



Quick Takeaways
The previous post covered the architecture problem: therapy AI systems capture session notes well, but after enough sessions, clinically useful details get buried.
At referral, those details get compressed into a short letter.
Mem0 helps to extract structured facts to be stored and makes them independently queryable.
While the referral letter preserves some context, the memory store preserves all as structured facts.
Mem0's benchmarks on this kind of cross-session retrieval: 91% lower p95 latency (1.44s vs 17.12s), 90% fewer tokens per query (~7,000 vs 25,000+), and 26% higher accuracy than full-context replay on the LOCOMO benchmark.
👉You'll need a free Mem0 API key to run the demo. Get one at app.mem0.ai (free tier, no credit card). The code below uses real
add()andsearch()calls.
If your therapy AI assistant has been running for more than 10 sessions, context burial is already happening. The trigger identified in session 3 is already unreachable in session 15. The coping strategy abandoned in session 7 is missing from the active context. The question is not whether your system has this problem. It is how much clinical context your assistant has already lost access to, because the referral letter contains four sentences: the diagnosis, one medication tried, current techniques, and the reason for the referral.
That is not wrong, but it is too compressed. That's why we require a structured memory that can store all the important information.
Practical Demo: Build a Therapy AI Assistant
In this tutorial, we'll see how Mem0 helps us solve this problem. Here is a quick look at what we'll build:
⭐️You can access the complete code repository on GitHub
The app has two tabs: Therapy Sessions and Handoff. The top row gives the whole system state at a glance:
Metric | Value |
|---|---|
Structured facts stored | 14 |
Source | 3 therapy sessions, 1 provider |
Referral letter | 4 sentences |
Retrieval speed | <2 seconds, ~7,000 tokens per query |
Note: The referral letter is small because it is compressed. The memory store is small because it is structured. Here, both are compact, but only one is queryable.
Step 1: Build memory across therapy sessions
The demo has three pre-filled therapy transcripts, but feel free to test it with your own transcripts.
Session 3 captures the first important facts like panic attacks correlate with Sunday evenings, sertraline 50mg was stopped in week 3 because of GI side effects, CBT grounding was introduced, and the patient has a penicillin allergy.
When the user clicks Save Session 3, the app runs:
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
The important architectural move is not saving the transcript. It is extracting facts that can be retrieved later. Mem0's extraction model automatically identifies structured facts from the session: diagnoses, medications, coping strategies, triggers, treatment goals. You don't have to write extraction rules.
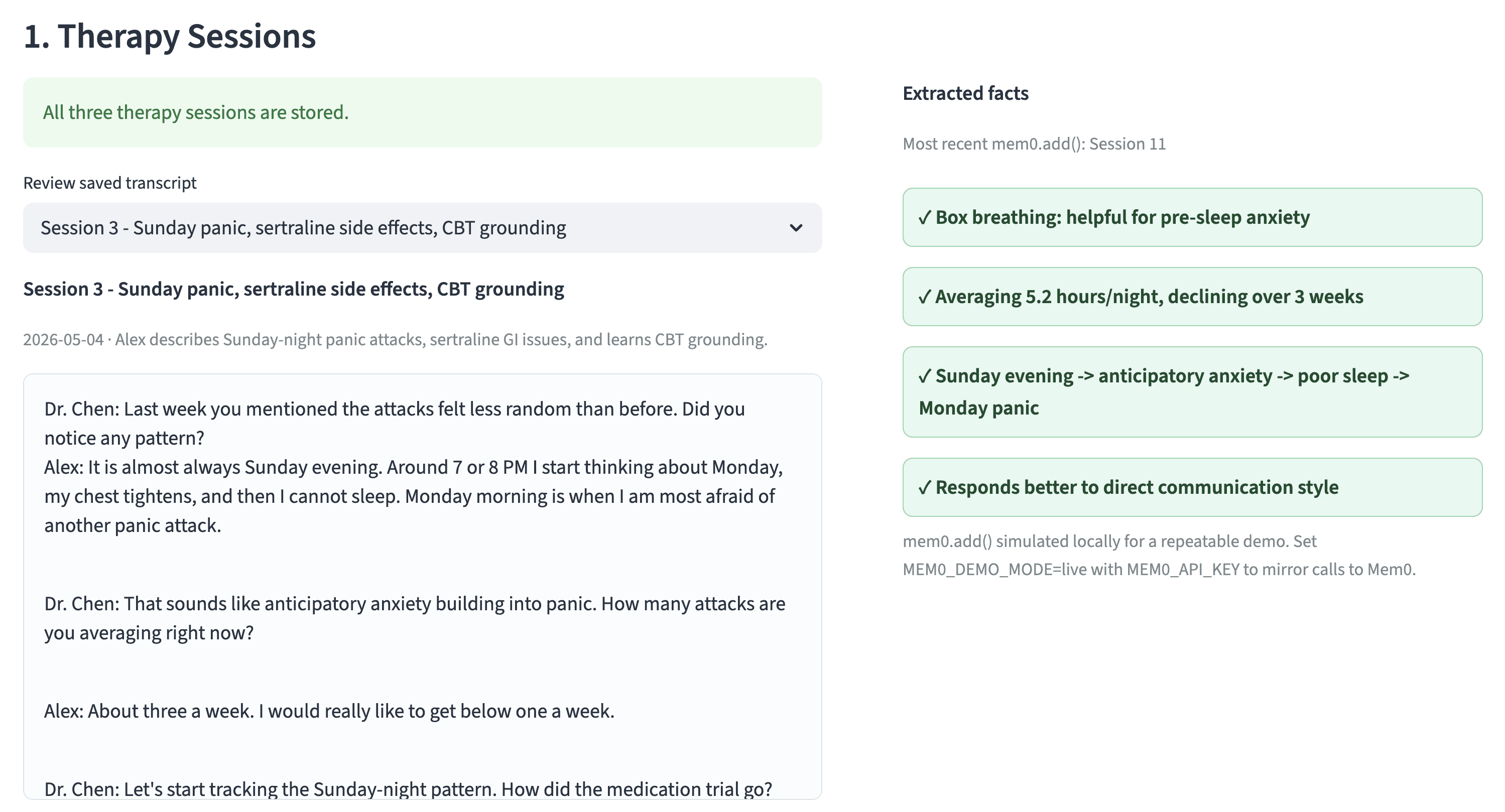
Session 7 adds that progressive muscle relaxation was tried and abandoned, grounding is effective for mild episodes but not severe ones, and journaling was introduced.
Session 11 adds declining sleep (5.2h average), box breathing for pre-sleep anxiety, and the referral decision.
By the end of Session 11, the memory store contains fourteen facts across diagnosis, medications, coping strategies, treatment goals, triggers, sleep, preferences, and allergies. Each fact is independently retrievable.
The therapist does not need to remember where each detail appeared. Just a single search() call returns the relevant subset.
👉After saving all three sessions, check your Mem0 dashboard to see the extracted facts. Each one is stored as a structured memory with the patient ID, provider role, and session metadata attached.
Step 2: The compression gap
The Handoff tab generates a referral letter, and next to the letter, the UI flags what was lost:
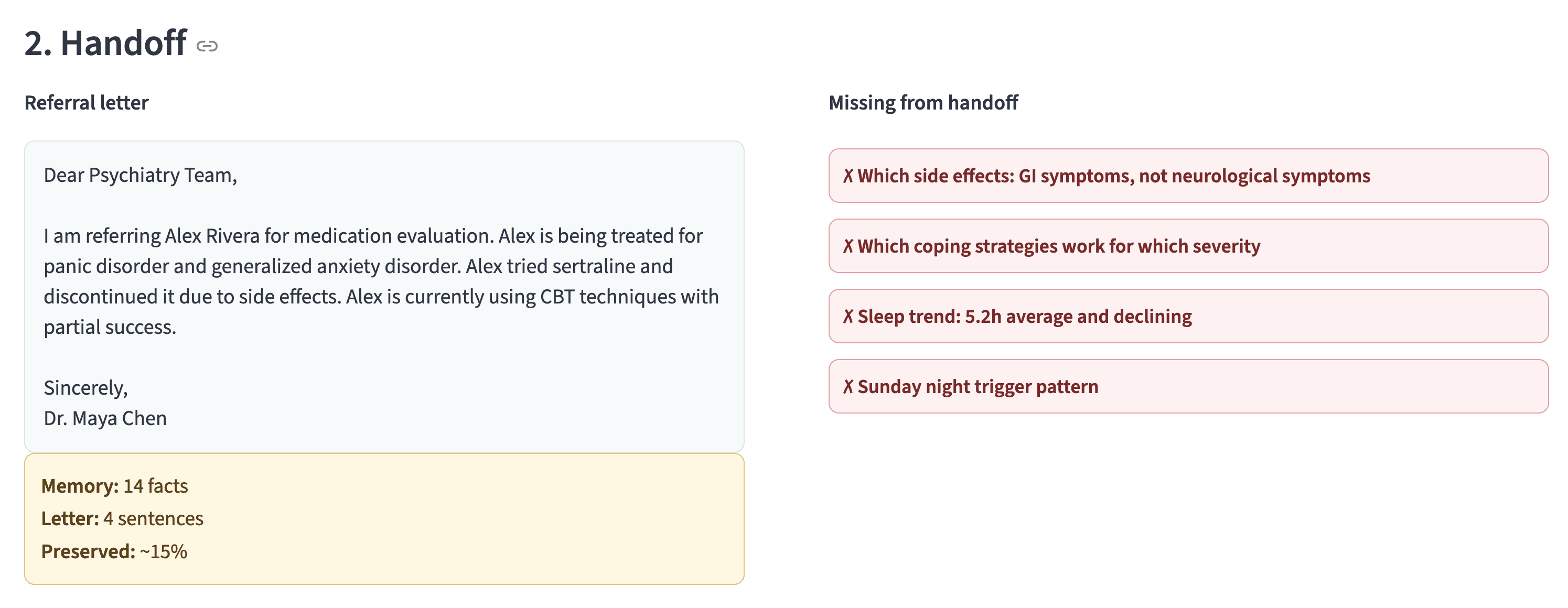
The referral letter is not useless. It is useful as a human-readable summary. But it should not be the primary source of context for an AI intake assistant. The primary context source should be queryable memory.
Step 3: Run the intake comparison
The demo uses the same patient message in both panels:
"Hi, I'm here for the medication evaluation."
Without Mem0
The assistant only has the referral letter. Its response:
"Welcome Alex. Can you tell me about your mental health history? What medications have you tried before?"
The patient repeats the context. Fifteen minutes of a thirty-minute appointment spent on information the therapist's system already captured.
With Mem0
Before responding, the assistant retrieves relevant patient memories:
The retrieved memories include:
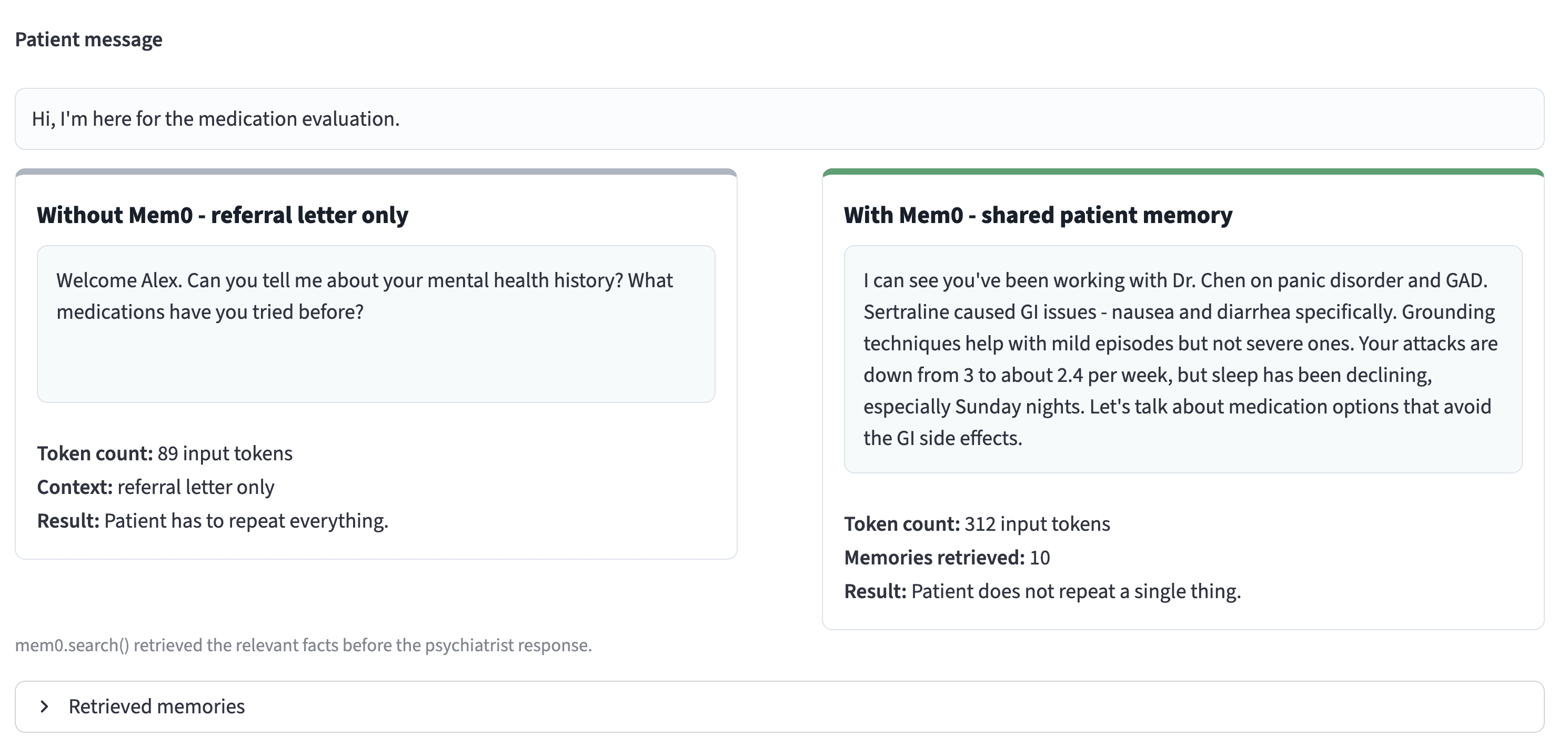
The numbers behind the difference: Mem0 retrieval used approximately 7,000 tokens and returned in under 2 seconds. Full-context replay (loading all three session transcripts into the prompt) would have consumed 25,000+ tokens with 91% higher latency. The accuracy improvement is measurable: 26% higher on the LOCOMO benchmark compared to full-context approaches, because selective retrieval surfaces the specific facts relevant to the query rather than hoping the model extracts them from a wall of text.
👉This is the pattern you'd ship in production. Get your API key, swap in your own session transcripts, and run the same
add()/search()flow. The extraction is automatic.
Run the demo yourself:
You can access the complete code repository on GitHub or simply follow these steps:
Set your environment variables:
Then run:
Click through the two tabs. Save the three sessions, inspect the referral gap, and run the intake comparison.
The repo is small by design:
Fork the repo on GitHub and swap in your own session transcripts. The
mem0.add()call handles extraction automatically. Themem0.search()call handles retrieval.
Production architecture
In production, the pattern is the same.
After every therapy session:
Before psychiatry intake:
Then inject the retrieved facts into the intake assistant's system prompt.
The referral letter can still exist. Clinicians need readable summaries. But the AI assistant should not depend on that letter as its only memory source.
For teams that need patient data to stay inside their infrastructure: Mem0 supports self-hosted Docker deployment, private Kubernetes, and fully air-gapped environments. Same API, same code, different data residency. SOC 2 Type I certified, HIPAA compliant, BYOK encryption.
Note:
This demo uses fictional data.
For real mental health workflows, memory architecture must support extracted facts instead of raw psychotherapy transcripts (45 CFR 164.501 restricts psychotherapy notes from the general medical record), consent-gated retrieval for substance use records (42 CFR Part 2), audit logging for every add() and search() call (required by the 2025 HIPAA Security Rule amendments for all AI systems touching PHI), minimum necessary retrieval so the intake assistant gets medication history and treatment goals rather than entire therapy transcripts, and scoped access by patient, provider role, session, and organization.
Developer note:
The difference between the two intake responses is not a prompt-engineering trick. It is the memory layer. The referral-only assistant has 4 sentences of manually compressed context while the Mem0-backed assistant has 10 retrieved facts selected from 14 structured memories.
The application does not stuff all historical notes into the prompt. It asks a narrow question and injects only the relevant facts. This matters for three reasons:
Lower tokens: Selective retrieval uses under 7,000 tokens per query instead of the 25,000+ required for full-context replay. Over a day of intakes, that is a 90% reduction in token cost.
Better precision: Medication side effects, trigger patterns, and treatment goals survive the handoff with exact specificity. "GI side effects: nausea and diarrhea" is a different clinical signal than "side effects."
Better patient experience: Patients do not repeat longitudinal history at every provider transition. The system remembers the moment the patient walks in.
Why this is different from summarization?
Summaries compress while memory retrieves. Those are different operations.
A summary asks: What is the shortest version of everything that happened?
Memory asks: What facts are relevant to this query right now?
For a referral letter, the shortest useful version may be:
Tried sertraline, discontinued due to side effects.
For a psychiatry intake query about medication options, the relevant memory is:
Sertraline 50mg was stopped in week 3 because of GI side effects: nausea and diarrhea.
That extra specificity changes the next clinical question. The psychiatrist who knows the side effects were GI-specific will avoid other medications with GI profiles and consider drug classes that work differently. The psychiatrist who only knows "side effects" may try another SSRI and hit the same problem.
Extraction over summarization is what makes facts independently queryable rather than buried in prose that loses precision with each compression cycle.
Frequently Asked Questions
Q. Can I run this demo with my own therapy transcripts?
Yes. Replace the pre-filled transcripts in simulated_sessions.py with your own session data. The mem0.add() call handles extraction automatically. You don't write extraction rules or label training data. Mem0's extraction model identifies diagnoses, medications, coping strategies, treatment goals, and other clinically relevant facts from the transcript.
Q. How is this different from just sharing EHR notes with the psychiatrist?
EHR notes are unstructured text written for clinicians, not for AI context injection. A 2-page progress note that mentions sertraline in paragraph four is not queryable. "Sertraline 50mg, discontinued week 3, GI side effects (nausea, diarrhea)" stored in Mem0 is a retrievable fact. The AI assistant asks "what medications were tried" and gets a direct answer across all sessions and providers.
Q. Does memory persist across different providers?
Yes. Any fact stored at user_id scope is available to any provider's assistant querying that scope. The therapist writes to user_id=patient_mrn, the psychiatrist reads from the same user_id. No manual export, no lossy referral letter as the only context source.
Q. Can Mem0 be deployed on-premises for healthcare organizations?
Yes. Mem0 supports managed cloud, self-hosted Docker, private Kubernetes, and fully air-gapped deployment. All models use the same API. BYOK encryption ensures patient data is encrypted with keys the organization controls. Full deployment guide.
Q. What happens to memory if the patient switches health systems?
Memory is scoped by user_id (patient MRN or internal UUID) and app_id (health system). If the patient moves to a new health system, a data export and import flow would be needed, subject to the patient's consent and the relevant data-sharing agreements. Mem0's API supports bulk export at the user_id scope.
Conclusion
The previous post made the architecture case: clinical AI needs persistent memory because session notes get buried, referral letters are lossy, and prose notes are hard to query.
This one makes the case visual with a demo.
The user sees fourteen facts accumulated across therapy sessions. Then they see those facts compressed into a four-sentence referral letter. Then they see the intake assistant behave differently when it can retrieve the original structured memories: 91% lower latency, 90% fewer tokens, 26% higher accuracy. The patient does not have to repeat themselves because the provider already starts with context. The AI assistant retrieves what matters.
Ready to add persistent memory to your clinical AI assistant?
Get a free API key at app.mem0.ai (no credit card, free tier includes add + search)
Self-host with Docker for on-prem deployments
Read the full architecture post for HIPAA, 42 CFR Part 2, and on-prem patterns
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

