent manner requires a system that understands entities, time, relevance, and security boundaries. Gemma 4 alone does not provide this structure. It must be built around the model.
What Mem0 provides as a memory layer
Mem0 is designed as an intelligent memory layer that sits between the application logic and models like Gemma 4. It handles storage, retrieval, and transformation of memories in a way that is model agnostic and works with both local and remote backends.
At a high level, Mem0 ingests interactions, extracts structured memories, and stores them with metadata such as user, type, and timestamp. Later, when an agent needs context, Mem0 retrieves and ranks relevant memories, then provides them as formatted snippets that can be injected into Gemma 4 prompts.
This separation gives engineers a clean boundary. Gemma 4 focuses on reasoning and text generation. Mem0 handles continuity, user personalization, and multi-session state. The result is simpler agent code and a consistent memory behavior across different environments.
Architecture pattern for Gemma 4 with Mem0

The typical architecture combines three elements. First, a Gemma 4 inference server, often using frameworks like vLLM or a simple HTTP wrapper over a local runtime. Second, Mem0 as a memory service, which may run as a separate process or as part of the backend application. Third, an agent orchestration loop that calls both.
The workflow can be summarized as:
Receive user input and identify the actor (user ID or session ID).
Query Mem0 for relevant memories given the user and the current message.
Construct a prompt that includes system instructions, retrieved memories, and the current conversation slice.
Call Gemma 4 for a response.
Send the response to the user and update Mem0 with new memories derived from the exchange.
This pattern works equally well when Gemma 4 runs fully local on a laptop, in a Kubernetes cluster, or on a GPU server behind an internal API. Mem0 provides a constant memory API while the underlying model can be swapped or upgraded independently.
Python example Gemma 4 and Mem0 integration
The following example demonstrates a minimal yet realistic integration where a local Gemma 4 model is used for reasoning, and Mem0 handles memory storage and retrieval.
This script shows how Mem0 stores both user and assistant messages and uses semantic search to retrieve relevant context for future turns. In a production agent, engineers would define more specific memory types, add redaction logic, and integrate with existing auth systems.
Comparison of Gemma 4 with and without Mem0

A memory layer becomes especially important as the complexity of tasks and the length of interaction grow. The table below summarizes typical behavior differences between a plain Gemma 4 deployment and one augmented with Mem0.
Aspect | Gemma 4 without Mem0 | Gemma 4 with Mem0 |
|---|---|---|
Cross-session personalization | Limited, manual prompt hacks | Structured, per-user memory with automatic recall |
Context window management | Manual truncation and summarization | External store with retrieval and summarization |
Long-term project tracking | Difficult, easy to forget older decisions | Persistent episodic memory, queryable by the agent |
Latency for large histories | Higher, longer prompts for every call | Lower, only relevant memories injected |
Multi-agent consistency | Each agent manages its own ad hoc state | Shared memory semantics across agents |
Governance and audit | Chat logs scattered across systems | Centralized memory with metadata and policies |
The main benefit is not only that the agent remembers more, but that memory becomes a first-class concept. Product logic can refer to memory types, tags, and time ranges instead of raw transcripts. This helps maintainers evolve behavior without rewriting prompt templates for every change.
Design considerations specific to local models
Local Gemma 4 deployments introduce unique constraints that affect memory design. Storage may live on the same machine, or on a local network segment, and often must respect stricter privacy policies. Some organizations prohibit sending raw user content off the device.
Mem0 supports both hosted and self-hosted modes, so engineers can run the memory layer within their own infrastructure. For local agents, a typical pattern is to co-locate Mem0 with the model server and share a fast internal network. This avoids WAN latency and external dependencies.
Another consideration is limited hardware on edge devices. Agents running on laptops or embedded systems may need lightweight memories or partial synchronization with a central store. In such cases, Mem0 can act as the core memory service in the backend, and the local Gemma 4 instance becomes a stateless compute node that pulls just enough context for each interaction.
Limitations of this pattern
Exploring how Gemma 4 and Mem0 fit together reveals several limitations that belong to the pattern itself rather than to any specific tool.
First, retrieval augmented memory depends heavily on good retrieval. If embeddings or indexing strategies are poor, the agent may recall irrelevant or stale memories. Engineers must monitor and tune retrieval quality, and add filters for time windows and types.
Second, memory growth must be managed. Unlimited storage of every token will eventually degrade performance and complicate governance. The pattern needs background jobs for pruning, summarizing, and archiving old memories based on business rules.
Third, latency budgets can become tight when combining inference plus memory operations. For some user experiences, the added round-trip to memory may not be acceptable without caching and batching strategies. Local models help reduce inference time, but memory retrieval still requires careful design.
Finally, not every task benefits from long-term memory. Stateless workflows such as single-shot document summarization or one-off code generation may not justify the added complexity.
Frequently Asked Questions
Q. How does Gemma 4 handle memory by default?
Gemma 4 maintains context only within its configured token window. It attends to recent tokens but discards anything outside that range. There is no built-in mechanism for cross-session or long-term memory.
Q. Why is an external memory layer needed with local models?
Local models reduce latency and improve privacy, but they do not change the fundamental stateless nature of transformer inference. An external memory layer is needed to persist facts, preferences, and events across calls and sessions, especially when agents run for days or weeks in production.
Q. When should Mem0 be added to a Gemma 4 deployment?
Mem0 brings the most value once an agent needs personalization, multi-session continuity, or complex workflows that span multiple tools and steps. Early prototypes might run without memory, but as soon as users expect the system to remember preferences or past conversations, Mem0 becomes a natural addition.
Q. How does Mem0 decide which memories to return to Gemma 4?
Mem0 uses semantic search and metadata filters to locate memories that are relevant to the current query and user. Engineers can configure memory types, tags, and time filters so that the retrieved context matches the agent’s needs without overwhelming the prompt.
Q. Can Mem0 be self-hosted alongside a local Gemma 4 model?
Yes. Mem0 is open source and can be deployed in the same environment as a local Gemma 4 server, such as an on-premises cluster or a single GPU box. This arrangement keeps data within the organization’s boundary and lets teams manage security and performance end-to-end.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

