



Quick Takeaways
AI therapy assistants capture excellent session notes, but the problem is not capture. It is retrieval. After 20+ sessions, the trigger identified in session 3 is buried under months of newer context. The assistant in session 25 cannot find it, not because it was never recorded, but because there is no way to query for it.
At referral, the problem compounds. The therapist sends a referral letter: a one-page lossy summary of months of structured notes. The specific medication reaction, the exact coping strategy that works for mild episodes but not severe ones, the sleep trend, all compressed into a few sentences or lost entirely.
The fix is a persistent memory layer that extracts structured facts after every session and makes them independently retrievable by query i.e, structured extraction with selective retrieval.
Mental health data carries stricter protections than general PHI. Psychotherapy notes have their own HIPAA carve-out, so the memory layer must support selective retrieval, consent-gated access, and on-prem deployment for organizations where patient data cannot leave the system.
👉Get a free API key at app.mem0.ai to follow along (free tier, no credit card, includes all the
add()andsearch()calls shown below).
How clinical context degrades in therapy AI
AI therapy assistants are excellent at capture. The problem is what happens to that captured context over time. It degrades in three specific ways:
facts get buried under months of accumulating session notes,
referral summaries compress months of structured data into a few sentences, and
notes stored as prose become impossible to query when you need a specific answer.
Each one is a different architectural failure. Each one has a specific fix.
Problem 1: Context burial within a single provider

Fig: Problem 1 - Context burial leads to loss of critical information
A therapist sees a patient weekly for 6 months. By session 20, the AI assistant's context window is full. The trigger pattern identified in session 3 is buried under 17 sessions of newer notes. The content that got abandoned in session 7 is no longer in the active context. The specific reason may have been compressed or dropped entirely.
This is the same context compression problem that affects every long-running AI system. In therapy, it is worse because treatment is longitudinal by design. A 6-month therapy course is not an edge case. It is the standard.
What this looks like in practice
The therapist's AI assistant in session 24 suggests a coping strategy the patient already tried and abandoned in session 7. The patient says, "We already tried that; it didn't work." The assistant has no record of it in its active context, and the patient loses confidence in the system.
How Mem0 fixes this
Extract structured facts after every session, not at some future compression trigger. By the time context burial would be a problem, the facts are already in Mem0 and independently retrievable.
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
Mem0's extraction model automatically identifies facts worth keeping: diagnoses, medications discussed, coping strategies tried, treatment goals, emotional state, clinical decisions.
Now in session 24, the therapist's assistant queries what happened months ago:
The assistant doesn't scroll through 24 sessions of notes. It queries "what coping strategies were tried" and gets a structured answer spanning the full treatment history. Session 3's insights are as accessible as session 23's.
The numbers: On the LOCOMO benchmark, Mem0's retrieval uses under 7,000 tokens per query compared to 25,000+ for full-context approaches. That is a 3.5x reduction in token cost per retrieval. For a therapy assistant running 24 sessions, each averaging 4-5 retrieval calls, the cumulative savings are significant. But the real value is not cost. It is that the retrieval in session 24 returns facts from session 3 with the same precision as if they were extracted yesterday.
⭐️This query takes under 2 seconds on the free tier. Get your API key and test it against your own session transcripts.
Problem 2: Lossy compression
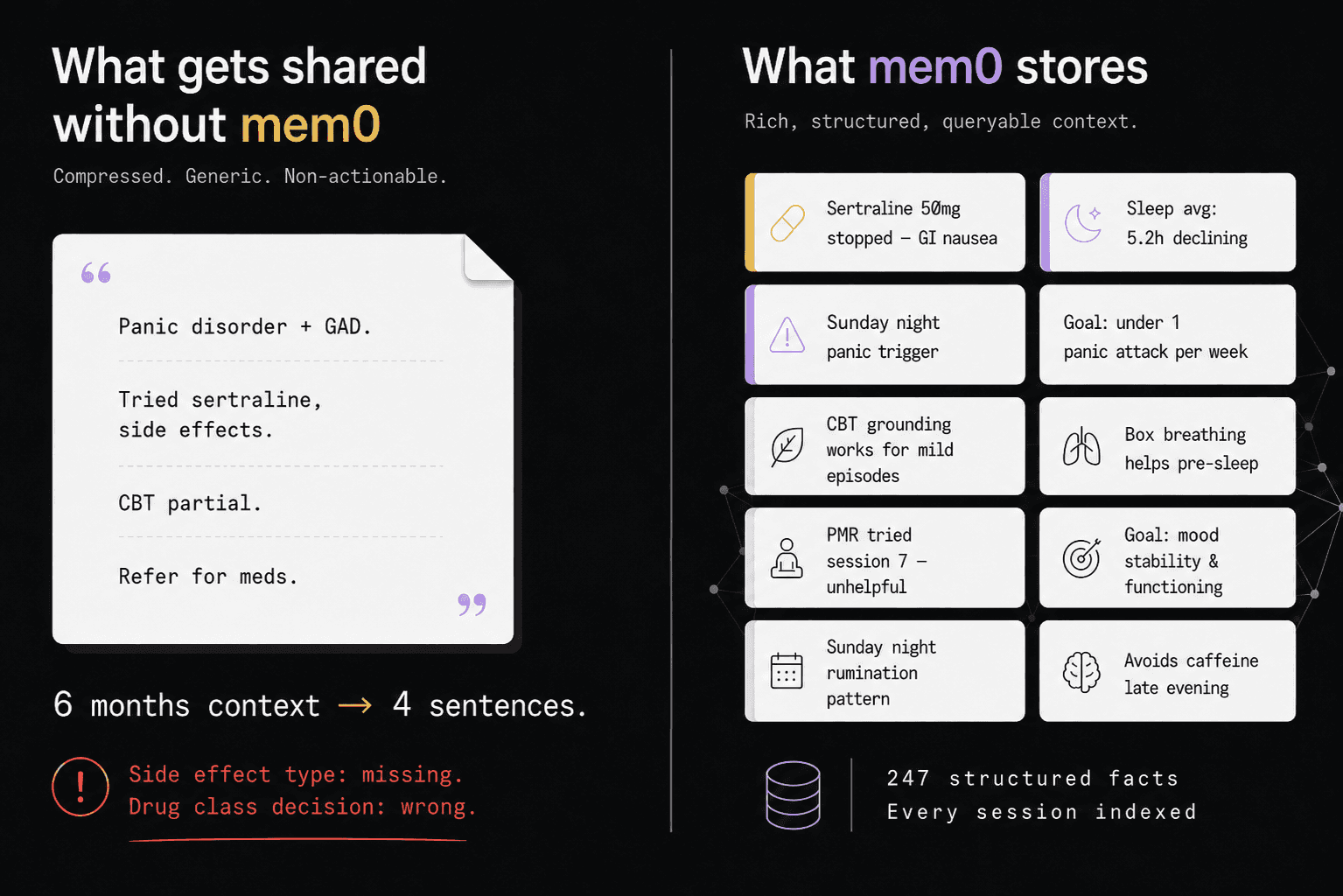
Fig: Problem 2 - Lossy compression leads to loss of critical information
When a therapist refers a patient to a psychiatrist, they don't send 24 sessions of structured notes. They send a referral letter. One page or maybe two?
Here is an example:
"Patient has panic disorder and generalized anxiety. Tried sertraline, discontinued due to side effects. Currently using CBT techniques with partial success. Referring for medication evaluation."
That is a lossy compression of 6 months of clinical work into 4 sentences.
What survives: the diagnosis, the broad medication history, the referral reason.
What doesn't: the specific side effect (GI, not neurological, which matters for choosing the next medication), the exact coping strategies that work and which don't, the sleep trend over the past month, the treatment goals, the between-session journal entries showing the patient's own words about their experience.
💡68% of specialists report receiving no preliminary information at all before a referral, while 70% rate the quality of referral information they do receive as fair or poor(Source). Even when information is shared, it is shared as a summary, not as structured retrievable facts. Only 35% of primary care referrals to specialists result in completed appointments(Source), and information gaps are a leading reason patients don't follow through.
What this looks like in practice
The psychiatrist reads the referral letter and prescribes a medication from the same drug class as one the patient already had a bad reaction to. The referral said "discontinued due to side effects" but didn't specify which side effects or which drug class alternatives were discussed. Hence, the psychiatrist is working blind.
How Mem0 fixes this
If the therapist's assistant stored facts in Mem0 after every session (as shown above), the psychiatrist's assistant reads from the same patient_id before the first appointment. The referral letter is no longer the only source of context. The full structured history is there.
⭐️ In production, this runs before every specialist appointment. One
search()call replaces the referral letter as the primary context source. Try it free and test with your own patient workflow.
Without shared memory, the psychiatrist opens with:
With Mem0, the psychiatrist opens with:
That second opening saves 15 minutes of a 30-minute appointment. But more importantly, it captures the specificity that a referral letter never would.
Mem0's benchmarks on this kind of cross-session retrieval: 91% lower p95 latency than full-context replay (1.44s vs 17.12s) and 26% higher accuracy than OpenAI's memory on the LOCOMO benchmark (66.9% vs 52.9%). The accuracy gap matters clinically: a 26% improvement in recall means the difference between "sertraline was discontinued" and "sertraline was discontinued due to GI side effects (nausea, diarrhoea), not lack of efficacy."
Problem 3: No structured retrieval

Fig: Problem 3 - Session notes are not structured queryable facts
The underlying problem beneath the first two is that session notes exist as prose, not as queryable facts. Whether it is the therapist's own assistant in session 24, the psychiatrist's assistant reading a referral, or a patient's journaling companion trying to surface a 3-month mood trend, the failure mode is the same: the information exists somewhere in a pile of unstructured text, and there is no way to query it directly.
EHR notes are written for clinicians, not for AI context windows. They are free-text, full of abbreviations that vary by provider, and structured around billing codes rather than treatment narratives. Psychotherapy notes have a specific HIPAA carve-out (45 CFR 164.501) that restricts their inclusion in the general medical record, which means the richest clinical context is often the hardest to access programmatically.
What this looks like in practice:
A patient logs mood, sleep quality, and journal entries between appointments via an AI journaling companion. After 3 months, the data shows a clear pattern: mood dips correlate with Sunday evenings, sleep quality declines in the week before a panic attack cluster. But the data is stored sequentially, not indexed for retrieval. The therapist's assistant in session 12 can see the most recent entries but not the longitudinal trend. The pattern is invisible.
How Mem0 fixes this
Between-session entries go into the same memory store as session notes. Mem0 extracts the facts and makes them queryable alongside everything from the clinical sessions.
Now the therapist, the psychiatrist, or the journaling companion can query "sleep patterns and panic attack frequency" and get a structured answer spanning months of both session notes and journal entries.
The extraction-over-summarization approach is what makes this work: Each fact is independently retrievable, not buried in a prose summary that loses precision every time it gets compressed. Mem0's multi-signal retrieval runs three scoring passes in parallel (semantic similarity, keyword matching, and entity matching) and fuses the results, which is why a query like "medications tried" returns the sertraline fact even though the word "medication" might not appear in the original therapy transcript.
⭐️ Between-session entries, clinical notes, and cross-provider context all live in the same queryable store. Start free on Mem0 and test with your own patient workflow.
How Mem0 scopes memory for multi-provider mental health workflows
All three fixes above depend on a shared memory store with precise scoping. Mem0's multi-provider memory scoping gives you four identity dimensions on every add() and search() call:
Scope | Maps to | What you store | Example |
|---|---|---|---|
| Patient (MRN) | Cross-provider, cross-session facts | Diagnosis, medications, allergies, treatment goals, coping toolkit, triggers |
| Provider role | Which provider contributed what | "therapist", "psychiatrist", "journal companion" |
| Session/encounter | Single-session state | Today's presenting mood, session-specific decisions |
| Practice/health system | Shared institutional knowledge | Formulary, crisis protocols, insurance-approved medication lists |
Cross-provider facts live at user_id scope. Session-specific state lives at run_id scope. When the psychiatrist queries the memory store, they query at user_id scope and get everything relevant from every provider and every session. When the therapist's own assistant needs to recall session 3, it queries at user_id scope with a specific question and gets the answer, even though 21 sessions have passed.
💡The identity key must be an internal identifier (MRN, system-generated UUID), never raw PII like email or SSN. This is both a HIPAA requirement and good architecture practice.
Why mental health data needs stricter memory controls
Mental health data is not general healthcare data. Three regulatory layers apply on top of standard HIPAA, and your memory architecture must account for all of them.
Psychotherapy notes
Psychotherapy notes (45 CFR 164.501) are explicitly excluded from the general medical record. They require separate patient authorization for disclosure, even to other providers within the same health system. A memory layer that stores raw therapy transcripts in the same scope as general clinical facts would violate this protection.
The architecture fix: store extracted facts, not raw session transcripts. The memory layer contains "patient tried sertraline, discontinued due to GI side effects" and "CBT grounding techniques effective for mild episodes." It does not contain the verbatim transcript of the session where the patient discussed their childhood trauma. The 2025 HIPAA Security Rule amendments made encryption of ePHI mandatory (previously "addressable") and expanded audit trail requirements to cover every AI system that touches PHI.
Minimum Necessary Standard and selective retrieval
HIPAA's Minimum Necessary Standard (45 CFR 164.502(b)) requires that only the PHI needed for the current purpose is accessed. A memory system that dumps the patient's entire history into the psychiatrist's context window on every turn violates this by design.
Mem0's top_k retrieval is architecturally aligned with Minimum Necessary. The psychiatrist's assistant queries "medication history and treatment progress" and gets medication history and treatment progress. It does not get the patient's full journal entries about their relationship or childhood unless those are relevant to the specific query.
💡Selective retrieval cuts token costs by 90% and satisfies the regulatory requirement simultaneously.
Audit trails: non-negotiable
Every mem0.add() and mem0.search() call must be logged with timestamp, patient_id, provider_id, and the query. The 2025 Security Rule amendments require audit trails for every AI system that touches PHI. Mem0's platform provides built-in audit logging. For self-hosted deployments, we can even implement logging at the application layer.
Mem0's deployment options
Managed cloud at app.mem0.ai is the fastest path. SOC 2 Type I certified, HIPAA compliant, with built-in audit logging and zero-trust architecture.
Self-hosted via Docker runs on any cloud or on-prem server. The full deployment guide covers the Postgres, pgvector and Neo4j stack and production hardening.
Kubernetes / private cloud deploys inside your VPC with the same API surface. No data leaves your infrastructure.
Air-gapped deployment packages container images for fully offline environments. No outbound network connectivity required. This is the deployment model for VA facilities, correctional health systems, and organizations under state-level privacy mandates.
All deployment models support BYOK (Bring Your Own Key) encryption. Patient data is encrypted at rest and in transit with keys your organization controls, not Mem0.
An engineering team that prototypes on the managed cloud and migrates to on-prem for production does not rewrite a single line of memory logic.
Conclusion
The real problem with AI therapy assistants is not that they lose information. It is that they bury it. After 20+ sessions, the trigger from session 3 is unreachable (Problem 1). At referral, 6 months of structured notes become a 4-sentence letter (Problem 2). Across both, notes exist as prose that no one can query (Problem 3).
Structured extraction after every session, stored in a persistent memory layer with selective retrieval, fixes all three at once. The therapist's own assistant retrieves session 3 facts in session 24. The psychiatrist retrieves 6 months of cross-provider context before the first appointment. Mem0 provides 91% lower latency, 90% fewer tokens, 26% higher accuracy than full-context replay.
Ready to add persistent memory to your clinical AI assistant?
Start free at app.mem0.ai (no credit card, free tier includes add + search)
Self-host with Docker for on-prem deployments
Explore the healthcare use case for the full compliance and architecture picture
Frequently asked questions
Q. Does memory from therapy sessions persist across sessions with the same therapist?
Yes. This is the within-provider value (Problem 1). Facts extracted after session 3 are retrievable in session 24 by query. The assistant queries "what triggers have been identified" and gets a structured answer spanning the full treatment history, regardless of how many sessions have accumulated since.
Q. Does memory persist into the psychiatry appointment after a referral?
Yes. This is the cross-provider value (Problem 2). Any fact stored at user_id scope is available to any provider querying that scope. The therapist writes to user_id=patient_mrn, the psychiatrist reads from the same user_id. The full structured history supplements the referral letter rather than depending on it.
Q. Can the patient control what gets shared?
Yes. The architecture supports consent-gated retrieval. Tag memories with consent metadata and filter at retrieval time. Substance use records (42 CFR Part 2) require explicit written consent before any cross-provider sharing. General treatment information is shareable between treating providers under HIPAA's Treatment, Payment, and Health Care Operations exception without additional consent.
Q. What if the patient sees two therapists?
Both write to the same user_id. Each uses a different agent_id. The memory store accumulates facts from both. The psychiatrist sees the unified picture. The agent_id tag and metadata field provide full provenance for which therapist contributed which fact.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

