


Every LLM interaction starts the same way: blank slate, no context, no history, no awareness of who the user is or what they have said before. That is the default. And for simple, one-off queries, it is fine.
But production AI systems are rarely one-offs. Customer support agents handle ongoing cases that span days. Coding assistants work across repositories and sessions. Research tools accumulate findings over weeks. Personal AI assistants need to hold preferences, past conversations, and accumulated knowledge to be useful at all.
The gap between a stateless LLM and an agent that can actually remember is not a model capability question. It is a memory management question. This article explains how memory management works in practice - what the data structures look like, how extraction pipelines work, where things break down, and what the benchmark evidence says about different approaches.
Why This Is Harder Than It Looks
The naive approach to memory is intuitive: store conversation history, replay it on each request. If the user told the agent something last Tuesday, that turn is in the history, the model sees it, problem solved.
This works until it doesn't.
At 10 conversation turns, full-history replay is manageable. At 40 turns - common in any ongoing customer relationship or extended project - the input token count has ballooned well past what makes sense to send on every call. And even when the tokens are available, the model does not give every position in the context window equal attention. Stanford NLP's "Lost in the Middle" research documented this precisely: retrieval accuracy degrades significantly when relevant information lands in the middle of a long context, away from the edges where model attention is strongest.
There is also the session boundary problem. No matter how much history you accumulate in a single conversation, the context window resets when the session ends. Every new session starts from zero unless you have built something to persist and retrieve the relevant parts. A context window is working memory. What agents actually need is long-term memory - a different system entirely.
Mem0's latest research measures this trade-off directly. Full-context approaches on the same benchmarks use 25,000+ tokens per query. Mem0's current token-efficient memory algorithm stays under 7,000 tokens per retrieval call, while reporting 92.5 on LoCoMo and 94.4 on LongMemEval.
The point is not only lower cost. It is selectivity. Full-context prompting asks the model to sift through everything. A memory layer extracts durable facts, retrieves the few that matter, and leaves the rest out of the prompt.
The Four Memory Layers
Effective memory management for agents is not a single store. It is a hierarchy of stores with different retention windows, retrieval patterns, and purposes.
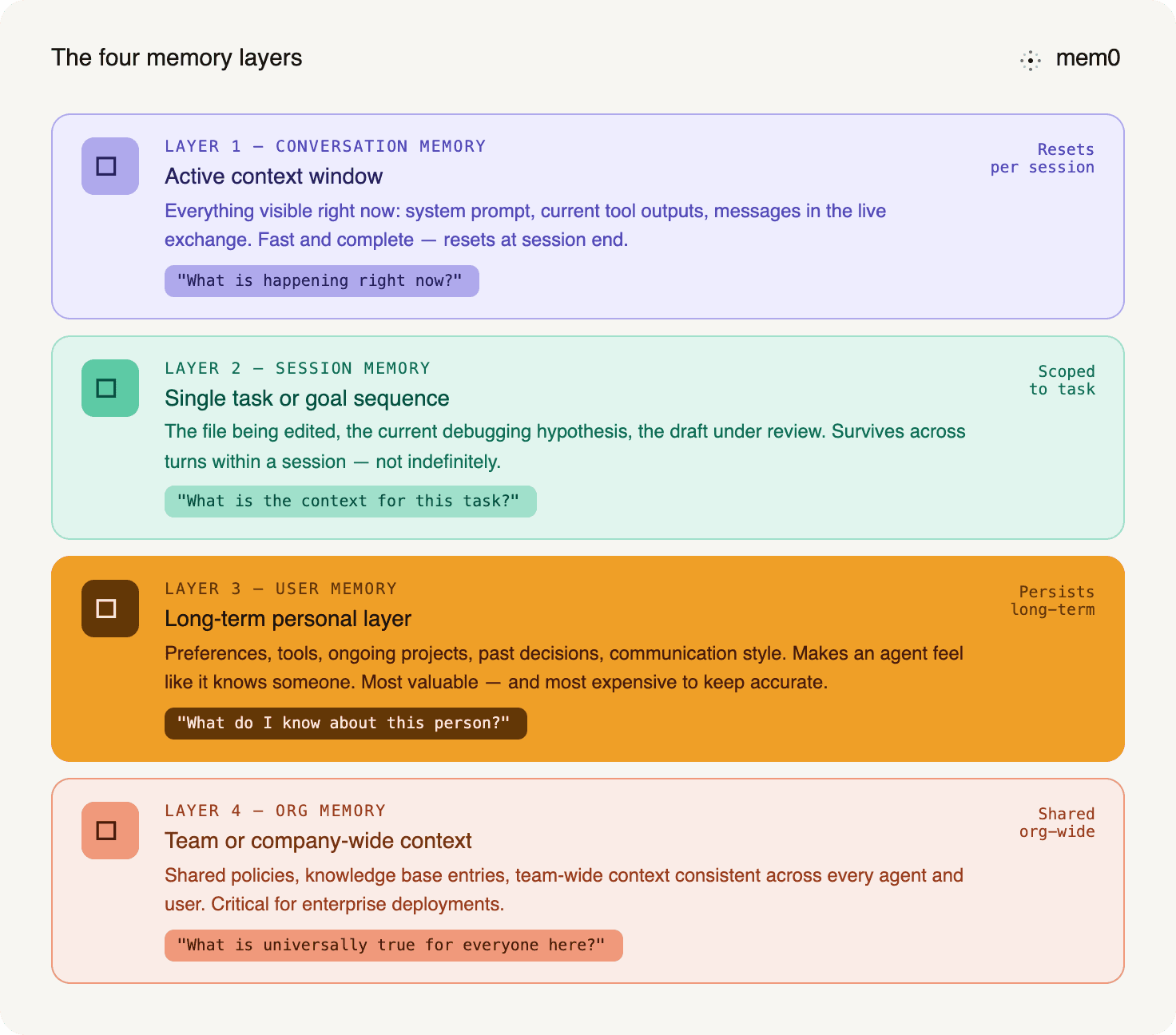
Fig: Four memory layers
Conversation memory is the active context window - what the model can see right now. Everything in a live turn is here: system prompt, current tool outputs, and the messages in the current exchange. It is fast and complete, but it resets at the end of the session, and its capacity is constrained by the model's context limit. This is where most teams stop.
Session memory spans a single task or goal sequence. It holds the thread of what is happening in a work session - the file the user is editing, the current debugging hypothesis, and the draft under review. Session memory survives across the individual turns within a session but does not need to persist indefinitely. Not everything that matters now will matter in six months.
User memory is the long-term layer. It holds what is durably true about a person: their preferences, the tools they use, the projects they are working on, the decisions they have made, their communication style, and domain context. User memory is the layer that makes an agent feel like it actually knows someone rather than starting fresh each time. It is also the most valuable and the most expensive to maintain correctly, because it has to stay accurate as things change.
Organizational memory operates at the team or company level. Shared policies, knowledge base entries, and team-wide context that should be consistent across every agent and every user in a deployment. This is the layer that matters for enterprise applications, where an agent needs to reflect company-specific knowledge regardless of which employee is using it.
Each layer answers a different question. Conversation memory answers "what is happening right now?" Session memory answers "what is the context for this task?" User memory answers, "What do I know about this person?" Org memory answers "what is universally true for everyone in this organization?" A functional memory management system needs all four. Most implementations have only the first.
The short-term vs. long-term memory breakdown covers how these layers map to each other and where the architectural handoffs are.
How Memory Extraction Actually Works
Storing memories is easy. Storing the right memories, while preserving how information changes over time, is the engineering problem.
Mem0's current algorithm uses single-pass ADD-only extraction. New facts are extracted in one pass and added to memory. The system does not overwrite or delete older memories during extraction.
This matters because user history is not a single mutable profile. It is a timeline. A user can change jobs, move cities, switch tools, or revise a preference. The older fact may still matter historically, even if it is no longer the current answer.
Retrieval handles the current query by ranking the most relevant memories. The latest stack combines semantic similarity, BM25 keyword matching, and entity matching, then fuses those signals into one score.
Memory Types: What Gets Stored
Not all memory content is the same kind of thing, and treating it as undifferentiated text is one of the more common design mistakes in production agent memory.
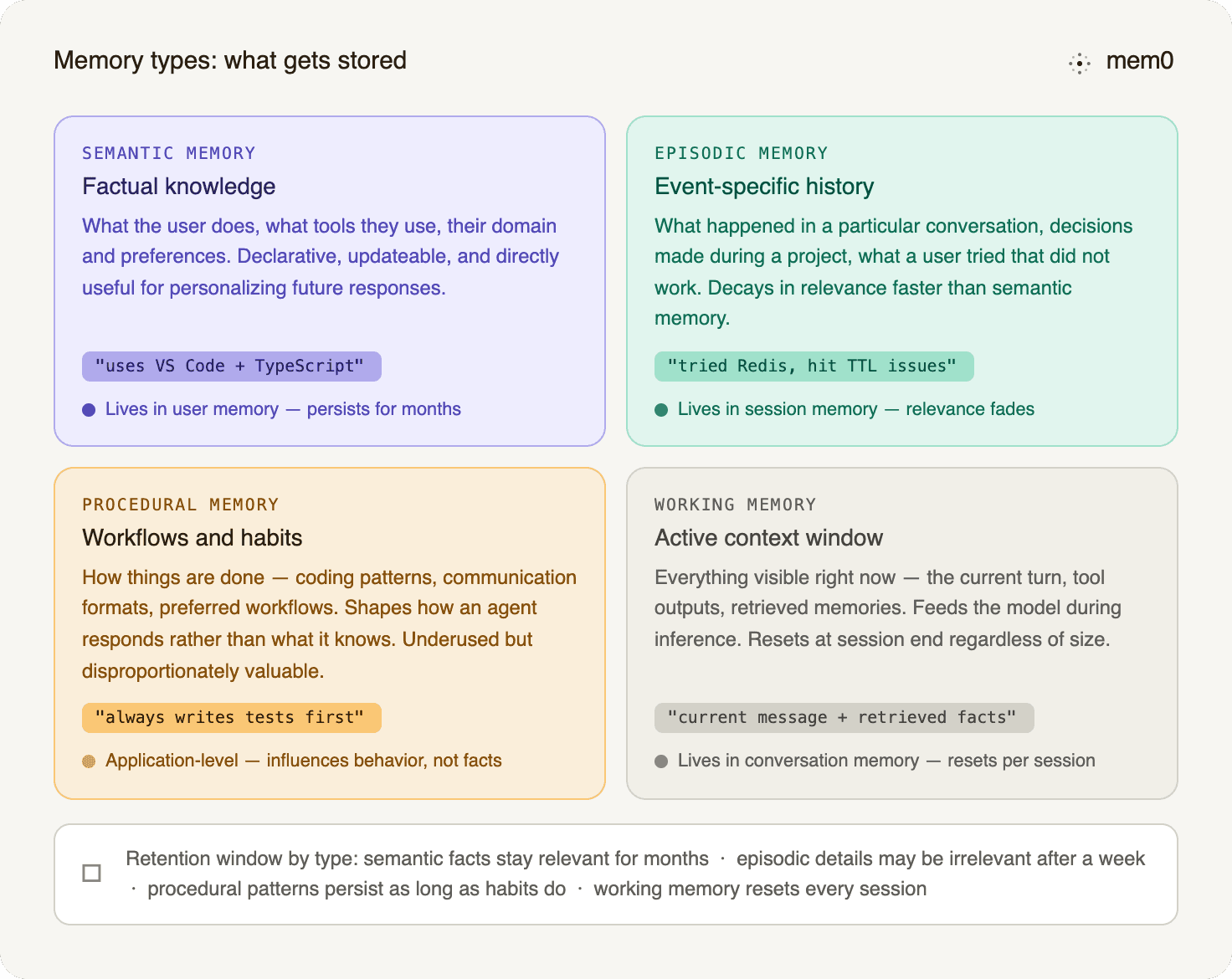
Fig: Memory types: what gets stored
Semantic memory is factual knowledge: what the user does, what tools they use, what their domain is, and what preferences they have expressed. This is the primary candidate for the user memory layer. It is declarative, updateable, and directly useful for personalizing future responses.
Episodic memory is event-specific: what happened in a particular conversation, what decisions were made during a specific project, what a user tried that did not work. Episodic memory is useful for continuity ("you mentioned last week that you tried X") but decays in relevance faster than semantic memory. It often belongs in session memory rather than user memory.
Procedural memory covers how things are done: workflows a user follows, coding patterns they prefer, and communication formats that work for them. Procedural memory influences behavior rather than knowledge - it shapes how an agent responds rather than what it knows. It is underused in current agent systems and disproportionately valuable when captured correctly. It is a useful application-level category for workflows and habits, even if it is not always exposed as a separate storage layer.
Working memory is the active context - the content of the current context window. The short-term memory guide covers how this layer works and how it interacts with retrieval from longer-term stores.
Understanding which type of memory you are storing changes where it should live and how long it should be retained. Semantic facts about a user stay relevant for months. Details of a specific debugging session may be irrelevant after the week ends.
The Retrieval Problem
Vector similarity is useful, but incomplete. It can miss exact terms, ignore entity relationships, and retrieve stale facts that are semantically close but no longer current.
Mem0's current retrieval stack addresses this with multi-signal search. Semantic similarity finds meaning. BM25 keyword matching helps with exact terms. Entity matching boosts memories connected to people, projects, tools, organizations, and other extracted entities.
The old Mem0g graph-enhanced variant is now historical. External graph memory has been replaced by built-in entity linking. Entities are extracted from memories, stored in a parallel entity collection, and used to improve ranking at search time.
The trade-off is important: this is not a queryable graph interface. Entity relationships are used indirectly for retrieval ranking, not exposed as a graph traversal API.
Memory Scoping for Multi-User and Multi-Agent Systems
A memory system that works correctly for a single user becomes a liability in production when the scope is not managed carefully. Mem0's architecture supports five scoping dimensions:
user_id: Memory specific to an individual user. The most common scope. Memories tied to auser_idare scoped to that user when queries use the same filter. Applications still need proper authentication and access-control boundaries around those IDs.run_id: Memory scoped to a specific session or task sequence. Useful for maintaining continuity within a project sprint or support case without permanently writing session-specific context to the user layer.agent_id: Memory associated with a specific agent instance. Relevant when you have multiple specialized agents in the same deployment - a code review agent and a documentation agent might both interact with the same user, but should maintain separate learned context.run_id(execution scope): Memory scoped to a single execution or pipeline run. Useful for batch processing where you need to track what happened in a specific run without polluting the user's persistent memory.org_id: Organizational memory shared across all users and agents in a deployment. The right scope for shared knowledge bases, company policies, or team-wide context that every agent instance should have access to.
Scopes can be combined. A query with both user_id and org_id will retrieve memories specific to that user, plus any org-level context that is relevant - a common pattern in enterprise deployments where agents need to blend personal context with company knowledge.
Getting scoping wrong creates two failure modes. Over-broad scoping bleeds memory between users or contaminates the org layer with individual user data. Under-broad scoping means the agent cannot access memories it should be using, which looks like poor retention even when the data is correctly stored.
The multi-agent memory systems guide covers how to structure scopes for complex agent architectures with multiple specialized agents operating on shared data.
Forgetting as a Design Requirement
A good memory system also needs a way to keep stale memories from dominating retrieval.
Mem0's Memory Decay handles this as a search-time soft rerank, not a hard delete. Each memory receives a recency-based scaling factor between 0.3× and 1.5×. Recently accessed memories get boosted. Idle memories are gently dampened.
The floor matters. A stale memory is not erased. If it is still the strongest semantic match, it can still surface. Decay only changes ranking pressure, helping current and recently useful memories stay near the top.
This solves low-relevance staleness, like an old breakfast preference. It does not fully solve high-relevance memories that have become wrong, like an outdated employer. Those still require timestamp-aware resolution at the application layer.
The Case for Local and Privacy-First Memory
Not every deployment can send user memory data to a cloud API. Healthcare applications with PHI, legal applications with privileged information, and any enterprise operating under strict data residency requirements need memory management that runs locally.
In these cases, you can self-host Mem0, keeping all memory data on your own infrastructure. It extracts, deduplicates, and retrieves only what's relevant at query time, while still integrating with tools like Claude, Cursor, and other MCP-compatible clients.
The tradeoff is infrastructure: local deployment means local resource management, local backup, and local reliability. For teams with compliance requirements that preclude cloud memory storage, it is a necessary tradeoff. For most development use cases and consumer applications, the cloud-hosted option is the lower-overhead path.
Integration Patterns in Production
The memory management system does not operate in isolation. It needs to integrate with whatever framework is running the agent, and the integration pattern affects how memory operations fit into the agent's request/response cycle.
For frameworks like LangChain and LangGraph, Mem0 integrates as a retriever and a storage backend. The agent can call memory search at the start of each turn to surface relevant context, and queue memory write operations at the end to capture anything worth persisting. In LangGraph specifically, memory operations can be embedded as nodes in the graph - a retrieve node at the beginning of the workflow, a store node at the end - which keeps the memory logic explicit in the workflow definition rather than buried in the agent's system prompt.
For Mastra, the integration exposes two tools directly to the agent: a Mem0-remember tool for retrieval and a Mem0-memorize tool for storage. The agent's own reasoning drives when each tool fires. The memorize tool saves asynchronously - the write happens in the background without blocking the agent's response, which keeps latency from compounding on write-heavy sessions. The remember tool uses semantic search, so the agent does not need to know exactly what it is looking for - it can pass the current user question, and the retrieval system finds the relevant stored context.
The key architectural choice across all integration patterns is whether memory operations are agent-driven (the agent decides when to read and write) or pipeline-driven (memory retrieval and storage happen automatically at defined points in every request cycle). Agent-driven memory is more flexible and avoids unnecessary memory operations on queries where history is not relevant. Pipeline-driven memory is more consistent - it does not depend on the agent's reasoning to correctly identify memory-worthy moments.
For most production applications, a hybrid approach works best: automatic retrieval at the start of each request (so the agent always has relevant context), and agent-driven storage (so the agent decides what from the current turn is worth keeping).
What the Numbers Actually Say
Three metrics matter for production memory management: accuracy, token cost, and retrieval quality under scale.
The latest Mem0 research page reports:
Benchmark | Score | Avg tokens/query |
|---|---|---|
LoCoMo | 92.5 | 6,956 |
LongMemEval | 94.4 | 6,787 |
BEAM 1M | 64.1 | 6,710 |
BEAM 10M | 48.6 | 6,910 |
LoCoMo and LongMemEval show strong long-term memory performance under practical token budgets. BEAM is harder because it evaluates memory at 1M and 10M token scales. At that size, many similar facts appear across history, and retrieval must find the exact useful one.
The production takeaway is simple: full-context approaches can use 25,000+ tokens per query. Mem0 stays under 7,000 tokens per retrieval call while preserving high benchmark accuracy.
Building the Right Memory Architecture
The practical sequence for teams adding memory management to an existing agent system:
Start with scope definition: Identify which memory layers you actually need. Most agents need user memory and conversation memory at a minimum. Session memory matters if users work in extended task sequences. Organizational memory matters if shared knowledge needs to be consistent across users.
Choose extraction over summarization: Summarization compresses conversation history but keeps it as undifferentiated text. Extraction pulls discrete facts and stores them as searchable, updateable units. Extraction has a higher upfront processing cost and pays back in retrieval quality, accuracy, and the ability to update individual facts without reprocessing entire conversation threads. The LLM chat history guide covers this trade-off in detail.
Build for history, not overwrites. With ADD-only extraction, changed information is stored alongside older information. Your retrieval and application logic should understand which fact is current, which fact is historical, and when each was true.
Enable lifecycle-aware ranking: Memory Decay can help low-relevance stale entries fall in rank without deleting them. For critical evergreen facts, use metadata, categories, or application-side rules so important memories are not accidentally pushed below top-k.
Get scoping right before going multi-user: user_id isolation is the minimum. If you have multiple agents or organizational contexts, define the scoping model before the first deployment rather than retrofitting it after.
Measure latency and accuracy separately: Retrieval accuracy and response latency pull in different directions as context grows. Benchmark both for your specific workload rather than relying on general numbers. What matters is how the system performs on the queries your users actually ask.
The AI agent memory guide and the long-term memory guide cover the implementation side of these decisions in detail.
Memory management is where the gap between a stateless LLM and a useful agent actually closes.
Large context windows help within a session. They do not create continuity across sessions. A production memory layer has to decide what to store, how to preserve changes over time, and how to retrieve the right facts without flooding the prompt.
The current pattern is selective memory plus hybrid retrieval: ADD-only extraction, semantic search, keyword matching, entity linking, and decay-aware ranking. That is what lets an agent remember accurately without carrying the whole transcript forever.
External references:
Mem0 Research: benchmark results across LoCoMo, LongMemEval, and BEAM
OSS v3 Migration Docs: v2 to v3 migration guide
Memory Types: semantic, episodic, procedural, and working memory
Memory Decay: search-time soft rerank documentation
Lost in the Middle: Stanford NLP research on long-context attention degradation
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

